当前位置:网站首页>Kubernetes业务日志收集与监控
Kubernetes业务日志收集与监控
2020-11-09 11:32:00 【osc_0hs26yvj】

集群业务日志收集

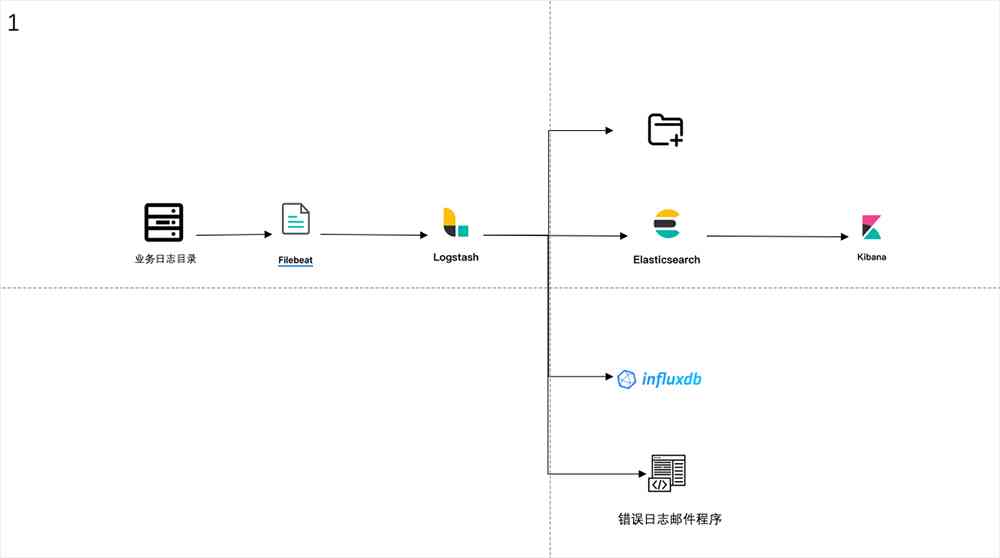
旧的日志收集架构其实存在一些问题:
当Logstash挂了之后就存在丢失日志问题,之前跨大版本升级Logstash失败就丢失了一段时间日志。
当Logstash后的消费程序挂了其一,例如ES挂了,会导致日志写文件和写InfluxDB都有问题并且由于Filebeat会不断推送日志给Logstash从而导致日志丢失。
以上两个问题都说明组件之间耦合严重,所以在迁移Kubernetes时我们对架构做了一些调整,调整后的日志收集架构如下图2。
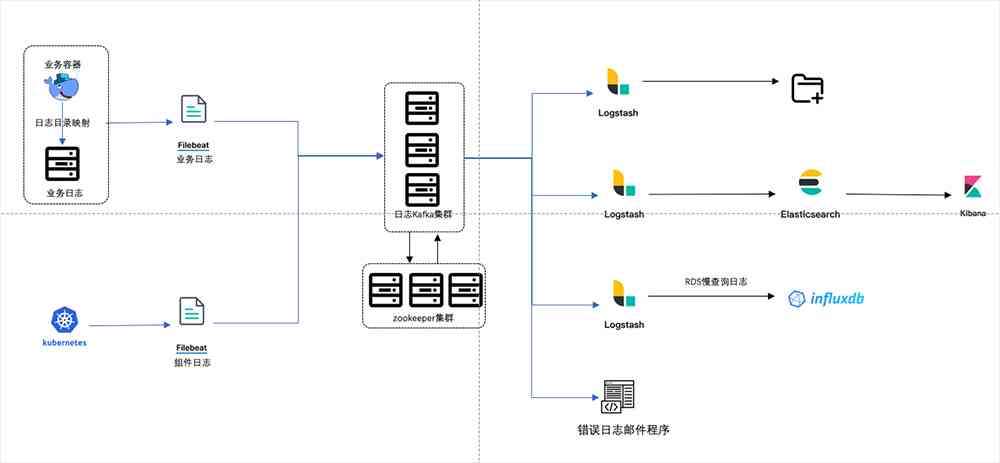
在Filebeat和Logstash之间增加Kafka用于临时缓存日志,并用于解耦日志消费者。
启动多个Logstash实例分别处理写文件、连接ES、写InfluxDB从而解耦日志消费程序耦合。
因为业务迁移要求快、时间短,没有时间将日志都打在容器stdout输出,所以采用将容器日志映射到宿主机上,再通过Filebeat收集,实现Kubernetes中业务日志收集。
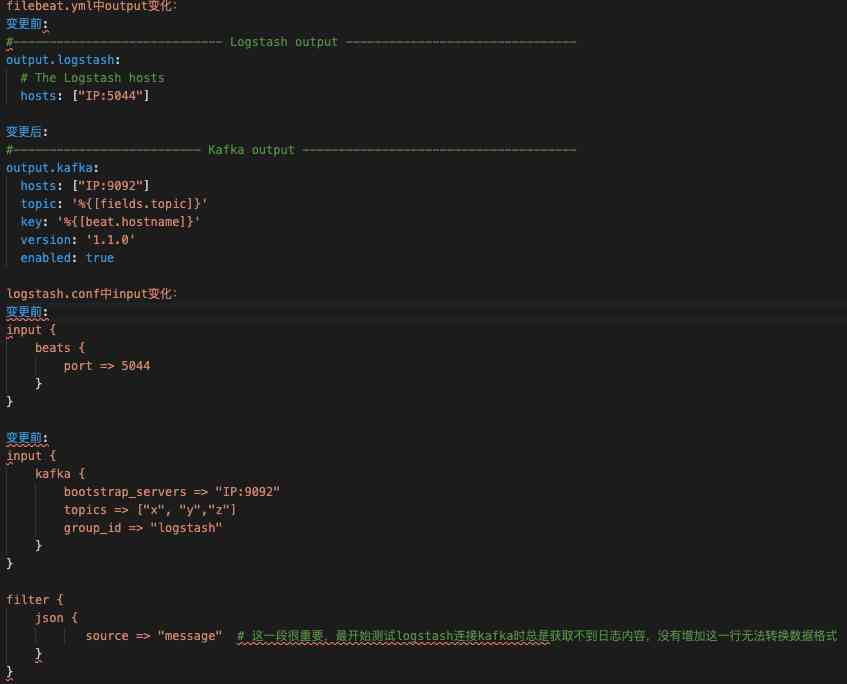
这里给出1、3点变化的配置变更:
第1点带来的配置变化对比如下图3。
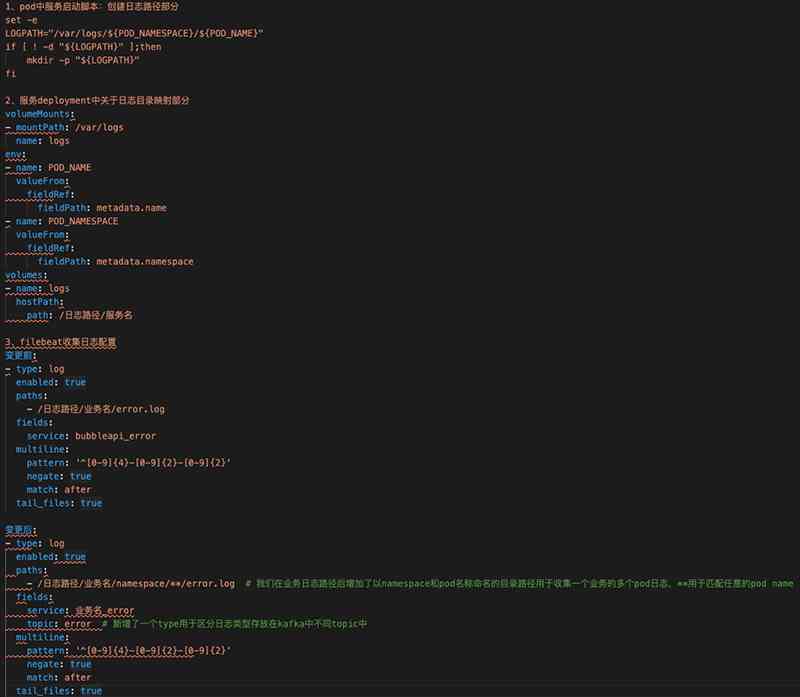
重点分享下第3点变化:最开始公司内部新增一个服务都需要将该服务的所有日志类型的收集规则直接写入filebeat.yml文件,然后使用Ansible下发到所有业务机上重启并Filebeat。这样导致filebeat.yml文件越来越长、难以维护并且一个配置不正确会导致Filebeat起不来,造成日志无法及时收集。后来我们将每个业务日志收集规则拆分成一个个小yaml文件存放在/etc/filebeat/inputs.d/中,业务Filebeat收集规则则由一个自动生成配置脚本从Kubernetes集群获取业务namespace和服务日志路径来自动生成业务Filebeat配置再通过Ansible将配置下发到指定目录。第3点配置变化对比如下图4中3部分。
通过以上几点修改我们快速的完成了业务日志在Kubernetes集群中的收集工作,并且提高了日志系统的稳定性,为以后常规化升级日志系统带来了便利。
当然我们的系统也有不足之处,现在我们的Filebeat还是使用Systemd启动,每新增一个Node,都需要安装一次Filebeat,并且需要让自动脚本检索到这个节点给节点下发配置,后期我们打算使用Kubernetes DaemonSet模式来部署Filebeat并且当有新服务加入自动更新Filebeat配置、使用Kubernetes的方法来完成Filebeat安装、配置更新。
集群状态监控以及业务状态监控
先介绍下各个组件作用:
Prometheus Operator:Prometheus是主动去拉取监控数据的,在Kubernetes里Pod因为调度原因导致IP不断变化,人工不可能去维持,自动发现又是基于DNS的,但是新增还是有点麻烦。Prometheus Operator的本职就是一组用户自定义的CRD资源以及Controller的实现,Prometheus Operator这个controller有RBAC权限、负责监听这些自定义资源的变化,并且根据这些资源的定义自动化的完成如Prometheus Server自身以及配置的自动化管理工作。
Kube-state-metrics:能够采集绝大多数Kubernetes内置资源相关数据,例如Pod、Deploy、Service等。同时它也提供自己的数据,主要是资源采集个数和采集发生的异常次数统计。例如我调度了多少个Replicas?现在可用的有几个?多少个Pod是running/stopped/terminated状态?Pod重启了多少次?等等这些状态值都可以通过添加Prometheus rule来产生报警,及时通知运维和开发人员。
Prometheus:用于收集集群组件Metric和集群中各类资源状态Metric以及自定义实现的监控Metric数据。
AlertManager:处理由Prometheus服务器等客户端发来的警报。它负责删除重复数据、分组,并将警报通过路由发送到正确的接收器,比如电子邮件、Webhook等。
在Kubernetes中部署业务前,监控系统和日志收集系统都需要提前安装好,因为业务分地区等原因我司内部存在多套集群环境,每套集群部署地区都不一致,所以在部署监控服务时,我们采取的方案是在每个集群中都创建一套完整的监控系统,因为我们的业务不属于PV很大的业务且集群规模较小,所以每个集群一套监控系统是比较合理的。监控系统中的各组件服务存放在一个单独的namespace中,直接采用YAML方式安装,没有使用helm安装。集群监控架构图如下图5。
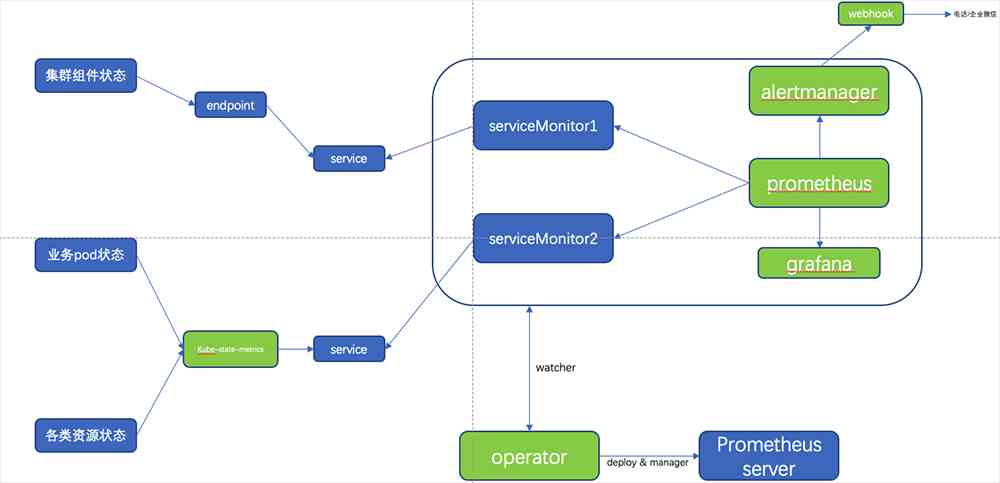
从图中可以看出我们主要收集了三个方面监控数据:
集群组件:我们收集了API、Controller、Scheduler、Kubelet、CoreDNS五个组件的Metrics,由于我司集群采用二进制方式安装的,所以部分组件Metric(Controller、Scheduler)数据的获取需要自己配置Endpoints并配合Service和ServiceMonitor完成Metric的收集。下面给出Controller的Endpoints、Service、ServiceMonitor配置如下图6。
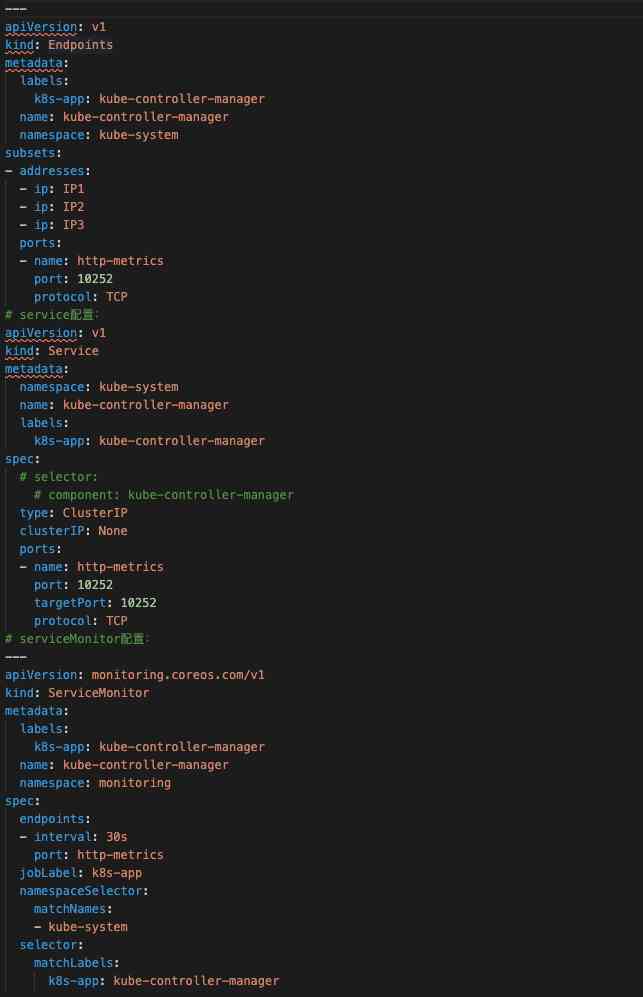
图6 Controller配置
Pod状态和资源状态:这两个方面的Metric由kube-state-metrics组件完成收集,至于kube-state-metrics的功能我就不多介绍了 网上和官方都有很好的介绍。
而关于Prometheus Operator、Prometheus、Alertmanager、kube-state-metrics的部署,网上教程也很多,大家自己搭建碰到问题自己解决也是很有乐趣的,也可以查看我的GitHub仓库:https://github.com/doubledna/k8s-monitor,参考安装。
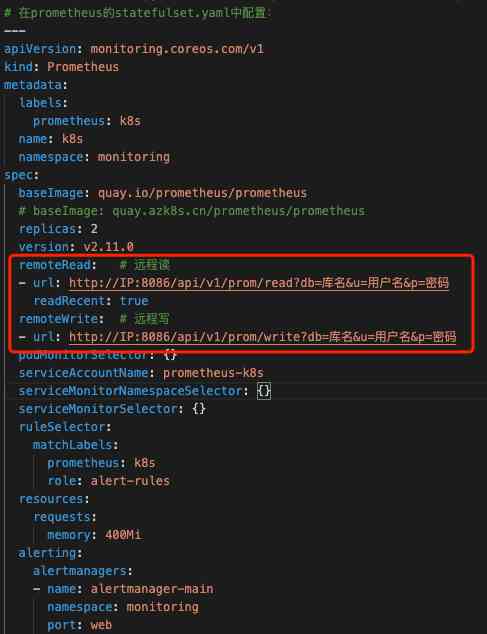
这里重点说下Prometheus存储,由于Prometheus部署在Kubernetes集群中而Pod是随时消亡的,所以直接本地存储是不合适的,当然也可以使用PV来存储,不过现在有很多很好也很完善的Prometheus远程存储方案可供选择,建议使用远程存储方案。我司采用InfluxDB作为Prometheus远程存储方案,单机InfluxDB性能已经很强基本满足日常需求,但由于他的集群方案是不开源的,存在单点故障问题。所以大家可以选择其他远程存储解决方案避免这个问题。Prometheus连接InfluxDB配置如下图7。
关于报警方面。我司内部为了统一各类报警资源与报警信息格式,由架构部开发了一个报警API程序,其他部门如需使用只要将报警内容转换成特定Json格式发送给报警API即可将报警信息推送到个人的电话、邮箱、短信、企业微信中。所以在Alertmanager中我们采用了Webhook模式发出Json格式报警数据到指定API,建议有能力的同学采用该模式 自行处理报警数据,而不要使用默认配置方法发送邮件或者微信,默认的报警格式不太美观。
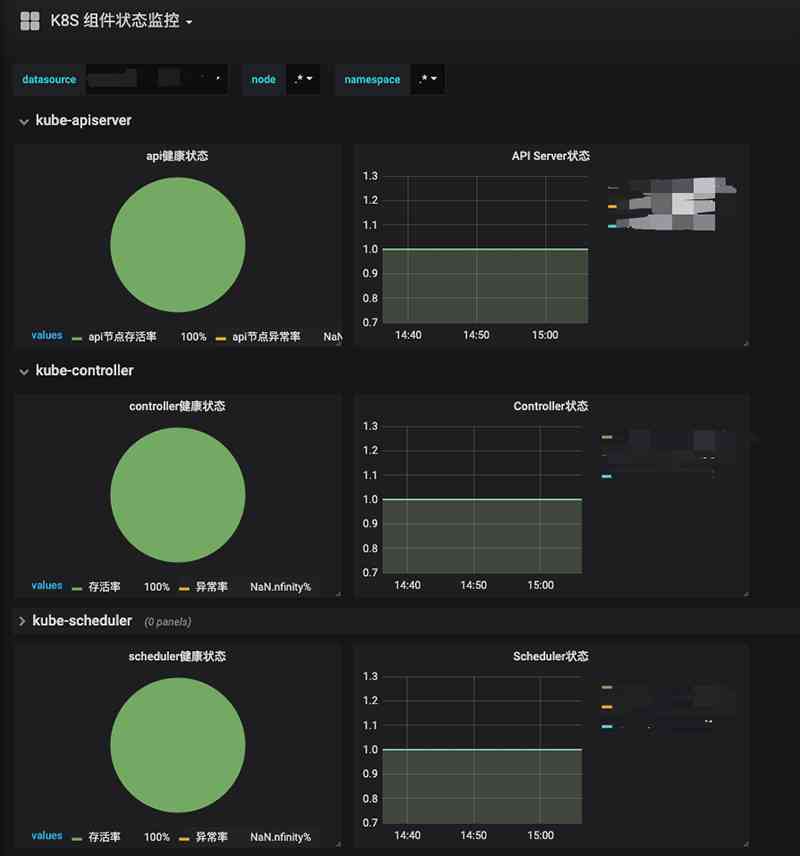
数据展示方面当然用的Grafana了,Grafana展示效果图如下图8与图9,我的图形配置也是基于Grafana官方模版中其他同学的模版,大家可以到官方网站中去下载适合自己的模版。
总结一下,对于中小型的企业采用开源的Prometheus Operator一揽子工具来快速的构建Kubernetes监控系统再合适不过了,这套系统基本可以搞定在Kubernetes中监控业务状态和组件状态,当然这套系统也有一些不足之处:
Event监控/收集:在Kubernetes中Pod的部署过程会产生一些事件,这些事件会记录Pod的生命周期以及调度情况。并且event在集群中不是永久保存的。如果你需要知道集群中Pod的调度情况,以及收集event作为审计或其他作用,并且当集群中业务越来越多,不太可能实时去集群中查看event,那么event的监控/收集就很重要了。最近在了解阿里的event收集工具kube-eventer,看上去还不错,有兴趣的同学可以一起讨论下如何搭建。
某些情况下Prometheus产生报警信息过多、过于频繁:虽然我们已经调整了部分Prometheus rule规则中并且修改了rule中报警产生频率,但是实际应用中我们偶尔会碰到例如一个节点故障时产生大量报警信息的问题。这些报警信息虽然有用,但是信息太多反而干扰了问题排查。
JVM监控
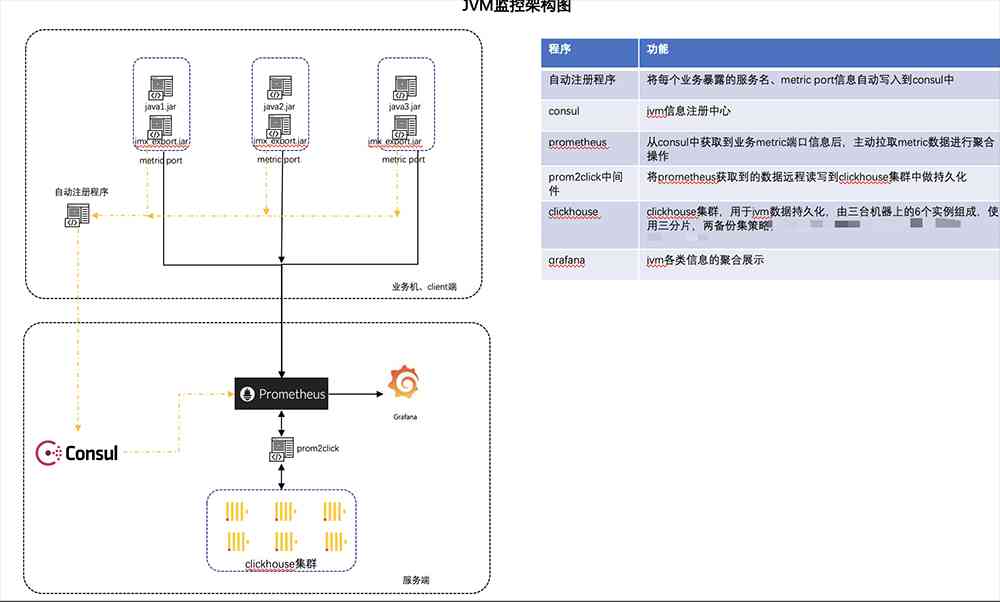
简单介绍图中架构:现在由于微服务的流行,后端存在很多服务并且新增后端服务很快,在prometheus.yml直接配置服务IP + JVM端口不是明智之选。所以我们选择用Consul来做自动注册服务功能并通过每台业务机器上的Python脚本将部署在该台机器上的所有服务JVM端口地址发送给Consul,Prometheus从Consul中获取服务JVM Metrics地址从而获取服务JVM数据。在没有Kubernetes集群之前Prometheus使用Docker启动,远程存储采用ClickHouse但是由于ClickHouse连接Promehteus需要使用prom2click做数据转换,多一个组件多一份维护成本且这个组件功能不全,所以在Kubernetes集群中Prometheus远程存储已经改成InfluxDB。JMX Exporter注入服务启动也很方便,这里只需将JMX Exporter的jar包以及配置文件放在程序的启动命令中并且指定端口即可获取到JVM相关Metric数据。服务启动命令如下:
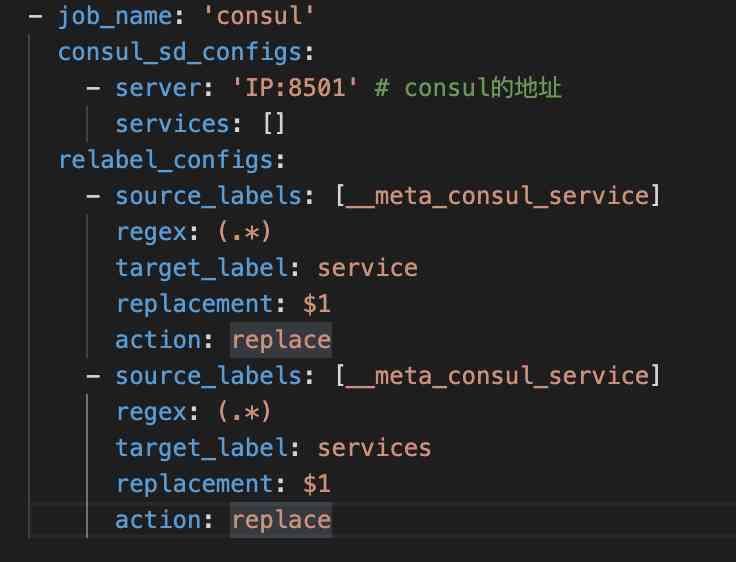
java -javaagent:/data/jmx_prometheus_javaagent-0.11.0.jar=57034:/data/jmx_exporter/jmx_exporter.yml -jar -DLOG_DIR=/日志路径/服务名/ -Xmx512m -Xms256m 服务名.jarPrometheus中配置Consul如下图11, 当Prometheus收集到业务JVM Metrics数据后就可以在Grafana中做聚合展示、报警等功能。
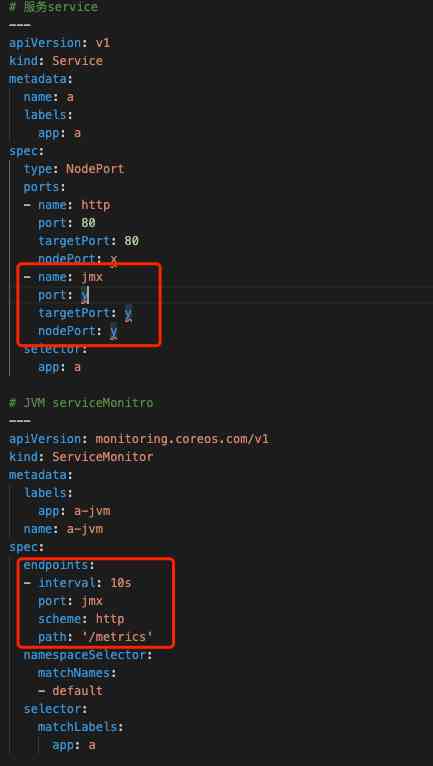
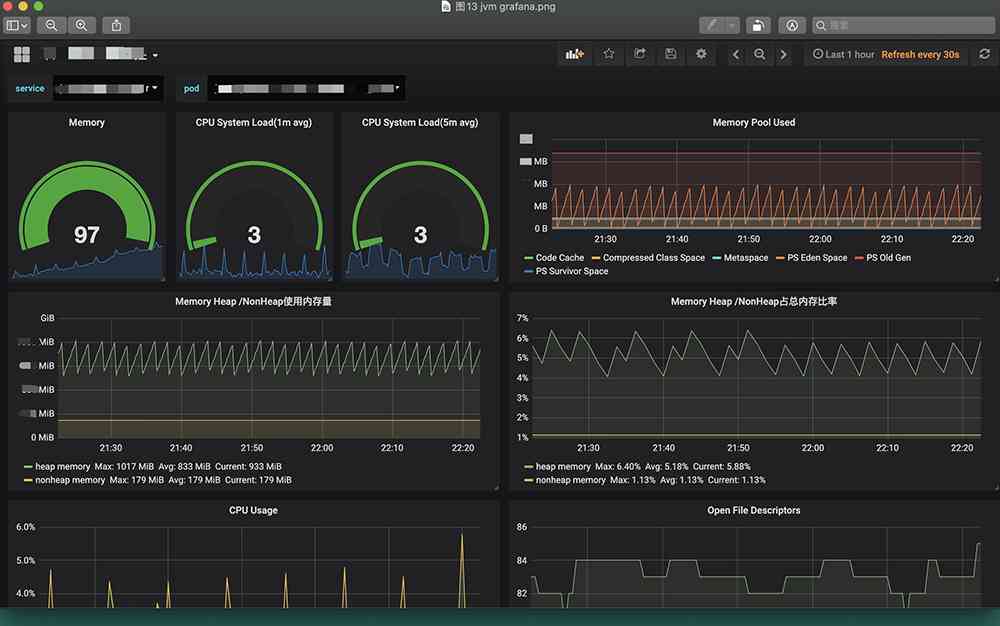
当服务迁移到Kubernetes集群中,我们变更了JMX Exporter的部署方式JMX Exporter通过initContainer方式共享jar包和配置给业务容器,方便jmx_exporter jar包升级和配置变更。这里就不具体展示配置YAML,而JVM采集我们抛弃了之前用Consul做自动注册的方法而采用ServiceMonitor配合Service来获取JVM Metrics数据,配置YAML如下图12,Grafana展示如下图13。
在Kubernetes中我们的JVM监控也碰到了一些问题,例如之前在业务机器直接部署程序,主机IP固定不变,当JVM挂了之后程序自动重启,我们可以在Grafana中看到程序挂掉那一刻的JVM状态,并且一台机器上的业务图像是连续的,而在集群中由于Pod IP和Pod名称都在变化这样就导致一个服务Pod挂了之后,在Grafana上查找之前消亡的Pod比较麻烦,而且图形在时间线上也不连续。之前有想过用StatfulSet模式来固定名称,最后觉得这有悖无状态原则就没有采纳, 这个问题还有待解决。
Q&A
Q:如何做到业务监控的报警,如某个接口响应时间增多,或调用频率多?A:我司的做法是程序自身记录接口响应时间,暴露成Metric数据之后通过Prometheus收集,配置对应的rule规则,超过设定的响应时间就推送报警消息给Alertmanager再发送给运维人员。
Q:kube-state在集群规模大的时候容易OOM,怎么解决?A:我们的集群节点还很少,到现在还未碰到kube-state-metric OOM的问题,既然你的集群规模大,由于kube-state收集的数据很多,那多给点内存总是没错的。
Q:内部应用http调用是怎么调的?直接使用service域名?还是有内网ingress controller?还是其他方案?A:我们用的是Eureka来做服务注册与发现,但是我更希望公司能用Kubernetes的servic,Eureka调用是有一丢丢问题的。
Q:Kubernetes日志系统做多租户模型有没有什么方案的建议?A:你的多租户是区分nanespace的话,可以考虑将namespace加入到日志路径中或kafka topic中,这样就能区分了。
Q:有没有考虑过监控跨集群,跨机房数据汇聚问题?A:之前我们用过Prometheus联邦方式,但是由于我们的业务跨了国家 在网络上有很多限制,就放弃了这种方法了。如果你的业务都在国内或者一个云服务商或者网络条件允许的话,可以搞一搞。
版权声明
本文为[osc_0hs26yvj]所创,转载请带上原文链接,感谢
https://my.oschina.net/u/4358286/blog/4709148
边栏推荐
- LTM understanding and configuration notes
- Mac 必备优质工具推荐
- 图节点分类与消息传递 - 知乎
- 再读《重构》
- For and for... In, for each and map and for of
- Handwritten digital image recognition convolution neural network
- Gather in Beijing! Openi / O 2020 Qizhi Developer Conference enters countdown
- Understanding runloop in OC
- Android 复选框 以及回显
- Three ways to operate tables in Apache iceberg
猜你喜欢


随机推荐
Program life: from Internet addicts to Microsoft, bat and byte offer harvesters
Application of cloud gateway equipment on easynts in Xueliang project
[design pattern] Chapter 4: Builder mode is not so difficult
range_sensor_layer
百亿级数据分表后怎么分页查询?
1486. Array XOR operation
操作系统之bios
Talk about my understanding of FAAS with Alibaba cloud FC
Mapstructure detoxifies object mapping
Initial installation of linx7.5
LTM understanding and configuration notes
BIOS of operating system
财富自由梦缓?蚂蚁金服暂停上市,监管后估值或下跌
What details does C + + improve on the basis of C
程序员的十年之痒
Looking for better dynamic getter and setter solutions
Log analysis tool - goaccess
寻找性能更优秀的动态 Getter 和 Setter 方案
WordPress Import 上传的文件尺寸超过php.ini中定义的upload_max_filesize值-->解决方法。
Rainbow sorting | Dutch flag problem