当前位置:网站首页>教你如何定位不合理的SQL?并优化之
教你如何定位不合理的SQL?并优化之
2022-08-04 00:05:00 【博学谷狂野架构师】
如何定位不合理的SQL
引言
在应用的开发过程中,由于初期数据量小,开发人员写 SQL 语句时更重视功能上的实现,但是当应用系统正式上线后,随着生产数据量的急剧增长,很多SQL语句开始逐渐显露出性能问题,对生产的影响也越来越大,此时这些有问题的SQL语句就成为整个系统性能的瓶颈,因此我们必须要对它们进行优化,本章将详细介绍在MySQL中优化SQL语句的方法。
当面对一个有SQL性能问题的数据库时,我们应该从何处入手来进行系统的分析,使得能够尽快定位问题SQL并尽快解决问题。
4.1 如何查看SQL执行频率
MySQL 客户端连接成功后,通过
-- 服务器状态信息
show [session|global] status;
命令可以提供服务器状态信息。show [session|global] status 可以根据需要加上参数“session”或者“global”来显示 session 级(当前连接)的统计结果和 global 级(自数据库上次启动至今)的统计结果。
如果不写,默认使用参数是“session”。
下面的命令显示了当前 session 中所有统计参数的值:
show status like 'Com_______';
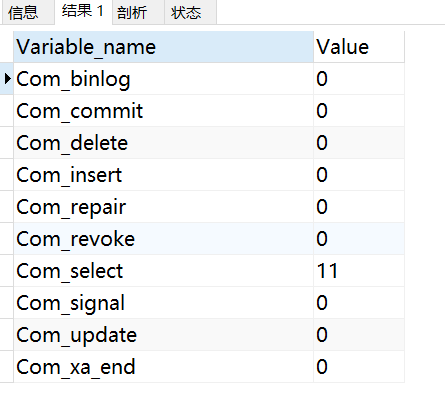
show status like 'Innodb_rows_%';
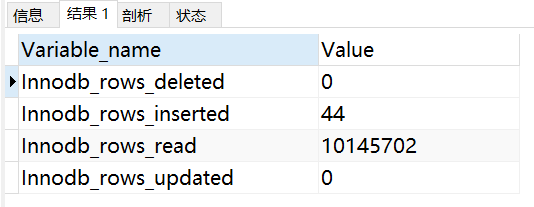
Com_xxx 表示每个 xxx 语句执行的次数,我们通常比较关心的是以下几个统计参数。
| 参数 | 含义 |
|---|---|
| Com_select | 执行 select 操作的次数,一次查询只累加 1。 |
| Com_insert | 执行 INSERT 操作的次数,对于批量插入的 INSERT 操作,只累加一次。 |
| Com_update | 执行 UPDATE 操作的次数。 |
| Com_delete | 执行 DELETE 操作的次数。 |
| Innodb_rows_read | select 查询返回的行数。 |
| Innodb_rows_inserted | 执行 INSERT 操作插入的行数。 |
| Innodb_rows_updated | 执行 UPDATE 操作更新的行数。 |
| Innodb_rows_deleted | 执行 DELETE 操作删除的行数。 |
| Connections | 试图连接 MySQL 服务器的次数。 |
| Uptime | 服务器工作时间。 |
| Slow_queries | 慢查询的次数。 |
Com_*** : 这些参数对于所有存储引擎的表操作都会进行累计。
Innodb_*** : 这几个参数只是针对InnoDB 存储引擎的,累加的算法也略有不同。
4.2 如何定位低效率SQL
以下两种方式:
慢查询日志(重要) : 通过慢查询日志定位那些执行效率较低的 SQL 语句,用–log-slow-queries[=file_name]选项启动时,mysqld 写一个包含所有执行时间超过 long_query_time 秒的 SQL 语句的日志文件。
tips:
关于慢查询SQL如何获取
参看上个章节
show processlist (重要) :
慢查询日志在查询结束以后才记录,所以在应用反映执行效率出现问题的时候查询慢查询日志并不能定位问题。
可以使用show processlist命令查看当前MySQL在进行的线程,包括线程的状态、是否锁表等,可以实时地查看 SQL 的执行情况,同时对一些锁表操作进行优化。

属性字段解释
1) id列,用户登录mysql时,系统分配的"connection_id",可以使用函数connection_id()查看
2) user列,显示当前用户。如果不是root,这个命令就只显示用户权限范围的sql语句
3) host列,显示这个语句是从哪个ip的哪个端口上发的,可以用来跟踪出现问题语句的用户
4) db列,显示这个进程目前连接的是哪个数据库
5) command列,显示当前连接的执行的命令,一般取值为休眠(sleep),查询(query),连接(connect)等
6) time列,显示这个状态持续的时间,单位是秒
7) state列,显示使用当前连接的sql语句的状态,很重要的列。
state描述的是语句执行中的某一个状态。一个sql语句,以查询为例,可能需要经过copying to tmp table、sorting result、sending data等状态才可以完成
8) info列,显示这个sql语句,是判断问题语句的一个重要依据
4.3 使用explain分析执行计划
-- explain 分析执行计划
explain SELECT * FROM product_list WHERE store_name = '联想北达兴科专卖店';

| 字段 | 含义 |
|---|---|
| id | select查询的序列号,是一组数字,表示的是查询中执行select子句或者是操作表的顺序。 |
| select_type | 表示 SELECT 的类型,常见的取值有 SIMPLE(简单表,即不使用表连接或者子查询)、PRIMARY(主查询,即外层的查询)、UNION(UNION 中的第二个或者后面的查询语句)、SUBQUERY(子查询中的第一个 SELECT)等 |
| table | 输出结果集的表 |
| partitions | 匹配的分区 |
| type | 表示表的连接类型,性能由好到差的连接类型为( system —> const -----> eq_ref ------> ref -------> ref_or_null----> index_merge —> index_subquery -----> range -----> index ------> all ) |
| possible_keys | 表示查询时,可能使用的索引 |
| key | 表示实际使用的索引 |
| key_len | 索引字段的长度 |
| rows | 扫描行的数量 |
| filtered | 按表条件过滤的行百分比 |
| extra | 执行情况的说明和描述 |
4.3.1 环境准备
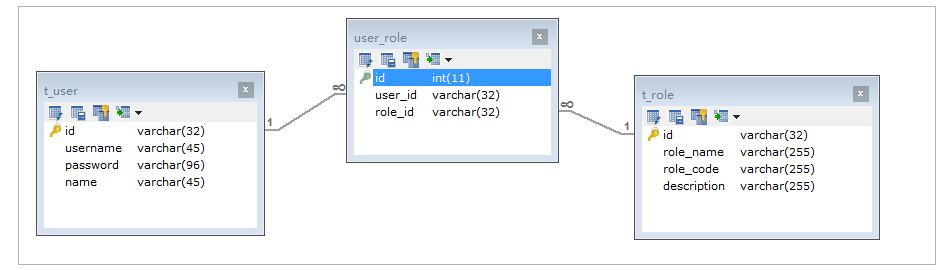
CREATE TABLE `t_role` (
`id` varchar(32) NOT NULL,
`role_name` varchar(255) DEFAULT NULL,
`role_code` varchar(255) DEFAULT NULL,
`description` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `unique_role_name` (`role_name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `t_user` (
`id` varchar(32) NOT NULL,
`username` varchar(45) NOT NULL,
`password` varchar(96) NOT NULL,
`name` varchar(45) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `user_role` (
`id` int(11) NOT NULL auto_increment ,
`user_id` varchar(32) DEFAULT NULL,
`role_id` varchar(32) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_role_user` (`role_id`,`user_id`),
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into `t_user` (`id`, `username`, `password`, `name`) values('1','super','$2a$10$TJ4TmCdK.X4wv/tCqHW14.w70U3CC33CeVncD3SLmyMXMknstqKRe','超级管理员');
insert into `t_user` (`id`, `username`, `password`, `name`) values('2','admin','$2a$10$TJ4TmCdK.X4wv/tCqHW14.w70U3CC33CeVncD3SLmyMXMknstqKRe','系统管理员');
insert into `t_user` (`id`, `username`, `password`, `name`) values('3','itcast','$2a$10$8qmaHgUFUAmPR5pOuWhYWOr291WJYjHelUlYn07k5ELF8ZCrW0Cui','test02');
insert into `t_user` (`id`, `username`, `password`, `name`) values('4','stu1','$2a$10$pLtt2KDAFpwTWLjNsmTEi.oU1yOZyIn9XkziK/y/spH5rftCpUMZa','学生1');
insert into `t_user` (`id`, `username`, `password`, `name`) values('5','stu2','$2a$10$nxPKkYSez7uz2YQYUnwhR.z57km3yqKn3Hr/p1FR6ZKgc18u.Tvqm','学生2');
insert into `t_user` (`id`, `username`, `password`, `name`) values('6','t1','$2a$10$TJ4TmCdK.X4wv/tCqHW14.w70U3CC33CeVncD3SLmyMXMknstqKRe','老师1');
INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES('5','学生','student','学生');
INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES('7','老师','teacher','老师');
INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES('8','教学管理员','teachmanager','教学管理员');
INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES('9','管理员','admin','管理员');
INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES('10','超级管理员','super','超级管理员');
INSERT INTO user_role(id,user_id,role_id) VALUES(NULL, '1', '5'),(NULL, '1', '7'),(NULL, '2', '8'),(NULL, '3', '9'),(NULL, '4', '8'),(NULL, '5', '10') ;
4.3.2 explain 之 id
id 字段是 select查询的序列号,是一组数字,表示的是查询中执行select子句或者是操作表的顺序。
id 情况有三种 :
1) id 相同表示加载表的顺序是从上到下。
explain select * from t_role r, t_user u, user_role ur where r.id = ur.role_id and u.id = ur.user_id ;

2) id 不同id值越大,优先级越高,越先被执行。
EXPLAIN SELECT * FROM t_role WHERE id = (SELECT role_id FROM user_role WHERE user_id = (SELECT id FROM t_user WHERE username = 'stu1'))

3) id 有相同,也有不同,同时存在。id相同的可以认为是一组,从上往下顺序执行;在所有的组中,id的值越大,优先级越高,越先执行。
EXPLAIN SELECT * FROM t_role r , (SELECT * FROM user_role ur WHERE ur.`user_id` = '2') a WHERE r.id = (select role.id from t_user, user_role role where role.id = 10) ;

4.3.3 explain 之 select_type
表示 SELECT 的类型,常见的取值,如下表所示:
EXPLAIN SELECT * FROM t_role WHERE id = (SELECT role_id FROM user_role WHERE user_id = (SELECT id FROM t_user WHERE username = 'stu1'));

| select_type | 含义 |
|---|---|
| SIMPLE | 简单的select查询,查询中不包含子查询或者UNION |
| PRIMARY | 查询中若包含任何复杂的子查询,最外层查询标记为该标识 |
| SUBQUERY | 在SELECT 或 WHERE 列表中包含了子查询 |
| DERIVED | 在FROM 列表中包含的子查询,被标记为 DERIVED(衍生) MYSQL会递归执行这些子查询,把结果放在临时表中 |
| UNION | 若第二个SELECT出现在UNION之后,则标记为UNION ; 若UNION包含在FROM子句的子查询中,外层SELECT将被标记为 : DERIVED |
| UNION RESULT | 从UNION表获取结果的SELECT |
4.3.4 explain 之 table
展示这一行的数据是关于哪一张表的
EXPLAIN SELECT * FROM t_role WHERE id = (SELECT role_id FROM user_role WHERE user_id = (SELECT id FROM t_user WHERE username = 'stu1'));

4.3.5 explain 之 type
EXPLAIN SELECT * FROM t_role WHERE id = (SELECT role_id FROM user_role WHERE user_id = (SELECT id FROM t_user WHERE username = 'stu1'));

type 显示的是访问类型,是较为重要的一个指标,可取值为:
| type | 含义 |
|---|---|
| NULL | MySQL不访问任何表,索引,直接返回结果 |
| system | 表只有一行记录(等于系统表),这是const类型的特例,一般不会出现 |
| const | 表示通过索引一次就找到了,const 用于比较primary key 或者 unique 索引。因为只匹配一行数据,所以很快。如将主键置于where列表中,MySQL 就能将该查询转换为一个常量。const会将 “主键” 或 “唯一” 索引的所有部分与常量值进行比较 |
| eq_ref | 类似ref,区别在于使用的是唯一索引,使用主键的关联查询,关联查询出的记录只有一条。常见于主键或唯一索引扫描 |
| ref | 非唯一性索引扫描,返回匹配某个单独值的所有行。本质上也是一种索引访问,返回所有匹配某个单独值的所有行(多个) |
| range | 只检索给定返回的行,使用一个索引来选择行。 where 之后出现 between , < , > , in 等操作。 |
| index | index 与 ALL的区别为 index 类型只是遍历了索引树, 通常比ALL 快, ALL 是遍历数据文件。 |
| all | 将遍历全表以找到匹配的行 |
结果值从最好到最坏依次是:
NULL > system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
system > const > eq_ref > ref > range > index > ALL
一般来说, 我们需要保证查询至少达到 range 级别, 最好达到ref 。
4.3.6 explain 之 key
possible_keys : 显示可能应用在这张表的索引, 一个或多个。
key : 实际使用的索引, 如果为NULL, 则没有使用索引。
key_len : 表示索引中使用的字节数。len=3*n+2(n为索引字段的长度)
EXPLAIN select * from t_role where role_name = '超级管理员';
select 255 * 3 + 2; -- role_name VARCHAR(255)

4.3.7 explain 之 rows
扫描行的数量。
4.3.8 explain 之 extra
其他的额外的执行计划信息,在该列展示 。
EXPLAIN select u.username from t_user u order by u.username desc;

| extra | 含义 |
|---|---|
| using filesort | 说明mysql会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取, 称为 “文件排序”, 效率低。 |
| using temporary | 使用了临时表保存中间结果,MySQL在对查询结果排序时使用临时表。常见于 order by 和 group by; 效率低 |
| using index | 表示相应的select操作使用了覆盖索引, 避免访问表的数据行, 效率不错。 |
专注Java技术干货分享,欢迎志同道合的小伙伴,一起交流学习
边栏推荐
- HNUCM 您好中国
- 全面讲解 Handler机制原理解析 (小白必看)
- The Beijing E-sports Metaverse Forum was successfully held
- Justin Sun: Web3.0 and the Metaverse will assist mankind to enter the online world more comprehensively
- 米哈游--测试开发提前批
- "Miscellaneous" barcode by Excel as a string
- HNUCM 2022年暑假ACM搜索专项练习
- Justin Sun was invited to attend the 36氪 Yuan Universe Summit and delivered a keynote speech
- XSLT – 服务器端概述
- leetcode/子串中不能有重复字符的最长子串
猜你喜欢

伦敦银最新均线分析系统怎么操作?
A simple understanding of TCP, learn how to shake hands, wave hands and various states
带你造轮子,自定义一个随意拖拽可吸边的悬浮View组件
In V8 how arrays (with source code, picture and text easier to understand)
现货白银需要注意八大事项

Three.js入门详解
七夕活动浪漫上线,别让网络拖慢和小姐姐的开黑时间
响应式织梦模板塑身瑜伽类网站
射频芯片(RFIC)的协议之5G及其调制
Using matlab to solve the linear optimization problem based on matlab dynamic model of learning notes _11 】 【
随机推荐
The Chinese Valentine's Day event is romantically launched, don't let the Internet slow down and miss the dark time
[Miscellaneous] How to install the specified font into the computer and then use the font in the Office software?
Graph-node:创建一个新的subgraph
Nanoprobes Alexa Fluor 488 FluoroNanogold 偶联物
免费的公共WiFi不要乱连,遭中间人攻击了吧?
OpenCV 图像拼接
3D Semantic Segmentation - 2DPASS
北京电竞元宇宙论坛活动顺利召开
越来越火的图数据库到底能做什么?
rsync 基础用法
(PC+WAP)织梦模板螺钉手柄类网站
XSLT – 编辑 XML概述
After building the pytorch environment, the pip and conda commands cannot be used
HNUCM 2022年暑假ACM搜索专项练习
Shell编程之循环语句与函数
响应式织梦模板塑身瑜伽类网站
MPLS Comprehensive Experiment
689. 三个无重叠子数组的最大和
Apple told Qualcomm: I bought a new campus for $445 million and may plan to speed up self-development of baseband chips
第1章:初识数据库与MySQL----MySQL安装