当前位置:网站首页>Query optimizer for SQL optimization
Query optimizer for SQL optimization
2022-07-04 14:28:00 【Dying fish】
Most of this article is quoted from Code Porter .-MYSQL Query optimizer
Recommended before reading this article innodb data structure , buffer Familiar with database storage structure
MYSQL Logical structure
MySQL Use a typical client / The server (Client/Server) structure , The architecture can be roughly divided into three layers : client 、 Server layer and storage engine layer . among , The server layer also includes connection management 、 The query cache 、SQL Interface 、 Parser 、 Optimizer 、 Buffer and cache, as well as various management tools and services . The logic structure diagram is as follows :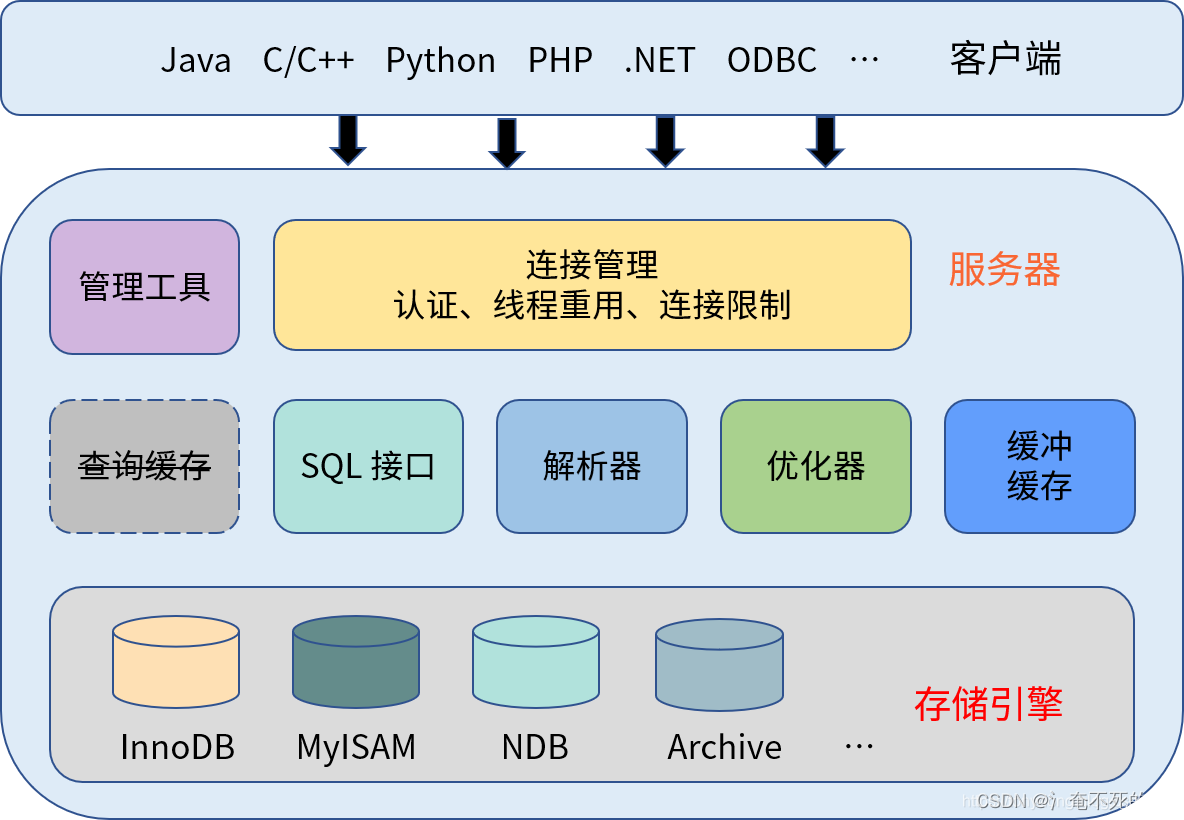
say concretely , The function of each component is as follows :
client , Connect MySQL Various tools and applications of the server . for example mysql Command line tools 、mysqladmin And various drivers, etc .
Connection management , Responsible for monitoring and managing client connections and thread processing . Each one is connected to MySQL All requests from the server are assigned a connection thread . The connection thread is responsible for communicating with the client , Accept the command sent by the client and return the result processed by the server .
The query cache , Used to convert the executed SELECT Statements and results are cached in memory . Determine whether the cache is hit before each query execution , If it hits, it directly returns the cached result . Cache hits need to meet many conditions ,SQL The sentences are exactly the same , Same context, etc . In fact, unless it's a read-only application , Query cache invalidation frequency is very high , Any modification to the table will invalidate the cache ; therefore , The query is cached in MySQL 8.0 Has been removed from .
SQL Interface , Receive various messages sent by the client DML and DDL command , And return the result of user query . It also includes all built-in functions ( date 、 Time 、 Mathematics and encryption functions ) And cross storage engine capabilities , For example, stored procedures 、 trigger 、 View etc. .
Parser , Yes SQL Statement parsing , For example, semantic and grammatical analysis and inspection , And object access rights check .
Optimizer , Use the statistical information of the database to determine SQL The best way to execute a statement . Use index or full table scan to access a single table , Implementation of multi table connection, etc . The optimizer is the key component that determines query performance , The statistical information of the database is the basis of the optimizer's judgment .
Caching and buffering , Composed of a series of caches , For example, data cache 、 Index cache, object permission cache, etc . For disk data that has been accessed , Cache in buffer ; The data in memory can be read directly at the next access , This reduces the number of disks IO.( Query caching and buffering are not the same thing )
Storage engine , The storage engine is a component that performs actual operations on the underlying physical data , Provide various operation data for the server layer API.MySQL Support plug-in storage engine , Include InnoDB、MyISAM、Memory etc. .
MYSQL Execute the process
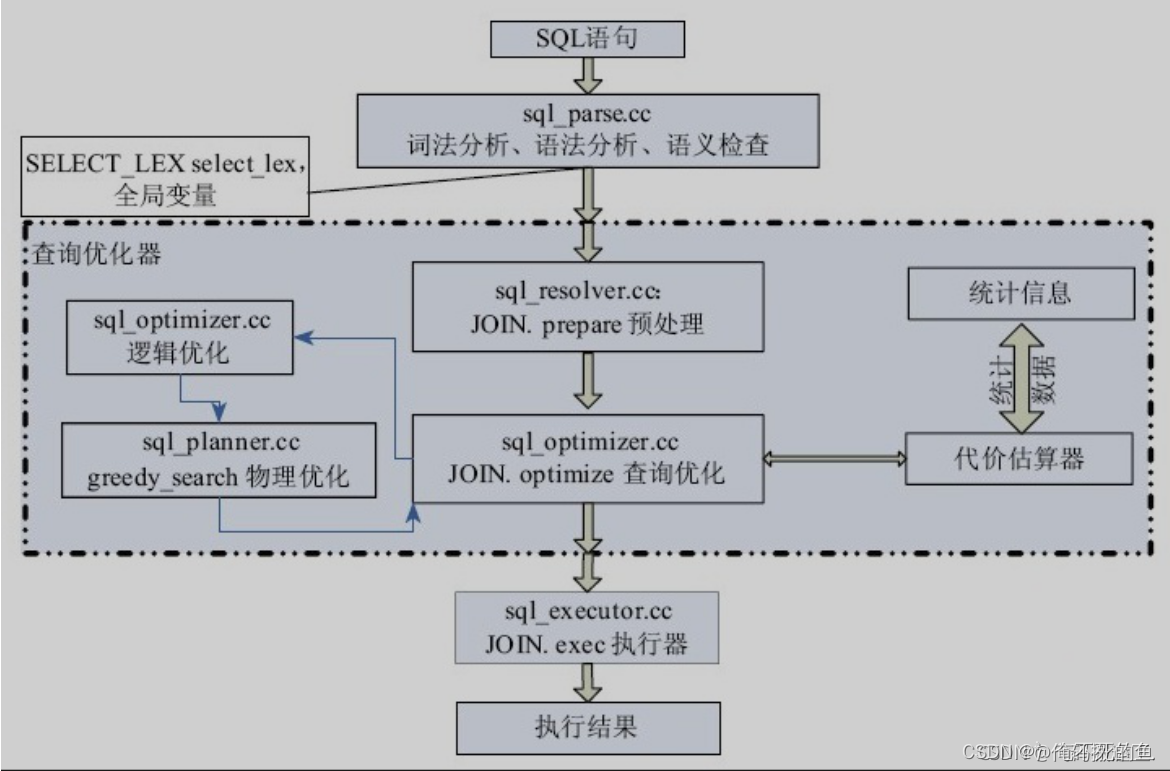
Optimizer
MySQL Query optimizer is also called cost optimizer , Use cost based optimization (Cost-based Optimization), With SQL Statement as input , Use the built-in cost model, data dictionary information and the statistical information of the storage engine to decide which steps to use to execute the query statement .
The concepts of query optimization and map navigation are very similar , We usually only need to enter the desired results ( Destination ), The optimizer is responsible for finding the most effective implementation ( The best route ). It should be noted that , Navigation does not always return to the fastest route , Because the traffic data obtained by the system cannot be absolutely accurate ; A similar , The optimizer is also based on a specific model 、 Choose from various configurations and statistics , Therefore, it is impossible to always get the best execution
Be careful :mysql The optimizer of is based on the optimization of query cost , Not optimization based on query time .
At a high level ,MySQL Server It can be divided into two parts : Server layer and storage engine layer . among , The optimizer works at the server layer , Located in the storage engine API above . The working process of the optimizer can be semantically divided into three stages :
- Logical transformation , Including negation and elimination 、 Equivalence transfer and constant transfer 、 Constant expression evaluation 、 The outer connection is converted to the inner connection 、 Subquery transformation 、 View merging, etc ;
- Cost based optimization , Including the selection of access method and connection order ;
- Implement the plan to improve , For example, push... Under table conditions 、 Access method adjustment 、 Avoid sorting and push down under index conditions .
Logical transformation
MySQL The optimizer may first transform the query in a way that does not affect the results , The goal of the transformation is to try to eliminate some operations and execute the query faster .
mysql> explain select * from user where id >1 and 1=1;
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+---------
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+---------
| 1 | SIMPLE | user | NULL | range | PRIMARY | PRIMARY | 4 | NULL | 1 | 100.00 | Using where |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+---------
1 row in set, 1 warning (0.02 sec)
mysql> show warnings;
+-------+------+--------------------------------------------------------------------------------------------
| Level | Code | Message|
+-------+------+--------------------------------------------------------------------------------------------
| Note | 1003 | /* select#1 */ select `test`.`user`.`id` AS `id`,`test`.`user`.`name` AS `name`,`test`.`user`.`age` AS `age`,`test`.`user`.`address` AS `address`,`test`.`user`.`birthday` AS `birthday` from `test`.`user` where (`test`.`user`.`id` > 1) |
+-------+------+--------------------------------------------------------------------------------------------
1 row in set (0.01 sec)
obviously , In the query condition 1=1 Is completely superfluous . There is no need to perform a calculation for each row of data ; Deleting this condition will not affect the final result . perform EXPLAIN After statement , adopt SHOW WARNINGS The command can view the after logical conversion SQL sentence , As can be seen from the above results 1=1 No longer exists .
Optimizer and index tips
Subqueries are like recursive functions , Sometimes it can get twice the result with half the effort , But its execution efficiency is low . Compared with table connection , Subquery is more flexible , convenient , In various forms , Suitable as a filter for queries , And table connection is more suitable for viewing data of multiple tables .
In general , Subqueries produce Cartesian products , Table joins are more efficient than subqueries . So I'm writing SQL Statements should try to use join queries .
Table joins ( Inner connection and outer connection ) Can be replaced with subqueries , But the reverse is not necessarily , Some subqueries cannot be replaced by table joins . Next, we will introduce which sub query query commands can be rewritten as table joins .
When checking query statements that tend to be written as subqueries , Consider replacing subqueries with table joins , See if the efficiency of the connection is better than that of the subquery . Again , If a subquery is used SELECT The statement takes a long time to complete , Then try rewriting it as a table connection , See if the implementation effect has improved .
The optimizer usually optimizes subqueries into join queries .
explain SELECT
*
FROM
app_user
WHERE
app_user.KEY IN ( SELECT app_user_copy1.`key` FROM app_user_copy1 WHERE app_user.age = 18 AND app_user.id > app_user_copy1.id );
show WARNINGS;
Optimization becomes inner join query
select * from `test_bai`.`app_user` semi join (`test_bai`.`app_user_copy1`) on ((`test_bai`.`app_user_copy1`.`key` = `test_bai`.`app_user`.`key`) and (`test_bai`.`app_user`.`age` = 18) and (`test_bai`.`app_user`.`id` < `test_bai`.`app_user_copy1`.`id`))
The outer connection is converted to the inner connection
In the process of query optimization , The connection order between tables connected within can be exchanged at will ,where or on Conditions involving only a single table can be pushed down to the table as the filter conditions of the table ; For external connections , The connection order of tables cannot be exchanged at will , Constraints cannot be pushed down at will . If you can convert an external connection to an internal connection , Then you can simplify the query optimization process .
Conditions to be met for external connection to be converted to internal connection
For the sake of description , Introduce two nouns :
No airside : The side where all data in the external connection is output . such as : The left table of the left outer connection 、 The right table of the right outer connection
Movable airside : The side of the external connection that will be filled with blank values . such as : The right table of the left outer connection 、 The left table of the right outer connection 、 The left and right tables of all external connections
As long as one of the following conditions is met , You can convert an external connection to an internal connection :
Where There is... In the condition “ Strictly ” Constraints of , And the constraint refers to the column in the table on the air side . such , This predicate can filter out the null values generated on the null side , Make the final result equal to the inner connection .
explain select * from app_user left join app_user_copy1 on app_user.`key` = app_user_copy1.`key`
where app_user.age = 18 and app_user_copy1.id is not null;
After optimization , Become interlinked
show WARNINGS;
\/* select#1 */ select `test_bai`.`app_user`.`id` AS `id`,`test_bai`.`app_user`.`name` AS `name`,`test_bai`.`app_user`.`email` AS `email`,`test_bai`.`app_user`.`phone` AS `phone`,`test_bai`.`app_user`.`gender` AS `gender`,`test_bai`.`app_user`.`password` AS `password`,`test_bai`.`app_user`.`age` AS `age`,`test_bai`.`app_user`.`create_time` AS `create_time`,`test_bai`.`app_user`.`update_time` AS `update_time`,`test_bai`.`app_user`.`key` AS `key`,`test_bai`.`app_user_copy1`.`id` AS `id`,`test_bai`.`app_user_copy1`.`name` AS `name`,`test_bai`.`app_user_copy1`.`email` AS `email`,`test_bai`.`app_user_copy1`.`phone` AS `phone`,`test_bai`.`app_user_copy1`.`gender` AS `gender`,`test_bai`.`app_user_copy1`.`password` AS `password`,`test_bai`.`app_user_copy1`.`age` AS `age`,`test_bai`.`app_user_copy1`.`create_time` AS `create_time`,`test_bai`.`app_user_copy1`.`update_time` AS `update_time`,`test_bai`.`app_user_copy1`.`key` AS `key` from `test_bai`.`app_user` join `test_bai`.`app_user_copy1` where ((`test_bai`.`app_user_copy1`.`key` = `test_bai`.`app_user`.`key`) and (`test_bai`.`app_user`.`age` = 18) and (`test_bai`.`app_user_copy1`.`id` is not null))
On In connection conditions , If not, the values in the null column can be a subset of the null column , And the values on the airside are not NULL. Typical , Columns on the non empty side are foreign keys , Columns on the empty side can be used as primary keys , And between the two is the main foreign key reference relationship .
Cost based optimization
Before actually executing a query statement ,MYSQL The optimizer will find all the solutions that can be used to execute the statement , And after comparing these schemes, find out the scheme with the lowest cost . The lowest cost solution is the so-called execution plan . Then the interface provided by the storage engine will be called to execute the query . To sum up , The process is as follows :
1、 According to the search criteria , Find all possible indexes .
2、 Calculate the cost of a full table scan .
3、 Calculate the cost of executing queries using different indexes .
4、 Compare the costs of various schemes , Find the lowest cost solution .
To find the best execution plan , The optimizer needs to compare different query schemes . As the number of tables in the query increases , Possible execution plans will show exponential growth ;MySQL Limit the of one query in join The maximum number of tables is 61, For one there is 61 A table participates in join operation , In theory, we need 61!( Factorial ) Second assessment .
Therefore, it is impossible for the optimizer to traverse all execution schemes , A more flexible optimization method is to allow users to control the degree of traversal of the optimizer when looking for the best query plan . Generally speaking , The fewer plans the optimizer evaluates , The less time it takes to compile the query ; But on the other hand , Because the optimizer ignores some plans , So what may be found is not the best plan .
Control the degree of optimization
MySQL Two system variables are provided , It can be used to control the optimization degree of the optimizer :
optimizer_search_depth, The depth of the optimizer lookup . If this parameter is greater than the number of tables in the query , You can get a better implementation plan , But the optimization time is longer ; If less than the number of tables , Optimization can be completed faster , But what may be obtained is not the optimal plan . The default value for this parameter is 62; If you're not sure if it's appropriate , You can set it to 0, Let the optimizer automatically determine the depth of the search .
optimizer_prune_level, Tell the optimizer to skip certain scenarios based on an estimate of the number of rows accessed per table , This heuristic method can greatly reduce the optimization time and rarely lose the best plan . therefore , The default setting of this parameter is 1( Turn on ); If you confirm that the optimizer missed the best plan , You can set this parameter to 0, However, this may lead to an increase in optimization time .
show variables like '%optimizer_prune_level%';
Cost constant
Keep raising costs , Then this price ( cost ) How to evaluate ? In two parts :
- IO cost :MySQL The cost of reading a page .
- CPU cost :CPU The cost of detecting whether a record meets the search criteria .
** The total cost =IO cost +CPU cost
** It can be seen that , We need three kinds of data :
Accounting IO Cost the number of pages to read
Accounting CPU The number of records that need to be compared
The cost constant coefficient corresponding to each operation
Let's talk about these cost constant coefficients , Cost constants can be obtained by mysql In the system database server_cost and engine_cost Query and set two tables .
select * from mysql.server_cost;
cost_name |cost_value|last_update |comment|default_value|
----------------------------|----------|-------------------|-------|-------------|
disk_temptable_create_cost | |2018-05-17 10:12:12| | 10.0|
disk_temptable_row_cost | |2018-05-17 10:12:12| | 1|
key_compare_cost | |2018-05-17 10:12:12| | 0.1|
memory_temptable_create_cost| |2018-05-17 10:12:12| | 2.0|
memory_temptable_row_cost | |2018-05-17 10:12:12| | 0.2|
row_evaluate_cost | |2018-05-17 10:12:12| | 0.2|
server_cost Stored in is the estimated cost of regular server operations :
cost_value Empty means default_value, among :
disk_temptable_create_cost and disk_temptable_row_cost Represents the disk based storage engine (InnoDB or MyISAM) The evaluation cost of using internal temporary tables in . Increasing these values will make the optimizer prefer query plans that use less internal temporary tables .(group by / distinct Wait to create a temporary table )
key_compare_cost Represents the evaluation cost of the comparison record key . Increasing this value will make query plans that need to compare multiple key values more expensive . for example , perform filesort A sorted query plan is relatively more expensive than a query plan that avoids sorting by indexing .
memory_temptable_create_cost and memory_temptable_row_cost Represents in MEMORY The evaluation cost of using internal temporary tables in the storage engine . Increasing these values will make the optimizer prefer query plans that use less internal temporary tables .
row_evaluate_cost Represents the evaluation cost of calculating the recording conditions . Increasing this value will make the query plan that checks many data rows more expensive . for example , Compared with index range scanning that reads a small number of data rows , Full table scanning has become relatively expensive .
engine_cost What is stored in is the cost estimate of the operation related to a specific storage engine :
select * from mysql.engine_cost;
engine_name|device_type|cost_name |cost_value|last_update |comment|default_value|
-----------|-----------|----------------------|----------|-------------------|-------|-------------|
default | 0|io_block_read_cost | |2018-05-17 10:12:12| | 1.0|
default | 0|memory_block_read_cost| |2018-05-17 10:12:12| | 0.25|
engine_name Represents the storage engine ,“default” Represents all storage engines , You can also insert specific data for different storage engines .cost_value Empty means default_value. among ,
io_block_read_cost Represents the cost of reading indexes or data blocks from disk . Increasing this value will make the query plan that reads many disk blocks more expensive . for example , Compared with index range scanning that reads fewer blocks , Full table scanning has become relatively expensive .
memory_block_read_cost Indicates the cost of reading indexes or data blocks from the database buffer .
example Son :
**1、** Let's take an example , Execute the following statement :
mysql> explain format=json select * from user where birthday between "2000-01-01" and "2020-11-01";
+ -------------------------------------------------------------------- +
| EXPLAIN |
+ -------------------------------------------------------------------- +
{
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "9822.60"
},
"table": {
"table_name": "user",
"access_type": "ALL",
"possible_keys": [
"index_birthday"
],
"rows_examined_per_scan": 48308,
"rows_produced_per_join": 18209,
"filtered": "37.70",
"cost_info": {
"read_cost": "6180.60",
"eval_cost": "3642.00",
"prefix_cost": "9822.60",
"data_read_per_join": "14M"
},
"used_columns": [
"id",
"sex",
"name",
"age",
"birthday"
],
"attached_condition": "(`test`.`user`.`birthday` between '2000-01-01' and '2020-11-01')"
}
}
}
The query plan shows that full table scanning is used (access_type = ALL), There is no choice index_birthday. You can see from the above that the cost of full table scanning is 9822.6, How does this value come from ? It must be mentioned that MYSQL A series of statistics maintained for each table . Can pass SHOW TABLE STATUS View the statistics of the table .
See the table user Statistical information (show table status like ‘user’;):
Rows: Number of records in the table . about MyISAM Storage engine , This value is accurate ; about InnoDB, This value is an estimate .
Data_length: Number of bytes of storage space occupied by the table . about MyISAM Storage engine , This value is the size of the data file ; about InnoDB engine , This value is equivalent to the storage space occupied by the cluster index . So for using InnoDB The engine's table ,Data_length = The number of pages in the clustered index * The size of each page ( Default 16k).
Let's calculate the total cost of the full table scan above 9822.6 How did it come from :
The number of pages in the clustered index (IO Number of pages read ) = 2637824 ÷ 16 ÷ 1024 = 161
I/O cost :161 * 1.0 = 161
CPU cost :48308 * 0.2 = 9661.6
The total cost :161 + 9661.6 = 9822.6
See why there is no choice index_birthday Index? ? You can see the specific reason through the optimizer trace .
Optimizer trace (optimizer_trace): from MySQL5.6 Version start ,optimizer_trace Can support MySQL Print out the query execution plan tree , For in-depth analysis SQL Implementation plan ,COST Cost is very useful , The internal information printed is relatively comprehensive .): from MySQL5.6 Version start ,optimizer_trace Can support MySQL Print out the query execution plan tree , For in-depth analysis SQL Implementation plan ,COST Cost is very useful , The internal information printed is relatively comprehensive .
The optimizer trace output mainly consists of three parts :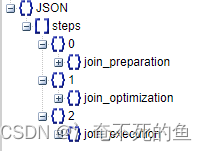
join_preparation, Preparation stage , Returned after the field name extension SQL sentence . about 1=1 This superfluous condition , It will also be deleted in this step .
join_optimization, Optimization stage . among condition_processing It contains various logical transformations , After equivalent transmission, condition id=age Convert to age=1. in addition constant_propagation Indicates constant passing ,trivial_condition_removal Indicates that the invalid condition is removed .
join_execution, Execution phase .
Turn on optimizer_trace:
mysql> SET optimizer_trace="enabled=on";
Query OK, 0 rows affected (0.00 sec)
Use the optimizer to track and view :
mysql> select * from information_schema.optimizer_trace\G
*************************** 1. row ***************************
QUERY: explain format=json select * from user where birthday between "2000-01-01" and "2020-11-01";
TRACE: {
"steps": [
{
"join_preparation": {
"select#": 1,
"steps": [
{
"expanded_query": "/* select#1 */ select `user`.`id` AS `id`,`user`.`sex` AS `sex`,`user`.`name` AS `name`,`user`.`age` AS `age`,`user`.`birthday` AS `birthday` from `user` where (`user`.`birthday` between '2000-01-01' and '2020-11-01')"
}
]
}
},
{
"join_optimization": {
"select#": 1,
"steps": [
{
"condition_processing": {
"condition": "WHERE",
"original_condition": "(`user`.`birthday` between '2000-01-01' and '2020-11-01')",
"steps": [
{
"transformation": "equality_propagation",
"resulting_condition": "(`user`.`birthday` between '2000-01-01' and '2020-11-01')"
},
{
"transformation": "constant_propagation",
"resulting_condition": "(`user`.`birthday` between '2000-01-01' and '2020-11-01')"
},
{
"transformation": "trivial_condition_removal",
"resulting_condition": "(`user`.`birthday` between '2000-01-01' and '2020-11-01')"
}
]
}
},
{
"substitute_generated_columns": {
}
},
{
"table_dependencies": [
{
"table": "`user`",
"row_may_be_null": false,
"map_bit": 0,
"depends_on_map_bits": [
]
}
]
},
{
"ref_optimizer_key_uses": [
]
},
{
"rows_estimation": [
{
"table": "`user`",
"range_analysis": {
"table_scan": {
"rows": 48308,
"cost": 9824.7
},
"potential_range_indexes": [
{
"index": "PRIMARY",
"usable": false,
"cause": "not_applicable"
},
{
"index": "index_name",
"usable": false,
"cause": "not_applicable"
},
{
"index": "index_birthday",
"usable": true,
"key_parts": [
"birthday",
"id"
]
}
],
"setup_range_conditions": [
],
"group_index_range": {
"chosen": false,
"cause": "not_group_by_or_distinct"
},
"analyzing_range_alternatives": {
"range_scan_alternatives": [
{
"index": "index_birthday",
"ranges": [
"0x21a00f <= birthday <= 0x61c90f"
],
"index_dives_for_eq_ranges": true,
"rowid_ordered": false,
"using_mrr": false,
"index_only": false,
"rows": 18210,
"cost": 21853,
"chosen": false,
"cause": "cost"
}
],
"analyzing_roworder_intersect": {
"usable": false,
"cause": "too_few_roworder_scans"
}
}
}
}
]
},
{
"considered_execution_plans": [
{
"plan_prefix": [
],
"table": "`user`",
"best_access_path": {
"considered_access_paths": [
{
"rows_to_scan": 48308,
"access_type": "scan",
"resulting_rows": 18210,
"cost": 9822.6,
"chosen": true
}
]
},
"condition_filtering_pct": 100,
"rows_for_plan": 18210,
"cost_for_plan": 9822.6,
"chosen": true
}
]
},
{
"attaching_conditions_to_tables": {
"original_condition": "(`user`.`birthday` between '2000-01-01' and '2020-11-01')",
"attached_conditions_computation": [
],
"attached_conditions_summary": [
{
"table": "`user`",
"attached": "(`user`.`birthday` between '2000-01-01' and '2020-11-01')"
}
]
}
},
{
"refine_plan": [
{
"table": "`user`"
}
]
}
]
}
},
{
"join_explain": {
"select#": 1,
"steps": [
]
}
}
]
}
The total cost of using full table scanning is 9822.60, The total cost of using range scanning is 21853. This is because the query returns user Most of the data in the table , Scan through index range , And then again Back to the table Instead, it will be slower than directly scanning the table .
**2、** Next, we compare the cost constants of the data rows row_evaluate_cost from 0.2 Change it to 1, And refresh the value in memory :
update mysql.server_cost
set cost_value=1
where cost_name='row_evaluate_cost';
flush optimizer_costs;
Then reconnect to the database , Get the results of the execution plan again as follows :
mysql> explain format=json select * from user where birthday between "2000-01-01" and "2020-11-01";
+ -------------------------------------------------------------------- +
| EXPLAIN |
+ -------------------------------------------------------------------- +
{
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "54631.01"
},
"table": {
"table_name": "user",
"access_type": "range",
"possible_keys": [
"index_birthday"
],
"key": "index_birthday",
"used_key_parts": [
"birthday"
],
"key_length": "4",
"rows_examined_per_scan": 18210,
"rows_produced_per_join": 18210,
"filtered": "100.00",
"index_condition": "(`test`.`user`.`birthday` between '2000-01-01' and '2020-11-01')",
"cost_info": {
"read_cost": "36421.01",
"eval_cost": "18210.00",
"prefix_cost": "54631.01",
"data_read_per_join": "14M"
},
"used_columns": [
"id",
"sex",
"name",
"age",
"birthday"
]
}
}
}
here , Range scan selected by the optimizer (access_type = range), Although its cost increases , But using full table scanning is more expensive .
row_evaluate_cost Restore to the default settings and reconnect to the database :
Optimizer and index tips
Although through the system variable optimizer_switch You can control the optimization strategy of the optimizer , But once you change its value , Subsequent queries will be affected , Unless you set it again .
Another way to control the optimizer strategy is the optimizer prompt (Optimizer Hint) And index tips (Index Hint), They are only valid for a single statement , And priority ratio optimizer_switch Higher .
The optimizer prompts to use /*+ … */ Annotation style syntax , The connection order can be 、 Table access mode 、 Index usage 、 Subquery 、 Statement execution time limit 、 System variables and resource groups are set at the statement level .
for example , Without using optimizer prompts :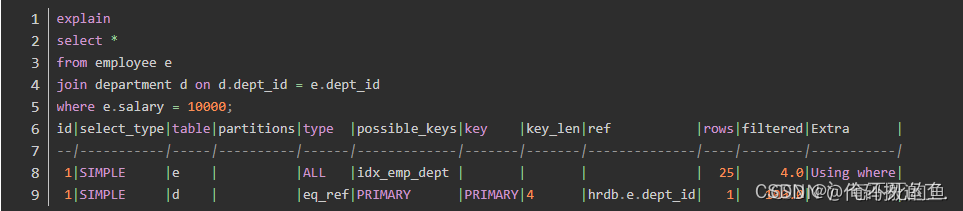
Optimizer selection employee As a driving table , And use the full table scan to return salary = 10000 The data of ; Then search through the primary key department Records in .
Then we prompt through the optimizer join_order Modify the join order of two tables :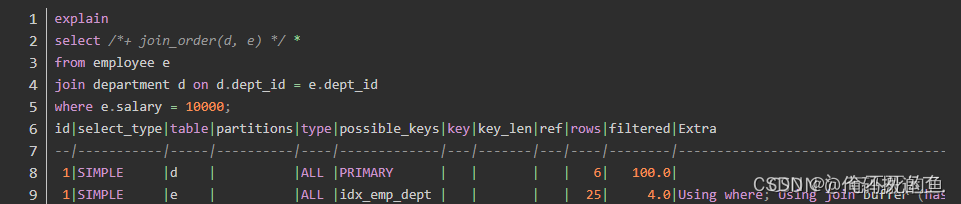
here , The optimizer chose department As a driving table ; Simultaneous access employee Select full table scan . We can add another optimizer hint related to index index: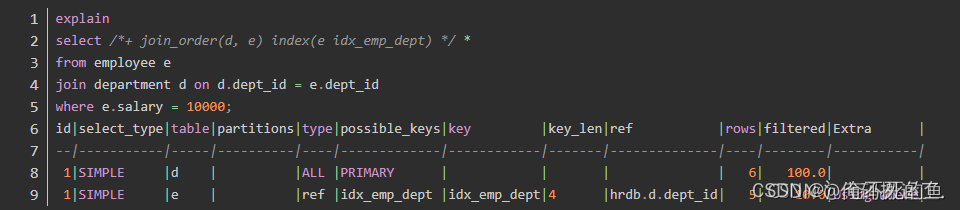
Final , The optimizer chose to pass the index idx_emp_dept lookup employee Data in .
There's a lot more , such as USE INDEX Prompt the optimizer to use an index ,IGNORE INDEX Prompt the optimizer to ignore an index ,FORCE INDEX Force an index .... wait .
Small tables drive large tables
Why use a small table to drive a large table
MySQL The algorithm of table association is Nest Loop Join
NLJ It is through two layers of circulation , Make... With the first watch Outter Loop, The second table makes Inner Loop,Outter Loop Every record of Inner Loop Compare the records of , If it meets the conditions, it will output . and NLJ And then there is 3 A subdivision algorithm :
1、Simple Nested Loop Join(SNLJ)
// Pseudo code
for (r in R) {
for (s in S) {
if (r satisfy condition s) {
output <r, s>;
}
}
}
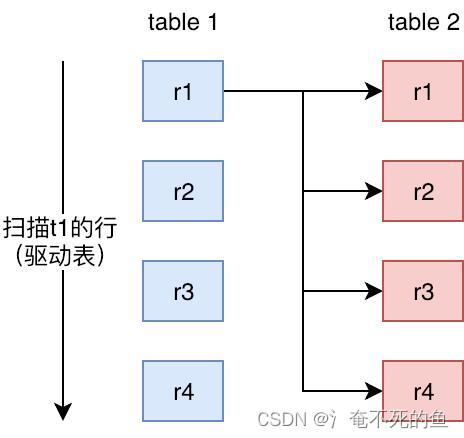
SNLJ It's two tables connected by two-layer cyclic full scan , If you get two records that meet the conditions, output , This is the Cartesian product of two tables , The number of comparisons is R * S, It is a more violent Algorithm , It will take time .( The associated sub query costs the same , It is generally impossible to carry out in this way join)
Simple nested loop connections are actually simple and crude nested loops , If table1 Yes 1 Ten thousand data ,table2 Yes 1 Ten thousand data , So the number of data comparisons =1 ten thousand * 1 ten thousand =1 100 million times , This query can be very slow .
2、Index Nested Loop Join(INLJ)
// Pseudo code
for (r in R) {
for (si in SIndex) {
if (r satisfy condition si) {
output <r, s>;
}
}
}
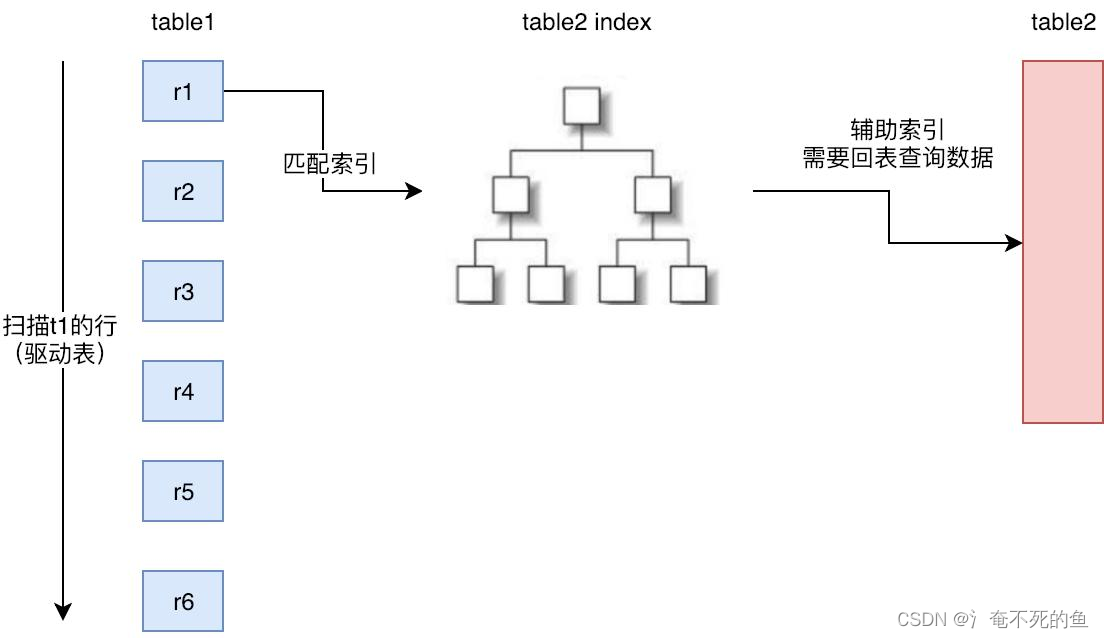
NLJ Is in SNLJ On the basis of the optimization , Determine the available indexes through the connection conditions , stay Inner Loop Scan the index without scanning the data itself , So as to improve Inner Loop The efficiency of .
and INLJ There are also shortcomings. , That is, if the scanned index is a non clustered index , And you need to access non indexed data , It will generate an operation of reading data back to the table , This is one more random I/O operation .
- Index nested circular join is an algorithm based on index , The index is based on the inner table , Match the outer table index directly with the inner table index through the matching conditions of the outer table , Avoid comparing with each record in the inner table , Thus, the query using the index reduces the matching times of the inner table , The advantages have been greatly improved join Performance of :
** The number of original matches = Number of outer table rows * Number of inner table rows
** Optimized matching times = Number of rows in the outer table * The height of the inner table index
- Use scenarios : Only the inner table join When the column has an index , To use it Index Nested-LoopJoin Connect .
- Because of the index , If the index is a secondary index and the returned data also includes other data of the inner table , Then it will return to the inner table to query the data , A few more IO operation .
3、Block Nested Loop Join(BNLJ)
- The nested loop connection of cache blocks caches multiple pieces of data at one time , Cache the columns participating in the query to Join Buffer in , Then take join buffer The data in the batch is matched with the data in the inner table , Thus reducing the number of outer cycles .
- When not used Index Nested-Loop Join When , By default Block Nested-Loop Join.
- Even if join buffer It also reduces the number of external cycles , Reduce internal circulation io frequency , But the connection conditions between records are compared (cpu Calculation ) The number of times cannot be less , So if the connection value is not an index , And the amount of data in the table is large , It's going to be a disaster
// Pseudo code
for (r in R) {
for (sbu in SBuffer) {
if (r satisfy condition sbu) {
output <r, s>;
}
}
}
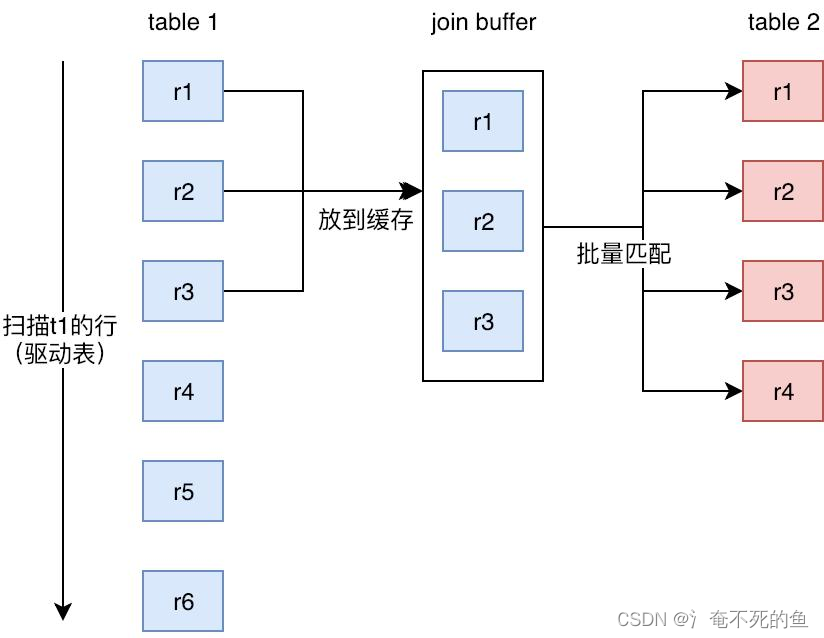
What is? Join Buffer?
(1)Join Buffer All columns participating in the query are cached instead of just Join The column of .
(2) Can be adjusted by join_buffer_size Cache size
(3)join_buffer_size The default value of is 256K,join_buffer_size The maximum value of is MySQL 5.1.22 Before the version is 4G-1, And later versions can be in 64 The application under bit operating system is greater than 4G Of Join Buffer Space .
(4) Use Block Nested-Loop Join The algorithm needs to turn on the optimizer to manage the configuration optimizer_switch Set up block_nested_loop by on, On by default .(5) Guess here joinbuf Stored data , Is similar to map The same mapping . That is, get
How to optimize JOIN Speed
- Driving big result sets with small result sets , Reduce the amount of data in the outer cycle :
If the columns joined by small and large result sets are index columns ,mysql When connecting inside, you will also choose to drive a large result set with a small result set , Because the cost of index query is relatively fixed , The less circulation there is in the outer layer ,join The faster the speed of . - Add an index to the matching condition : Try to use INLJ, Reduce the number of cycles in the inner table
- increase join buffer size Size : When using BNLJ when , The more data you cache at a time , The less times the outer table loops
- Reduce unnecessary field queries :
(1) When used BNLJ when , The fewer fields ,join buffer The more data is cached , The less cycles the outer table has ;
(2) When used INLJ when , If you can query without returning to the table , That is, to use the overlay index , It may prompt the speed .( Unverified , It's just a corollary )
Sort : Sort according to the fields of the drive table
The drive table can be sorted directly , For non drive meters ( Field sorting of ) You need to merge the results of the circular query ( A temporary table ) Sort ( Waste memory , Waste again cpu)!
Implement the plan to improve
ICP(Index Condition Pushdown) - Push... Under index conditions
Push... Under index conditions , Also called index push down , English full name Index Condition Pushdown, abbreviation ICP.
Index push down is MySQL5.6 Newly added features , Queries for optimizing data .
stay MySQL5.6 Before , When querying by using a non primary key index , The storage engine queries the data through the index , Then return the result to MySQL server layer , stay server The layer judges whether it meets the conditions .
stay MySQL5.6 And above , You can use the feature of index push down . When there is an indexed column as the judgment condition ,MySQL server Pass this part of the judgment conditions to the storage engine , Then the storage engine will filter out accord with MySQL server The index entry of the pass condition , That is, in the storage engine layer, according to the index conditions Filter Drop the unqualified index entries , Then return to the table to query the results , Return the result to MySQL server.
You can see , With the optimization of index push down , Under certain conditions , The storage engine layer will filter the data before returning to the table query , It can reduce the number of queries returned to the table by the storage engine .
for instance
Suppose there is a user information table user_info, There are three fields name, level, weapon( equipment ), Set up a joint index (name, level),user_info The initial data for the table is as follows :
| id | name | level | weapon |
|---|---|---|---|
| 1 | Dabin | 1 | keyboard |
| 2 | Gagne | 2 | Yuanhong |
| 3 | Weizhuang | 3 | Shark tooth |
| 4 | Big hammer | 4 | Hammer |
If you need to match the name, the first word is " Big ", also level by 1 Users of ,SQL The statement is as follows :
SELECT * FROM user_info WHERE name LIKE " Big %" AND level = 1;
So this one SQL How will it be implemented ?
The following is a case by case analysis .
First look at it. MySQL5.6 Previous versions .
Mentioned earlier MySQL5.6 Previous versions had no index push down , The implementation process is as follows :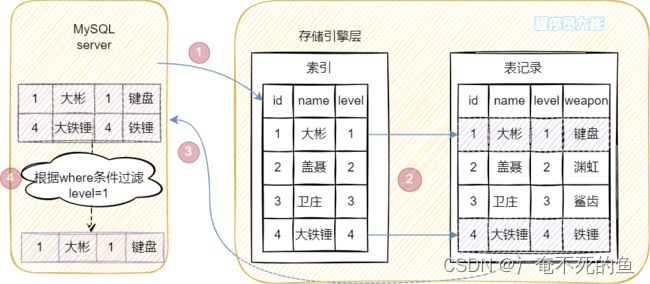
Query criteria name LIKE Not equivalent matching , according to Left most matching principle , stay (name, level) Only... Is used on the index tree name To match , Found two records (id by 1 and 4), Who got these two records id Query back to the table respectively , Then return the result to MySQL server, stay MySQL server Layer for level Field judgment . The whole process needs to go back to the table 2 Time .
And then look at it MySQL5.6 And above , Here's the picture .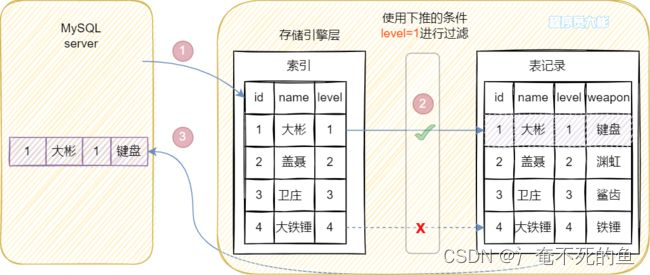
comparison 5.6 Previous versions , More optimization of index push down , During index traversal , Yes Fields in the index Make a judgment first , Filter out unqualified index entries , That's judgment level Is it equal to 1,level Not for 1 Then skip directly . So in (name, level) The index tree matches only one record , Then take the corresponding... Of this record id(id=1) Back to the table to query all data , The whole process returns to the table 1 Time .
have access to explain See if index push down is used , When Extra The value of the column is Using index condition, It indicates that index push down is used .
summary
As can be seen from the above example , Using index push down can be effective in some scenarios Reduce the number of times to return to the table , So as to improve query efficiency .
Sort to avoid
In fact, when querying according to conditions , Because the index is ordered , If the conditions are ordered, you can directly use the reading order of the index as the sorting result . Without additional sorting
Example
-- key There is an index
explain select * from app_user where app_user.age < 1999 order by app_user.key -- Using filesort
explain select * from app_user where app_user.key < 1999 order by app_user.key -- Avoid sorting
We know sql In language , The user cannot command the database to sort . Hiding from users is a formal operation SQL Design idea . But some commands in the database will sort the results , When the amount of data is large , Sorting can be very time-consuming . In this article, we discuss how to avoid unnecessary sorting , promote SQL Execution efficiency .
MySQL Two sorts are supported filesort and index, Using index Is the sort completed by scanning the index , and Using filesort It uses memory and even disk to complete sorting . therefore ,index Efficient ,filesort Low efficiency .
Will sort SQL command
- GROUP BY Clause
- ORDER BY Clause
- Aggregate functions (SUM,COUNT,AVG,MAX,MIN)
- DISTINCT
- Set operations (UNICON,INTERSECT,EXCEPT)
- Window function (RANK,ROW_NUMBER etc. )
The optimization of sorting and grouping is actually very similar , The essence is to sort first and then group , Follow the leftmost matching principle of index creation order . therefore , Take sorting as an example .
explain select app_user.age from app_user where app_user.age < 1999 group by app_user.age -- Using filesort
边栏推荐
- 富文本编辑:wangEditor使用教程
- 迅为IMX6Q开发板QT系统移植tinyplay
- 电商系统中红包活动设计
- leetcode:6110. 网格图中递增路径的数目【dfs + cache】
- [MySQL from introduction to proficiency] [advanced chapter] (V) SQL statement execution process of MySQL
- Learn kernel 3: use GDB to track the kernel call chain
- Progress in architecture
- MySQL stored procedure exercise
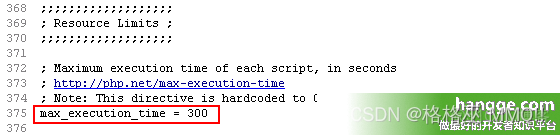
- Count the running time of PHP program and set the maximum running time of PHP
- MySQL triggers
猜你喜欢



随机推荐
尊重他人的行为
Ruiji takeout notes
Solutions to the problems of miui12.5 red rice k20pro using Au or povo2
数据中台概念
Blob, text geometry or JSON column'xxx'can't have a default value query question
Ml: introduction, principle, use method and detailed introduction of classic cases of snap value
Chapter 17 process memory
R语言使用epiDisplay包的followup.plot函数可视化多个ID(病例)监测指标的纵向随访图、使用stress.col参数指定强调线的id子集的颜色(色彩)
Popular framework: the use of glide
使用CLion编译OGLPG-9th-Edition源码
codeforce:C. Sum of Substrings【边界处理 + 贡献思维 + 灵光一现】
flink sql-client.sh 使用教程
R语言使用dplyr包的group_by函数和summarise函数基于分组变量计算目标变量的均值、标准差
nowcoder重排链表
Chapter 16 string localization and message Dictionary (2)
统计php程序运行时间及设置PHP最长运行时间
一文概览2D人体姿态估计
Pandora IOT development board learning (RT thread) - Experiment 3 button experiment (learning notes)
Vscode common plug-ins summary
【算法leetcode】面试题 04.03. 特定深度节点链表(多语言实现)