当前位置:网站首页>ACM Multimedia 2022 | 视觉语言预训练模型中社会偏见的反事实衡量和消除
ACM Multimedia 2022 | 视觉语言预训练模型中社会偏见的反事实衡量和消除
2022-07-04 21:33:00 【智源社区】
论文标题:
Counterfactually Measuring and Eliminating Social Bias in Vision-Language Pre-training Models
论文链接:
https://arxiv.org/submit/4382207
代码和数据集:
https://github.com/VL-Bias/VL-Bias
在本工作中,我们针对VLP模型的多模态特性,基于反事实样本生成衡量了各个模态的社会偏见以及多模态融合的社会偏见。衡量预训练模型中的社会偏见本质上是衡量偏见概念(比如,性别等社会属性)和目标概念之间的相关性。
我们提出了基于反事实的偏见衡量方法CounterBias,对每个样本都生成偏见属性上的反事实样本,之后使用反事实前后模型对目标属性的建模变化来衡量偏见概念和目标概念的联系。
由于目前还没有现成的数据集专门用于分析VLP模型中的社会偏见,我们提出了VL-Bias数据集,用于本工作以及社区对VLP模型中的社会偏见的理解。VL-Bias包含24K图文对,其中目标属性包含52个动作和13个职业。在VL-Bias数据集上,使用CounterBias,我们测试了两种典型的VLP结构,单流VLP和双流VLP。关键的观测结果包括:(1)测试的VLP模型中存在社会偏见,视觉模态和文本模态中都存在;(2)包含在VLP模型中的社会偏见与人类刻板影响基本一致;(3)测试的单流架构VLP和双流架构VLP在两个模态中的偏见表现出不同的一致性;(4)测试的VLP模型表现出比BERT更强的性别偏见。
继承了CounterBias中的反事实思路,我们提出了一个简单但有效的方法FiarVLP消除VLP模型中的社会偏见。具体来说,我们首先在视觉和语言模态中分别生成偏见概念的反事实样本。再将MLM任务对事实和反事实的预测的概率差异最小化,从而防止模型学习偏差和目标概念之间的关联。实验结果证明了FairVLP的有效性。
边栏推荐
猜你喜欢
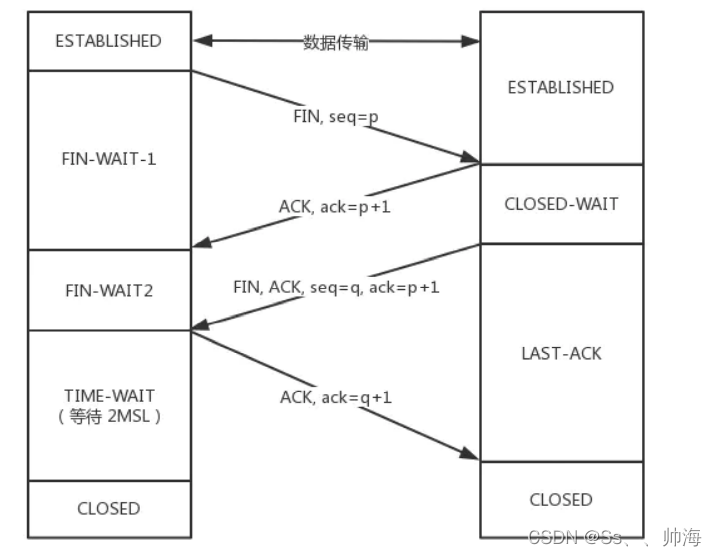
TCP shakes hands three times and waves four times. Do you really understand?
Bookmark

创客思维在高等教育中的启迪作用
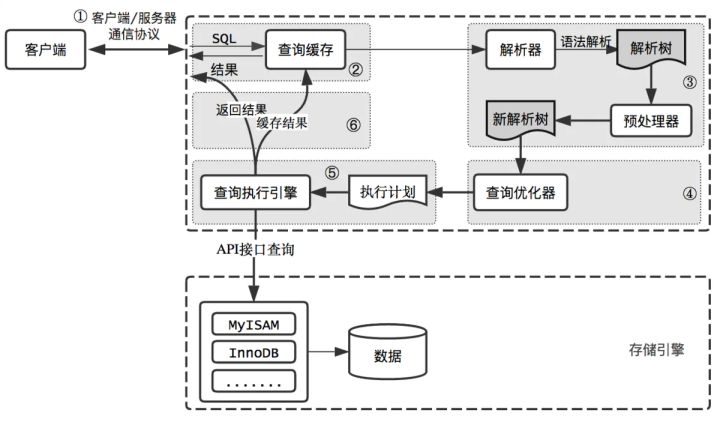
输入的查询SQL语句,是如何执行的?
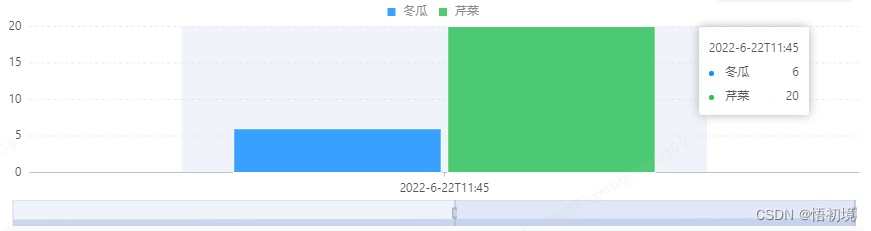
Bizchart+slider to realize grouping histogram
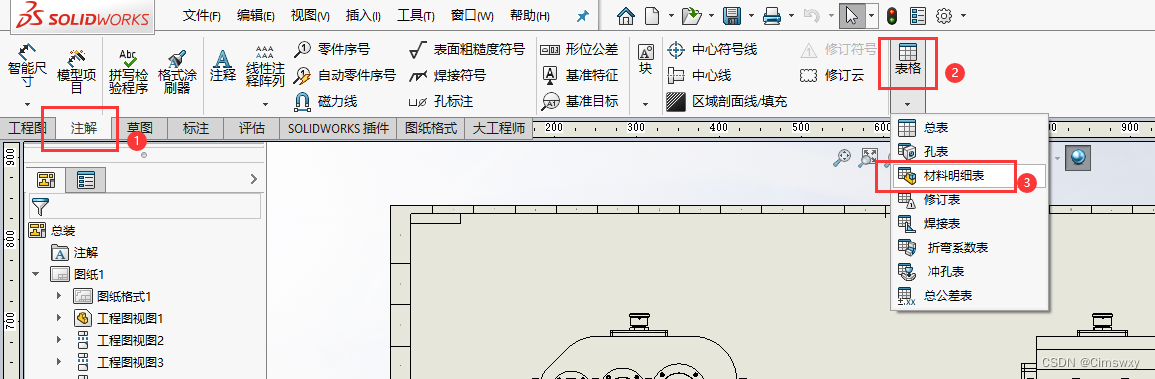
SolidWorks工程图添加材料明细表的操作
保证接口数据安全的10种方案

Exclusive interview of open source summer | new committer Xie Qijun of Apache iotdb community
![[public class preview]: basis and practice of video quality evaluation](/img/fd/42b98a08b5a0fd89c119f1d1a8fe1b.png)
[public class preview]: basis and practice of video quality evaluation

【活动早知道】LiveVideoStack近期活动一览
随机推荐
Bookmark
HDU - 2859 Phalanx(DP)
QT—绘制其他问题
并列图的画法,多排多列
Golang面试整理 三 简历如何书写
Learning breakout 3 - about energy
How much is the minimum stock account opening commission? Is it safe to open an account online
Liu Jincheng won the 2022 China e-commerce industry innovation Figure Award
QT—双缓冲绘图
Go language loop statement (3 in Lesson 10)
[optimtool.unconstrained] unconstrained optimization toolbox
Jerry's ad series MIDI function description [chapter]
How was MP3 born?
SolidWorks工程图添加材料明细表的操作
Solve the problem of data disorder caused by slow asynchronous interface
Le module minidom écrit et analyse XML
输入的查询SQL语句,是如何执行的?
How to remove the black dot in front of the title in word document
Analysis of maker education technology in the Internet Era
从RepVgg到MobileOne,含mobileone的代码