当前位置:网站首页>Implementation principle of redis string and sorted set
Implementation principle of redis string and sorted set
2022-07-04 08:51:00 【Attacking Xiao Wang 666】
character string
yes Redis The most common type of data storage in , Its underlying implementation is a simple dynamic string sds(simple dynamic string), Is a string that can be modified .
It uses pre allocation of redundant space to reduce the frequent allocation of memory .
When the string length is less than 1M when , Expansion is to double the existing space , If exceeded 1M, When expanding, it will only expand more at one time 1M Space .( The maximum length of the string is 512M)
So when more than 512M When an error
Every sds.h/sdshdr The structure represents a SDS Value
struct sdshdr{
// Record buf Number of bytes used in the array
// be equal to sds The length of the saved string
int len;
// Record buf Unused data in
int free;
// A character array , To hold strings
char buf[];
}
That is, every time you create one sds, Will perform the above operations , Will apply for additional 8 Only bytes are saved len(4 byte ) and free(4 byte ) Information .
sorted set Ordered set
The bottom layer is a jump table , Jump list will maintain multiple index linked lists and original linked lists ,
Constantly improve new key nodes to form a new ordered linked list , Change time through space .
The simplest example 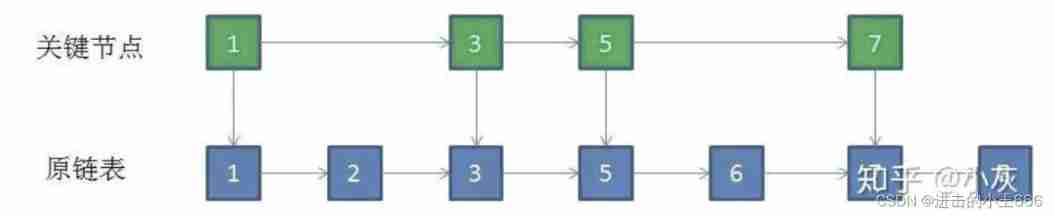
Insert logic
Insert new elements into the linked list , Just compare the value of the new element with the key list , This will reduce the number of comparisons .( Similar index )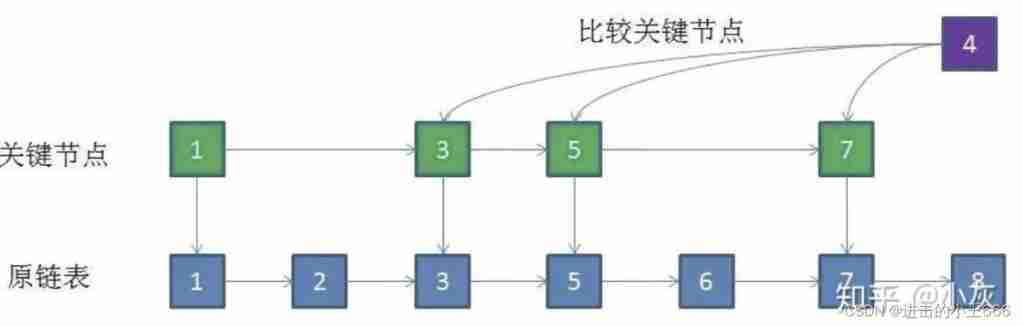
Key node extraction logic
Because in the jump table , Use space for time , There will be multiple levels of index linked lists , Each level of the index linked list is half of the previous level , When the amount of data is large , It can easily reduce the performance of linked list query .
As for the limit of extraction , There are only two nodes in the same layer *
Extract new inodes
Jump table adopts random method , After insertion, it will determine whether the newly inserted element has become a new key
Skip the process of inserting a node
1. The new node is compared with each layer index node one by one , Determine the insertion position of the original list O(logN)
2. Insert the node into the original linked list ,O(1)
3. Using the random way of flipping a coin , Decide whether the new node is promoted to the next level index .O(logN)
Overall, the time complexity of jump table insertion is O(logN), The space complexity is O(N)
Process of node deletion
1. Find the corresponding node in the index layer and delete , Delete the same node of each layer O(logN)
3. If there is only one node left in a layer after deleting nodes , Then the linked list can be deleted .O(logN)
The time complexity of jump table deletion is O(logN)
SortedSet Typical usage scenarios
Ranking List
边栏推荐
- DM8 database recovery based on point in time
- [error record] no matching function for call to 'cacheflush' cacheflush();)
- Codeforces Round #793 (Div. 2)(A-D)
- swatch
- Basic discipline formula and unit conversion
- Basic operations of databases and tables ----- view data tables
- Clion console output Chinese garbled code
- How to re enable local connection when the network of laptop is disabled
- C语言-入门-基础-语法-[主函数,头文件](二)
- What exactly is DAAS data as a service? Don't be misled by other DAAS concepts
猜你喜欢
](/img/dc/5c8077c10cdc7ad6e6f92dedfbe797.png)
C语言-入门-基础-语法-[变量,常亮,作用域](五)

ES6 summary

Educational Codeforces Round 119 (Rated for Div. 2)
Codeforces Round #793 (Div. 2)(A-D)

AcWing 244. Enigmatic cow (tree array + binary search)

Industry depression has the advantages of industry depression
C语言-入门-基础-语法-数据类型(四)
ArcGIS application (XXII) ArcMap loading lidar Las format data
Horizon sunrise X3 PI (I) first boot details
DM8 uses different databases to archive and recover after multiple failures
随机推荐
1211 or chicken and rabbit in the same cage
Webapi interview question summary 01
In depth research and investment strategy report on China's hydraulic parts industry (2022 Edition)
How to play dapr without kubernetes?
awk从入门到入土(12)awk也可以写脚本,替代shell
【无标题】转发最小二乘法
Awk from getting started to digging in (9) circular statement
Openfeign service interface call
Go zero micro service practical series (IX. ultimate optimization of seckill performance)
Codeforces Round #793 (Div. 2)(A-D)
C语言-入门-基础-语法-[主函数,头文件](二)
HMS core helps baby bus show high-quality children's digital content to global developers
Newh3c - routing protocol (RIP, OSPF)
go-zero微服务实战系列(九、极致优化秒杀性能)
The upper layer route cannot Ping the lower layer route
Basic discipline formula and unit conversion
Research Report on the current market situation and development prospects of calcium sulfate whiskers in China (2022 Edition)
C language - Introduction - Foundation - syntax - [operators, type conversion] (6)
The map set type is stored in the form of key value pairs, and the iterative traversal is faster than the list set
Question 49: how to quickly determine the impact of IO latency on MySQL performance