当前位置:网站首页>MMDetection3D加载毫米波雷达数据
MMDetection3D加载毫米波雷达数据
2022-07-06 18:59:00 【naca yu】

前言
mmdetection3d没有提供radar数据的读取,仅实现了对于LiDAR和Camera的数据读取、处理,因此需要根据LiDAR的数据处理流程进行改进,创建一套适合于radar数据处理的流程,本次处理流程部分参考了FUTR3D提供的思路,并对其进行了部分改进。
在开始之前,首先要知道关于mmdetection3d的如下说明:
- mmdetection3d的NuScenes数据集坐标系以LiDAR坐标系为参考,包括bbox属性、各传感器到lidar的投影矩阵;
- mmdetection3d的雷达投影坐标系和其他坐标系都通过了一定修改,为了方便不同传感器的目标位姿统一;
- NuScenes的数据标注中,实例的标注以该传感器为准,这里的实例标注是在LIDAR下的坐标;
- RADAR数据本身带有[x,y,z=0]的属性,通过坐标转换矩阵可以直接将其转换到LIDAR下[x,y,z]并直接作为LIDAR点云使用;
基于以上背景知识,我们开始介绍Radar数据加载的实现流程。
实现
1.1 生成.pkl数据
- create_data.py文件中:
_fill_trainval_infos()在mmdetection3d中负责生成.pkl文件,这个文件包括我们需要的一切数据。
# load data tranforlation matrix and data path
def _fill_trainval_infos(nusc,
train_scenes,
val_scenes,
test=False,
max_sweeps=10):
train_nusc_infos = []
val_nusc_infos = []
for sample in mmcv.track_iter_progress(nusc.sample):
lidar_token = sample['data']['LIDAR_TOP']
sd_rec = nusc.get('sample_data', sample['data']['LIDAR_TOP'])
cs_record = nusc.get('calibrated_sensor',
sd_rec['calibrated_sensor_token'])
pose_record = nusc.get('ego_pose', sd_rec['ego_pose_token'])
# boxes对应多个box的类
lidar_path, boxes, _ = nusc.get_sample_data(lidar_token)
mmcv.check_file_exist(lidar_path)
info = {
'token': sample['token'],
'cams': dict(),
'radars': dict(),
'lidar2ego_translation': cs_record['translation'],
'lidar2ego_rotation': cs_record['rotation'],
'ego2global_translation': pose_record['translation'],
'ego2global_rotation': pose_record['rotation'],
'timestamp': sample['timestamp'],
}
# lidar and global translation to each
l2e_r = info['lidar2ego_rotation']
l2e_t = info['lidar2ego_translation']
e2g_r = info['ego2global_rotation']
e2g_t = info['ego2global_translation']
l2e_r_mat = Quaternion(l2e_r).rotation_matrix
e2g_r_mat = Quaternion(e2g_r).rotation_matrix
# obtain 6 image's information per frame
camera_types = [
'CAM_FRONT',
'CAM_FRONT_RIGHT',
'CAM_FRONT_LEFT',
'CAM_BACK',
'CAM_BACK_LEFT',
'CAM_BACK_RIGHT',
]
for cam in camera_types:
cam_token = sample['data'][cam]
cam_path, _, cam_intrinsic = nusc.get_sample_data(cam_token)
# camera to lidar_top matrix
cam_info = obtain_sensor2top(nusc, cam_token, l2e_t, l2e_r_mat,
e2g_t, e2g_r_mat, cam)
cam_info.update(cam_intrinsic=cam_intrinsic)
info['cams'].update({
cam: cam_info})
# radar load
radar_names = [
'RADAR_FRONT',
'RADAR_FRONT_LEFT',
'RADAR_FRONT_RIGHT',
'RADAR_BACK_LEFT',
'RADAR_BACK_RIGHT'
]
for radar_name in radar_names:
radar_token = sample['data'][radar_name]
radar_rec = nusc.get('sample_data', radar_token)
sweeps = []
# load multi-radar sweeps into sweeps once sweeps < 5
while len(sweeps) < 5:
if not radar_rec['prev'] == '':
radar_path, _, radar_intrin = nusc.get_sample_data(radar_token)
# obtain translation matrix from radar to lidar_top
radar_info = obtain_sensor2top(nusc, radar_token, l2e_t, l2e_r_mat,
e2g_t, e2g_r_mat, radar_name)
sweeps.append(radar_info)
radar_token = radar_rec['prev']
radar_rec = nusc.get('sample_data', radar_token)
else:
radar_path, _, radar_intrin = nusc.get_sample_data(radar_token)
radar_info = obtain_sensor2top(nusc, radar_token, l2e_t, l2e_r_mat,
e2g_t, e2g_r_mat, radar_name)
sweeps.append(radar_info)
# one radar correspond to serveral sweeps
# sweeps:[sweep1_dict, sweep2_dict...]
info['radars'].update({
radar_name: sweeps})
# 这里的annotation,是lidar坐标系下的annotaion
if not test:
annotations = [
nusc.get('sample_annotation', token)
for token in sample['anns']
]
locs = np.array([b.center for b in boxes]).reshape(-1, 3)
dims = np.array([b.wlh for b in boxes]).reshape(-1, 3)
rots = np.array([b.orientation.yaw_pitch_roll[0]
for b in boxes]).reshape(-1, 1)
velocity = np.array(
[nusc.box_velocity(token)[:2] for token in sample['anns']])
# valid_flag标志annotations有无pts
valid_flag = np.array(
[(anno['num_lidar_pts'] + anno['num_radar_pts']) > 0
for anno in annotations],
dtype=bool).reshape(-1)
# convert velo from global to lidar
for i in range(len(boxes)):
velo = np.array([*velocity[i], 0.0])
velo = velo @ np.linalg.inv(e2g_r_mat).T @ np.linalg.inv(
l2e_r_mat).T
velocity[i] = velo[:2]
names = [b.name for b in boxes]
for i in range(len(names)):
if names[i] in NuScenesDataset.NameMapping:
names[i] = NuScenesDataset.NameMapping[names[i]]
names = np.array(names)
# update valid now
name_in_track = [_a in nus_categories for _a in names]
name_in_track = np.array(name_in_track)
valid_flag = np.logical_and(valid_flag, name_in_track)
# add instance_ids
instance_inds = [nusc.getind('instance', ann['instance_token']) for ann in annotations]
# we need to convert rot to SECOND format.
# -rot translate lidar coordinate and then concatenate them together
# 角度是以Π为单位
gt_boxes = np.concatenate([locs, dims, -rots - np.pi / 2], axis=1)
assert len(gt_boxes) == len(
annotations), f'{
len(gt_boxes)}, {
len(annotations)}'
info['gt_boxes'] = gt_boxes
info['gt_names'] = names
info['gt_velocity'] = velocity.reshape(-1, 2)
# 每个gt_boxes对应的num_lidar_pts用于过滤无点云目标
info['num_lidar_pts'] = np.array(
[a['num_lidar_pts'] for a in annotations])
# obtain radar info as lidar
info['num_radar_pts'] = np.array(
[a['num_radar_pts'] for a in annotations])
info['valid_flag'] = valid_flag
info['instance_inds'] = instance_inds
# 这里划分train_info & test_infos
if sample['scene_token'] in train_scenes:
train_nusc_infos.append(info)
else:
val_nusc_infos.append(info)
return train_nusc_infos, val_nusc_infos
- 这一步调用上一部分的函数生成dict后,通过create_nuscenes_infos()保存生成pkl文件
def create_nuscenes_infos(root_path,
info_prefix,
version='v1.0-trainval',
max_sweeps=10):
train_nusc_infos, val_nusc_infos = _fill_trainval_infos(
nusc, train_scenes, val_scenes, test, max_sweeps=max_sweeps)
metadata = dict(version=version)
if test:
print('test sample: {}'.format(len(train_nusc_infos)))
data = dict(infos=train_nusc_infos, metadata=metadata)
info_path = osp.join(root_path,
'{}_infos_test.pkl'.format(info_prefix))
mmcv.dump(data, info_path)
else:
print('train sample: {}, val sample: {}'.format(
len(train_nusc_infos), len(val_nusc_infos)))
data = dict(infos=train_nusc_infos, metadata=metadata)
info_path = osp.join(root_path,
'{}_infos_train.pkl'.format(info_prefix))
mmcv.dump(data, info_path)
data['infos'] = val_nusc_infos
info_val_path = osp.join(root_path,
'{}_infos_val.pkl'.format(info_prefix))
mmcv.dump(data, info_val_path)
1.2 读取pkl数据并构建dataset接口
- 节选部分,其中get_data_info()函数加载上一步生成的pkl文件,生成input_dict字典保存,以未入pipeline使用
@DATASETS.register_module()
class NuScenesDataset(Custom3DDataset):
def __init__(self,
ann_file,
pipeline=None,
data_root=None,
classes=None,
load_interval=1,
with_velocity=True,
modality=None,
box_type_3d='LiDAR',
filter_empty_gt=True,
test_mode=False,
eval_version='detection_cvpr_2019',
use_valid_flag=False):
self.load_interval = load_interval
self.use_valid_flag = use_valid_flag
super().__init__(
data_root=data_root,
ann_file=ann_file,
pipeline=pipeline,
classes=classes,
modality=modality,
box_type_3d=box_type_3d,
filter_empty_gt=filter_empty_gt,
test_mode=test_mode)
self.with_velocity = with_velocity
self.eval_version = eval_version
from nuscenes.eval.detection.config import config_factory
self.eval_detection_configs = config_factory(self.eval_version)
if self.modality is None:
self.modality = dict(
use_camera=False,
use_lidar=True,
use_radar=False,
use_map=False,
use_external=False,
)
def get_data_info(self, index):
info = self.data_infos[index]
input_dict = dict(
sample_idx=info['token'],
timestamp=info['timestamp'] / 1e6,
radar=info['radars'],
)
if self.modality['use_camera']:
image_paths = []
lidar2img_rts = []
intrinsics = []
extrinsics = []
for cam_type, cam_info in info['cams'].items():
image_paths.append(cam_info['data_path'])
# obtain lidar to image transformation matrix
lidar2cam_r = np.linalg.inv(cam_info['sensor2lidar_rotation'])
lidar2cam_t = cam_info[
'sensor2lidar_translation'] @ lidar2cam_r.T
lidar2cam_rt = np.eye(4)
lidar2cam_rt[:3, :3] = lidar2cam_r.T
lidar2cam_rt[3, :3] = -lidar2cam_t
intrinsic = cam_info['cam_intrinsic']
viewpad = np.eye(4)
viewpad[:intrinsic.shape[0], :intrinsic.shape[1]] = intrinsic
lidar2img_rt = (viewpad @ lidar2cam_rt.T)
lidar2img_rts.append(lidar2img_rt)
intrinsics.append(viewpad)
extrinsics.append(lidar2cam_rt.T)
# 添加图像信息
input_dict.update(
dict(
img_filename=image_paths,
lidar2img=lidar2img_rts,
intrinsic=intrinsics,
extrinsic=extrinsics,
))
if not self.test_mode:
annos = self.get_ann_info(index)
input_dict['ann_info'] = annos
return input_dict
1.3 构建pipeline处理数据
- 这一部分源自上一步自己定义的NuScenesDataset类的一个方法,作为方法于__ getitem __(self,index)中被调用,负责调用上一步的get_data_info()返回某个sample下的所有数据字典,并喂入pipeline中处理,返回处理完成后的数据于dataloader中使用。
def prepare_train_data(self, index):
"""Training data preparation. Args: index (int): Index for accessing the target data. Returns: dict: Training data dict of the corresponding index. """
# input_dict = dict(
# sample_idx=info['token'],
# timestamp=info['timestamp'] / 1e6,
# radar=info['radars'],
# anno = dict(
# gt_bboxes_3d=gt_bboxes_3d,
# gt_labels_3d=gt_labels_3d,
# gt_names=gt_names_3d)
# )
input_dict = self.get_data_info(index)
if input_dict is None:
return None
self.pre_pipeline(input_dict)
example = self.pipeline(input_dict)
if self.filter_empty_gt and \
(example is None or
~(example['gt_labels_3d']._data != -1).any()):
return None
return example
边栏推荐
- 1--新唐nuc980 NUC980移植 UBOOT,从外部mx25l启动
- 【森城市】GIS数据漫谈(二)
- Chang'an chain learning notes - certificate model of certificate research
- The boss is quarantined
- CDB PDB user rights management
- Halcon instance to opencvsharp (C openCV) implementation -- bottle mouth defect detection (with source code)
- 如何设计好接口测试用例?教你几个小技巧,轻松稿定
- 4 -- Xintang nuc980 mount initramfs NFS file system
- leetcode:5. Longest palindrome substring [DP + holding the tail of timeout]
- unity webgl自适应网页尺寸
猜你喜欢
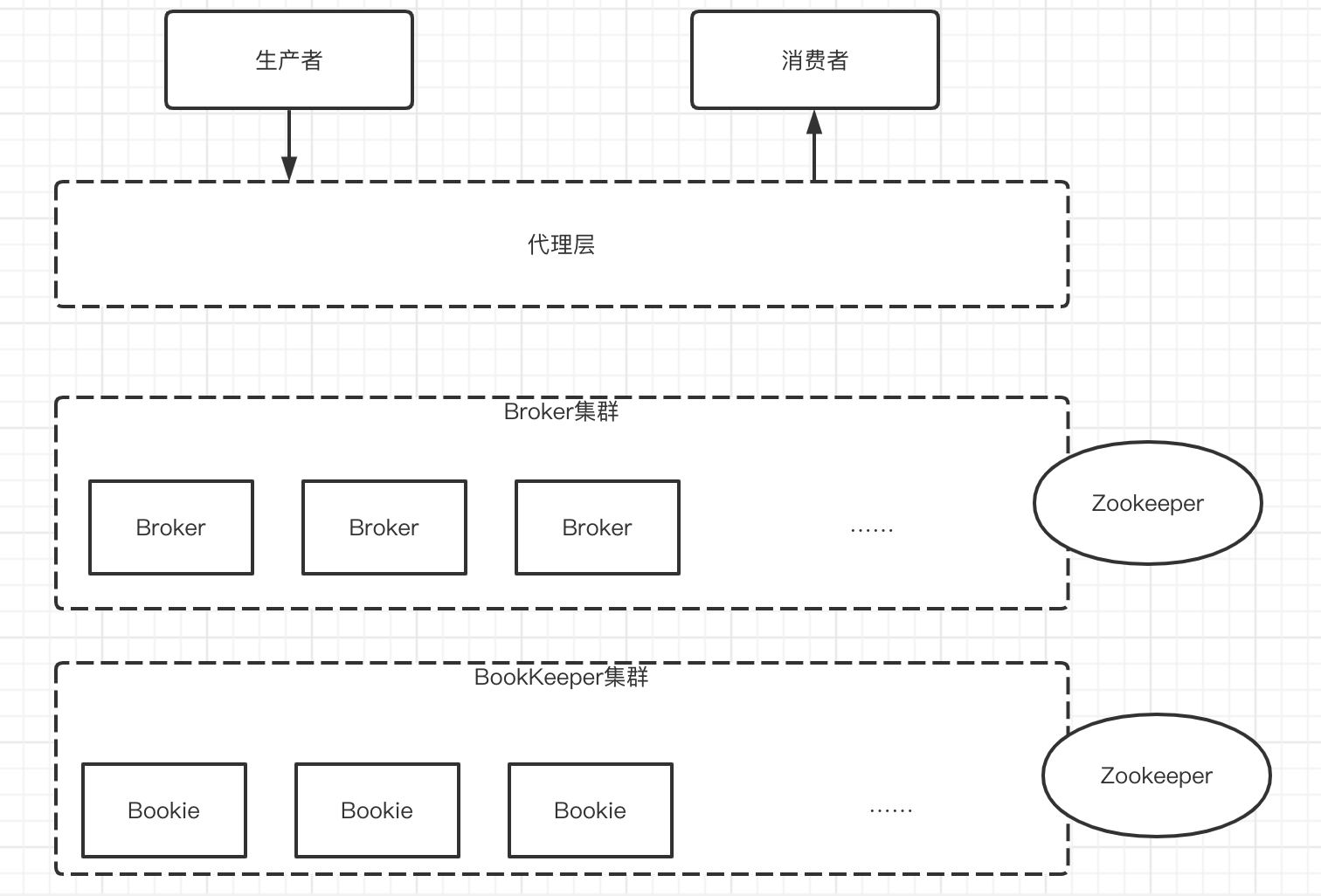
New generation cloud native message queue (I)
![[unity notes] screen coordinates to ugui coordinates](/img/e4/fc18dd9b4b0e36ec3e278e5fb3fd23.jpg)
[unity notes] screen coordinates to ugui coordinates
新一代云原生消息队列(一)
![leetcode:5. Longest palindrome substring [DP + holding the tail of timeout]](/img/62/d4d5428f69fc221063a4f607750995.png)
leetcode:5. Longest palindrome substring [DP + holding the tail of timeout]
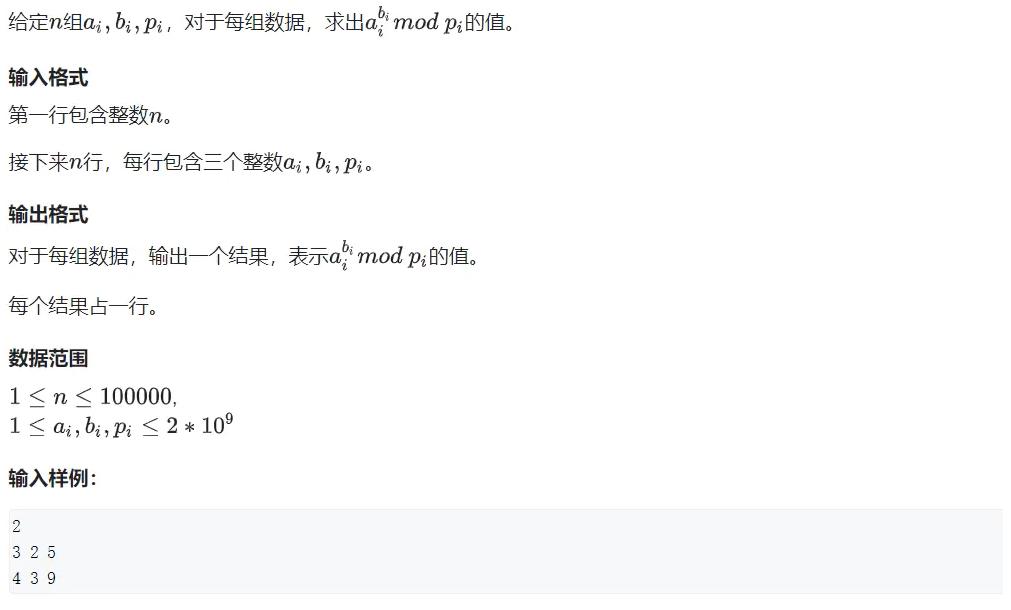
数论 --- 快速幂、快速幂求逆元
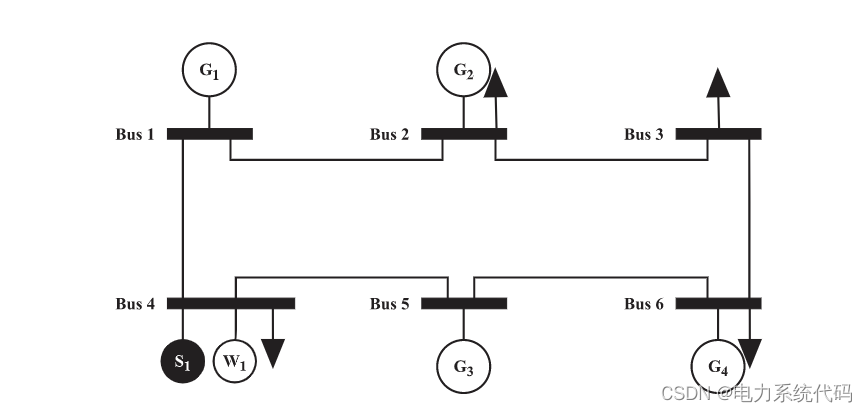
MATLB|具有储能的经济调度及机会约束和鲁棒优化

豆瓣平均 9.x,分布式领域的 5 本神书!
慧通编程入门课程 - 2A闯关

Web3's need for law
unity 自定义webgl打包模板
随机推荐
AWS学习笔记(一)
[paper reading | deep reading] anrl: attributed network representation learning via deep neural networks
【论文阅读|深读】 GraphSAGE:Inductive Representation Learning on Large Graphs
MySQL
How to build a 32core raspberry pie cluster from 0 to 1
TiFlash 源码阅读(四)TiFlash DDL 模块设计及实现分析
猿桌派第三季开播在即,打开出海浪潮下的开发者新视野
数论 --- 快速幂、快速幂求逆元
Use of pgpool II and pgpooladmin
[server data recovery] data recovery case of a Dell server crash caused by raid damage
STM32项目 -- 选题分享(部分)
数字滚动增加效果
MySQL --- 常用函数 - 字符串函数
【软件测试】最全面试问题和回答,全文背熟不拿下offer算我输
The boss is quarantined
Halcon实例转OpenCvSharp(C# OpenCV)实现--瓶口缺陷检测(附源码)
安德鲁斯—-多媒体编程
1个月增长900w+播放!总结B站顶流恰饭的2个新趋势
Recommended collection!! Which is the best flutter status management plug-in? Please look at the ranking list of yard farmers on the island!
A new path for enterprise mid Platform Construction -- low code platform