当前位置:网站首页>Prior knowledge of machine learning in probability theory (Part 1)
Prior knowledge of machine learning in probability theory (Part 1)
2022-07-05 20:53:00 【Full stack programmer webmaster】
Hello everyone , I meet you again , I'm the king of the whole stack , I've prepared for you today Idea Registration code .
With Hadoop Such as the emergence of big data and the development of Technology , machine Study More and more people's attention .
Actually early Hadoop Before , Machine learning and data mining already exist , As a separate discipline , Why? hadoop After that , Machine learning is so compelling ? because of this hadoop The emergence of enables many people to have the technical support to deal with massive data . And then discover the importance of data , And to find valuable information from data . Choosing machine learning seems to be an inevitable trend . Of course, it does not rule out the factor of public opinion . In fact, I have always been skeptical of many people claiming to have mastered machine learning . To understand the essence of machine learning . Mathematical knowledge is indispensable , For example, linear algebra . Probability theory and calculus 、 Vector space, etc . And the assumption has no certain mathematical basis , Using machine learning can only know it but don't know why . For this reason , We will systematically summarize some mathematical knowledge used in machine learning , Of course, it's impossible to cover everything , But it will be as accurate as possible .
This article first studies probability theory , Probability theory plays a major role in machine learning . Because probability theory provides a theoretical basis for the correctness of machine learning algorithm . The design of learning algorithm often depends on the probability assumption of data and is directly used in some algorithms .
Permutation and combination
array : from n Among the different elements , Take whatever you like m(m≤n,m And n All are natural numbers ) The elements are arranged in a column in a certain order , Called from n Take out... Of the different elements m An arrangement of elements ; from n Take out... Of the different elements m(m≤n) The number of all permutations of elements , Called from n Take out... Of the different elements m Number of permutations of elements , Use symbols A(n,m) Express .A(n,m)=n(n-1)(n-2)……(n-m+1)=n!/(n-m)!. Usually what we call permutation refers to the number of all permutations , namely A(n,m).
Combine : from n Among the different elements . Take whatever you like m(m≤n) A group of elements , It's called from n Take out... Of the different elements m A combination of elements ; from n Take out... Of the different elements m(m≤n) The number of all combinations of elements , It's called from n Take out... Of the different elements m Number of combinations of elements . Use symbols C(n,m) Express .C(n,m)=A(n,m)/m!.C(n,m)=C(n,n-m).
Usually, what we call combination refers to the number of all combinations . namely C(n,m).
The difference between combination and arrangement is only seen from the formula ,C(n,m)=A(n,m)/m!, And why divide by m! Well ? Analyze from the definition . Arrangement is an ordered sequence , That is, the element x,y Put it in position 1.2 And put it on 2.1 There are two different sequences , Composition only cares about whether an element is selected . Regardless of order , That is to say x,y Put it in position 1.2 still 2.1 Are considered to be the same combination . because m The elements are m There are two positions m! Arrangement in , And this is just a combination for a combination , So you have to divide by m!.
A random variable
In probability theory . Random variables play an important role . Never confuse random variables with commonly mentioned variables , Think that random variables are variables whose values have randomness , But in fact . Random variables are functions . Map the test results to real numbers , More generally understood as , Random variables are artificially defined functions based on test results , The definition domain of this function is the value of the test result , Its value range varies according to different situations . Capital letters are usually used to represent random variables .
Suppose that random variables X Indicates that the result of rolling six sided dice is mapped to a real number , Be able to define X The result of the throw i It maps to i, For example, the result of throwing is 2, be X The result is 2.
It can also define the assumption that the throwing result is even . be X As the result of the 1. Otherwise 0. Such random variables are called indicator variables . Used to indicate whether an event has occurred .
A random variable X Value a And the probability of that is expressed as P(X = a) or P X(a), Use Val(X) Indicates the value range of random variables .
Joint distribution 、 Marginal distribution and conditional distribution
The distribution of random variables refers to the probability of taking certain values , According to the definition, the distribution is essentially probability , Use P(X) Represents a random variable X The distribution of .
When it comes to the distribution of more than one variable . This distribution is called joint distribution , At this time, the probability is determined by all the variables involved .
Consider the following example of joint distribution .X Random variable for rolling dice . The value is [1,6],Y A random variable for tossing coins , The value is [0,1], The joint distribution of the two is :
P | X=1 | X=2 | X=3 | X=4 | X=5 | X=6 |
|---|---|---|---|---|---|---|
Y=0 | 1/12 | 1/12 | 1/12 | 1/12 | 1/12 | 1/12 |
Y=1 | 1/12 | 1/12 | 1/12 | 1/12 | 1/12 | 1/12 |
Use P(X=a,Y=b) or PX,Y(a,b) Express X take a,Y take b The probability of time , Use P(X,Y) Express X.Y The joint distribution of .
Given a random variable X and Y The joint distribution of , Be able to define X perhaps Y The marginal distribution of . Marginal distribution refers to the probability distribution of a random variable itself , To calculate the marginal distribution of a random variable , You need to add other random variables in the joint distribution , Formula for :
The conditional distribution points out that when other random variables are known , The distribution of a particular random variable . And for a random variable X stay Y=b In this case, the value is a The conditional probability of can be defined as follows , The conditional distribution of the variable can be determined according to the formula :
The above formula can be extended to conditional probabilities based on multiple random variables . example , Based on two variables :
Using symbols P(X|Y=b) It means that Y=b Under the circumstances ,X The distribution of .P(X|Y)X Distributed set . Each of these elements is Y When taking different values X The distribution of .
In probability theory , Independence means that the distribution of one random variable is not affected by another random variable . Use the following mathematical formula to define random variables X Independent of Y:
According to this formula and the formula of conditional distribution, we can deduce the hypothesis X Independent of Y, that Y Also independent of X. Push to step, such as the following :
According to the push process above, we can get P(X,Y)=P(X)P(Y). That is, the formula is X and Y Mutually independent equivalent formulas .
Further, we can define conditional independence . That is, the value of one or more random variables is known , If some other variables are independent of each other, it is called conditional independence . It is known that Z.X and Y Independent mathematical definitions, such as the following :
Finally, let's look at two important theorems , They are chain rules and Bayesian rules .
The formula of chain rule is as follows :
The formula of Bayesian rule is as follows :
Bayesian formula is calculated P(Y|X) To get the value of P(X|Y) Value . This formula can be derived from the conditional formula :
The value of the denominator can be calculated from the edge distribution mentioned above :
Discrete distribution and continuous distribution
A broad sense . There are two kinds of distributions . They are discrete distribution and continuous distribution .
Discrete distribution means that random variables under this distribution can only take finite different values ( Or the result space is limited ). The discrete distribution can be defined by simply enumerating the probabilities of random variables to take each possible value , Such enumeration is called probability quality function , Because this function will unit mass ( Total probability ,1) Cut and then assign different values that random variables can take .
Continuous distribution means that random variables can take infinitely different values ( Or the result space is infinite ), Use the probability density function (probability density function,PDF) Define continuous distribution .
Probability density function f Non negative . An integrable function :
A random variable X According to the probability density function :
Special . The value of a continuously distributed random variable is whatever the probability of ordering a single value is 0, For example, random variables with continuous distribution X The value is a The probability of is 0. Because the upper and lower limits of the integral are a.
The cumulative distribution function can be derived from the probability density function . This function gives the probability that the random variable is less than a certain value , The relationship with probability density function is :
So according to the meaning of indefinite integral ,
Copyright notice : This article is an original blog article , Blog , Without consent , Shall not be reproduced .
Publisher : Full stack programmer stack length , Reprint please indicate the source :https://javaforall.cn/117652.html Link to the original text :https://javaforall.cn
边栏推荐
- Écrire une interface basée sur flask
- Make Jar, Not War
- Clear app data and get Icon
- Abnova丨CRISPR SpCas9 多克隆抗体方案
- Hongmeng OS' fourth learning
- Chemical properties and application instructions of prosci Lag3 antibody
- [quick start of Digital IC Verification] 2. Through an example of SOC project, understand the architecture of SOC and explore the design process of digital system
- Applet page navigation
- Duchefa丨MS培养基含维生素说明书
- Maker education infiltrating the transformation of maker spirit and culture
猜你喜欢

Duchefa low melting point agarose PPC Chinese and English instructions

XML建模
台风来袭!建筑工地该如何防范台风!

请查收.NET MAUI 的最新学习资源

Who the final say whether the product is good or not? Sonar puts forward performance indicators for analysis to help you easily judge product performance and performance
中国的软件公司为什么做不出产品?00后抛弃互联网;B站开源的高性能API网关组件|码农周刊VIP会员专属邮件周报 Vol.097

培养机器人教育创造力的前沿科技
Phpstudy Xiaopi's MySQL Click to start and quickly flash back. It has been solved
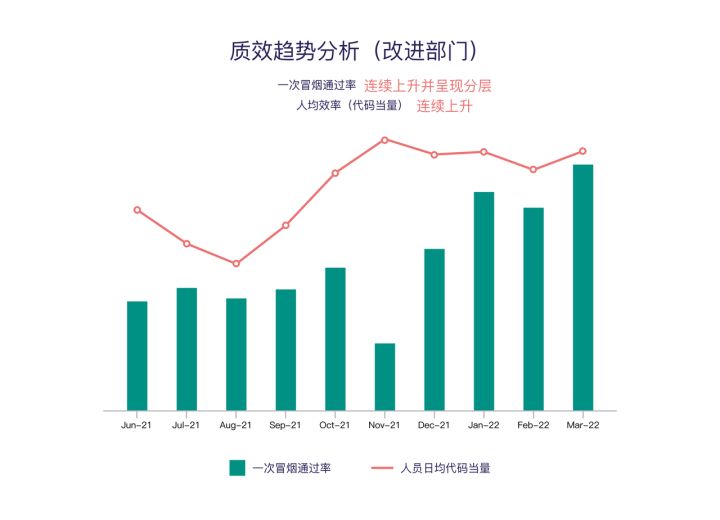
Research and development efficiency improvement practice of large insurance groups with 10000 + code base and 3000 + R & D personnel
Typhoon is coming! How to prevent typhoons on construction sites!
随机推荐
Abnova丨荧光染料 620-M 链霉亲和素方案
[quick start of Digital IC Verification] 2. Through an example of SOC project, understand the architecture of SOC and explore the design process of digital system
重上吹麻滩——段芝堂创始人翟立冬游记
Duchefa丨P1001植物琼脂中英文说明书
The development of research tourism practical education helps the development of cultural tourism industry
Maker education infiltrating the transformation of maker spirit and culture
Composition of applet code
Duchefa s0188 Chinese and English instructions of spectinomycin hydrochloride pentahydrate
Écrire une interface basée sur flask
《SAS编程和数据挖掘商业案例》学习笔记# 19
Interpreting the daily application functions of cooperative robots
Nprogress plug-in progress bar
Use of form text box (II) input filtering (synthetic event)
Specification of protein quantitative kit for abbkine BCA method
CADD course learning (7) -- Simulation of target and small molecule interaction (semi flexible docking autodock)
Duchefa low melting point agarose PPC Chinese and English instructions
How to renew NPDP? Here comes the operation guide!
Abnova e (diii) (WNV) recombinant protein Chinese and English instructions
leetcode:1755. 最接近目标值的子序列和
Duchefa丨低熔点琼脂糖 PPC中英文说明书