当前位置:网站首页>#夏日挑战赛#数据库学霸笔记(下)~
#夏日挑战赛#数据库学霸笔记(下)~
2022-07-06 18:37:00 【51CTO】
视图/存储过程/触发器 视图
视图是虚拟的表,与包含数据的表不同,视图只包含使用时动态检索数据的查询,主要是用于查询。 为什么使用视图
注意:
视图的规则和限制
视图的创建
视图的更新
视图是否可以更新,要视情况而定。
通常情况下视图是可以更新的,可以对他们进行insert,update和delete。更新视图就是更新其基表(视图本身没有数据)。如果你对视图进行增加或者删除行,实际上就是对基表进行增加或者删除行。
但是,如果MySQL不能正确的确定更新的基表数据,则不允许更新(包括插入和删除),这就意味着视图中如果存在以下操作则不能对视图进行更新:(1)分组(使用group by 和 having );(2)联结;(3)子查询;(4)并;(5)聚集函数;(6)dictinct;(7)导出(计算)列。
存储过程
存储过程就是为了以后的使用而保存的一条或者多条MySQL语句的集合。可将视为批文件,虽然他们的作用不仅限于批处理。 为什么使用储存过程?
1.通过把处理封装在容易使用的单元中,简化复杂的操作;
2.由于不要求反复建立一系列处理步骤,保证了数据的完整性。如果所有开发人员和应用程序都使用同一(实验和测试)存储过程,则所使用的代码都是相同的。这一点的延伸就是防止错误。需要执行的步骤越多,出错的可能性就越大,防止错误保证了数据的一致性。
3.简化对变动的管理,如果表名。列名或者业务逻辑等有变化,只需要更改存储过程的代码。使用它的人员甚至不需要知道这些变化。这一点延伸就是安全性,通过存储过程限制对基数据的访问减少了数据讹误的机会。
4.提高性能。因为使用存储过程比使用单独的sql语句更快。
5.存在一些只能用在单个请求的MySQL元素和特性,存储过程可以使用他们来编写功能更强更灵活的代码
综上:
三个主要的好处:简单、安全、高性能。
两个缺陷:
1、存储过程的编写更为复杂,需要更高的技能更丰富的经验。
2、可能没有创建存储过程的安全访问权限。许多数据库管理员限制存储过程的 创建权限,允许使用,不允许创建。 执行存储过程
Call关键字:Call接受存储过程的名字以及需要传递给他的任意参数。存储过程可以显示结果,也可以不显示结果。
CREATE PROCEDURE productpricing()
创建名为productpricing的储存过程。如果存储过程中需要传递参数,则将他们在括号中列举出来即可。括号必须有。BEGIN和END关键字用来限制存储过程体。上述存储过程体本身是一个简单的select语句。注意这里只是创建存储过程并没有进行调用。
储存过程的使用:
Call productpring();
使用参数的存储过程
一般存储过程并不显示结果,而是把结果返回给你指定的变量上。
变量:内存中一个特定的位置,用来临时存储数据。
解释:
此存储过程接受3个参数,pl存储产品最低价,ph存储产品最高价,pa存储产品平均价。每个参数必须指定类型,使用的为十进制,关键字OUT 指出相应的参数用来从存储过程传出一个值(返回给调用者)。
MySQL支持in(传递给存储过程)、out(从存储过程传出,这里所用)和inout(对存储过程传入和传出)类型的参数。存储过程的代码位于begin和end语句内。他们是一系列select语句,用来检索值。然后保存到相对应的变量(通过INTO关键字)。
存储过程的参数允许的数据类型与表中使用的类型相同。注意记录集是不被允许的类型,因此,不能通过一个参数返回多个行和列,这也是上面为什么要使用3个参数和3条select语句的原因。
调用:为调用此存储过程,必须指定3个变量名。如上所示。3个参数是存储过程保存结果的3个变量的名字。调用时,语句并不显示任何数据,它返回以后可以显示的变量(或在其他处理中使用)。
注意:所有的MySQL变量都是以@开头。
带有控制语句的存储过程
在存储过程中我们使用了DECLARE语句,他们表示定义两个局部变量,DECLARE要求指定变量名和数据类型。它也支持可选的默认值(taxrate默认6%),因为后期我们还要判断要不要增加税,所以,我们把SELECT查询的结果存储到局部变量total中,然后在IF 和THEN的配合下,检查taxable是否为真,然后在真的情况下,我们利用另一条SELECT语句增加营业税到局部变量total中,然后我们再利用SELECT语句将total(增加税或者不增加税的结果)保存到总的ototal中。
COMMENT关键字 上面的COMMENT是可以给出或者不给出,如果给出,将在SHOW PROCEDURE STATUS的结果中显示。
触发器
在某个表发生更改时自动处理某些语句,这就是触发器。
触发器是MySQL响应delete 、update 、insert 、位于begin 和end语句之间的一组语句而自动执行的一条MySQL语句。其他的语句不支持触发器。 创建触发器
在创建触发器时,需要给出4条语句(规则):
- 唯一的触发器名;
- 触发器关联的表;
- 触发器应该响应的活动;
- 触发器何时执行(处理之前或者之后)
Create trigger 语句创建 触发器
CREATE TRIGGER newproduct AFTER INSERT ON products FOR EACH ROW SELECT 'Product added' INTO @info;
CREATE TRIGGER用来创建名为newproduct的新触发器。触发器可以在一个操作发生前或者发生后执行,这里AFTER INSERT 是指此触发器在INSERT语句成功执行后执行。这个触发器还指定FOR EACH ROW , 因此代码对每个插入行都会执行。文本Product added 将对每个插入的行显示一次。
注意:
1、触发器只有表才支持,视图,临时表都不支持触发器。
2、触发器是按照每个表每个事件每次地定义,每个表每个事件每次只允许一个触发器,因此,每个表最多支持六个触发器(insert,update,delete的before 和after)。
3、单一触发器不能与多个事件或多个表关联,所以,你需要一个对insert和update 操作执行的触发器,则应该定义两个触发器。
4、触发器失败:如果before 触发器失败,则MySQL将不执行请求的操作,此外,如果before触发器或者语句本身失败,MySQL则将不执行after触发器。 触发器类别
INSERT触发器
是在insert语句执行之前或者执行之后被执行的触发器。
1、在insert触发器代码中,可引入一个名为new的虚拟表,访问被插入的行;
2、在before insert触发器中,new中的值也可以被更新(允许更改被插入的值);
3、对于auto_increment列,new在insert执行之前包含0,在insert执行之后包含新的自动生成值
CREATE TRIGGER neworder AFTER INSERT ON orders FOR EACH ROW SELECT NEW.order_num;
创建一个名为neworder的触发器,按照AFTER INSERT ON orders 执行。在插入一个新订单到orders表时,MySQL生成一个新的订单号并保存到order_num中。触发器从NEW.order_num取得这个值并返回它。此触发器必须按照AFTER INSERT执行,因为在BEFORE INSERT语句执行之前,新order_num还没有生成。对于orders的每次插入使用这个触发器总是返回新的订单号。
DELETE触发器
Delete触发器在delete语句执行之前或者之后执行。
1、在delete触发器的代码内,可以引用一个名为OLD的虚拟表,用来访问被删除的行。
2、OLD中的值全为只读,不能更新。
在任意订单被删除前将执行此触发器,它使用一条INSERT 语句将OLD中的值(要被删除的订单) 保存到一个名为archive_orders的存档表中(为实际使用这个例子,我们需要用与orders相同的列创建一个名为archive_orders的表)
使用BEFORE DELETE触发器的优点(相对于AFTER DELETE触发器来说)为,如果由于某种原因,订单不能存档,delete本身将被放弃。
我们在这个触发器使用了BEGIN和END语句标记触发器体。这在此例子中并不是必须的,只是为了说明使用BEGIN END 块的好处是触发器能够容纳多条SQL 语句(在BEGIN END块中一条挨着一条)。
UPDATE触发器
在update语句执行之前或者之后执行
1、在update触发器的代码内,可以引用一个名为OLD的虚拟表,用来访问以前(UPDATE语句之前)的值,引用一个名为NEW的虚拟表访问新更新的值。
2、在BEFORE UPDATE触发器中,NEW中的值可能也被用于更新(允许更改将要用于UPDATE语句中的值)
3、OLD中的值全为只读,不能更新。
CREATE TRIGGER updatevendor BEFORE UPDATE ON vendors FOR EACH ROW SET NEW.vend_state = Upper(NEW.vemd_state);
保证州名缩写总是大写(不管UPFATE语句中是否给出了大写),每次更新一行时,NEW.vend_state中的值(将用来更新表行的值)都用Upper(NEW.vend_state)替换。 总结
1、通常before用于数据的验证和净化(为了保证插入表中的数据确实是需要的数据) 也适用于update触发器。
2、与其他DBMS相比,MySQL 5中支持的触发器相当初级,未来的MySQL版本中估计会存在一些改进和增强触发器的支持。
3、创建触发器可能需要特殊的安全访问权限,但是触发器的执行时自动的,如果insert,update,或者delete语句能够执行,则相关的触发器也能执行。
4、用触发器来保证数据的一致性(大小写,格式等)。在触发器中执行这种类型的处理的优点就是它总是进行这种处理,而且透明的进行,与客户机应用无关。
5、触发器的一种非常有意义的使用就是创建审计跟踪。使用触发器,把更改(如果需要,甚至还有之前和之后的状态)记录到另外一个表是非常容易的。
6、MySQL触发器不支持call语句,无法从触发器内调用存储过程。
数据库恢复 实现技术
数据转储
转储是指DBA将整个数据库复制到其他存储介质上保存起来的过程,备用的数据称为后备副本或后援副本
静态转储:
1)定义:在系统中无事务运行时进行的转储操作。转储开始的时刻数据库处于一 致性状态,而转储不允许对数据库的任何存取、修改活动。静态转储得到的一定是一个数据一致性的副本。
2)优点:实现简单
3)缺点:降低了数据库的可用性
转储必须等待正运行的用户事务结束才能进行;新的事务必须等待转储结束才能执行
动态转储:
海量转储:
增量转储:
日志文件
1、什么是日志文件
日志文件(log)是用来记录事务对数据库的更新操作的文件 2、日志文件的格式
1)以记录为单位:
日志文件中需要登记的内容包括:
每个日志记录的内容:
2)以数据块为单位
日志记录内容包括:
事务标识(标明是哪个事务)
被更新的数据块 3、日志文件的作用
1)事务故障恢复和系统故障恢复必须用日志文件
2)在动态转储方式中必须建立日志文件,后备副本和日志文件结合起来才能有效地恢复数据库
3)静态转储方式中也可以建立日志文件(重新装入后备副本,然后利用日志文件把已完成的事务进行重做,对未完成事务进行撤销)
4、登记日志文件:
为什么要先写日志文件?
1)写数据库和写日志文件是两个不同的操作,在这两个操作之间可能发生故障
2)如果先写了数据库修改,而在日志文件中没有登记下这个修改,则以后就无法恢复这个修改了
3)如果先写日志,但没有修改数据库,按日志文件恢复时只不过是多执行一次不必要的UNDO操作,并不会影响数据库的正确性
恢复策略
事务故障的恢复
- 反向扫描文件日志,查找该事务的更新操作。
- 对该事务的更新操作执行逆操作。即将日志记录中“更新前的值” 写入数据库。
插入操作, “更新前的值”为空,则相当于做删除操作 删除操作,“更新后的值”为空,则相当于做插入操作 若是修改操作,则相当于用修改前值代替修改后值 - 继续反向扫描日志文件,查找该事务的其他更新操作,并做同样处理。
- 如此处理下去,直至读到此事务的开始标记,事务故障恢复就完成了。 系统故障的恢复
系统故障造成数据库不一致状态的原因 未完成事务对数据库的更新已写入数据库 已提交事务对数据库的更新还留在缓冲区没来得及写入数据库 恢复方法 Undo 故障发生时未完成的事务 Redo 已完成的事务 系统故障的恢复由系统在重新启动时自动完成,不需要用户干预 系统故障的恢复步骤 - 正向扫描日志文件
- 对撤销(Undo)队列事务进行撤销(UNDO)处理
- 对重做(Redo)队列事务进行重做(REDO)处理
介质故障的恢复
恢复步骤
重装数据库
装入有关的日志文件副本,重做已完成的事务。
检查点
周期性地执行如下操作:建立检查点,保存数据库状态。
具体步骤是:
1.将当前日志缓冲区中的所有日志记录写入磁盘的日志文件上
2.在日志文件中写入一个检查点记录
3.将当前数据缓冲区的所有数据记录写入磁盘的数据库中
4.把检查点记录在日志文件中的地址写入一个重新开始文件
使用检查点方法可以改善恢复效率
当事务T在一个检查点之前提交:
使用检查点的恢复步骤
1.从重新开始文件中找到最后一个检查点记录在日志文件中的地址,由该地址在日志文件中找到最后一个检查点记录
2.由该检查点记录得到检查点建立时刻所有正在执行的事务清单ACTIVE-LIST
3.从检查点开始正向扫描日志文件,直到日志文件结束
4.对UNDO-LIST中的每个事务执行UNDO操作
镜像
为避免硬盘介质出现故障影响数据库的可用性,许多DBMS提供了数据库映像(mirror)功能用于数据库恢复。
将整个数据库或其中的关键数据复制到另一个磁盘上,每当主数据库更新时,DBMS自动把更新后的数据复制过去,由DBMS自动保证镜像数据与主数据库的一致性。一旦出现介质故障,可由镜像磁盘继续提供使用,同时DBMS自动利用磁盘数据进行数据库的恢复,不需要关闭系统和重装数据库副本。
在没有出现故障时,数据库镜像还可以用于并发操作,即当一个用户对数据库加排它锁修改数据时,其他用户可以读镜像数据库上的数据,而不必等待该用户释放锁。
由于数据库镜像是通过复制数据实现的,频繁地赋值数据自然会降低系统运行效率。因此在实际应用中用户往往只选择对关键数据和日志文件进行镜像。
小结:
常用恢复技术
事务故障的恢复
系统故障的恢复
介质故障的恢复
提高恢复效率的技术
检查点技术
镜像技术
并发控制
多用户数据库:允许多个用户同时使用的数据库(订票系统)
不同的多事务执行方式:
单处理机系统中,事务的并发执行实际上是这些并行事务的并行操作轮流交叉运行(不是真正的并发,但是提高了系统效率)
3.同时并发方式:
多处理机系统中,每个处理机可以运行一个事务,多个处理机可以同时运行多个事务,实现多个事务真正的并行运行
并发执行带来的问题:
概述
并发操作带来的数据不一致性包括
记号:W(x)写数据x R(x)读数据x
并发控制机制的任务:
并发控制的主要技术
封锁
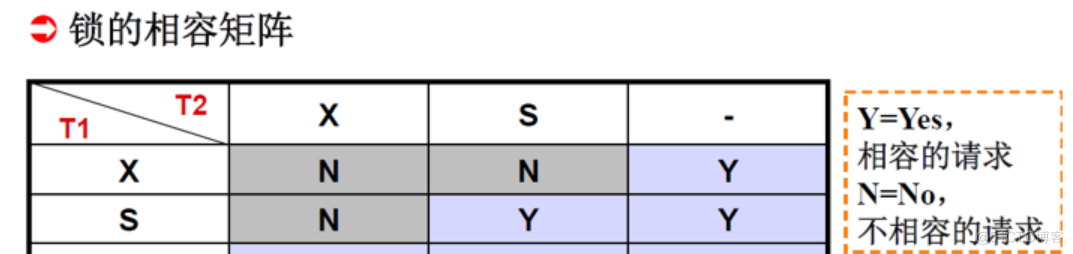
封锁:封锁就是事务T在对某个数据对象(例如表、记录等)操作之前,先向系统发出请求,对其加锁。加锁后事务T就对该数据对象有了一定的控制,在事务T释放它的锁之前,其它的事务不能更新此数据对象
确切的控制由封锁的类型决定
基本的封锁类型有两种:排它锁(X锁,exclusive locks)、共享锁(S 锁,share locks)
排它锁又称写锁,对A加了排它锁之后,其他事务不能对A加 任何类型的锁(排斥读和写)
共享锁又称读锁,对A加了共享锁之后,其他事务只能对A加S锁,不能加X锁(只排斥写)
(很重要)
封锁协议
在运用X锁和S锁对数据对象加锁时,需要约定一些规则:封锁协议(Locking Protocol)
何时申请X锁或S锁、持锁时间、何时释放
对封锁方式制定不同的规则,就形成了各种不同的封锁协议。
常用的封锁协议:三级封锁协议
三级封锁协议在不同程度上解决了并发问题,为并发操作的正确调度提供一定的保证。
1、一级封锁协议
事务T在修改数据R之前,必须先对其加X锁,直到事务结束(commit/rollback)才释放。
一级封锁协议可以防止丢失修改
如果是读数据,不需要加锁的,所以它不能保证可重复读和不读“脏”数据。
2、 二级封锁协议
二级封锁协议除了可以防止丢失修改,还可以防止读脏数据
由于读完数据即释放S锁,不能保证不可重复读
3、三级封锁协议:
三级封锁协议除了可以防止丢失修改和读脏数据外,还防止了不可重复读
三级封锁协议的主要区别是什么操作需要申请锁,何时释放锁。封锁协议越高,一致性程度越高。
饥饿
饥饿:事务T1封锁了数据R,事务T2又请求封锁R,于是T2等待。T3也请求封锁R,当T1释放了R上的封锁之后,系统首先批准了T3的请求,T2仍然等待。 T4又请求封锁R,当T3释放了R上的封锁之后系统又批准了T4的请求……T2有可能永远等待,这就是饥饿的情形
避免饥饿的方法:先来先服务
当多个事务请求封锁同一数据对象时,按请求封锁的先后次序对这些事务排队
该数据对象上的锁一旦释放,首先批准申请队列中第一个事务获得锁。
死锁
死锁:事务T1封锁了数据R1, T2封锁了数据R2。 T1又请求封锁R2,因T2已封锁了R2,于是T1等待T2释放R2上的锁。 接着T2又申请封锁R1,因T1已封锁了R1,T2也只能
等待T1释放R1上的锁。 这样T1在等待T2,而T2又在等待T1,T1和T2两个事务永远不能结束,形成死锁。
解决死锁的方法:预防、诊断和解除
1、死锁的预防
产生死锁的原因是两个或多个事务都已经封锁了一些数据对象,然后又都请求对已被其他事务封锁的数据对象加锁,从而出现死等待。
预防死锁发生就是破坏产生死锁的条件
方法
1)一次封锁法:
2)顺序封锁法:
维护成本:数据库系统中的封锁对象极多,并且在不断地变化
难以实现:很难实现确定每一个事务要封锁哪些对象
DBMS普通采用的诊断并解除死锁的方法
2、死锁的诊断和解除
等待图是一个有向图G=(T,U),T为结点的集合,每个结点表示正运行的事务, U为边的集合,每条边表示事务等待的情况。若T1等待T2,则T1、T2之间划一条有向边,从T1指向T2。
并发控制子系统周期性地(比如每隔数秒)生成事务等待图,检测事务。如果发现图中存在回路,则表示系统中出现了死锁。
解除死锁:并发控制子系统选择一个处理死锁代价最小的事务,将其撤销。
释放该事务持有的所有的锁,使其他事务能够继续运行下去。
串行调度
什么样的调度是正确的?串行调度是正确的。
(执行结果等价于串行调度的调度也是正确的,这样的调度称为可串行化调度。) 可串行化调度
定义:多个事务的并发执行是正确的,当且仅当其结果与按某一次序串行地执行这些事务时的结果相同,称这种调度策略为可串行化调度(serializable)。
可串行性是并发事务正确调度的准则。按这个准则规定,一个给定的并发调度,当且仅当它是可串行化的,才认为是正确调度。
冲突可串行化调度
判断可串行化调度的充分条件
冲突操作:不同的事务对同一个数据的读写和写写操作。
不同事务的冲突操作和同一事务的两个操作是不能交换的。
Ri(x)和Wj(x)不可交换,Wi(x)和Wj(x)不可交换
冲突可串行化调度:
一个调度Sc在保证冲突操作的次序不变的情况下,通过交换两个事务不冲突操作的次序得到另一个调度Sc’,如果Sc’是串行的,称调度Sc为冲突可串行化的调度。
两段锁协议
DBMS的并发控制机制必须提供一定的手段来保证调度是可串行化的。目前DBMS普遍采用两段锁协议(TwoPhase Locking,简称2PL)的方法来显示并发调度的可串行性。
两段锁协议是指所有事务必须分两个阶段对数据对象进行加锁和解锁。
“两段”锁的含义:事务分为两个阶段
第一阶段是获得封锁,也称为扩展阶段
事务可以申请获得任何数据对象上的任何类型的锁,但是不能释放任何锁
第二阶段是释放封锁,也称为收缩阶段
事务可以释放任何数据对象上的任何类型的锁,但是不能再申请任何锁
事务遵守两段锁协议是可串行化调度的充分条件,而不是必要条件。
若并发事务都遵守两段锁协议,则对这些事务的任何并发调度策略都是可串行化的
若并发事务的一个调度是可串行化的,不一定所有事务都符合两段锁协议
两段锁协议与防止死锁的一次封锁法
一次封锁法要求每个事务必须一次将所有要使用的数据全部加锁,否则就不能继续执行,因此一次封锁法遵守两段锁协议
但是两段锁协议并不要求事务必须一次将所有要使用的数据全部加锁,因此遵守两段锁协议的事务可能发生死锁
封锁的粒度
封锁对象的大小称为封锁粒度(granularity)。
封锁的对象可以是逻辑单元(属性值、属性值集合、元组、关系、索引项、数据库),也可以是物理单元(页、物理记录)。
选择封锁粒度原则:
越小;
封锁的粒度越小,并发度较高,但系统开销也就越大
意向锁
意向锁:如果对一个节点加意向锁,则可说明该节点的下层节点正在被加锁;对任一节点加锁时,必须先对它的上层节点加意向锁。
例如,对任一元组加锁时,必须先对它所在的数据库和关系加意向锁。
三种常用的意向锁:意向共享锁(Intent Share Lock,IS锁);意向排它锁(Intent Exclusive Lock,IX锁);共享意向排它锁(Share Intent Exclusive Lock,SIX锁)。
1、IS锁
如果对一个数据对象加IS锁,表示它的子节点拟加S锁。
例如:事务T1要对R1中某个元组加S锁,则要首先对关系R1和数据库加IS锁
2、IX锁
如果对一个数据对象加IX锁,表示它的子节点拟加X锁。
例如:事务T1要对R1中某个元组加X锁,则要首先对关系R1和数据库加IX锁
3、SIX锁
如果对一个数据对象加SIX锁,表示对它加S锁,再加IX锁,即SIX = S + IX。
例如:对某个表加SIX锁,则表示该事务要读整个表(所以要对该表加S锁),同
时会更新个别元组(所以要对该表加IX锁)
意向锁的强度: 锁的强度是指它对其他锁的排斥程度。一个事务在申请封锁时以强锁代替弱锁是安全的,反之则不然。
具有意向锁的多粒度封锁方法
申请封锁时应该按自上而下的次序进行
释放封锁时则应该按自下而上的次序进行
优点:
在实际的DBMS产品中得到广泛应用。
其他并发控制
并发控制的方法除了封锁技术外,还有时间戳方法、乐观控制法和多版本并发控制。
时间戳方法:给每一个事务盖上一个时标,即事务开始的时间。每个事务具有唯一的时间戳,并按照这个时间戳来解决事务的冲突操作。如果发生冲突操作,就回滚到具有较早时间戳的事务,以保证其他事务的正常执行,被回滚的事务被赋予新的时间戳被从头开始执行。
乐观控制法认为事务执行时很少发生冲突,所以不对事务进行特殊的管制,而是让它自由执行,事务提交前再进行正确性检查。如果检查后发现该事务执行中出现过冲突并影响了可串行性,则拒绝提交并回滚该事务。又称为验证方法
多版本控制是指在数据库中通过维护数据对象的多个版本信息来实现高效并发的一种策略。
总结:
学霸笔记(下)希望能对你有所帮助,明天更新……一起期待吧~
边栏推荐
- sql中批量删除数据---实体中的集合
- The foreground downloads network pictures without background processing
- centos8安装mysql报错:The GPG keys listed for the “MySQL 8.0 Community Server“ repository are already ins
- 将截断字符串或二进制数据
- Web开发小妙招:巧用ThreadLocal规避层层传值
- 一文带你走进【内存泄漏】
- Yiwen takes you into [memory leak]
- 建議收藏!!Flutter狀態管理插件哪家强?請看島上碼農的排行榜!
- Shortcut keys commonly used in idea
- FLIR blackfly s industrial camera: configure multiple cameras for synchronous shooting
猜你喜欢
低代码平台中的数据连接方式(上)
TiFlash 源码阅读(四)TiFlash DDL 模块设计及实现分析

【服务器数据恢复】raid损坏导致戴尔某型号服务器崩溃的数据恢复案例
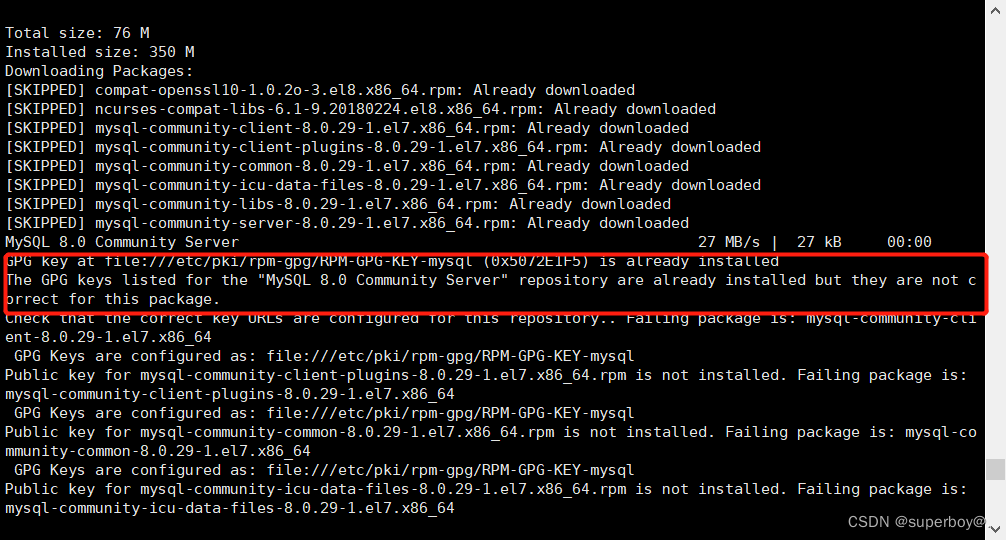
centos8安装mysql报错:The GPG keys listed for the “MySQL 8.0 Community Server“ repository are already ins

BigDecimal 的正确使用方式
刨析《C语言》【进阶】付费知识【二】

微服务架构介绍

Blue Bridge Cup 2022 13th provincial competition real topic - block painting
![[unique] what is the [chain storage structure]?](/img/cd/be18c65b9d7faccc3c9b18e3b2ce8e.png)
[unique] what is the [chain storage structure]?
蓝桥杯2022年第十三届省赛真题-积木画
随机推荐
JVM memory model
Domestic images of various languages, software and systems. It is enough to collect this warehouse: Thanks mirror
Word wrap when flex exceeds width
Unicode string converted to Chinese character decodeunicode utils (tool class II)
uva 1401 dp+Trie
Public key \ private SSH avoid password login
How can reinforcement learning be used in medical imaging? A review of Emory University's latest "reinforcement learning medical image analysis", which expounds the latest RL medical image analysis co
Cisp-pte practice explanation (II)
MySQL execution process and sequence
ROS学习(26)动态参数配置
FLIR blackfly s industrial camera: auto exposure configuration and code
centos8安装mysql报错:The GPG keys listed for the “MySQL 8.0 Community Server“ repository are already ins
ROS learning (21) robot slam function package -- installation and testing of orbslam
NPM install compilation times "cannot read properties of null (reading 'pickalgorithm')“
@Before, @after, @around, @afterreturning execution sequence
强化学习如何用于医学影像?埃默里大学最新《强化学习医学影像分析》综述,阐述最新RL医学影像分析概念、应用、挑战与未来方向
使用Ceres进行slam必须要弄清楚的几个类和函数
Big guys gather | nextarch foundation cloud development meetup is coming!
Stm32f4 --- general timer update interrupt
Input and output of C language pointer to two-dimensional array