作者|[email protected]
编译|Flin
来源|analyticsvidhya
介绍
Fastai是一个流行的开源库,用于学习和练习机器学习以及深度学习。杰里米·霍华德(Jeremy Howard)和蕾切尔·托马斯(Rachel Thomas)创立了 fast.ai, 其目标是使深度学习资源更容易获得。fast.ai中提供的所有详尽的资源,例如课程,软件和研究论文都是完全免费的。
2020年8月,fastai_v2发布,该版本有望更快,更灵活地实现深度学习框架。在2020 fastai课程结合了机器学习和深入学习的核心概念。它还向用户介绍了模型生产和部署的重要方面。
在本文中,我将讨论fast.ai初学者课程的前三课中介绍的有关建立快速简单的图像分类模型的技术。在构建模型的同时,你还将学习如何轻松地为模型开发Web应用程序并将其部署到生产环境。
本文将遵循Jeremy在其课程中所采用的自上而下的教学方法。你将首先学习有关训练图像分类器的知识。稍后,将解释有关用于分类的模型的细节。要理解本文,你必须具备Python知识,因为fastai是用Python编写并基于PyTorch构建的。建议你在Google Colab或Gradient中运行此代码,因为我们需要GPU访问权限,而且fastai可以轻松安装在这两个平台上。
安装,导入和加载数据集
!pip install -Uqq fastbookimport fastbook
fastbook.setup_book()
from fastbook import *
from fastai.vision.widgets import *安装fastai并导入必要的库。如果你使用的是Colab,则必须提供对Google云端硬盘的访问权限以保存文件和图像。你可以从Kaggle和Bing图像搜索等来源下载任何图像数据集。Fast.ai也有大量的图像集合。我在本文中使用了来自 https://github.com/ieee8023/c... 的一组胸部X射线图像。
path = Path ('/content/gdrive/My Drive/Covid19images')将数据集位置的路径保存在Path()对象中。如果使用fast.ai数据集,则可以使用以下代码:
path = untar_data(URLs.PETS)/'images'这将从fastai PETS数据集集合中下载并提取图像。
检查图像路径并显示数据集中的一些样本图像。我已经为此使用了Python Imaging Library(PIL)。
path.ls
from PIL import Image
img = Image.open(path'/train/covid/1-s2.0-S1684118220300682-main.pdf-002-a2.png')
print(img.shape)
img.to_thumb(128,128)
在此图像分类问题中,我将训练模型,以将X射线图像分类为COVID或No COVID类。预处理数据集已放置在单独的COVID和No COVID文件夹中(来源:ChristianTutivénGálvez)。
如果你使用的是fast.ai数据集,请使用以下函数根据宠物的名称对图像进行分组:
def is_cat(x): return x[0].isupper()PETS是猫和狗图像的集合。Cat图片标有大写的第一个字母,因此很容易对其进行分类。
图像变换
图像变换是训练图像模型的关键步骤。它也称为数据扩充。为了避免模型过拟合,必须进行图像变换。可以使用多种方法来转换图像,例如调整大小,裁剪,压缩和填充。但是,压缩和填充会抢夺图像中的原始信息,并分别添加其他像素。因此,随机调整图像大小会产生良好的效果。
如以下示例所示,在此方法中,在每个时期都对每个图像的随机区域进行采样。这使模型可以了解每个图像的更多细节,从而获得更高的准确性。
要记住的另一个要点是,始终仅变换训练图像,而不修改验证图像。在fastai库中,默认情况下会处理此问题。
item_tfms=Resize(128, ResizeMethod.Squish))
item_tfms=Resize(128, ResizeMethod.Pad, pad_mode='zeros')
item_tfms=RandomResizedCrop(128, min_scale=0.3) - 30% of the image area is zoomed by specifying 0.3Fastai库通过aug_transforms函数提供了一组标准的扩充。如果图像尺寸均匀,可以批量应用,节省大量训练时间。
tfms = aug_transforms(do_flip = True, flip_vert = False, mult=2.0)
fastai中的DataLoaders类非常便于存储用于训练和验证模型的各种对象。如果要自定义训练期间要使用的对象,则可以将DataBlock类与DataLoaders结合使用。
data= ImageDataLoaders.from_folder(path,train = "train", valid_pct=0.2, item_tfms=Resize(128), batch_tfms=tfms, bs = 30, num_workers = 4)如果你在图元文件中定义了图像标签,则可以使用DataBlock将图像和标签分为两个不同的块,如下面的代码片段所示。将定义的数据块与数据加载器功能一起使用以访问图像。
Data = DataBlock( blocks=(ImageBlock, CategoryBlock), get_items=get_image_files,
splitter=RandomSplitter(valid_pct=0.2, seed=42), get_y=parent_label, item_tfms=Resize(128))
dls = Data.dataloaders(path)模型训练
为了训练该图像数据集,使用了预训练的CNN模型。这种方法称为转移学习。杰里米(Jeremy)建议使用预先训练的模型,以加快训练速度并提高准确性。这尤其适用于计算机视觉问题。
learn = cnn_learner(data, resnet34, metrics=error_rate)
learn.fine_tune(4)

使用ResNet34体系结构,并根据错误率验证结果。由于使用预先训练的模型进行训练,因此使用微调方法而不是对模型进行拟合。
你可以运行更多时期,并查看模型的性能。选择正确的时期数以避免过拟合。
你可以尝试使用准确性(准确性= 1-错误率)来验证模型性能,而不是使用error_rate。两者都用于验证模型的输出。在此示例中,保留了20%的数据用于验证。因此,该模型将仅对80%的数据进行训练。这是检查任何机器学习模型性能的非常关键的一步。你也可以通过更改ResNet层(选项为18、50、101和152)来运行此模型。除非你有一个大型数据集将产生准确的结果,否则这可能再次导致过拟合。
验证模型性能
模型性能可以通过不同的方式进行验证。一种流行的方法是使用混淆矩阵。矩阵的对角线值指示每种类别的正确预测,而其他单元格值指示许多错误的预测。
interp = ClassificationInterpretation.from_learner(learn)
interp.plot_confusion_matrix()
Fastai提供了一个有用的功能,可以根据最高丢失率查看错误的预测。该函数的输出指示每个图像的预测标签,目标标签,丢失率和概率值。高概率表示模型具有较高的置信度。它在0到1之间变化。高丢失率表示模型性能有多差。
interp.plot_top_losses(5, nrows=1, figsize = (25,5))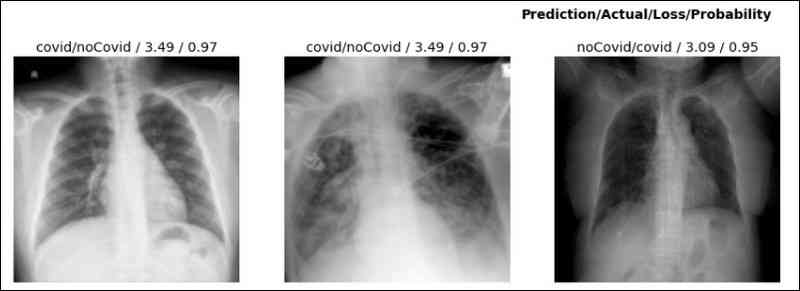
另一个很棒的Fastai功能, ImageClassifierCleaner(GUI),它可以通过删除故障图像或重命名其标签来清除故障图像。这非常有助于数据预处理,从而提高了模型的准确性。
杰里米(Jeremy)建议在对图像进行基本训练后再运行此功能,因为这可以了解数据集中异常的种类。
from fastai.vision.widgets import *
cleaner = ImageClassifierCleaner(learn)
cleaner保存和部署模型
训练完模型并对结果满意后,就可以部署模型了。要将模型部署到生产环境中,你需要保存模型体系结构以及对其进行训练的参数。为此,使用了导出方法。导出的模型另存为PKL文件,该文件是pickle(Python模块)创建的文件。
learn.export()从导出的文件中创建一个推理学习器,该学习器可用于将模型部署为应用程序。推理学习器一次预测一个新图像的输出。预测返回三个参数:预测类别,预测类别的索引以及每个类别的概率。
learn_inf = load_learner(path/'export.pkl')
learn_inf.predict("img")(‘noCovid’, tensor(1), tensor([5.4443e-05, 9.9995e-01])) – prediction
有多种方法可以创建用于部署模型的Web应用程序。最简单的方法之一是使用作为GUI组件的IPython小部件在Jupyter notebook中为应用程序创建所需的对象。
from fastai.vision.widgets import *
btn_upload = widgets.FileUpload()
out_pl = widgets.Output()
lbl_pred = widgets.Label()
设计应用程序元素后,请使用像Web应用程序一样运行Jupyter notebook的Voila来部署模型。它删除所有单元格输入,仅显示模型输出。要将notebook作为VoilàWeb应用程序查看,请将浏览器URL中的“notebook”一词替换为“ voila/render”。必须在包含受过训练的模型和IPython小部件的同一notebook中安装和执行Voila。
!pip install voila
!jupyter serverextension enable voila --sys-prefix结论
就这样,你已经使用fastai库构建并部署了一个很酷的图像分类器应用程序,只需八个步骤!这还只是我在本文中展示的冰山一角。有更多的fastai组件可用于与NLP和计算机视觉相关的各种深度学习用例,你可以探索这些组件。
以下是fastai学习资源,以及我的git repo,其中包含本文中解释的图像分类器的代码和图像。
Covid19 X射线图像分类器:包含本文中讨论的完整代码和数据集
涵盖了fast.ai课程中教授的所有课程
涵盖完整的fastai API文档
Fast.ai社区论坛
原文链接:https://www.analyticsvidhya.c...
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/