当前位置:网站首页>Go language implementation principle -- lock implementation principle
Go language implementation principle -- lock implementation principle
2022-07-05 23:11:00 【There is too much uncertainty in life】
Contents of this article
Lock implementation principle
1、 summary
In multithreaded environment , There are often A critical region , At this time, we only hope that only one thread can enter A critical region perform , Atomic operations of the operating system can be used to build The mutex , This approach is simple and efficient , But it can't deal with some complex situations , for example :
- The lock is occupied by a thread for a long time , Other processes will idle and wait meaninglessly , waste CPU resources
- Because everyone is fighting for the lock , So some threads may not be able to grab the lock all the time
In order to solve the above problems , Inside the operating system, a Waiting in line , For subsequent wakeups , Prevent it from idling all the time . An operating system level lock will lock the entire thread , And lock preemption will also occur context switching .
stay Go In language , It has more lightweight coroutines than threads , And it also realizes a more lightweight mutex based on the coroutine , Usage examples are as follows :
var count int64 = 0
var m sync.Mutex
func main() {
go add()
go add()
}
func add() {
m.Lock()
count++
m.Unlock()
}
2、 Realization principle
Go The mutex of language is used sync/atomic Atomic operations in the package spinlocks , In fact, it's just CAS( If you don't know it yet, you can learn the principle of this algorithm ), The sample code is as follows :
var count int64 = 0
var flag int64 = 0
func main() {
go add()
go add()
}
func add() {
for {
// Try to flag Set to new value 1
if atomic.CompareAndSwapInt64(&flag, 0, 1) {
count++
// take flag Revert to old value 0
atomic.StoreInt64(&flag, 0)
}
}
}
The above example shows CompareAndSwap Method , Actually atomic There's also AddInt64 Method , Atomic addition operation can be realized .
3、 The mutex
The source code of mutex is located in src/sync/mutex.go in , The following will explain the principle of mutex through the source code
3.1、Lock
Lock Method
// Lock locks m.
// If the lock is already in use, the calling goroutine
// blocks until the mutex is available.
// translate : If the mutex lock has been used , Calling this method goroutine It will block , Until the mutex is available .
func (m *Mutex) Lock() {
// Fast path: grab unlocked mutex.
// Fast path
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
if race.Enabled {
race.Acquire(unsafe.Pointer(m))
}
return
}
// Slow path (outlined so that the fast path can be inlined)
// Slow path
m.lockSlow()
}
From the above code, it is not difficult to see , call Lock When the method is used , I will try the fast path first , That's one time CAS operation , If successful, it will return directly , It won't block . If it doesn't work , It indicates that the current mutex is being used , Then it will enter lockSlow Method .
lockSlow Method
func (m *Mutex) lockSlow() {
var waitStartTime int64
starving := false
awoke := false
iter := 0
old := m.state
for {
// Don't spin in starvation mode, ownership is handed off to waiters
// so we won't be able to acquire the mutex anyway.
// In normal mode ( Non starvation mode ), If you can spin , Will continue to spin
if old&(mutexLocked|mutexStarving) == mutexLocked && runtime_canSpin(iter) {
// Active spinning makes sense.
// Try to set mutexWoken flag to inform Unlock
// to not wake other blocked goroutines.
if !awoke && old&mutexWoken == 0 && old>>mutexWaiterShift != 0 &&
atomic.CompareAndSwapInt32(&m.state, old, old|mutexWoken) {
awoke = true
}
// The first stage : The spin ( Idle for a certain time )
runtime_doSpin()
iter++
old = m.state
continue
}
new := old
// Don't try to acquire starving mutex, new arriving goroutines must queue.
// You will not try to acquire the lock in hunger mode , Instead, it is directly added to the waiting queue
if old&mutexStarving == 0 {
new |= mutexLocked
}
if old&(mutexLocked|mutexStarving) != 0 {
new += 1 << mutexWaiterShift
}
// The current goroutine switches mutex to starvation mode.
// But if the mutex is currently unlocked, don't do the switch.
// Unlock expects that starving mutex has waiters, which will not
// be true in this case.
// Switch to starvation mode , If the mutex has been unlocked , Then do not switch
if starving && old&mutexLocked != 0 {
new |= mutexStarving
}
if awoke {
// The goroutine has been woken from sleep,
// so we need to reset the flag in either case.
if new&mutexWoken == 0 {
throw("sync: inconsistent mutex state")
}
new &^= mutexWoken
}
if atomic.CompareAndSwapInt32(&m.state, old, new) {
if old&(mutexLocked|mutexStarving) == 0 {
break // locked the mutex with CAS
}
// If we were already waiting before, queue at the front of the queue.
// If I had been waiting , Then it is added to the head of the waiting queue
queueLifo := waitStartTime != 0
// timing ( Prevent a coroutine from occupying the mutex for a long time )
if waitStartTime == 0 {
waitStartTime = runtime_nanotime()
}
// The second stage : Control by semaphore
runtime_SemacquireMutex(&m.sema, queueLifo, 1)
// runtime_nanotime()-waitStartTime > starvationThresholdNs Indicates that the exclusive lock cannot be occupied for more than 1ms
// The lock has not been acquired for a long time , Into starvation mode
starving = starving || runtime_nanotime()-waitStartTime > starvationThresholdNs
old = m.state
if old&mutexStarving != 0 {
// If this goroutine was woken and mutex is in starvation mode,
// ownership was handed off to us but mutex is in somewhat
// inconsistent state: mutexLocked is not set and we are still
// accounted as waiter. Fix that.
if old&(mutexLocked|mutexWoken) != 0 || old>>mutexWaiterShift == 0 {
throw("sync: inconsistent mutex state")
}
delta := int32(mutexLocked - 1<<mutexWaiterShift)
if !starving || old>>mutexWaiterShift == 1 {
// Exit starvation mode.
// Critical to do it here and consider wait time.
// Starvation mode is so inefficient, that two goroutines
// can go lock-step infinitely once they switch mutex
// to starvation mode.
// Out of hunger mode
delta -= mutexStarving
}
atomic.AddInt32(&m.state, delta)
break
}
awoke = true
iter = 0
} else {
old = m.state
}
}
if race.Enabled {
race.Acquire(unsafe.Pointer(m))
}
}
lockSlow Inside the method is actually a for loop ,for The first of the cycle if It's actually spin , among ,runtime_canSpin The source code of the method is as follows :
const(
...
active_spin = 4
...
)
func sync_runtime_canSpin(i int) bool {
// sync.Mutex is cooperative, so we are conservative with spinning.
// Spin only few times and only if running on a multicore machine and
// GOMAXPROCS>1 and there is at least one other running P and local runq is empty.
// As opposed to runtime mutex we don't do passive spinning here,
// because there can be work on global runq or on other Ps.
if i >= active_spin || ncpu <= 1 || gomaxprocs <= int32(sched.npidle+sched.nmspinning)+1 {
return false
}
if p := getg().m.p.ptr(); !runqempty(p) {
return false
}
return true
}
By annotating , You can know the condition of spin :
- The number of spins is less than 4 Time
- CPU The number of cores is greater than 1
- Logic processor P The number of >1 And there's one P There is no running collaboration on
If the spin condition is satisfied , You will enter if Sentence block , And then we'll do runtime_doSpin() Method , Source code is as follows :
const (
active_spin_cnt = 30
)
func sync_runtime_doSpin() {
procyield(active_spin_cnt)
}
Called procyield It's actually an assembly code , Will execute 30 Time of PAUSE Instructions , It is equivalent to telling the processor , This code sequence is a circular wait .
After spin , If the lock has not been acquired , Then we will enter the second stage : adopt Semaphore Synchronous control , In the source code, the corresponding is runtime_SemacquireMutex(&m.sema, queueLifo, 1) Method , The specific source code is as follows :
func sync_runtime_SemacquireMutex(addr *uint32, lifo bool, skipframes int) {
semacquire1(addr, lifo, semaBlockProfile|semaMutexProfile, skipframes)
}
func semacquire1(addr *uint32, lifo bool, profile semaProfileFlags, skipframes int) {
gp := getg()
if gp != gp.m.curg {
throw("semacquire not on the G stack")
}
// Easy case.
if cansemacquire(addr) {
return
}
// Harder case:
// increment waiter count
// try cansemacquire one more time, return if succeeded
// enqueue itself as a waiter
// sleep
// (waiter descriptor is dequeued by signaler)
s := acquireSudog()
root := semroot(addr)
t0 := int64(0)
s.releasetime = 0
s.acquiretime = 0
s.ticket = 0
if profile&semaBlockProfile != 0 && blockprofilerate > 0 {
t0 = cputicks()
s.releasetime = -1
}
if profile&semaMutexProfile != 0 && mutexprofilerate > 0 {
if t0 == 0 {
t0 = cputicks()
}
s.acquiretime = t0
}
for {
lockWithRank(&root.lock, lockRankRoot)
// Add ourselves to nwait to disable "easy case" in semrelease.
atomic.Xadd(&root.nwait, 1)
// Check cansemacquire to avoid missed wakeup.
if cansemacquire(addr) {
atomic.Xadd(&root.nwait, -1)
unlock(&root.lock)
break
}
// Any semrelease after the cansemacquire knows we're waiting
// (we set nwait above), so go to sleep.
root.queue(addr, s, lifo)
goparkunlock(&root.lock, waitReasonSemacquire, traceEvGoBlockSync, 4+skipframes)
if s.ticket != 0 || cansemacquire(addr) {
break
}
}
if s.releasetime > 0 {
blockevent(s.releasetime-t0, 3+skipframes)
}
releaseSudog(s)
}
The above source code may seem difficult , The most important one is for Code in loop . After locking , The semaphore will be increased by one , After unlocking, the semaphore will be reduced by one , The semaphore here can be understood as waiter( Waiting process ) The number of .
Put it in a more general way , In this stage, semaphores will be used to control the competition for mutexes . To organize data , adopt semaRoot Structure to encapsulate the mutex , This structure is stored in semtable In this hash table structure , When a hash conflict occurs , The same table Medium semaRoot Will be organized into a treap Trees ( A balanced binary tree ). The following is the structure source code :
A structure that encapsulates mutexes and waiters semaRoot
type semaRoot struct {
lock mutex
treap *sudog // root of balanced tree of unique waiters.
nwait uint32 // Number of waiters. Read w/o the lock.
}
preservation semaRoot The structure of the body semtable ( Hashtable )
const semTabSize = 251
var semtable [semTabSize]struct {
root semaRoot
pad [cpu.CacheLinePadSize - unsafe.Sizeof(semaRoot{
})]byte
}
The illustration :
Encapsulate the mutex into semaRoot Structure , Then calculate the hash value according to the address of the mutex, and then take the modulus to get its bucket , And solve hash conflicts through a two-way linked list
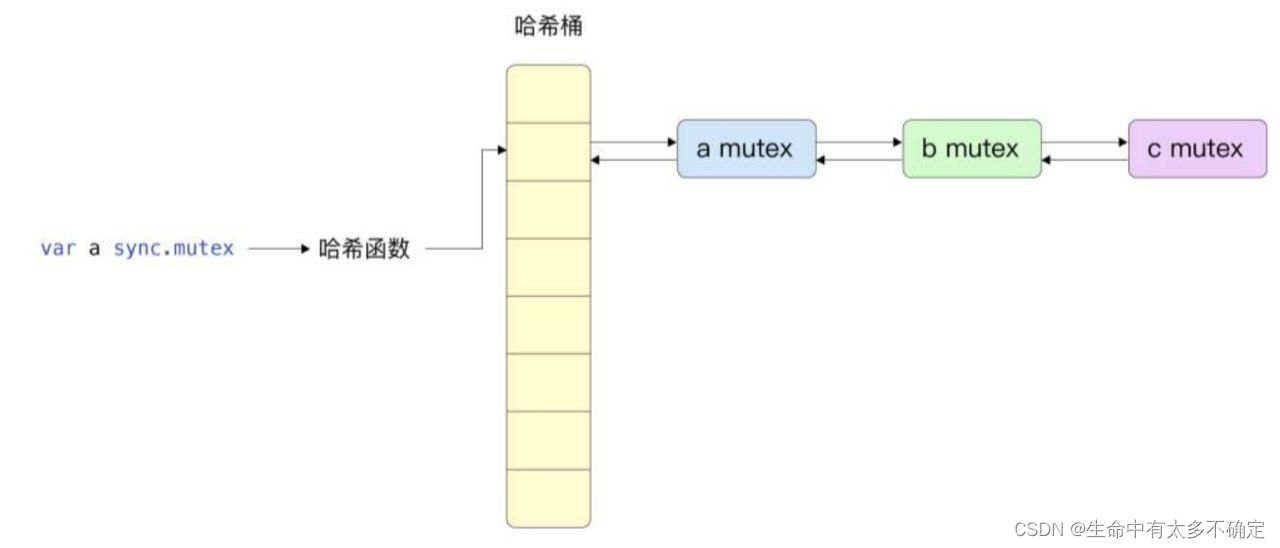
The two-way linked list will also be organized into treap Trees , The reason for this is to quickly find ( L o g 2 N Log_2N Log2N Complexity )
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-MoPjA3cR-1655993423695)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/d05b8622-6cbc-49b2-a7db-e4b2e682f5cd/Untitled.png)]](/img/18/02ffeefdeb6bd8439f742f76980652.png)
In the diagram above ,G1 G2 G3 Is to get the mutex e Cooperation of
If the lock cannot be obtained for a long time in the second stage above , The current mutex will enter Hunger mode , After that, if the lock can be obtained quickly, it will return to the normal mode
Summary
Go The lock in language is actually a hybrid lock , Used Atomic manipulation 、 The spin 、 Semaphore 、 Lock of the operating system sector 、 Waiting in line 、 Global hash table .
3.2、Unlock
Source code :
// Unlock unlocks m.
// It is a run-time error if m is not locked on entry to Unlock.
//
// A locked Mutex is not associated with a particular goroutine.
// It is allowed for one goroutine to lock a Mutex and then
// arrange for another goroutine to unlock it.
func (m *Mutex) Unlock() {
if race.Enabled {
_ = m.state
race.Release(unsafe.Pointer(m))
}
// Fast path: drop lock bit.
// Fast path :
new := atomic.AddInt32(&m.state, -mutexLocked)
if new != 0 {
// Outlined slow path to allow inlining the fast path.
// To hide unlockSlow during tracing we skip one extra frame when tracing GoUnblock.
m.unlockSlow(new)
}
}
unlockSlow Method
func (m *Mutex) unlockSlow(new int32) {
if (new+mutexLocked)&mutexLocked == 0 {
throw("sync: unlock of unlocked mutex")
}
if new&mutexStarving == 0 {
old := new
for {
// If there are no waiters or a goroutine has already
// been woken or grabbed the lock, no need to wake anyone.
// In starvation mode ownership is directly handed off from unlocking
// goroutine to the next waiter. We are not part of this chain,
// since we did not observe mutexStarving when we unlocked the mutex above.
// So get off the way.
if old>>mutexWaiterShift == 0 || old&(mutexLocked|mutexWoken|mutexStarving) != 0 {
return
}
// Grab the right to wake someone.
new = (old - 1<<mutexWaiterShift) | mutexWoken
// Normal mode : Keep passing CAS Compete for mutually exclusive locks
if atomic.CompareAndSwapInt32(&m.state, old, new) {
runtime_Semrelease(&m.sema, false, 1)
return
}
old = m.state
}
} else {
// Starving mode: handoff mutex ownership to the next waiter, and yield
// our time slice so that the next waiter can start to run immediately.
// Note: mutexLocked is not set, the waiter will set it after wakeup.
// But mutex is still considered locked if mutexStarving is set,
// so new coming goroutines won't acquire it.
// Hunger mode : Directly wake up the longest waiting process in the waiting queue
runtime_Semrelease(&m.sema, true, 1)
}
}
seen Lock See the source code of Unlock The source code will feel much simpler ,Unlock There is also a fast path , That is, try to grab the lock through atomic operation , If you fail, you will enter unlockSlow In the method , Then according to the current mode ( Normal mode / Hunger mode ) Do something different , But everything you do is encapsulated into a runtime_Semrelease Method , If it's hunger mode , Then the second parameter is true
4、 Read-write lock
4.1、 summary
In some scenarios of concurrent reading and writing , If you continue to use mutexes, it will seriously affect performance , Especially in some scenes where reading is more than writing . In this case, concurrent reads are allowed , But concurrent writes are not allowed , So ,Go Language encapsulates a mutex , The structure is as follows :
type RWMutex struct {
w Mutex // held if there are pending writers The mutex
writerSem uint32 // semaphore for writers to wait for completing readers Write semaphores
readerSem uint32 // semaphore for readers to wait for completing writers Read semaphore
readerCount int32 // number of pending readers The number of read operations currently being performed ( Because read operations can be concurrent )
readerWait int32 // number of departing readers When writing , The number of coroutines waiting to be read
}
It is not difficult to see from the source code , Read / write locks are based on mutexes
4.2、 principle
Because the encapsulation is based on mutual exclusion , Relatively simple , So don't show the source code . The principle is very simple , Before reading , If there is a write operation in progress , You need to wait until the write operation is completed before reading . let me put it another way , Except that concurrent reads can be run , Concurrent read + Writing or concurrent writing will block .
5、 Summary
This section describes atomic operations 、 Mutex lock and read-write lock ,Go The mutex of language is specially designed for coroutines , Through the above analysis, we can know that its essence is a hybrid lock , The purpose is also simple : Do not use system level locks as a last resort ( Because this will lock the whole thread ). Later, the read-write lock is also introduced , This is encapsulated for specific scenarios based on mutexes , Its read operation will be better than mutex . In actual use, you still need to choose according to business needs
边栏推荐
- Leecode learning notes
- PLC编程基础之数据类型、变量声明、全局变量和I/O映射(CODESYS篇 )
- Starting from 1.5, build a micro Service Framework -- log tracking traceid
- Krypton Factor-紫书第七章暴力求解
- Thoroughly understand JVM class loading subsystem
- 第十七周作业
- VOT toolkit environment configuration and use
- Data type, variable declaration, global variable and i/o mapping of PLC programming basis (CoDeSys)
- 实现反向代理客户端IP透传
- Detailed explanation of pointer and array written test of C language
猜你喜欢
透彻理解JVM类加载子系统
Simple and beautiful method of PPT color matching

【Note17】PECI(Platform Environment Control Interface)
Vcomp110.dll download -vcomp110 What if DLL is lost

Sum of two numbers, sum of three numbers (sort + double pointer)

Nangou Gili hard Kai font TTF Download with installation tutorial
Douban scoring applet Part-2
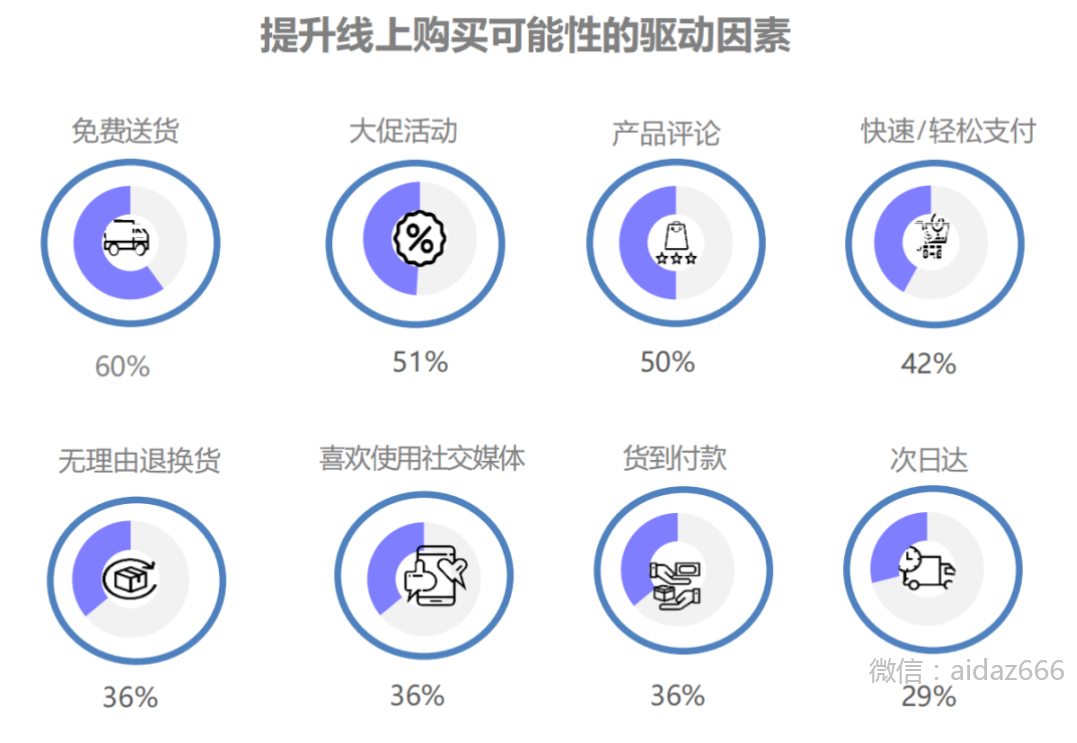
Southeast Asia e-commerce guide, how do sellers layout the Southeast Asia market?
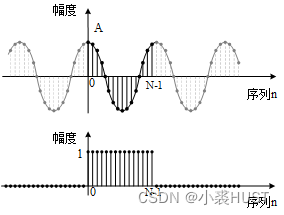
Spectrum analysis of ADC sampling sequence based on stm32

Registration and skills of hoisting machinery command examination in 2022
随机推荐
Southeast Asia e-commerce guide, how do sellers layout the Southeast Asia market?
利用LNMP实现wordpress站点搭建
LeetCode145. Post order traversal of binary tree (three methods of recursion and iteration)
3:第一章:认识JVM规范2:JVM规范,简介;
Composition of interface
Element operation and element waiting in Web Automation
How to quickly understand complex businesses and systematically think about problems?
一文搞定JVM常见工具和优化策略
一文搞定JVM的内存结构
Global and Chinese market of water treatment technology 2022-2028: Research Report on technology, participants, trends, market size and share
The maximum happiness of the party
使用rewrite规则实现将所有到a域名的访问rewrite到b域名
VOT toolkit environment configuration and use
Negative sampling
Use of metadata in golang grpc
Leetcode buys and sells stocks
两数之和、三数之和(排序+双指针)
Hj16 shopping list
Codeforces Global Round 19
并查集实践