当前位置:网站首页>一文概览2D人体姿态估计
一文概览2D人体姿态估计
2022-07-04 12:52:00 【小白学视觉】
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达来自 | 知乎 作者 | 谢一宾
链接 | https://zhuanlan.zhihu.com/p/140060196
编辑 | 深度学习这件小事公众号
本文经作者授权转载,请勿二次转发
0. 前言
本文主要讨论2D的人体姿态估计,内容主要包括:基本任务介绍、存在的主要困难、方法以及个人对这个问题的思考等等。希望大家带着批判的目光阅读这篇文章,和谐讨论。
1. 介绍
2D人体姿态估计的目标是定位并识别出人体关键点,这些关键点按照关节顺序相连,就可以得到人体的躯干,也就得到了人体的姿态。

在深度学习时代之前,和其他计算机视觉任务一样,都是借助于精心设计的特征来处理这个问题的,比如pictorial structure。凭借着CNN强大的特征提取能力,姿态估计这个领域得到了长足的发展。2D人体姿态估计主要可以分为单人姿态估计(Single Person Pose Estimation, SPPE)和多人姿态估计(Multi-person Pose Estimation, MPPE)两个子任务。
单人姿态估计是基础,在这个问题中,我们要做的事情就是给我们一个人的图片,我们要找出这个人的所有关键点,常用的MPII数据集就是单人姿态估计的数据集。
在多人姿态估计中,我们得到的是一张多人的图,我们需要找出这张图中的所有人的关键点。对于这个问题,一般有自上而下(Top-down)和自下而上(Bottom-up)两种方法。
Top-down: (从人到关键点)先使用detector找到图片中的所有人的bounding box,然后在对单个人进行SPPE。这个方法是Detection+SPPE,往往可以得到更好的精度,但是速度较慢。
Bottom-up: (从关键点到人)先使用一个model检测(locate)出图片中所有关键点,然后把这些关键点分组(group)到每一个人。这种方法往往速度可以实时,但是精度较差。
2. 难点
2D人体姿态估计中有许多难点,很多问题可以通过网络结构的优化来解决,更准确地说,就是利用好多尺度、多分辨率的特征。
遮挡(自遮挡,被其他人遮挡)
扩大感受野,让网络自己去学习被遮挡的关系
人的尺度不一,拍照角度不一
多尺度特征融合
各种各样的姿态
考验网络的容量,深度
光照
在数据预处理中加入光照变化的因素,对每个通道做偏移
遮挡问题是比较难解决的,很多工作也都在发力于此。除了网络结构,数据的预处理也很重要,对于SPPE,要尽量将人放在图片中心。后处理也同样重要,怎么减小对heatmap的argmax操作的量化误差。人体不同于其他物体,人体不同关键点之间是有空间约束关系的,怎么去best capture various spatial relationships between human joints是关键。
3. 方法
本节主要对姿态估计的方法进行简单介绍,由于篇幅有限,难以呈现论文的全貌,大家可自行阅读原论文。2D姿态估计方法可以分为单人姿态估计(SPPE)和多人姿态估计(MPPE)两个部分,其中多人姿态估计又分为自顶向下(Top-down)和自底向上(Bottom-up)两种。
3.1. SPPE
DeepPose (Google, 2014)[1]
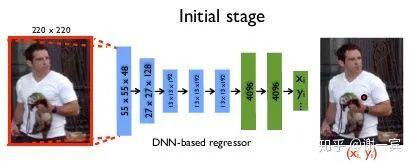
DeepPose
使用AlexNet作为backbone
直接回归关节点的坐标
使用级联的结构来refine结果
Joint training with CNN and Graphical Model(LeCun, 2014)[2]
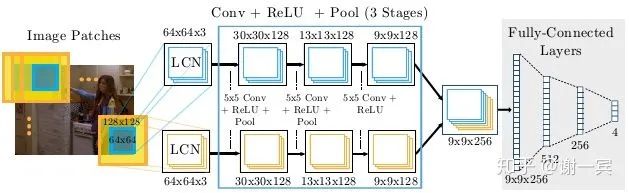
开始使用heatmap
CPM (CMU, 2016)[3]
全卷积网络,可以端到端训练
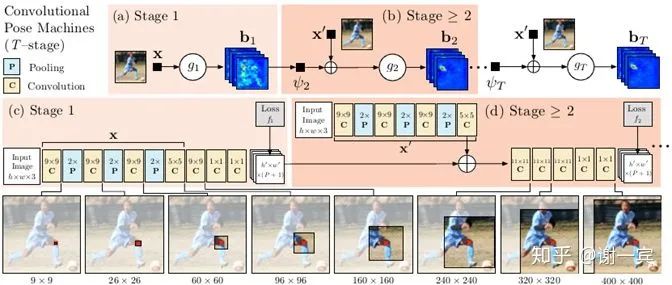
CPM是SPPE中的首篇经典之作,来自CPM的Jia Deng组(之后同组改进出了OpenPose,是目前Bottom-up方法中影响力最大的方法),CPM创新之处主要在于其提出的网络结构。
网络有多个stage组成,以第二个stage为例,他的输入由两部分组成,一个是上一个stage预测出的heatmap,一个是自己这个stage中得到的feature map,也就是在每一个stage都做一次loss计算,这样做可以使网络收敛更快也有助于提高精度。
上一层预测的heatmap可以提供丰富的spatial context,这对关节点的识别是非常重要的
正式开启e2e学习时代
Stacked Hourglass Network (Jia Deng组, 2016)[4]
hourglass影响深远,是常用的backbone,时至今日,效果依然很能打。
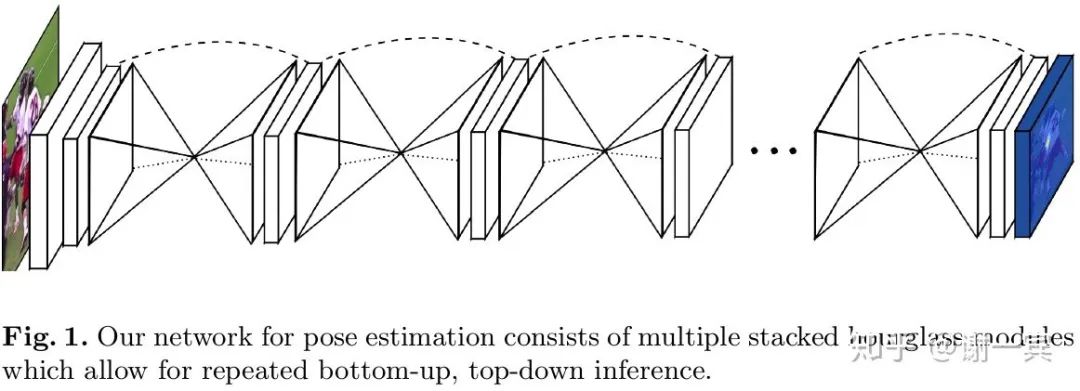
该工作的主要创新在于网络结构方面的改进,从图中可以看出,形似堆叠的沙漏。
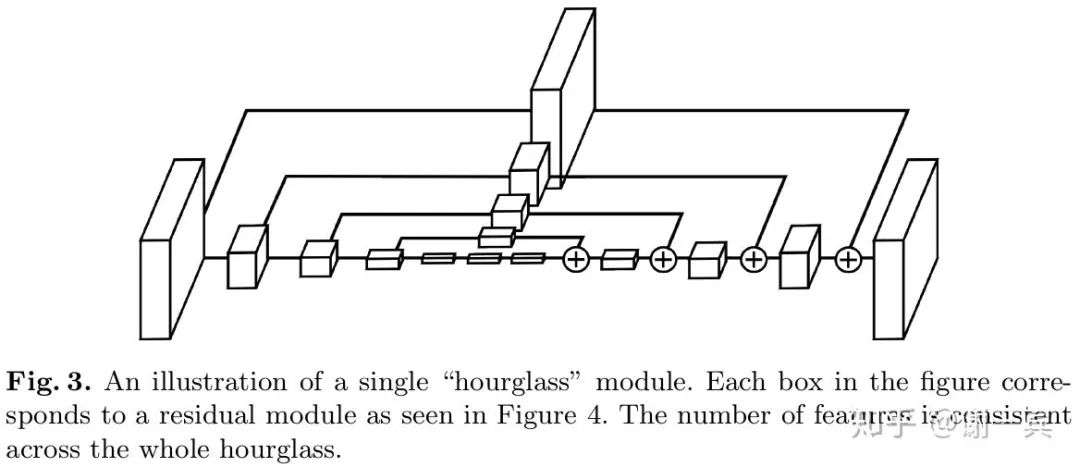
每一个沙漏模块包含了对称的下采样和上采样的过程,每一个box都代表了一个有跨层连接的子模块
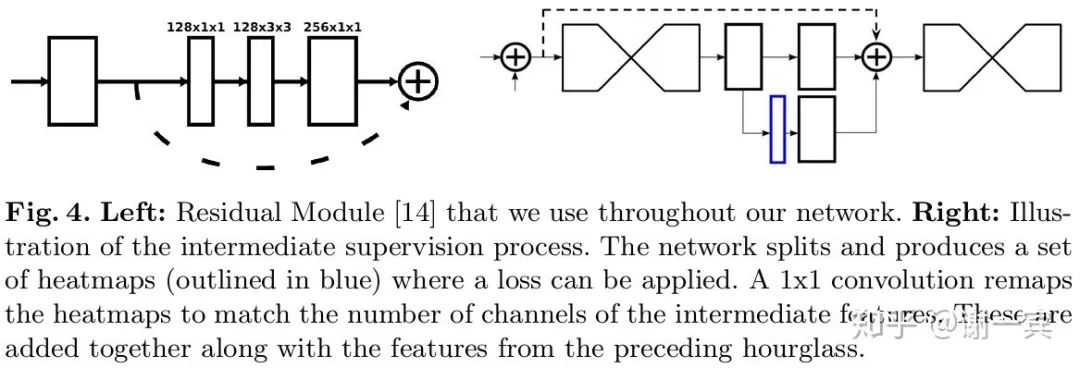
网络使用了中间监督,也就是图中的蓝色框是一个预测的heatmap,这加快了网络的收敛也提高了实际效果
Fast Human Pose (2019)[5]
backbone是hourglass,这篇文章把知识蒸馏用在了pose问题上,算是一次很好的尝试
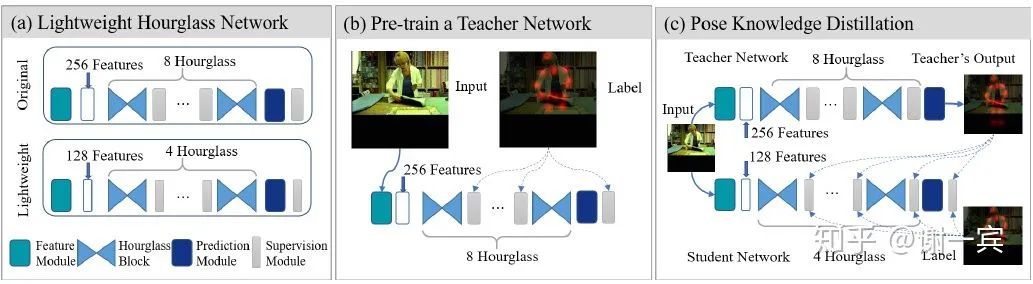
为了追求cost-effective,需要compact的网络结构
4-stage hourglass可以取得95%的8-stage的效果
一半的channel数(128)只会导致1%的performance drop
使用蒸馏来做监督的增强,Students learn knowledge from books (dataset) and teachers (advanced networks).
3.2. MPPE
3.2.1. Top-down
G-RMI (Google, 2017)[6]
使用Faster-RCNN作为人体检测器,姿态部分基于ResNet估计了offset来refine

Faster-RCNN得到bounding box之后进行image cropping,使得所有box具有同样的纵横比,然后扩大box来包含更多图像上下文
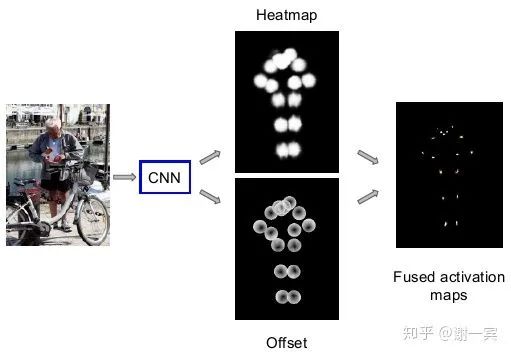
使用ResNet作为backbone来估计heatmap和offset vector,因为得到heatmap之后我们往往还需要一个argmax的操作才能得到关节点的坐标,而这个过程中由于网络的下采样过程,heatmap势必分辨率比原图更小,所以得到的坐标会出现偏移,因此又估计了一个offset vector来补偿掉这种量化误差。
OKS-based NMS:基于关键点相似度来衡量两个候选姿态的重叠情况,在目标检测中常基于IoU来做NMS,但是姿态估计中输出的是关键点,更适合用这种属性来衡量。
RMPE (上交卢策吾老师组, 2017)[7]
上交卢策吾老师组的工作,是国内比较好的姿态估计方面的工作,AlphaPose开源代码影响广泛。
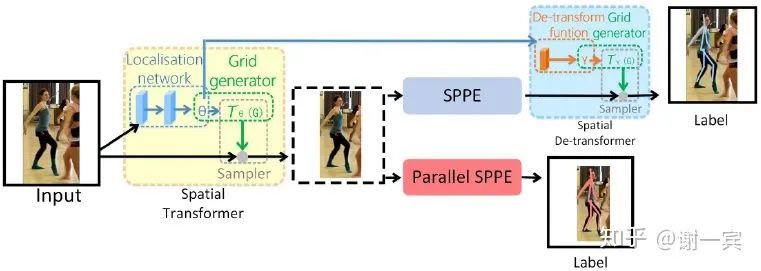
SSTN(Symmetric Spatial Transformer Network):在不准确的bounding box中提取担任区域
STN来选择RoI
SPPE帮助STM得到准确的区域
PNMS(Parametric Pose Non-Maximum-Suppression)来去除冗余的姿态
PGPG(Pose-Guided Proposals Generator)
Compositional Human Pose Regression (MSRA, 2018)[8]
MSRA Xiao Sun组的工作,从输出表示下手,由于heatmap表示的量化误差和坐标表示的效果不好,作者提出使用bones as representation。
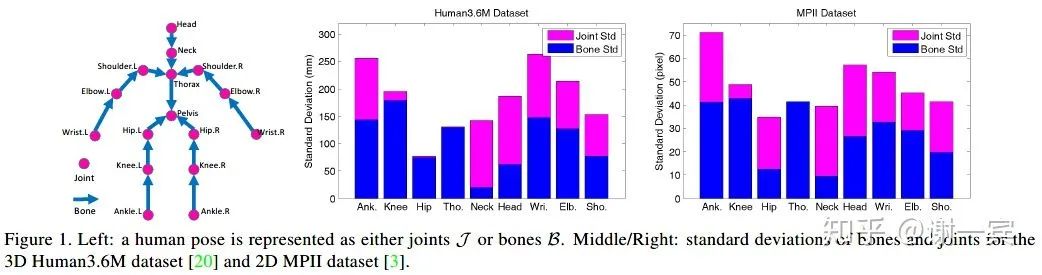
bones比joints更稳定,并且可以包含更多的几何信息,为了避免直接计算bones的MSE所引起的累积误差,作者提出考虑长距离目标,会考虑两关节点之间所有bones之和。作者把输出表示重新参数化了,与网络结构无关,同样可以用于3D。
CPN (旷视,2018)[9]
采用的是top-down的方法,采用的网络结构是一个U-Shape的结构,因为对于关键点定位来说,不同尺度的特征会起到不同的作用,浅层的特征可以帮助定位,深层的特征可以帮助识别什么什么部位。而且关键点的定位是有难易之分的,所以,很自然的想法,要找到难定位的关键点,对它们进行更多的操作,所以就有了难例挖掘和RefineNet。
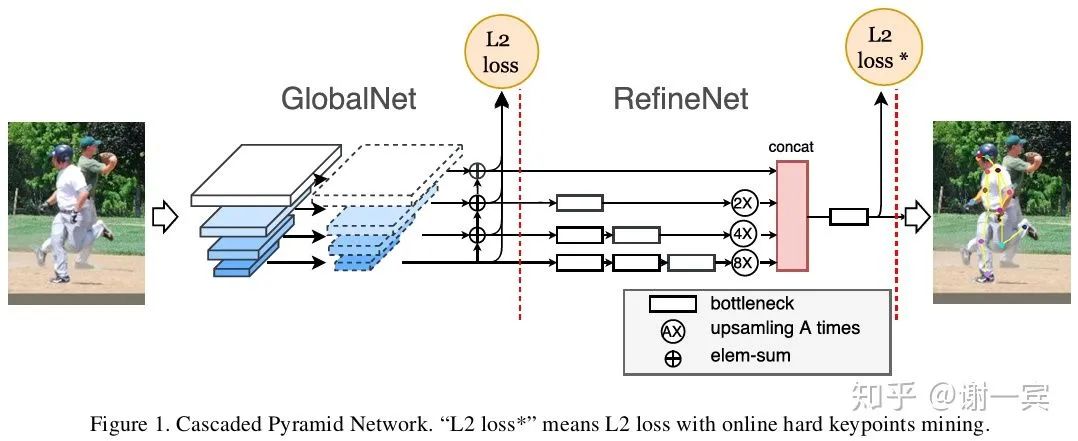
多尺度特征信息的融合是网络设计的一个很大的目标,作者使用 GlobalNet (global pyramid network, U-Shape)来处理easy keypoints,GlobalNet中包含了下采样和上采样(插值非转置卷积)的过程。
使用RefineNet (pyramid refined network)来处理hard keypoints
OHKM(online hard keypoints mining)用来找出hard keypoints,类似于检测中的OHEM
MSPN (旷视,2018)[10]
在CPN的基础上做了改进,类似于stacked hourglass的结构,把CPN也堆叠起来了,他们也提出detector精度不是很重要,只要够用就行。
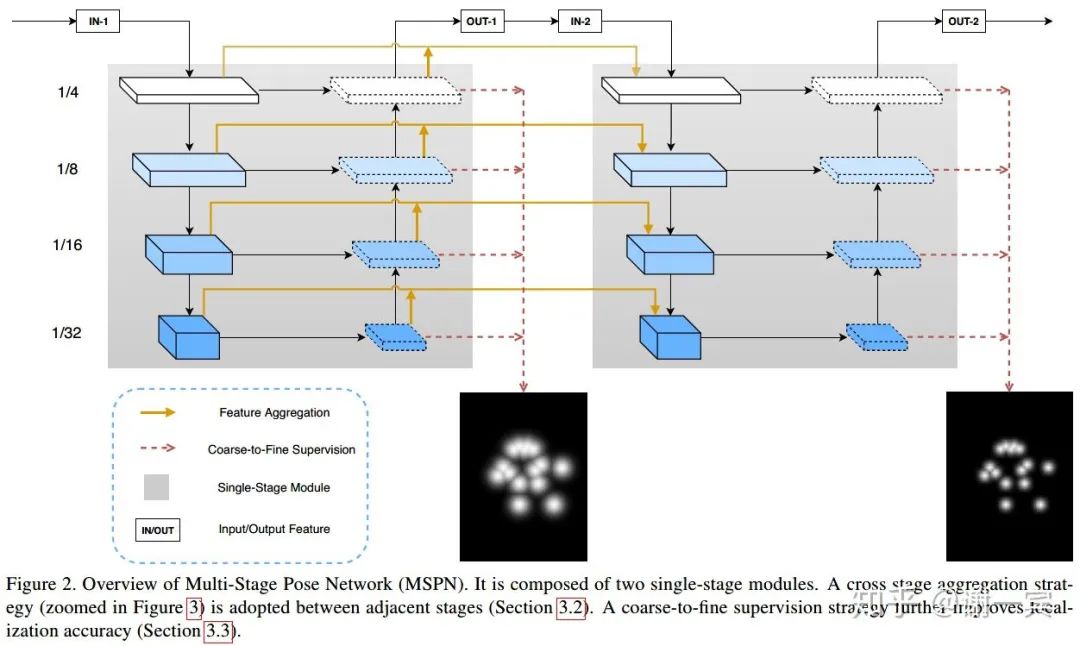
网络结构方面的改进
Simple Baseline (MSRA, 2018)[11]
MSRA Bin Xiao等人的工作(后续也推出了HRNet系列和HigherHRNet),真的很simple,作者就是把hourglass和CPN中的upsample部分用deconvolution做了,作者论文中提到想探究how good could a simple method be? 真是会写。
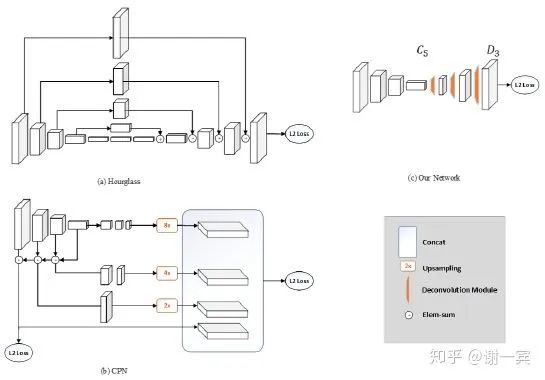
从图中不难看出,这个网络结构非常简洁,作者使用Deconvolution来做上采样,网络中也没有不同特征层之间的跨层连接,和经典的网络结构Hourglass和CPN相比都十分简洁。
MultiPoseNet (2018)[12]
作者使用了两个subnet,一个用来输出keypont和segmentationd的heatmap,另一个是detector,用来输出人体的bounding box,然后将这两种输出送到PRN,Pose Residual Network中,得到最终的pose。最关键的部分就是PRN,作者说他们先从data中学习pose structures,然后可以解决遮挡的问题。这部分作者没有讲清楚,呵呵。作者给出的结果是很好的,在单1080ti上COCO数据集可以达到23FPS的速度,效果也是与SOTA的Top-down方法competitive的。
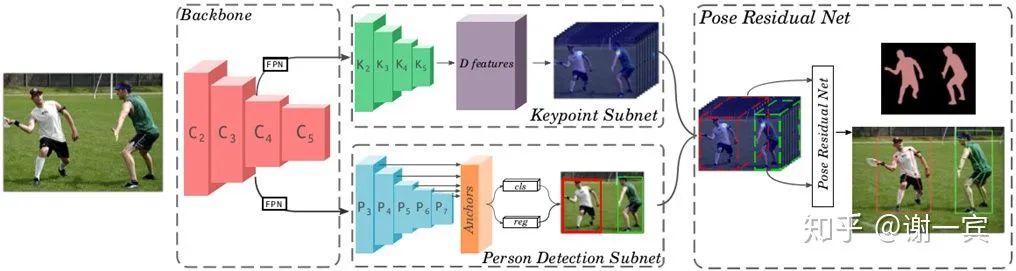
backbone也就是用来提取特征的部分采用的是resnet和两个FPN(用两个的原因是因为后面要接两个subnet)
keypoint subnet用来输出keypoint和segmentation的heatmap
person detect subnet用来检测人体,使用的是RetinaNet作为detector
pose residual network输出最终的pose,说是在学习了data的pose structures之后可以有效应对遮挡的问题
Deeply learned compositional models (2019)[13]
我没有很明白他这个compositional的意思,大概是把人体当成一个树结构,children可以帮助parent,也就是文章中所说的bottom-up (不是常提到的那个),parent也可以帮助children,也就是文章中所说的top-down
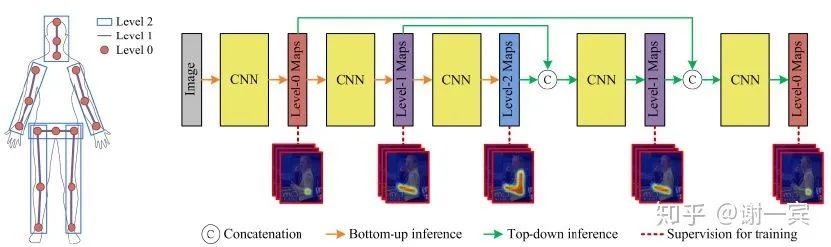
compositional models
HRNet (MSRA, 2019)[14]
MSRA Bin Xiao等人继simple baseline之后又一力作。网络常常包括下采样和上采样过程,上采样的目的就是要得到高分辨率图像,基于这一观察,该项工作始终在一分支保留着高分辨率的图像,HRNet是像ResNet一样的通用backbone,但是其在姿态估计方面的影响是比较大的,效果也是比较好的。
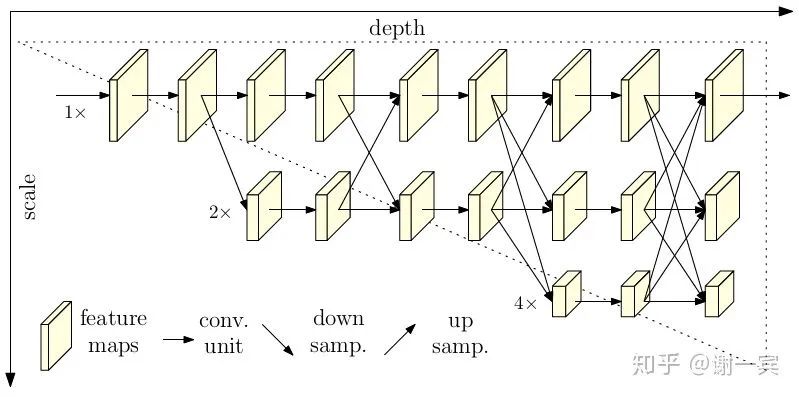
各个scale之间互相fuse,并不是一个串联的下采样过程,这样保留了原分辨率的feature,会有很好的spatial信息。
Enhanced Channel-wise and Spatial Information (字节跳动, 2019)[15]
这项工作主要是对网络结构的改进,主要创新点在于加入channel shuffle和注意力机制。
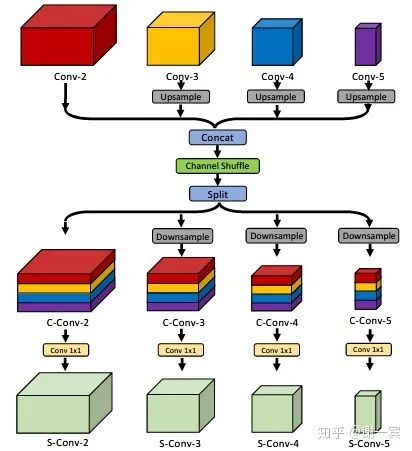
Channel Shuffle Module (CSM): reshape-transpose-reshape, 经过这一通操作之后,希望feature能够和通道的上下文信息相关。
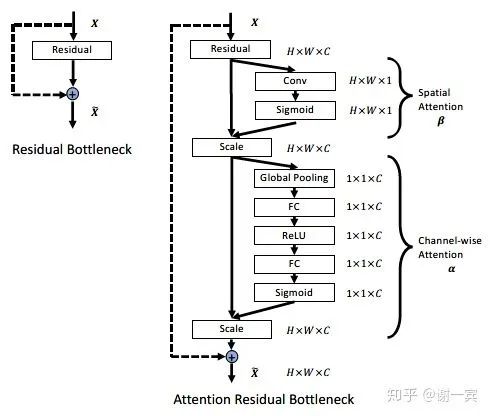
spatial attention: (feature level)希望网络对于特征图是pay attention to task-related regions而不是整张图片。
Channel-wise Attention: (channel level) 从SE-Net中借鉴来,主要包含GAP和Sigmoid两个步骤,希望网络可以选择更好的通道来detect pattern。
Related Parts Help (2019)[16]
这篇文章很好,作者提到人体并不是所有keypoint都是相关的,所以用一个shared feature来预测不好,作者根据mutual information把人体关键点分成五类,网络先学一个shared feature,然后再为这五类分出五个branch,学习specific features for relates parts Evaluation: 这个方法很好,值得借鉴,相关的可以提供帮助,不相关的keypoint硬是用shared feature来预测,反而会导致文章中所说的negative transfer
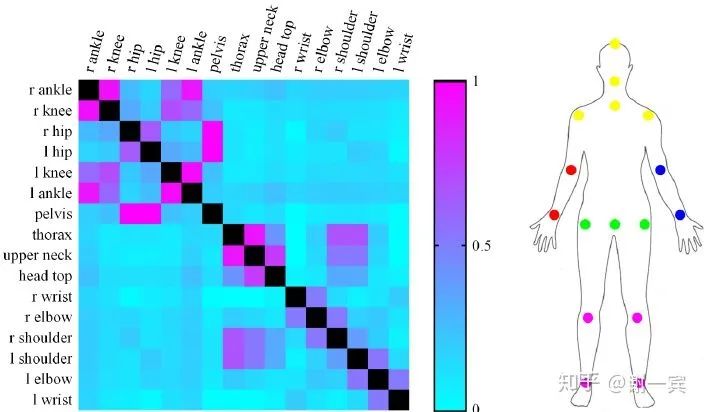
Related body parts 把keypoint分成多个group,根据mutual information
Part-based branching network (PBN) learn specific features for each group of related parts
Crowd Pose (上交卢策吾老师组,2019)[17]
这项工作主要是要处理拥挤场景下的多人姿态估计问题,并且在MPII, COCO和AI Challenger数据集基础上做了一个新的crowd benchmark。
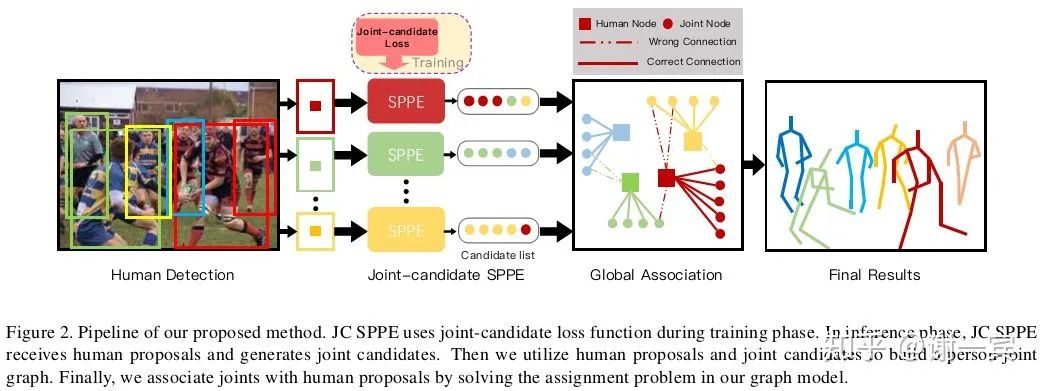
在拥挤场景下,在同一个box内,我们可能需要处理很多其他人的关键点,该项工作设计了joints candidate loss来估计multi-peak heatmaps,让所有可能的关节点都作为候选。
Person-joint Graph: joint node是通过关节点间的距离来建立,person node通过检测的human proposals来建立,两者之间的edge通过看是否有contribution来建立。由此建立了一个人-关节的graph,也就转化到了图论问题上,目标就是最大化二分图中的边权重。使用updated Kuhn-Munkres解决这个问题。
Single-Stage Multi-Person Pose Machines (NUS, 2019)[18]
backbone是hourglass,提出分级的SPR,把person instance and position information 统一了起来,所以可以做到single-stage。估计人的中心root joint,其他关节由估计的displacement来处理。
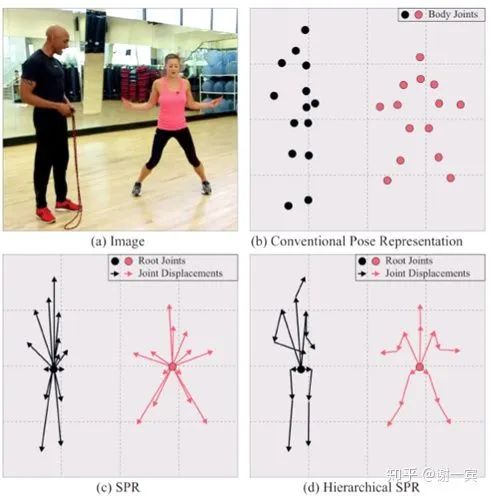
Hierarchical SPR
A unique root for each person
Several joint displacements for each joint
heatmap for root joint (L2 loss)
dense displacement map for each joint (smooth L1 loss)
3.2.2. Bottom-up
DeepCut (Germany, 2016)[19]
用了Fast R-CNN和ILP,速度比较慢

pipeline(Bottom-up)
detect 检测人体关键点(Adapted Fast R-CNN)并且把他们表示为graph中的节点
label 使用人体关节点类别给检测出的关键点分类,比如arm, leg
partition 将关键点分组到同一个人
使用pairwise terms来做优化
Associative Embedding (Jia Deng组,2016)[20]
基于Jia Deng组之前的stacked hourglass network做的(也启发了后来该组的CornerNet)作者的insight很好,Many CV tasks can be viewed as joint detection and grouping,提出tag heatmap来group人体部件。
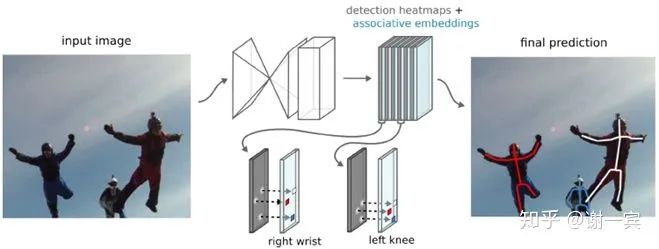
produce detection heatmaps and associate embedding tags together (bottom-up but single-stage) and then match detections to others that share the same embedding tag
主要的工作在于提出了associate embedding tag,也就是说预测每个关节点的时候也同时预测这个关节点的tag值,具有相同tag值的就是同一个人的关节点
DeeperCut (Germany, 2017)[21]
基于DeepCut的改进
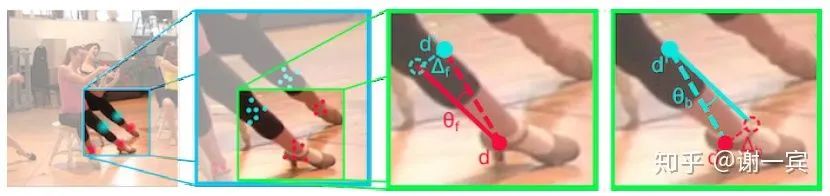
使用深层的ResNet架构来检测body part
使用image-conditioned pairwise terms来做优化,可以将众多候选节点减少,通过候选节点之间的距离来判断该节点是否重要
OpenPose (CMU, 2017)[22]
可以做到实时,作者在CVPR上的报告直接拿笔记本现场对着观众演示,十分惊艳,不仅可以估计姿态,还可以估计脸、手和脚的关键点,也就是全身都估计了遍。是目前Bottom-up方法中影响最大的工作。

网络结构基于CPM改进,网络包含两个分支,一个分支预测heatmap,另一个分支预测paf(part affine field),paf也是这项工作的关键所在。
paf是两个关节点连接的向量场,可以把它看做肢体,以paf为基础,把group的问题转化文二分图匹配(bipartite graph)的问题,使用匈牙利算法求解。
PersonLab (2018)[23]
这篇也是估计了offset来做refine,并且也是multi-task的,估计了short mid long三种offsets,各自都有不同的作用。
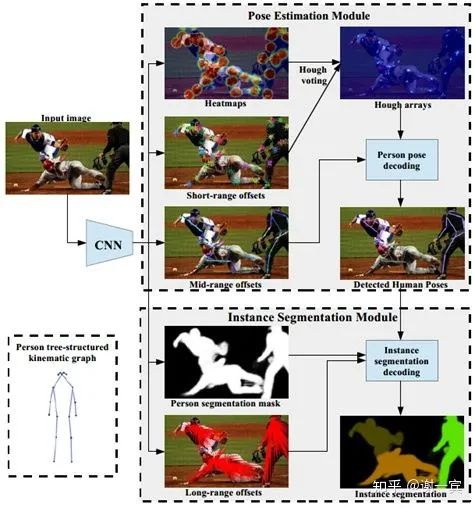
short-range offsets to refine heatmaps
mid-range to predict pairs of keypoints
greedy decoding to group keypoints into instances
PifPaf (EPFL, 2019)[24]
该工作主要贡献在于提出PIF和PAF(非OpenPose的PAF)这两种向量。
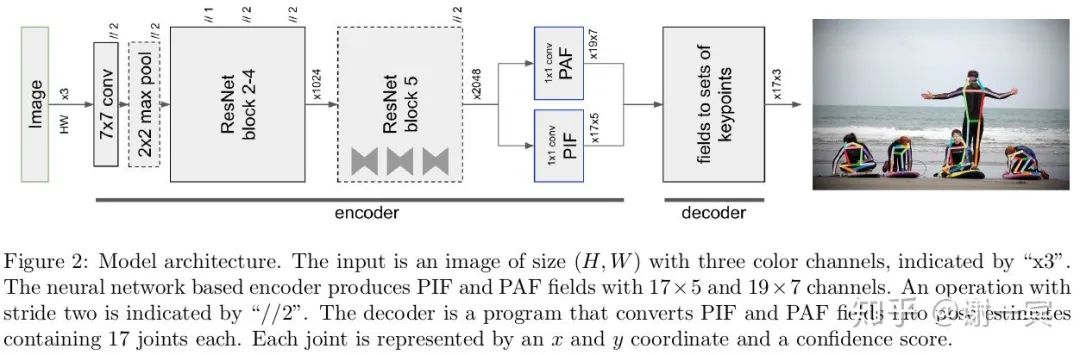
从图中可以看出,网络基于ResNet,encoder最后输出两个分支,PIF和PAF向量场。
PIF向量场是17x5,其中17是关节数,5表示用于优化heatmap的值。
PAF向量场是19x7,其中19代表了19种肢体连接,7表示了confidence和offset来优化肢体向量的值。
关键点由PIF给出,关键点之间的连接由PAF给出,接下来就是使用Greedy Decoding进行group的过程了。
HigherHRNet (字节跳动,2020)[25]
字节跳动Bin Xiao团队的工作,基于之前的HRNet工作和associative embedding。
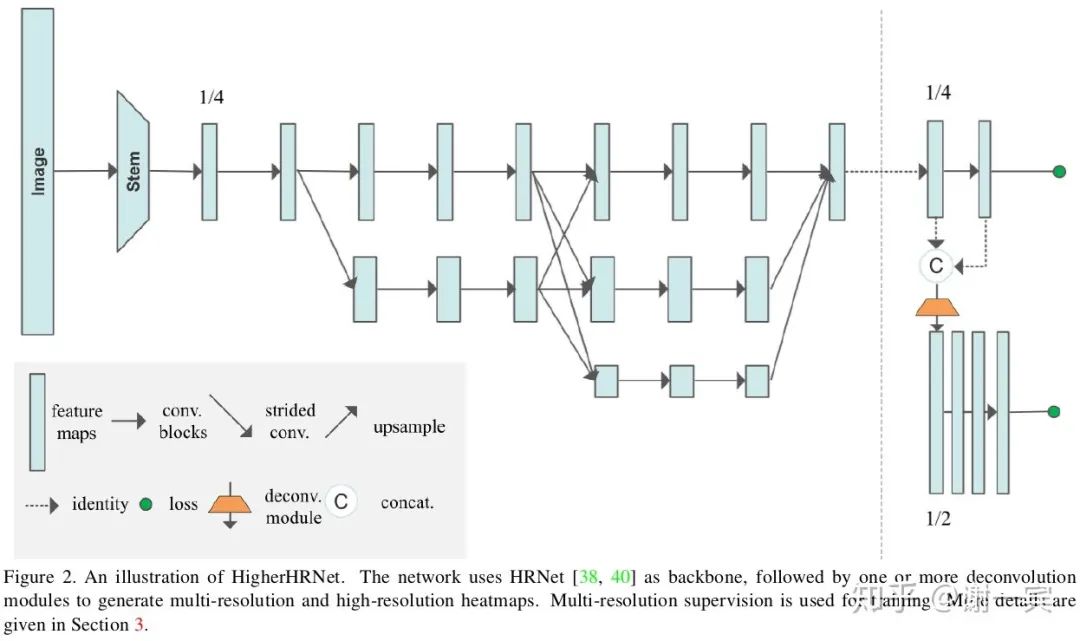
HRNet在bottom-up方法中的尝试,associative embedding加上更强大的网络。
4. 总结
大体的创新点主要集中在网络结构和特征表示两个方面,网络结构是一个填不满的坑,怎么更好的抽取信息,利用信息是网络结构设计的本质。在输出特征的表示方面主要有heatmap和自定义的向量场,人为设计的向量也许可以更好地指引网络训练。人体的关节点不是孤立的,利用好这种先验的肢体关系也可以更好地指导网络训练。
好消息!
小白学视觉知识星球
开始面向外开放啦

下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~边栏推荐
- redis 日常笔记
- The font of markdown grammar is marked in red
- Understand chisel language thoroughly 09. Chisel project construction, operation and testing (I) -- build and run chisel project with SBT
- 【FAQ】華為帳號服務報錯 907135701的常見原因總結和解决方法
- Unity shader learning (3) try to draw a circle
- 【信息检索】链接分析
- ML之shap:基于boston波士顿房价回归预测数据集利用Shap值对LiR线性回归模型实现可解释性案例
- Learn kernel 3: use GDB to track the kernel call chain
- Leetcode 61: 旋转链表
- 【云原生】我怎么会和这个数据库杠上了?
猜你喜欢
How to package QT and share exe
【Matlab】conv、filter、conv2、filter2和imfilter卷积函数总结

Test evaluation of software testing
Detailed index of MySQL
Leetcode T48:旋转图像
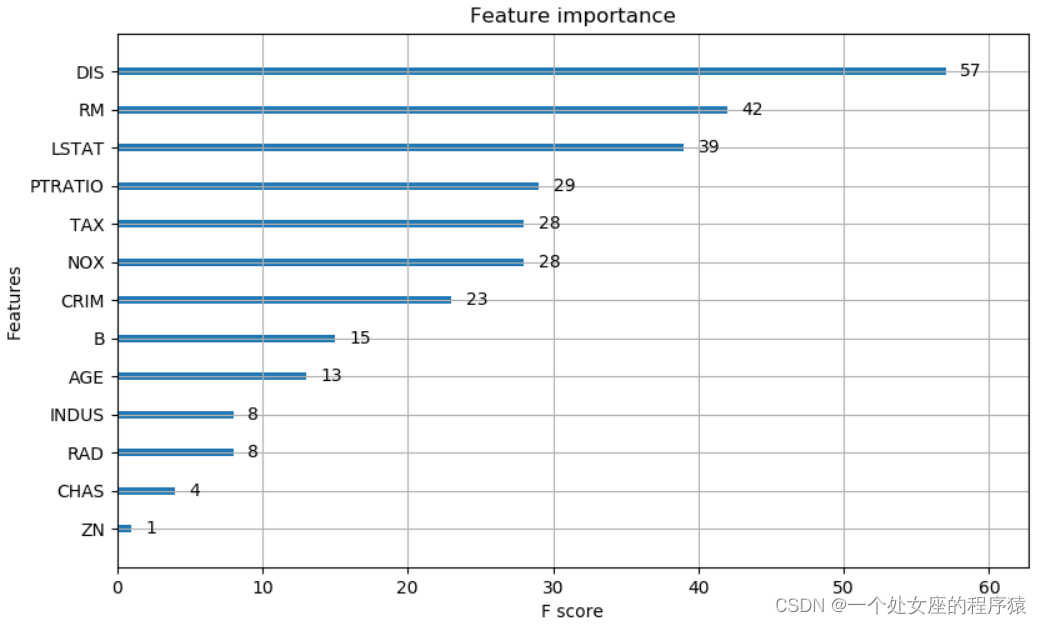
ML之shap:基于boston波士顿房价回归预测数据集利用shap值对XGBoost模型实现可解释性案例

迅为IMX6Q开发板QT系统移植tinyplay
Learn kernel 3: use GDB to track the kernel call chain
The implementation of OSD on rk1126 platform supports color translucency and multi-channel support for Chinese

Introducing testfixture into unittest framework
随机推荐
ViewModel 初体验
ML之shap:基于boston波士顿房价回归预测数据集利用shap值对XGBoost模型实现可解释性案例
数据仓库面试问题准备
去除重複字母[貪心+單調棧(用數組+len來維持單調序列)]
Rich text editing: wangeditor tutorial
R语言使用epiDisplay包的followup.plot函数可视化多个ID(病例)监测指标的纵向随访图、使用stress.col参数指定强调线的id子集的颜色(色彩)
聊聊保证线程安全的 10 个小技巧
[R language data science]: cross validation and looking back
Install and use MAC redis, connect to remote server redis
富文本编辑:wangEditor使用教程
One architecture to complete all tasks - transformer architecture is unifying the AI Jianghu on its own
nowcoder重排链表
Ws2818m is packaged in cpc8. It is a special circuit for three channel LED drive control. External IC full-color double signal 5v32 lamp programmable LED lamp with outdoor engineering
Map of mL: Based on Boston house price regression prediction data set, an interpretable case is realized by using the map value to the LIR linear regression model
Understand chisel language thoroughly 05. Chisel Foundation (II) -- combinational circuits and operators
leetcode:6110. 网格图中递增路径的数目【dfs + cache】
【信息检索】分类和聚类的实验
[FAQ] summary of common causes and solutions of Huawei account service error 907135701
R语言使用dplyr包的mutate函数对指定数据列进行标准化处理(使用mean函数和sd函数)并基于分组变量计算标准化后的目标变量的分组均值
MATLAB中tiledlayout函数使用