当前位置:网站首页>A survey of automatic speech recognition (ASR) research
A survey of automatic speech recognition (ASR) research
2022-07-05 04:29:00 【Wang Xiaoxi WW】
Automatic speech recognition (ASR) Research Summary
Note:
- Most of the text is taken from A survey of speech recognition research
- WeNet The deployment of refers to this Blog WeNet Platform building
List of articles
- Automatic speech recognition (ASR) Research Summary
- zero 、 Reference material
- One 、 Basic knowledge of speech recognition
- 1、 feature extraction (MFCC Acoustic features )
- 2、 Acoustic models ( Establish the mapping relationship between phonetic features and phonemes ( Conditional probability ), The most important part of speech recognition )
- 3、 Language model (n-gram or Use RNN Modeling language model , Calculate the prior probability of phonemes )
- 4、 End to end speech recognition (2020 ContextNet)
- Two 、 Speech recognition to difficulties and hot spots
- 3、 ... and 、 Discussion on speech recognition landing scheme
zero 、 Reference material
1、 Reference documents
- be based on PaddlePaddle Realized DeepSpeech2 End to end Chinese speech recognition model
- ASR- Industrial Chinese speech recognition system
- THCHS-30 Dataset Download (EU Mirror image )
- Several latest free and open source Chinese voice data sets
- ASRT Speech recognition document
- Wenet - Industrial oriented E2E Speech recognition tools
2、 Reference paper
- A survey of speech recognition research
- Speech recognition patent technology overview
- A survey of acoustic models in speech recognition
- WeNet Production Oriented Streaming and Non-streaming End-to-End Speech Recognition Toolkit
3、 Reference code
One 、 Basic knowledge of speech recognition
Reference resources A survey of speech recognition research
Speaking from the composition of speech recognition system , A complete set Speech recognition system Include Preprocessing 、 feature extraction 、 Acoustic models 、 Language model as well as search algorithm Equal module , Its structure is shown in the figure :
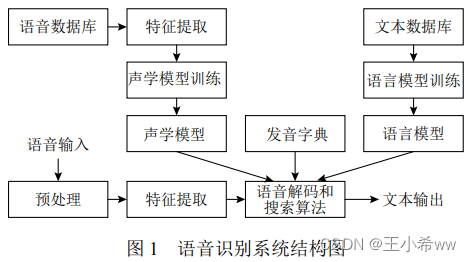
1、 feature extraction (MFCC Acoustic features )
Usually , Before speech recognition , It is necessary to extract effective acoustic features according to the waveform of speech signal . The performance of feature extraction is critical to the accuracy of subsequent speech recognition systems , Therefore, it is necessary to have certain robustness and discrimination . At present, speech recognition systems are commonly used Acoustic features There is Mel frequency cepstrum coefficient (Mel-frequency cepstrum coefficient,
MFCC)、 Perceptual linear prediction coefficient (perceptual linear predictive cepstrum coefficient, PLP)、 Linear prediction cepstrum coefficient (linear prediction cepstral coefficient, LPCC)、 Mel filter bank coefficients (Mel filter bank, Fbank) etc. .
MFCC It is the most classic phonetic feature , The extraction process is shown in the figure 2 Shown . MFCC The extraction of mimics the human auditory system , Simple calculation , The low-frequency part also has good frequency resolution , It has certain robustness in noisy environment . therefore , At present, most speech recognition systems still use MFCC As characteristic parameters , And achieved good recognition effect .
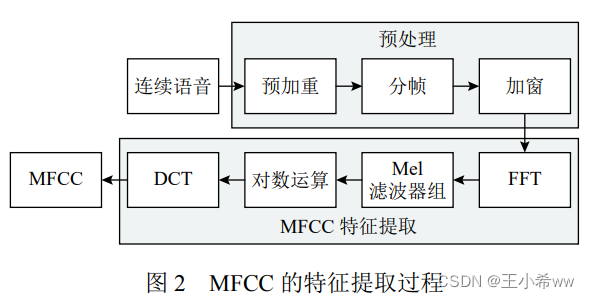
2、 Acoustic models ( Establish the mapping relationship between phonetic features and phonemes ( Conditional probability ), The most important part of speech recognition )
Let the feature vector sequence of a speech signal obtained by feature extraction be X = [ x 1 , x 2 , … , x N ] X=[x_1, x_2, …, x_N] X=[x1,x2,…,xN], among x i x_i xi yes The eigenvector of a frame , i = 1 , 2 , … , N i=1, 2, …,N i=1,2,…,N Is the number of eigenvectors . This paragraph Text sequence corresponding to speech Set to W = [ w 1 , w 2 , … , w M ] W=[w_1 , w_2, …, w_M] W=[w1,w2,…,wM], among w i w_i wi Is a basic component unit , Such as phoneme 、 word 、 character , i = 1 , 2 , … , M i=1, 2, …, M i=1,2,…,M, M Is the dimension of the text sequence . from Bayesian perspective , The goal of speech recognition is to generate feature vectors from all possible sources X X X Find the text sequence with the highest probability W ∗ W^* W∗, It can be expressed by formula (1) optimization problem :
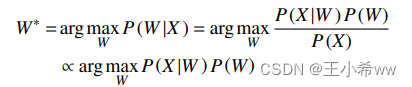
By the type (1) You know , To find the most likely text sequence, two probabilities must be made P ( X ∣ W ) P(X|W) P(X∣W) and P ( W ) P(W) P(W) The product of is the largest , among P ( X ∣ W ) P(X|W) P(X∣W) For conditional probability , Determined by the acoustic model ; P ( W ) P(W) P(W) For a priori probability , Determined by the language model . Acoustic model and language model are more accurate in representing speech signal , The more accurate the speech system effect is .
The acoustic model is the following formula (1) Medium P ( X ∣ W ) P(X|W) P(X∣W) Modeling , In speech features and phoneme Establish a mapping relationship between , That is, after a given model Probability of speech waveform , Its input is the feature vector sequence of speech signal after feature extraction .
Acoustic model is the most important part of the whole speech recognition system , Only by learning pronunciation well , To smooth and pronunciation dictionary 、 Better recognition performance can be achieved by combining language models .
Common acoustic models are GMM-HMM, The model uses HMM Ability to model time series , Describe how voice can be transferred from
Transition from one short-term stable segment to the next short-term stable segment ; Besides , HMM There is no correlation between the number of hidden states and the number of observed states , It can solve the problem of unequal length of input and output in speech recognition . Each of the acoustic models HMM It's all about 3 Parameters : Initial state probability 、 State transition probability and observation probability , The observation probability depends on the probability distribution of the eigenvector , Gaussian mixture model GMM Modeling .
The rise of deep learning provides a new way for acoustic modeling , Scholars use deep neural networks (deep neural network, DNN) Instead of GMM It is estimated that HMM Observation probability of , Got it DNN-HMM Speech recognition system . be based on DNN-HMM The framework of speech recognition system is as follows :
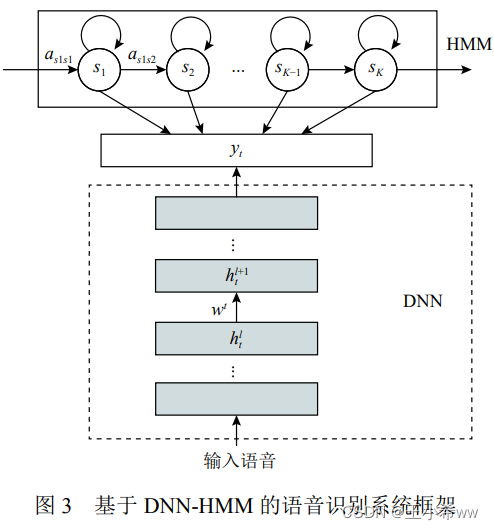
However , DNN There is still a lack of context modeling ability and flexibility for temporal information . To address this issue , Cyclic neural network with stronger ability to use context information RNN And convolution neural network CNN Introduced into acoustic modeling .
Overall speaking , In recent years, the research on acoustic model in speech recognition is still focused on neural network , According to different application scenarios and requirements, the above classical network structure is integrated and improved , In order to train more complex 、 A more powerful acoustic model .
3、 Language model (n-gram or Use RNN Modeling language model , Calculate the prior probability of phonemes )
Language models are used to predict characters ( word ) The probability of a sequence , Judge whether a language sequence is a normal statement , That is, how to calculate the equation (1) Medium P ( W ) P(W) P(W). Conventional Language model n-gram It's a kind of having Strong Markov independence hypothesis Model of , It holds that the probability of any word appearing is only limited to the previous n–1 The probability of a word appearing , The formula is expressed as follows :
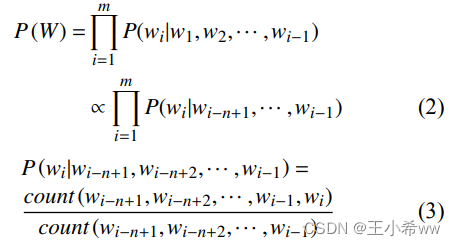
However , Due to the lack of training corpus data or the low frequency of phrase use and other common factors , Words that do not appear in the training set or a subsequence that does not appear in the training set may appear in the test set , This will lead to n-gram The probability calculated by the language model is zero , This situation is called unregistered words (out-of-vocabulary, OOV) problem . To alleviate this problem , Some smoothing techniques are usually used , Common smoothing methods are Discounting、Interpolation and Backing-off etc. . n-gram The advantage of the model is that its parameters are easy to train , Highly interpretable , And it completely includes the former n–1 All the information of a word , It can save decoding time ; But it is difficult to avoid the problem of dimension disaster , Besides n-gram The generalization ability of the model is weak , It's easy to see OOV problem , Lack of long-term dependence .
To further solve the problem , RNN Used for language model modeling .RNNLM The loop of the hidden layer in the can get more context information , The model is trained by optimizing the cross entropy on the whole training set , So that the network can model the internal relationship between natural language sequences and subsequent words as much as possible . Its advantage is that the same network structure and super parameters can handle any length of historical information , Be able to use the representation learning ability of neural network , It greatly avoids the problem of not logging in ; However, the parameters in the neural network cannot be modified arbitrarily , It is not conducive to the addition and modification of new words , And the real-time performance is not high .
The performance of language models usually adopts confusion (perplexity ,PPL) Evaluate . PPL It is defined as the reciprocal of the probability geometric mean of the sequence , The formula is defined as follows :
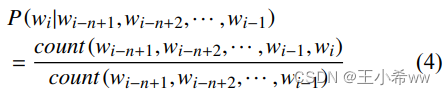
PPL Smaller means that the probability of the next prediction word appearing in a given history is higher , The better the effect of this model .
4、 End to end speech recognition (2020 ContextNet)
Traditional speech recognition consists of several modules , Train independently of each other , However, the training objectives of each sub module are different , Easy to produce Error accumulation , So that the optimal solution of the sub module is not necessarily the global optimal solution . In response to this question , Scholars have proposed an end-to-end speech recognition system , Direct equality (1) The probability of P ( W ∣ X ) P(W|X) P(W∣X) Modeling , The input voice waveform ( Or eigenvector sequence ) Convert directly to words 、 Character sequence . End to end speech recognition will be acoustic model 、 Language model 、 Pronunciation dictionary, etc
Modules are housed in a system , Directly optimize the final goal through training , Such as word error rate (word error rate, WER)、 Word error rate (character error rate, CER), It greatly simplifies the whole modeling process .
At present, end-to-end speech recognition methods are mainly based on Connection timing classification (connectionist temporal classification, CTC) And based on Attention mechanism (attention model) Two kinds of methods and their improvements .
CTC Introduce a blank symbol (blank) Solve the problem of unequal length of input and output sequences , The main idea is to maximize the sum of all possible sequence probabilities , There is no need to consider the alignment relationship between voice frames and characters , Only input and output are needed to train . CTC It is essentially a loss function , Often with LSTM A combination of . be based on CTC The structure of the model is simple , High readability , However, it is highly dependent on pronunciation dictionaries and language models , And we need to make the assumption of independence . RNN-Transducer The model is right CTC An improvement of , Join a language model prediction network , And on and on CTC The network gets new output through a full connection layer , That's it CTC Output the problem of conditional independence assumption , It can accumulate information about historical output and historical speech features , Make better use of linguistic information to improve recognition accuracy .
be based on Attention mechanism The end-to-end model of was first used Machine translation , It can automatically realize the conversion between word sequences of different lengths in two languages . The model is mainly composed of coding network 、 Decoding network and attention sub network . The coding network maps the speech feature sequence into high-dimensional feature sequence through deep neural network , Attention network allocation weight coefficient , The decoding network is responsible for outputting the predicted probability distribution . The model does not need prior alignment information , also No phoneme sequence The assumption of independence between , No Need a pronunciation dictionary And other artificial knowledge , It can really realize end-to-end modeling .2016 In, Google put forward a Listen-Attend-Spell (LAS) Model , LAS The model really realizes end-to-end , Joint training of all components , There is no independence assumption . but LAS The model needs to identify the whole input sequence , Therefore, the real-time performance is poor , Since then, many scholars have continuously improved the model .
At present, end-to-end speech recognition system is still a research hotspot in the field of speech recognition , be based on CTC、attention Mechanism and the system combining the two , Have achieved very good results . among Transformer-Transducer The model will RNN-T In the model RNN Replace with Transformer Improved computational efficiency , And control attention Width of the module context time slice , Meet the needs of streaming speech recognition . 2020 Google put forward ContextNet Model [39], use Squeeze-and-Excitation Module obtains global information , And pass Progressive downsampling and Model scaling Achieve a balance between reducing model parameters and maintaining recognition accuracy . stay Transformer Model capture adds CNN Good at local feature extraction Conformer Model , Achieve better accuracy with fewer parameters . In fact, the recognition effect of the end-to-end speech recognition system in many scenes has exceeded that of the recognition system under the traditional structure , However, there is still a way to go before it can be widely used commercially .
Two 、 Speech recognition to difficulties and hot spots
As a key technology of human-computer interaction, speech recognition has always been a research hotspot in the field of scientific and technological applications . at present , Speech recognition technology has made a lot of achievements from theoretical research to product development , However , Relevant research and application are still on the ground It's a big challenge , Specifically, it can be summarized into the following aspects :
1、 Robust speech recognition
at present , Under ideal conditions ( Low noise near field ) The accuracy of speech recognition has reached a certain level . However , In some complex speech environments , Such as far field of sound source , Low SNR 、 Room reverberation 、 Echo interference and multi-source signal interference , It makes the task of speech recognition face great challenges . therefore , Research on robust speech recognition for complex environments is a difficult and hot topic in the field of speech recognition . At present , The research on speech recognition in complex environment can be roughly divided into 4 A direction :
- (1) In front of speech recognition , Using signal processing technology to improve signal quality : Adopt microphone array technology to collect far-field sound source signals , And then through Sound source location 、 Echo cancellation 、 Sound source separation or Voice enhancement Improve the quality of voice signal . for example , Literature on adaptive acoustic echo cancellation based on deep learning (acoustic echo cancellation, AEC) In order to adapt to the changes of the deployment environment , To improve the quality of voice signal ; The literature [45] Based on the framework of deep clustering, a blind source separation method combining spectral and spatial information is proposed ; The literature [46] Use to generate countermeasures based on network (generative adversial networks, GAN) For the enhanced network of the basic framework
Noise suppression , So as to improve the quality of the target speech signal ; - (2) Look for new robustness features , Eliminate the influence of non target speech signal as far as possible : for example , Cepstrum coefficient of gamma pass filter (Gammatone frequency cepstrumcoefficient, GFCC) And other auditory characteristic parameters are more suitable for fitting the selectivity of human ear basement membrane , It conforms to the characteristics of human hearing ; perhaps , Adopt automatic encoder [48]、 The migration study [49] And other methods to extract more robust features ;
- (3) Model improvement and adaptation : Proposed by Shanghai Jiaotong University VDCNN[6] as well as VDCRN[7] Enhance the robustness of the algorithm by deepening the convolution layer , Literature utilization GAN Build acoustic model based on the mutual game between generator and discriminator and bottleneck characteristics , The literature adopts teacher-student learning The acoustic model of clean speech training is used as the teacher model to train the student model in the noisy environment ;
- (4) Multimodal data fusion : When in high noise environment or voice overlap caused by multiple speakers , The target speech signal is easy to be corrupted by noise or other non target sound sources ( interference signal )“ Flood ”, At this time, only the pickup device captures “ voice ” Signals often fail to achieve good recognition performance ; At this time , Combine voice signals with other signals such as Vibration signal of vocal cord [54]、 Image signal of mouth [55] And so on , Better improve the robustness of the identification system . for example , The literature [56] With RNN-T For the framework , A multimodal attention mechanism is proposed to fuse audio and video information , To improve recognition performance ; The literature [57] Also based on RNN-T, But use vision-to-phoneme model(V2P) Extracting visual features , Together with the audio features, it is input to the encoder at the same frame rate , Good recognition performance is achieved .
2、 Low resource speech recognition
This is a It is a general term for the study of language recognition in various small languages . Small languages are different from dialects , Have an independent and complete pronunciation system , Strong heterogeneity but lack of data resources , Difficult to adapt to Chinese 、 English based speech recognition system , Acoustic modeling needs to use insufficient data resources to train as many acoustic features as possible . The basic idea to solve this problem can be summarized as extracting commonalities from the rich resources of mainstream languages and training common models , On this basis, train the small language model . The literature [58] To solve the problem that unnecessary specific information will be learned in the shared hidden layer , A model of parallel shared layer and unique layer is proposed , It passes through Confrontational learning ensures that the model can learn more invariant features between different languages . However , There are many kinds of small languages , It is not cost-effective to spend too much resources to establish a recognition system alone , So now it's mainly Study the speech recognition system of multilingual fusion .
3、 The fuzziness of speech
It exists in all languages Similar pronunciation 's words , Different speakers have different pronunciation habits and accents 、 Dialect and other issues , Native speakers and non-native speakers speak the same language with different accents , It is difficult to model individual accents . Aiming at the problem of multi accent modeling , The existing methods can generally be divided into two categories, which are irrelevant to the accent and related to the accent , The models that have nothing to do with accent generally perform better . Literature attempts to establish a unified multi accent recognition model through the collection of specific accent models ; The literature combines acoustic model and accent recognition classifier through multi task learning ; The literature is based on GAN A pre training network is constructed to distinguish invariable accents from acoustic features .
4、 Low computing resources
Neural network models with high accuracy and good effect often need a lot of computing resources and have a huge scale , But mobile devices ( Such as mobile phone 、 Smart home, etc ) Limited computing power and memory , Difficult to support , Therefore, the model needs to be compressed and accelerated . At present, the compression methods used for deep learning models are Network pruning 、 Parameter quantification 、 Distillation of knowledge etc. . The literature [65] A dynamic sparse neural network is constructed by network pruning (dynamic sparsity neural networks, DSNN) , Provide network models with different sparse levels , The ability to dynamically adjust to a variety of hardware types with different resource and energy constraints . The literature [66] By quantifying network parameters, it can reduce memory consumption and speed up calculation . Knowledge distillation can move the knowledge of complex models into small models , It has been applied to the language model of speech recognition system [67]、 Acoustic models [68] And end-to-end models [29,69,70] And so on . The literature [71] Knowledge distillation is used to transfer the recognition system of audio-visual two modes to the single auditory model , Reduced the scale of the model , Speed up the training , But it does not affect the accuracy .
3、 ... and 、 Discussion on speech recognition landing scheme
Reference resources I want to know what is the mainstream scheme of speech recognition ? What is the mainstream landing plan ?
At present, the mainstream solutions of open source speech recognition are K2、PaddleSpeech、ESPnet 、WeNet. What is the mainstream landing plan , This should be said separately , If you want to engage in scientific research , that ESPnet It will be more suitable ,WeNet It's fine too ; If the product is to be launched , So for now WeNet It's the one who walks in the front . First ,WeNet For some problems of landing , Proposed a language model 、 Hot words and many other solutions , Next, we will continue to optimize hot words , A hot word may come out later 2.0, You can also pay attention to . secondly , We can basically put WeNet Deploy it , Use a real business .
Reference resources I want to know what is the mainstream scheme of speech recognition ? What is the mainstream landing plan ?
At present, there should be two mainstream programs : be based on Kaldi System and system based on end-to-end model , These two options , I think there are still two mainstream directions at this stage . Although many papers and works have claimed that their end-to-end models are better than Kaldi Of TDNN-LFMMI The system is as good as it is , But be careful , Are these comparisons completely reasonable ? For example, take a pure Fluid Kaldi Model Go to PK Completely Non streaming end-to-end model , That must be the end-to-end model better !Kaldi The system of , It has its own complete framework , From model training to decoder , Even now many companies have upgraded to end-to-end systems ,Kaldi The toolkit is still an important tool , For example GMM model training 、 feature extraction 、 Important functions such as alignment are still in use . The following is an introduction to these two mainstream solutions , But for this problem , I think my answer should be : The mainstream landing plan is based on CTC or Transducer For the leading end-to-end speech recognition system .
1、Kaldi System
Kaldi System key “ Neural network acoustic model + Decoding diagram “ To the plan ; Neural networks are generally used TDNN More , The training loss function is LFMMI+CE Joint training . The decoding diagram is based on WFST Of ,HCLG It's compounded . It can be said that most company decoders are based on Kaldi Engineering optimization , Even today's end-to-end systems , Want to put it into formal use , Still use one based on WFST The decoder of , It's just a relatively simple composition . Although many companies' systems are still based on Kaldi Of , But in the long run ,Kaldi This system should be abandoned soon . One side , This system is completely C++ Realization , Although it is a very good open source project , The code quality is very good , But for users , The threshold is also relatively high , And now based on pytorch Comparison of the plans , It's simply too complicated . A beginner , Want to write a neural network structure that is currently the most cutting-edge , use pytorch Combined with open source code , Maybe it can be done in a few days , But if you use Kaldi, That's much more complicated . On the other hand , The end-to-end system continues to improve , With Google 、 Voice teams from companies such as Microsoft and Amazon , Constantly Polish various flow end-to-end models , The performance of the system also exceeds Kaldi, The modeling process is very simple and clear , So everyone will definitely move to the end-to-end system .
2、 End to end systems
End to end system is a relatively broad term , Because there are many end-to-end solutions , The so-called end-to-end , In fact, they are all relative to the previous modeling of sequence data “frame-by-frame” In terms of . The end-to-end solutions are “sequence-to-sequence” How to model , such as CTC,RNN-Transducer(RNNT) as well as Attention based Enocder-Decoder(AED). When end-to-end became popular , We hope that the larger the modeling granularity, the better , For example, input voice , Output Chinese characters directly , Then this is the most intuitive end-to-end system . But with everyone's re-re-research, It is found that this system can't really be used , An end-to-end system that does not integrate any external information cannot really be put into commercial use , Finally , You still choose to use the modeling unit with relatively small granularity , such as phone Modeling , Finally, you need to add a simple TLG Decoding diagram , It's just the training of acoustic model , Adopted “sequence-to-sequence” Loss function of . From this perspective , Our current so-called end-to-end system , Most of them are still a hybrid system , But the training process and modeling process have been simplified .
In the course of practical use , be based on CTC and Transducer There are relatively many systems , Because as long as they use streaming Neural Networks , It can realize the real-time recognition of streaming .CTC and Transducer Just two loss functions , The acoustic model can use any neural network , As long as this neural network has certain memory ability or the ability to model context . Up to now (20220623), I believe that the neural networks we use should be mainly Conformer 了 , For example, now the more popular WeNet, In fact, that is Conformer+CTC The architecture of ,google Pushed by force Cascaded encoder The way , It's using Conformer+Transducer(C-T) The way . So if contrast CTC and Transducer Two loss functions , I prefer Transducer Loss function , This loss function is theoretically better than CTC More perfect , And when actually used , There are many tricks you can play , Like Microsoft's Meng Zhong Doctor, their ILME、 our Tiny Transducer[1] Some of the tips in , It's all very effective . If you want to deploy a model quickly , You can use WeNet, at present WeNet Just to support Conformer-CTC,Conformer The implementation of is mainly a reference Espnet, If you want to train a small lightweight model , Adopt other structures , Then you still need to code it yourself . As far as I know , At present, each company basically has its own set based on pytorch End to end system , Because each company's own business is different , The model structure required must be different , The models used in the device and cloud will be very different , Another is pytorch Of jit The export model ,C++ The environment deployment is done very well , It greatly simplifies the difficulty of model deployment .
边栏推荐
- level18
- PHP reads the INI file and writes the modified content
- 小程序中实现文章的关注功能
- [thingsboard] how to replace the homepage logo
- Introduction to RT thread kernel (5) -- memory management
- How to carry out "small step reconstruction"?
- Raki's notes on reading paper: soft gazetteers for low resource named entity recognition
- 如何优雅的获取每个分组的前几条数据
- Matplotlib draws three-dimensional scatter and surface graphs
- About the prompt loading after appscan is opened: guilogic, it keeps loading and gets stuck. My personal solution. (it may be the first solution available in the whole network at present)
猜你喜欢
Longyuan war "epidemic" 2021 network security competition web easyjaba
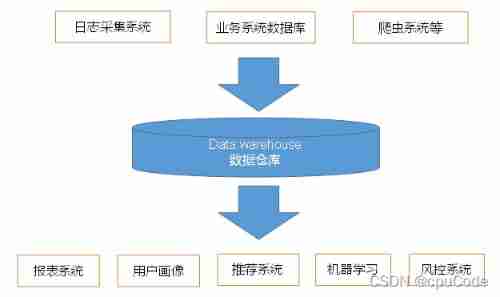
User behavior collection platform
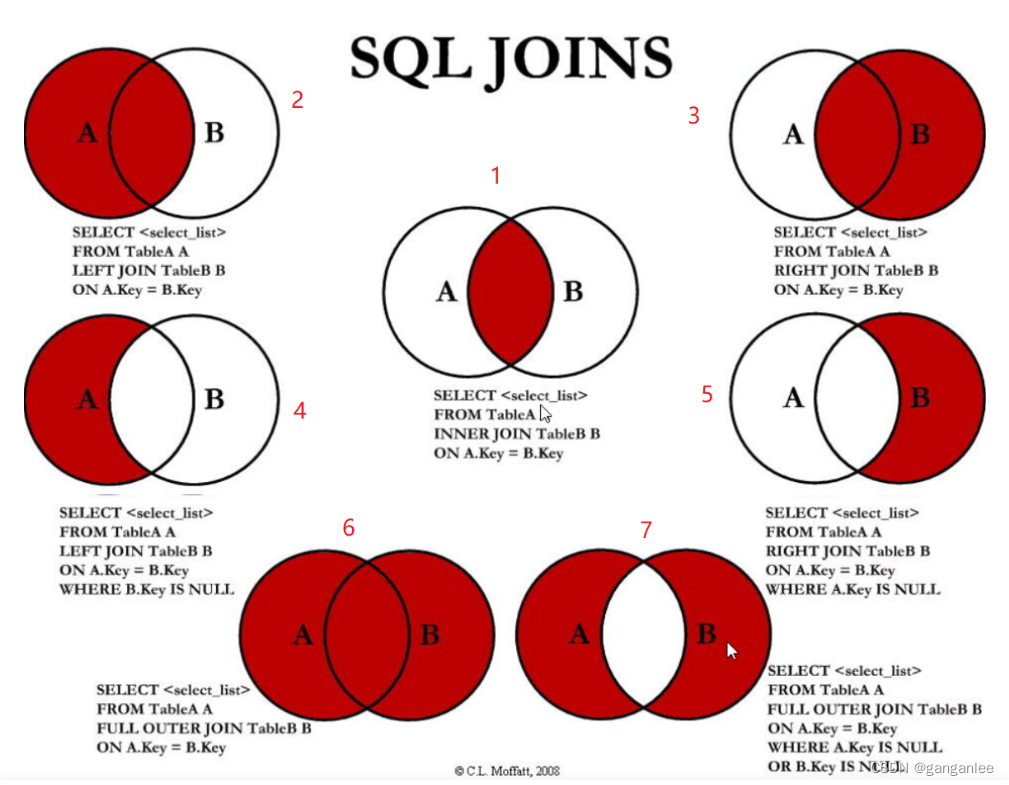
mysql的七种join连接查询
![[phantom engine UE] the difference between running and starting, and the analysis of common problems](/img/e2/49d6c4777c12e9f4e3f8b6ca6db41c.png)
[phantom engine UE] the difference between running and starting, and the analysis of common problems
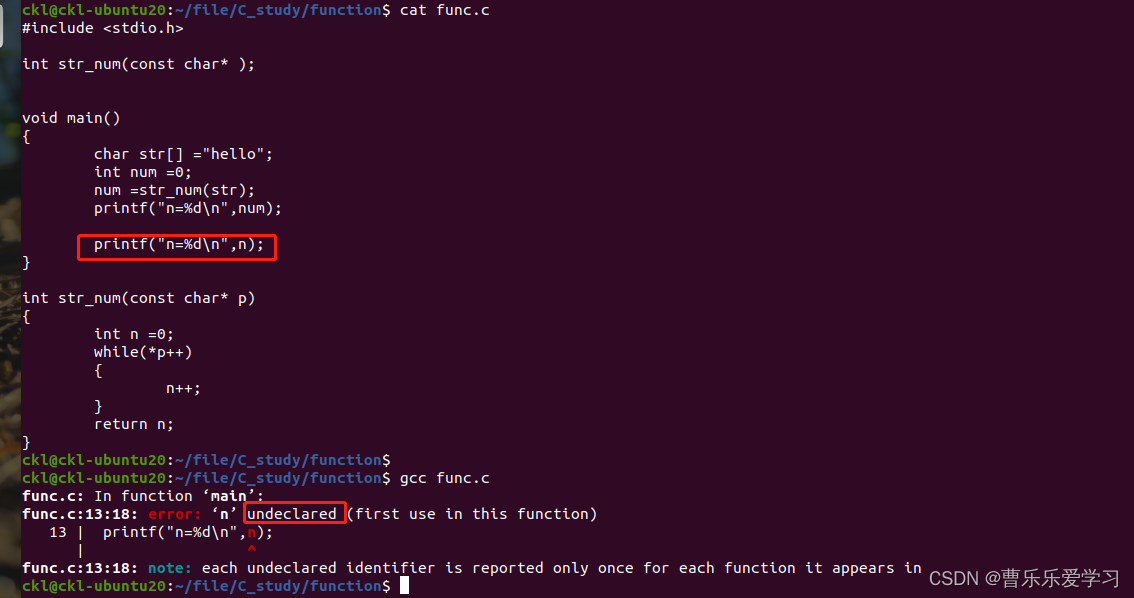
函数(基本:参数,返回值)
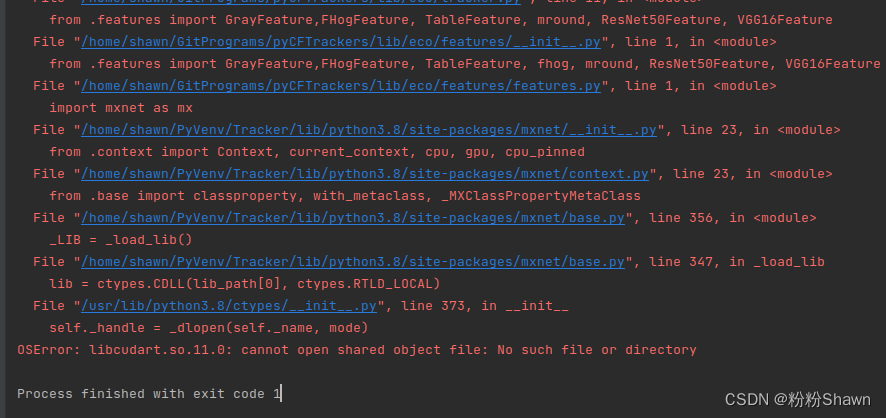
mxnet导入报各种libcudart*.so、 libcuda*.so找不到

Kwai, Tiktok, video number, battle content payment

Discussion on the dimension of confrontation subspace

Components in protective circuit
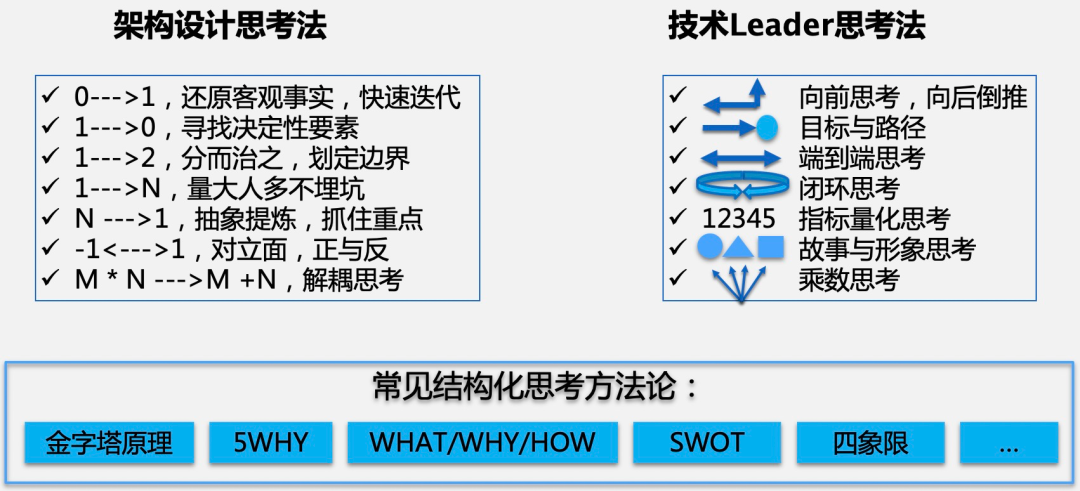
Uncover the seven quirky brain circuits necessary for technology leaders
随机推荐
PR video clip (project packaging)
Web开发人员应该养成的10个编程习惯
kubernetes集群之调度系统
[uniapp] system hot update implementation ideas
Threejs Internet of things, 3D visualization of farm (III) model display, track controller setting, model moving along the route, model adding frame, custom style display label, click the model to obt
Decimal to hexadecimal
网络安全-记录web漏洞修复
官宣!第三届云原生编程挑战赛正式启动!
PHP reads the INI file and writes the modified content
机器学习 --- 决策树
[thingsboard] how to replace the homepage logo
【虚幻引擎UE】打包报错出现!FindPin错误的解决办法
Number of possible stack order types of stack order with length n
windows下Redis-cluster集群搭建
3 minutes learn to create Google account and email detailed tutorial!
Qt蓝牙:搜索蓝牙设备的类——QBluetoothDeviceDiscoveryAgent
Power management bus (pmbus)
Function (error prone)
首席信息官如何利用业务分析构建业务价值?
假设检验——《概率论与数理统计》第八章学习笔记