This time 6 month Meetup What I bring to you is Scaleph be based on Apache SeaTunnel (Incubating) Introduction to data integration , Hope you found something .
This speech mainly includes five parts :

Wang Qi
Apache SeaTunnel Contributor
Search for recommended engineers , big data Java Development
01 Scaleph The origin of
I was first engaged in search recommendation , Be responsible for maintenance in the team Dump System , Mainly for our search engine
Provide the function of feeding data
, First of all, let me introduce the main problems in the maintenance process 5 Pain points :

Timeliness and stability
Search recommendation is the core online system of e-commerce platform , In particular, the timeliness and stability of data are highly required . Because search recommendations will receive
The whole e-commerce platform C End
Most of the traffic , So once the service fluctuates , It may cause service damage , The user experience is greatly reduced .
Business complex / Wide table design
Dump The system will integrate the e-commerce platform
goods 、 category 、 brand 、 The store 、 Product label 、 Real time data warehouse / Offline data and model data
It will go through a series of pretreatment , The final output is a wide table , In the process , The complexity and variability of business , Will invade Dump From the system , Therefore, the technical challenges to deal with are relatively higher .
Total quantity + Real time index
Run the full index once a day , The main purpose is to update
T+1 frequency
Updated data . When the full index is finished , We will refresh the data that needs to be updated in real time through real-time index , For example, the price of goods 、 Information about inventory changes .
Data linkage update
We have many upstream data sources , Yes
Message queue 、 database 、 Big data related storage and dubbo Interface
, Because it is a wide table design , Take the commodity index as an example , The wide watch will be mainly commodity , If it is a store index , Mainly stores , Depending on the data , Upstream data changes are not necessarily product or store dimensions , Data will also produce certain linkage updates .
The bottom line of the data
Search recommendation service was also responsible for C Most of the traffic at the end , When the performance of other teams in the company cannot keep up , They usually pass the data Dump The system sends it to the search engine , Then our team returned to Web page , Avoid subsequent secondary request calls to them .
meanwhile , If other teams' business systems generate dirty data , Also needed Dump The system does data protection , Prevent data leakage to C End users have a bad impact , So when developing and maintaining , It's also very difficult .
02 Why introduce Flink?
As a domestic Flink Early users of , Alibaba has a long history and successful experience in the field of search recommendation , Develop and maintain in the search recommendation team Dump The professional experience of the system prompted me to pay attention to using Flink do
A/B Experimental report 、 Real time data flow
Other related work , It mainly uses Flink To achieve Dump The system provides for search Dump Platform work , Use Flink Doing data integration has 5 advantage :
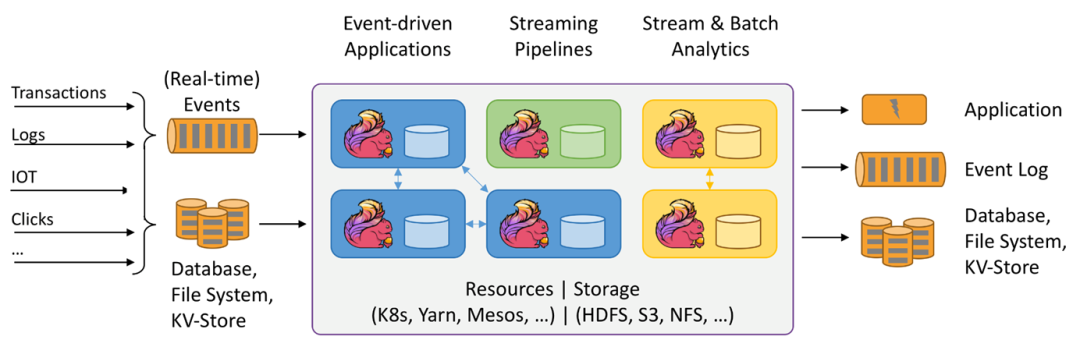
Ecological support :Flink There are many out of the box connector, Support csv、avro data format ,kafka、pulsar And many storage systems , Closely integrate with the big data ecosystem ;
03 Why choose SeaTunnel?
Later contact SeaTunnel When , Love it SeaTunnel Design concept of !
SeaTunnel Is running on the Flink and Spark above , Next generation integration framework for high-performance and distributed massive data .
The important thing is that it is out of the box , And it can realize seamless integration for the existing ecosystem , Because it runs on Flink and Spark above , It can easily access the existing Flink and Spark Infrastructure of .
On the other hand SeaTunnel There are also many production cases
, When entering Apache After the foundation incubates , The community is very active , Future period .
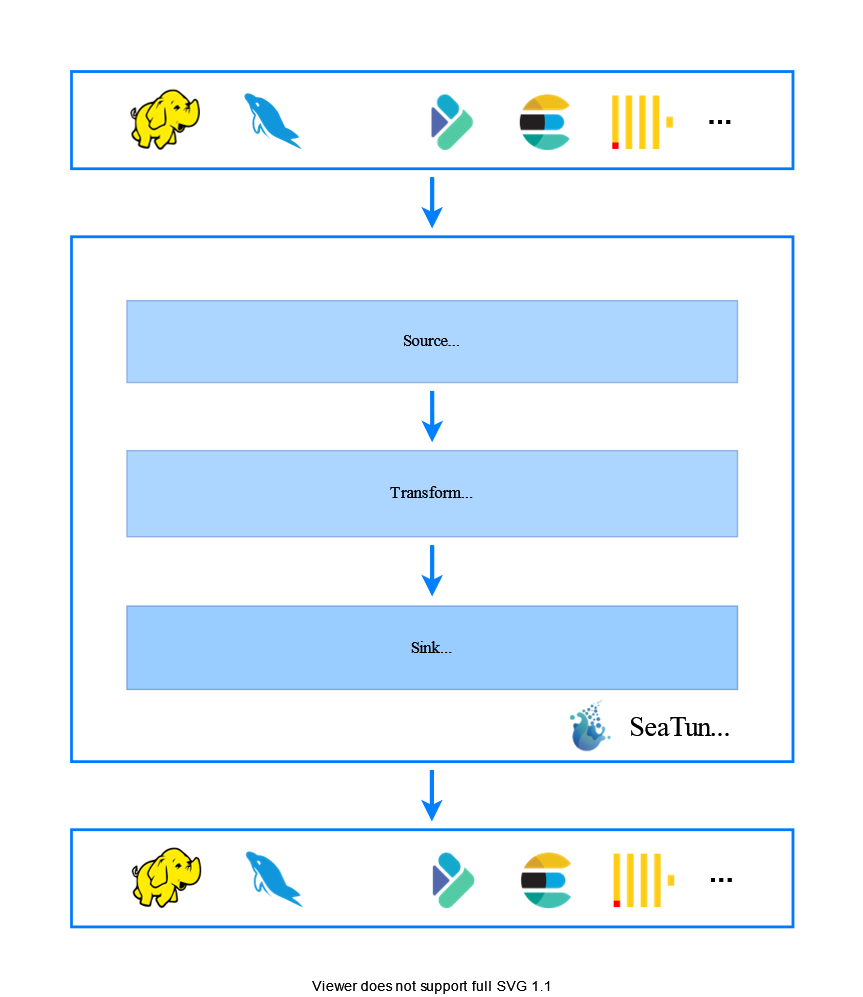
04 About Scaleph
The starting point of the project
Our initial idea was to SeaTunnel Provide Web page , Be able to build an open source system for data integration . At present, our main goal is SeaTunnel
Make an open source visual data development and management system
, Expect later Scaleph It can minimize the development threshold of real-time and offline data tasks , Provide developers with a one-stop data development platform .
Project highlights
In real production applications , During data integration , Arrange or SQL Development is the main form of data integration , We think
Drag and Drop Visual task choreography
It can minimize the burden of data integration for users ;
The other is to realize multi version management of jobs , Data source support ;
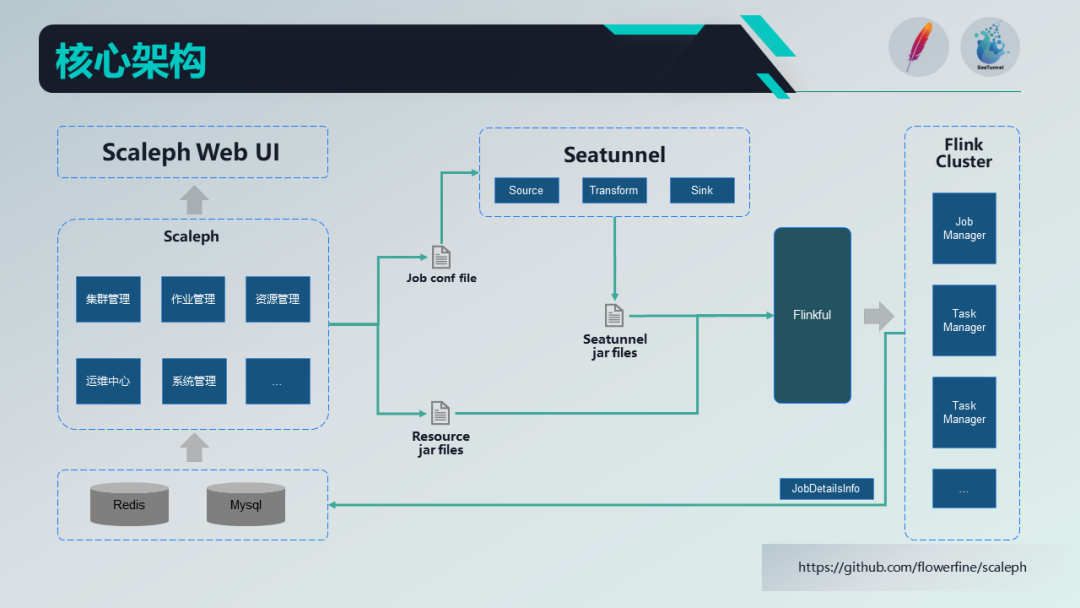
The above is the architecture diagram of our system , Users mainly use Web UI, Encapsulated by the job management function SeaTunnel operator , Users drag and drop configuration on the page , Automatic system generation SeaTunnel Configuration file for , Finally, through the resources uploaded by users in resource management
jar
The bags pass together Flinkful Library submitted to Flink In the cluster . Resources for resource management
jar
The purpose of the package is to support users to upload their own R & D related
jar
package , Make up SeaTunnel Related defects , Or right SeaTunnel and Flink Enhance its functions !
We use it quartz Developed a scheduling task , When the task is submitted to Flink after , The task will go regularly Flink The cluster pulls the task information , Store in MySQL Inside , End users are Web UI You can see the task related operation information on the page .
Scaleph Function introduction ( Data development )
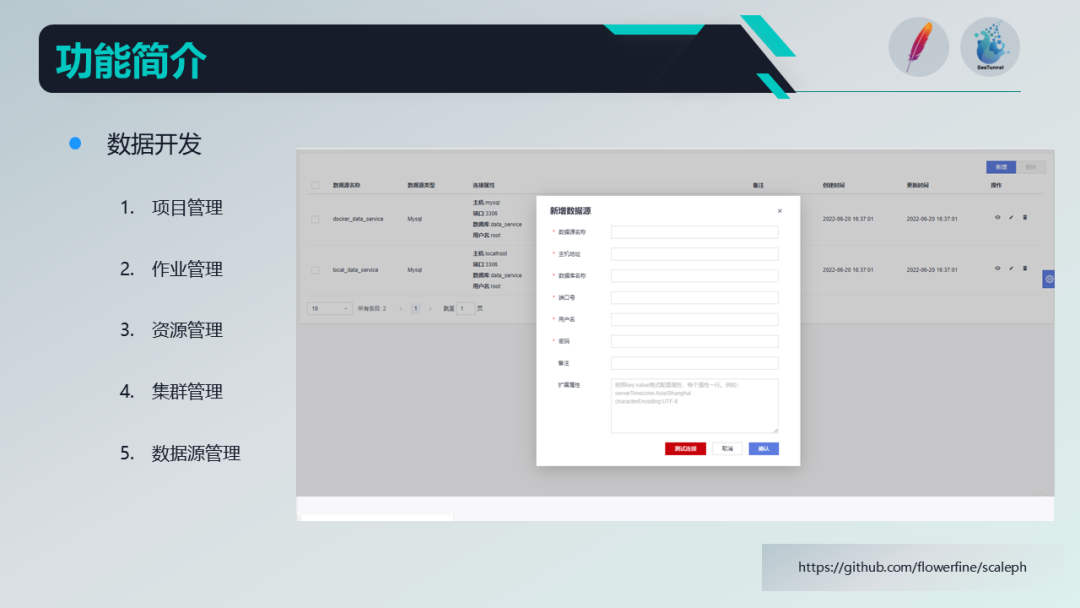
01 project management
Mainly when users create data synchronization tasks , Be able to carry out relevant management work according to different business dimensions .
02 Job management
By dragging and dropping, you can create SeaTunnel Data tasks , Then submit and run accordingly .
03 Resource management
SeaTunnel In order to Apache2.0 Open source certificates are open source , And MySQL Of JDBC The open source protocol of the driver package is incompatible ,SeaTunnel Of jdbc connector Do not provide relevant JDBC driving-dependent . When users use jdbc connector when ,
It needs to be provided by itself JDBC Drive pack .
Here we provide the function of resource management , Users can upload the driver package by themselves , Then take it. SeaTunnel The tasks and MySQL Drivers are submitted to the cluster together to ensure the normal operation of tasks .
04 Cluster management
Mainly to provide Flink Input of cluster information , At present, it can support Standalone Session Cluster entry , After the user enters , Submit SeaTunnel Cluster can be selected when working , The task will run in the cluster .
05 Data source management
Support users to enter some data source information in advance , In this way, it is not necessary to input the data source information for each task . meanwhile , You can also share data sources and restrict permissions , Prevent the disclosure of data source information in plaintext .
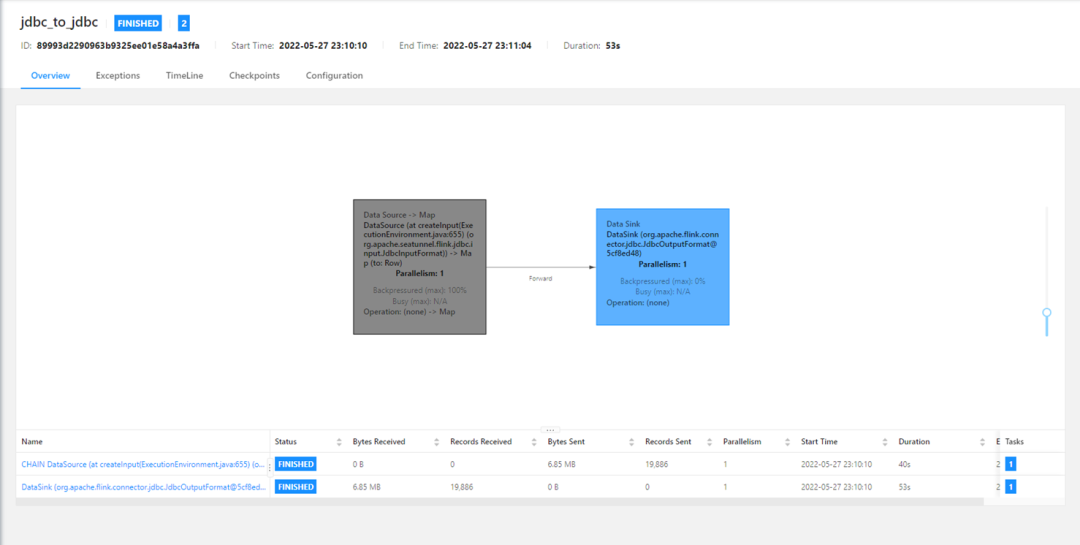
Scaleph Function introduction ( Operation and maintenance center )
The operation and maintenance center is a running log of real-time tasks and periodic tasks , Users see task related information when submitting tasks , We also provide
Link jump operation
, Users can click to jump to Flink Of Web UI The above to , adopt Flink Official Web UI page , You can see the specific execution information of the task .
Scaleph Function introduction ( Data standards )
01 Data element
Data governance is a big system , Everyone is more concerned
Metadata 、 Data consanguinity 、 Data assets
, But data standards are also an important part of data governance , We open source the standard system used internally by the company , Share the relevant knowledge of data standards .
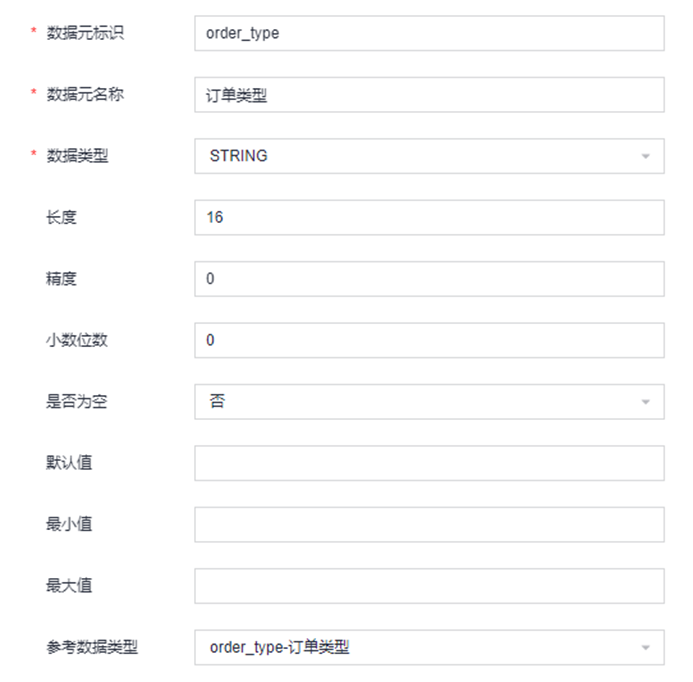
In the development process of many data warehouses , Because it is multi person collaboration , Fields with the same meaning , In different model tables , Development will define different fields to express the same meaning and business . The data standard hopes to pass the data element , To unify the model field definitions of data warehouse developers .
02 Reference data
The data in the data warehouse is pulled from the business system through data integration tools , Inevitably, fields with the same meaning will have different definitions in different business systems , These fields with the same meaning and different definitions need to be maintained by warehouse personnel , And the maintenance process is mainly offline documents , Possible
Maintenance is out of date
The situation of .
At the same time, there will also be the problem that business knowledge cannot be directly mapped to data warehouse model information , Data standards allow users to Web Maintain these business knowledge in the page .
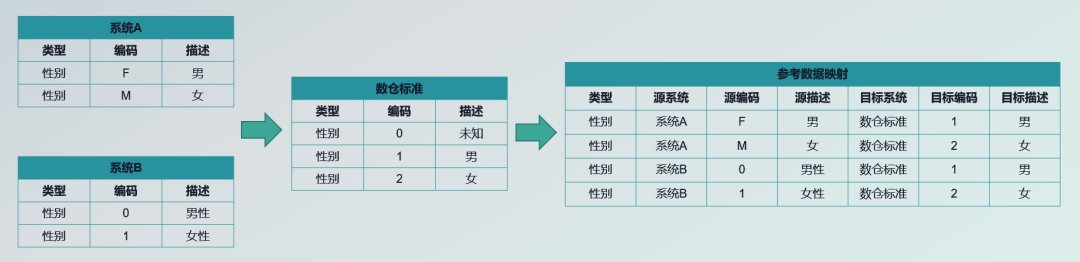
The above figure is a specific case . Here are two business systems defined , One is the system A, One is the system B, They have different gender enumeration values , meanwhile A/B The enumeration description of the system is also different , What to do with that ?
This is the time , We can set a set of unified standards through data warehouse developers , For example, the coding system must be
0,1,2,
The corresponding description is also well defined , Map through a reference data in the middle , Users can easily see .
03 Follow up ideas
Whether it can be in the process of data integration , Directly through data standards Transform operation , Realize automatic maintenance and mapping of knowledge and models .
04 Scaleph Feature highlights
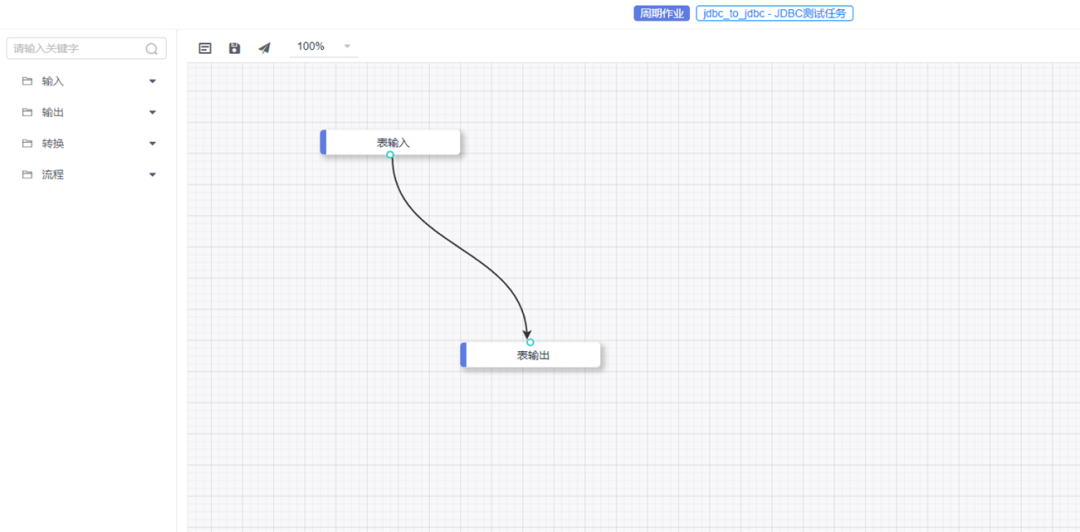
Visual development of data .
We believe that in the field of data synchronization , Visual drag and drop , It can help users quickly create data integration tasks , The user drags out two operators , Fill in the corresponding parameters to create a data integration task .
Flinkful It's for Flink One developed Java client .
Flink As a popular computing engine , There are many ways for users to use , for instance
Command line interface 、HTTP Interface
etc. , Through the command line interface, users can submit tasks 、 Create and cancel tasks ;HTTP The interface is mainly used for Web UI Interface .
It's docking Flink The process of , We found that Flink As a run on JVM An application on the same runs on JVM Above Scaleph application , The integration of the two should pass shell Script , It's unreasonable . So we developed Flinkful, open Flink stay Java Ecological openness , Let users through Flinkful, It can be directly to Flink Cluster and task management .
We think Flinkful Yes Flink Infrastructure maintenance personnel are more meaningful , So from Scaleph Stripped out of the warehouse , Open source alone .
Plug-in system
. We want to define plug-ins , Provide system expansion interface , Users and Scaleph Developers can quickly enhance through these interfaces Scaleph Functions and features of . At present, we have defined two plug-ins , They are data source plug-ins and SeaTunnel plug-in unit , Through the data source plug-in, you can quickly expand JDBC、ES、Kafka、Clinkhouse Data sources like that , Gather these data sources into Scaleph The system is uniformly configured and used .
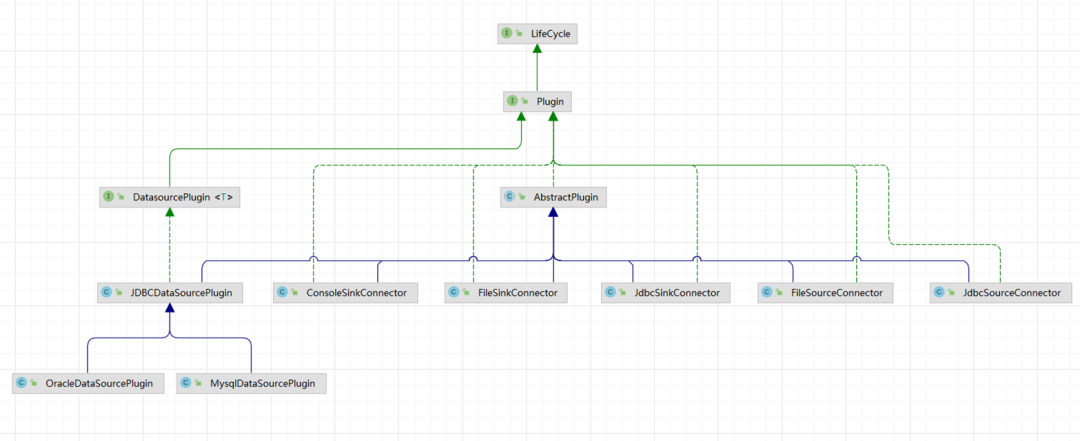
at present SeaTunnel There are a lot of connector and transform plug-in unit , If you develop pages one by one , It's a time-consuming thing ,
We just want to use a simple 、 Declarative way , hold SeaTunnel Relevant parameters are defined
, Can quickly put SeaTunnel Relevant capabilities are completely transferred to Scaleph Project up .
Problem analysis
Flink-jdbc-connector Functional enhancement
SeaTunnel Many cases in official documents , It's all about FakeSource and ConsoleSink Realized , And we are developing with jdbc-connector Dominant . In the integration process , We found that flink-jdbc-connector The plug-in JdbcSink Only support Stream mode , Then we realized it Batch Pattern .
JdbcSource You need to provide sql,
The program gets sql The column of 、 Table information , To generate JdbcSource Of RowTypeInfo.
But the definition is complex sql Alias will appear when 、 Sub query and so on , Regular expressions are difficult to cover all scenarios . We use Jdbc Of Connection Get sql Of ResultSet, from ResultSet Direct access to sql Column information for , To generate JdbcSource Of RowTypeInfo.
Seatunnel-core-flink.jar Slimming
SeaTunnel Is running on the Flink and Spark above , The two will be divided into two jar package ,seatunnel-core-flink.jar Namely Flink Corresponding implementation . stay 2.1.1 In the version ,Seatunnel Based on flink Realized connector All hit this fat jar In bag .
When you really use it , Data synchronization task , Only one of them may be used 1-2 Kind of connector.Seatunnel There will be a certain amount of additional network overhead when the task is submitted .
We want to achieve this effect :
There is a comparison thin Of core jar package , Then add related connector Of jar package .
At the time of submission , With core-jar Package based , Plus related connector Of jar package . At the same time, the resources mentioned above jar Package upload , Such as SeaTunnel Of jdbc-connector lack of JDBC Drive pack , Carry resources jar Bao He connector jar The task submission of packages is handled in the same way .
Later, the community carried out connector When you split it up , We are also actively involved issue I shared relevant experience , When Seatunnel 2.1.2 When it was released , Our system is also easily adapted seatunnel-core-flink.jar and connector jar Separate release form . At the same time, the user is not Flink The cluster is prepared in advance JDBC In the case of driving , You can also use the function of resource management , Upload driver package , Submitting SeaTunnel When the task , Submit with the driver package .
Flink jobId Get questions
Flink The core way of task submission is in the form of command line interface , Therefore, users need to pass shell Script to submit Flink Mission .Flink After the task is submitted ,
The command-line client will send the corresponding task id Output to console log
, Users need to capture the log output to the console , Extract tasks from them id.
Because our project and Flink All interactions are through Flinkful Library implementation ,Flinkful You can put such a jobId
Send it back directly as the return value of the interface call
. So our implementation is compared with capture console log extraction jobId It's more elegant .
SeaTunnel call System.exit() problem
SeaTunnel When the task is carried out , First, the configuration file written by the user will be checked , If the check fails , Will call directly System.exit(), And then this time JVM So I quit .SeaTunnel Its submission method is shell Foot implementation , therefore JVM There is no problem exiting .
But when Scaleph System , When integrating it into our application , When calling this method , It will cause us Scaleph Such an application will directly hang up , One of our services is unavailable . therefore , We also submit this piece of code for the task , adopt
SecurityManager
, Added a related permission limit , Then stipulate SeaTunnel Relevant task submission procedures , Ban called System.exit() Method .
05 SeaTunnel Community contribution
Develop with me Scaleph A friend , Here are some of our submissions pr, Like the above jdbc-connector Enhancements to . And that is jdbc-connector Of upsert Function realization .flink-jdbc-connector Of JdbcSink A big drawback of is
Only support insert function , It can't be done update, This will considerably limit this connector The function of .
We also developed upsert Semantic support , Support repeated synchronization of data .
01 System demonstration
This project can be carried out if there is enough time Docker The environment and IDE Environment demonstration , Here time is limited, so choose Docker Environment for everyone to demonstrate , Demo video ( Direct jump 23'18s):
02 Follow up development plan
At present, we will still put SeaTunnel dependent connector and transform plug-in unit , Move to our visual drag and drop page , It can make users feel completely SeaTunnel A powerful . The other is to follow SeaTunnel-connector Rich plug-ins , Also want to connector The corresponding data source types are enriched .
We also hope to do something for data development and data integration DAG Related scheduling , At the same time, we also hope to support in data development SQL Task development .
Apache SeaTunnel

// Keep in contact //
Little helper : Seatunnel1 remarks infoq
Come on , Grow with the community !
Apache SeaTunnel(Incubating)
It's a distribution 、 High performance 、 Easy to expand 、 For massive data ( offline & real time ) Data integration platform for synchronization and transformation .
Warehouse address :
https://github.com/apache/incubator-seatunnel
website :
https://seatunnel.apache.org/
Proposal:
https://cwiki.apache.org/confluence/display/INCUBATOR/SeaTunnelProposal
Apache SeaTunnel(Incubating) 2.1.0 Download address :
https://seatunnel.apache.org/download
We sincerely welcome more people to join !
Can enter Apache The incubator ,SeaTunnel( primary Waterdrop) The new journey has just begun , But the development of the community needs more people to join . We believe that , stay
「Community Over Code」
( Community greater than code )、
「Open and Cooperation」
( Open collaboration )、
「Meritocracy」
( Elite management )、 as well as 「
Diversity and consensus decision making 」
etc. The Apache Way Under the guidance of , We will usher in a more diversified and inclusive community ecology , Technological progress brought by the spirit of co construction and open source !
We sincerely invite all partners who are interested in making local open source based on the world to join SeaTunnel Contributor family , Build open source together !
Submit questions and suggestions :
https://github.com/apache/incubator-seatunnel/issues
Contribution code :
https://github.com/apache/incubator-seatunnel/pulls
Subscribe to community development mailing lists :
Develop mailing lists :
Join in Slack:
https://join.slack.com/t/apacheseatunnel/shared_invite/zt-123jmewxe-RjB_DW3M3gV~xL91pZ0oVQ
Focus on Twitter:
https://twitter.com/ASFSeaTunnel
原网站版权声明
本文为[InfoQ]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/185/202207042132513540.html
![Compréhension approfondie du symbole [langue C]](/img/4b/26cf10baa29eeff08101dcbbb673a2.png)