当前位置:网站首页>Detailed explanation of the ranking of the best universities
Detailed explanation of the ranking of the best universities
2022-07-05 04:49:00 【Prosperity comes to an end and the city is ruined 891】
#2021/10/16 Saturday
# Crawling https://www.shanghairanking.cn/rankings/bcur/202111 The top Chinese Universities on the website 20 Famous university “ ranking ”“ University name ”“ Provinces ”“ Total score ” Four things
# Before crawling, carefully observe the web page source code of the content to be crawled , Include the tag element where the content is located (<tbody><tr><td><div><a>), Sort the crawled content in the same tag
# The website changes every year , The source code of the website will change , In recent years, there are many spaces in the content tags we need to crawl , Attention should be paid to handling
import requests# Role of request , The simple understanding is to request web pages url link , Then climb it
import bs4# In the second method bs4 Tag definition function of element
from bs4 import BeautifulSoup# This BeautifulSoup Library is a function of typesetting and beautifying web pages , To the original web page html Wrap closer to make it look more comfortable
def getHTMLText(url):# Get university rankings from the web : Defined function getHTMLText()
try: # remarks 1
r = requests.get(url,timeout=30)# adopt get Function to obtain url Information
r.raise_for_status()# Used to generate abnormal information
r.encoding = r.apparent_encoding# Modify encoding ,apparent_encoding It's usually utf-8, Avoid garbled code .
return r.text# If successful, the web page information of the link will be returned
except:
return ""# Otherwise, it is abnormal information , Return to empty string
def fillUnivList(ulist, html):# Extract the information needed in the university ranking web page and store it in the appropriate list
soup = BeautifulSoup(html, "html.parser")# adopt BeautifulSoup Function to adjust the page , Make the format more convenient to see , use html The parser
for tr in soup.find('tbody').children:# remarks 2
if isinstance(tr, bs4.element.Tag):# remarks 3( To filter out bs4 Other information of non label information defined by the Library )
a = tr('a')# Will all a The tag is saved as a list type
tds = tr('td')# Will all td The tag is saved as a list type
ulist.append([tds[0].text.strip(), a[0].text.strip(), tds[2].text.strip(),tds[4].text.strip()])
#td There is more white space before the content in the label ,strip() Method is used to remove the characters specified at the beginning and end of a string ( The default is space or newline ) Or character sequence
def printUnivList(ulist, num):# Use data structure to display and output results
tplt = "{0:^10}\t{1:{4}^10}\t{2:^10}\t{3:^10}"
# use tplt Store output The definition of format ; among ^ Indicates center alignment ,10 According to the said 10 The length of characters is output . The length is not enough to fill in spaces ,{4} Said the use of format Functional
# The fourth variable is filled , That is, fill in the blanks in Chinese .
print(tplt.format(" ranking "," School name "," Provinces "," Total score ",chr(12288)))
#Python Use .format Function to format the output
#chr(12288) Means to fill in blanks according to Chinese habits , To output aligned constraints
for i in range(num):
u=ulist[i]
print(tplt.format(u[0],u[1],u[2],u[3],chr(12288)))
print("Suc"+str(num))
def main():
uinfo = []# Store University Information
url = "https://www.shanghairanking.cn/rankings/bcur/202111"
html = getHTMLText(url# Get the content of this page
fillUnivList(uinfo,html)# Analyze the content of this web page , Store in uinfo In the list
printUnivList(uinfo,20)# Print the information of the top 20 in the list
main()
# remarks 1:
#try except The execution flow of the statement is as follows :
# First, execute try Code block in , If an exception occurs during execution , The system will automatically generate an exception type , And submit the exception to Python Interpreter , This process is called catching exceptions .
# When Python When the interpreter receives an exception object , Will look for someone who can handle the exception object except block , If you find the right except block , Then give the exception object to the except Block handling ,
# This process is called exception handling . If Python The interpreter could not find a to handle the exception except block , Then the program is terminated ,Python The interpreter will also exit .
# remarks 2:
# The following functions need to be written by observing the source code of the web page ,( You can use the web page source code page ctrl+f Find the tag ) It can be seen that : One <tr></tr> It contains all the information of a University , Every
#<td></td> It also includes a ranking of different aspects of universities 、 name 、 Provinces and cities, etc .tr The last attribute of is tbody, adopt tbody The child node of search traverses all tr, stay tr label
# Find td Tag information , And will be the first 1、2、4 Corresponding to tds No 0、1、3 Column information , The first 1 Corresponding a The... In the array 0 The information of the column is stored in ulist in .
# remarks 3:
#isinstance Function USES ,isinstance() Function to determine whether an object is a known type , similar type().isinstance(object, classinfo),object: Instance object .
#classinfo: It can be a direct or indirect class name 、 Basic types or tuples made up of them . Determine whether the instance belongs to which class .
#bs4.element.Tag:bs4 Defined in the library tag type
边栏推荐
- Uncover the seven quirky brain circuits necessary for technology leaders
- Detailed introduction of OSPF header message
- CUDA Programming atomic operation atomicadd reports error err:msb3721, return code 1
- The 22nd Spring Festival Gala, an immersive stage for the yuan universe to shine into reality
- Leetcode hot topic Hot 100 day 33: "subset"
- 【acwing】240. food chain
- 2022 U.S. college students' mathematical modeling e problem ideas / 2022 U.S. game e problem analysis
- Is $20billion a little less? Cisco is interested in Splunk?
- The remainder operation is a hash function
- #775 Div.1 C. Tyler and Strings 组合数学
猜你喜欢
AutoCAD - isometric annotation

2022-2028 global and Chinese video coding and transcoding Market Research Report
![[crampon game] MC tutorial - first day of survival](/img/81/82034c0382f545c39bd8c15f132ec7.jpg)
[crampon game] MC tutorial - first day of survival

Advanced length of redis -- deletion strategy, master-slave replication, sentinel mode
解密函数计算异步任务能力之「任务的状态及生命周期管理」

【acwing】240. food chain
WeNet:面向工业落地的E2E语音识别工具
An article takes you to thoroughly understand descriptors
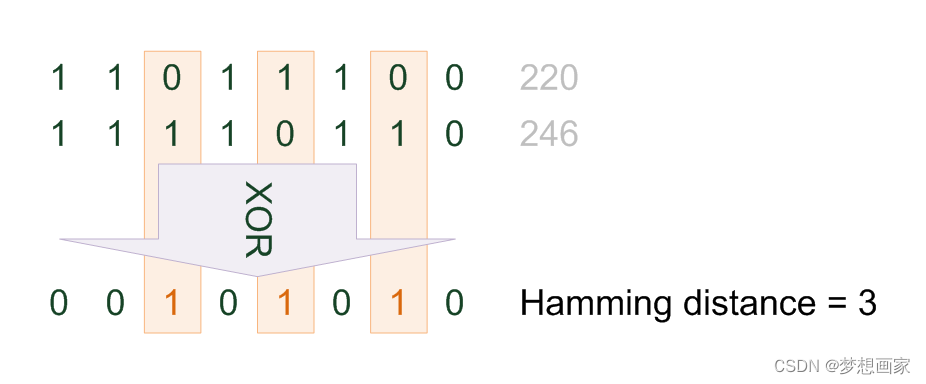
Introduce Hamming distance and calculation examples
Emlog blog theme template source code simple good-looking responsive
随机推荐
[groovy] closure (Introduction to closure class closure | this, owner, delegate member assignment and source code analysis)
XSS injection
Error statuslogger log4j2 could not find a logging implementation
History of web page requests
[ideas] 2021 may day mathematical modeling competition / May Day mathematical modeling ideas + references + codes
#775 Div.1 B. Integral Array 数学
猿人学第一题
MD5绕过
中国艾草行业研究与投资前景预测报告(2022版)
Hypothesis testing -- learning notes of Chapter 8 of probability theory and mathematical statistics
775 Div.1 B. integral array mathematics
[groovy] closure (closure call is associated with call method | call () method is defined in interface | call () method is defined in class | code example)
Group counting notes (1) - check code, original complement multiplication and division calculation, floating point calculation
Leetcode hot topic Hot 100 day 33: "subset"
Introduce Hamming distance and calculation examples
CUDA Programming atomic operation atomicadd reports error err:msb3721, return code 1
【acwing】836. Merge sets
次小生成树
2022 thinking of mathematical modeling D problem of American college students / analysis of 2022 American competition D problem
[PCL self study: feature9] global aligned spatial distribution (GASD) descriptor (continuously updated)