当前位置:网站首页>概率论机器学习的先验知识(上)
概率论机器学习的先验知识(上)
2022-07-05 20:47:00 【全栈程序员站长】
大家好,又见面了,我是全栈君,今天给大家准备了Idea注册码。
随着Hadoop等大数据的出现和技术的发展,机器学习越来越多地进入人们的视线。
其实早Hadoop之前,机器学习和数据挖掘已经存在,作为一个单独的学科,为什么hadoop之后出现,机器学习是如此引人注目了?因是hadoop的出现使非常多人拥有了处理海量数据的技术支撑。进而发现数据的重要性,而要想从数据中发现有价值的信息。选择机器学习似乎是必定的趋势。当然也不排除舆论的因素。事实上本人一直对非常多人宣称掌握了机器学习持怀疑态度。而要想理解机器学习的精髓。数学知识是不可或缺的,比方线性代数。概率论和微积分、向量空间等。而假设没有一定的数学基础,使用机器学习也仅仅能是知其然而不知其所以然了。基于这个原因,将系统地总结学习机器学习中用到的一些数学知识,当然不可能面面俱到,但会尽可能准确。
这篇文章首先学习概率论知识,概率论在机器学习中占主要地位。由于概率论为机器学习算法的正确性提供了理论依据。学习算法的设计常常依赖于对数据的概率假设以及在某些算法中被直接使用等。
排列组合
排列:从n个不同元素中,任取m(m≤n,m与n均为自然数)个元素依照一定的顺序排成一列,称为从n个不同元素中取出m个元素的一个排列;从n个不同元素中取出m(m≤n)个元素的全部排列的个数,称为从n个不同元素中取出m个元素的排列数,用符号 A(n,m)表示。A(n,m)=n(n-1)(n-2)……(n-m+1)=n!/(n-m)!。通常我们所说的排列指的是全部排列的个数,即A(n,m)。
组合:从n个不同元素中。任取m(m≤n)个元素并成一组,叫做从n个不同元素中取出m个元素的一个组合;从n个不同元素中取出m(m≤n)个元素的全部组合的个数,叫做从n个不同元素中取出m个元素的组合数。用符号 C(n,m) 表示。C(n,m)=A(n,m)/m!。C(n,m)=C(n,n-m)。
通常我们所说的组合指的是全部组合的个数。即C(n,m)。
组合和排列的差别单从公式来看的话,C(n,m)=A(n,m)/m!,而为什么要除以m!呢?从定义分析。排列是一个有序的序列,也就是将元素x,y放在位置1。2和放在2。1是两个不同的序列,而组合关心的仅仅是是否选取了某个元素。而不考虑顺序,也就是x,y放在位置1。2还是2。1都被觉得是同样的组合。由于m个元素在m个位置有m!中排列方式,而这对组合来说仅仅是一种组合,因此须要除以m!。
随机变量
在概率论中。随机变量扮演了重要的角色。千万不要将随机变量和通常所提到的变量相混淆,以为随机变量就是其值具有随机性的变量,而实际上。随机变量是函数。将试验结果映射为实数,更一般地理解为,随机变量是人为定义的基于试验结果的函数,该函数的定义域为试验结果的取值,其值域依据不同情境而不同。通常使用大写字母表示随机变量。
假设随机变量X表示将投掷六面骰子的结果映射为实数,能够定义X将投掷的结果i映射为i,比方投掷的结果为2,则X的结果就为2。
还能够定义假设投掷结果为偶数。则X的结果为1。否则为0。这样的类型的随机变量被称为指示器变量。用于表示某一事件是否发生。
随机变量X取值a的概率表示为P(X = a) 或P X(a),使用Val(X)表示随机变量的取值范围。
联合分布、边缘分布和条件分布
随机变量的分布指的是取某些值的概率,由定义可知分布本质上是概率,使用P(X)表示随机变量X的分布。
当提及多于一个变量的分布时。该分布称为联合分布,由于此时概率由涉及的全部变量共同决定。
考虑以下这个联合分布的样例。X为投掷骰子的随机变量。取值为[1,6],Y为抛掷硬币的随机变量,取值为[0,1],二者的联合分布为:
P | X=1 | X=2 | X=3 | X=4 | X=5 | X=6 |
|---|---|---|---|---|---|---|
Y=0 | 1/12 | 1/12 | 1/12 | 1/12 | 1/12 | 1/12 |
Y=1 | 1/12 | 1/12 | 1/12 | 1/12 | 1/12 | 1/12 |
使用P(X=a,Y=b)或PX,Y(a,b)表示X取a,Y取b时的概率,使用P(X,Y)表示X。Y的联合分布。
给定随机变量X和Y的联合分布,能够定义X或者Y的边缘分布。边缘分布指的是某个随机变量自身的概率分布,为了计算某个随机变量的边缘分布,须要将联合分布中其他随机变量相加,公式为:
条件分布指出了在当其他随机变量已知的情况,某个特定随机变量的分布。而对于某个随机变量X在Y=b的情况下取值为a的条件概率能够定义例如以下,并可依据该公式确定该变量的条件分布:
能够将上述公式扩展到基于多个随机变量的条件概率。比方,基于两个变量的:
使用符号P(X|Y=b)表示在Y=b的情况下,X的分布。P(X|Y)X分布的集合。当中每一个元素为Y取不同值时X的分布。
在概率论中,独立性意味着一个随机变量的分布不受还有一个随机变量的影响。使用以下的数学公式定义随即变量X独立于Y:
依据该公式及条件分布的公式能够推导出假设X独立于Y,那么Y也独立于X。推到步骤例如以下:
依据上面的推到过程能够得出P(X,Y)=P(X)P(Y)。也就是该公式是X和Y相互独立的等价公式。
更进一步能够定义条件独立。即已知一个或者多个随机变量的值,其余某些变量相互独立则称为条件独立。已知Z。X和Y相互独立的数学定义例如以下:
最后再看两个重要的定理,分别为链式规则和贝叶斯规则。
链式规则的公式例如以下:
贝叶斯规则的公式例如以下:
贝叶斯公式通过计算P(Y|X)的值来得到P(X|Y)的值。该公式能够通过条件公式推导而出:
分母的值可通过上面提到的边缘分布计算得出:
离散分布和连续分布
广义上讲。存在两类分布。分别为离散分布和连续分布。
离散分布意味着该分布下的随机变量仅仅能取有限的不同值(或者结果空间是有限的)。能够通过简单地枚举随机变量取每一个可能值的概率来定义离散分布,这样的枚举的方式称为概率质量函数,由于该函数将单位质量(总的概率,1)切割然后分给随机变量能够取的不同值。
连续分布意味着随机变量能够取无穷的不同值(或者结果空间是无穷的),使用概率密度函数(probability density function,PDF)定义连续分布。
概率密度函数f为非负的。可积分的函数:
随机变量X的概率依据概率密度函数可得:
特别的。一个连续分布的随机变量的值为不论什么给定单个值的概率为0,比方连续分布的随机变量X取值为a的概率为0。由于此时积分的上限和下限都为a。
由概率密度函数可引申出累积分布函数。该函数给出了随机变量小于某个值的概率,与概率密度函数的关系为:
因此依据不定积分的含义,
版权声明:本文博客原创文章,博客,未经同意,不得转载。
发布者:全栈程序员栈长,转载请注明出处:https://javaforall.cn/117652.html原文链接:https://javaforall.cn
边栏推荐
- Frequent MySQL operations cause table locking problems
- Point cloud file Dat file read save
- 解析五育融合之下的steam教育模式
- Duchefa low melting point agarose PPC Chinese and English instructions
- The Chinese Academy of Management Sciences gathered industry experts, and Fu Qiang won the title of "top ten youth" of think tank experts
- 1. Strengthen learning basic knowledge points
- 手机开户股票开户安全吗?我家比较偏远,有更好的开户途径么?
- 证券开户选择哪个证券比较好?网上开户安全么?
- E. Singhal and numbers (prime factor decomposition)
- Return to blowing marshland -- travel notes of zhailidong, founder of duanzhitang
猜你喜欢
2.<tag-哈希表, 字符串>补充: 剑指 Offer 50. 第一个只出现一次的字符 dbc
线程池的使用

Return to blowing marshland -- travel notes of zhailidong, founder of duanzhitang

渗透创客精神文化转化的创客教育
Abnova丨DNA 标记高质量控制测试方案
ProSci LAG3抗体的化学性质和应用说明

Classic implementation method of Hongmeng system controlling LED
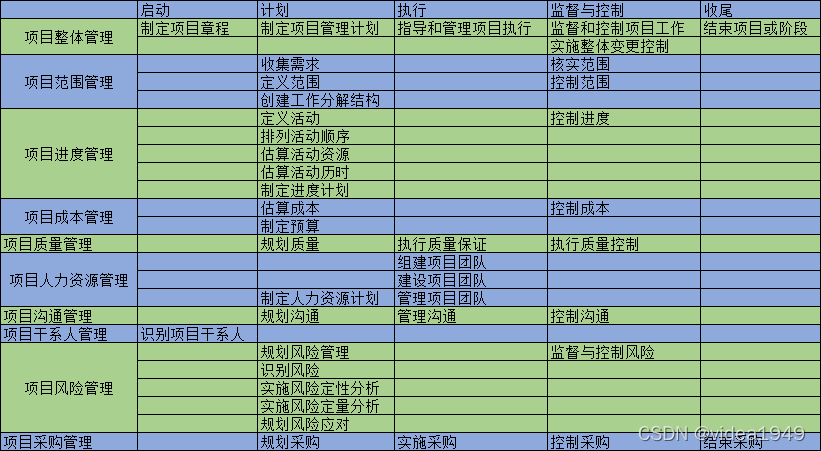
2.8 basic knowledge of project management process
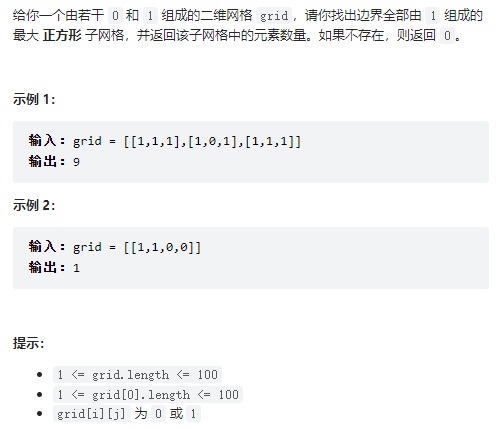
leetcode:1139. 最大的以 1 为边界的正方形
欢迎来战,赢取丰厚奖金:Code Golf 代码高尔夫挑战赛正式启动
随机推荐
Applet project structure
Applet global configuration
haas506 2.0开发教程 - 阿里云ota - pac 固件升级(仅支持2.2以上版本)
ProSci LAG3抗体的化学性质和应用说明
[record of question brushing] 1 Sum of two numbers
Abnova丨 MaxPab 小鼠源多克隆抗体解决方案
培养机器人教育创造力的前沿科技
鸿蒙os第四次学习
Duchefa d5124 md5a medium Chinese and English instructions
Codeforces Round #804 (Div. 2) - A, B, C
教你自己训练的pytorch模型转caffe(一)
渗透创客精神文化转化的创客教育
小程序全局配置
[Yugong series] go teaching course in July 2022 004 go code Notes
Applet page navigation
The Chinese Academy of Management Sciences gathered industry experts, and Fu Qiang won the title of "top ten youth" of think tank experts
PHP反序列化+MD5碰撞
Selenium element information
Abnova fluorescent dye 620-m streptavidin scheme
[quick start of Digital IC Verification] 2. Through an example of SOC project, understand the architecture of SOC and explore the design process of digital system