This article is not published synchronously in personal technology blog , Details are available. Jab hard
You can also scan the right side of the screen, and pay attention to the official account. , There is personal contact in official account. , Wait for you to flirt ...
A few days ago, I came home from work and was dealing with a problem I didn't solve during the day bug, The sound of the object came from the toilet :
object :xx, Do you have 《 A brief history of time 》 Do you ?
I : I went to ! sister , What's your hobby , I don't pick up shit when I have time !
object :... They say Hawking's popular science works 《 A brief history of time 》, It's a book !
I : Oh , Then I didn't ...
object : People want to see it , Please help me borrow a book from the library tomorrow ...
I : I have to change it tomorrow ...
object : Don't you love me anymore , Break up !
I : I'll go early in the morning ~
I arrived at the library early the next morning , As soon as I entered the door, I saw an index board , It marks the functions of different floors , In this way, I can quickly locate the floor where I am looking for .

When I went upstairs, I saw that the bookshelves in each row subdivided the classification of books , In this way, I can quickly locate the specific bookshelf where I am looking for the book !
And each floor has a query terminal , Enter the title of the book to find the corresponding unique identification “ Cable number ”, Be similar to P159-49/164 Such a code , The books on the shelf are sorted according to this code ! With this code, go to the corresponding bookshelf , Soon we can find the specific location of the corresponding book on the shelf .

Less than ten minutes , I borrowed good books from the library .
Such a large library , Why can I find the book I want in such a short time ? If these books are in a disorderly pile , Or put it on the shelf without any signs , Can I find it so soon ?
This reminds me of the database that we use in our development , The books in the library are like the data in our data sheet , Floor index board 、 Shelf classification marks 、 The search number is similar to the index we use to find the data .
What kind of data structure is the underlying index of our common database ? Thinking of this, I went back to the library and borrowed a book 《 Database from entry to give up 》!
To understand the underlying principles of database indexing , We have to understand a data structure called a tree , The classic data structure in a tree is a binary tree ! So let's go from binary tree to balanced binary tree , Until then B- Trees , The last to B+ Tree step by step to understand the underlying principles of database index !
Binary tree (Binary Search Trees)
A binary tree is a tree structure in which each node has at most two subtrees . Usually a subtree is called “ The left subtree ”(left subtree) and “ Right subtree ”(right subtree). Binary tree is often used to implement binary search tree and binary heap . Binary trees have the following characteristics :
1、 Each node contains an element and n Subtree , here 0≤n≤2.
2、 The left and right subtrees are ordered , The order cannot be arbitrarily reversed . The value of the left subtree is smaller than the parent node , The value of the right subtree is greater than that of the parent node .
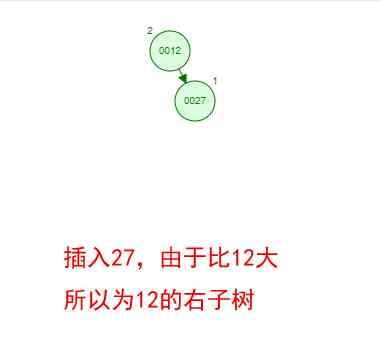
It's a little boring just to see the concept , Let's say we have such a set of numbers now [35 27 48 12 29 38 55], Sequential insertion into the structure of a number , Steps are as follows

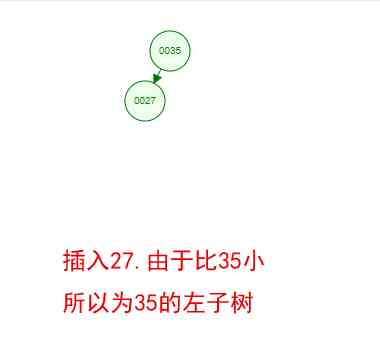
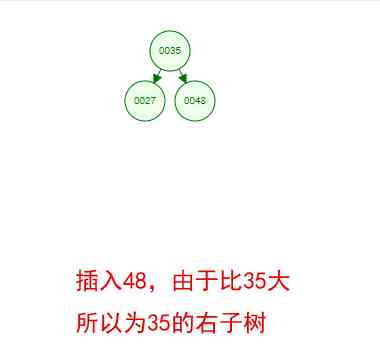
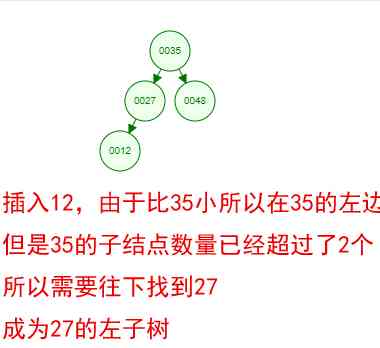
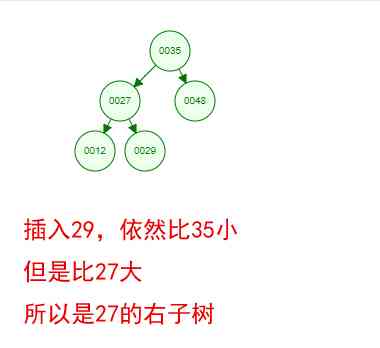
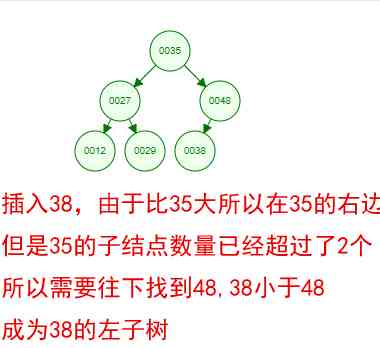
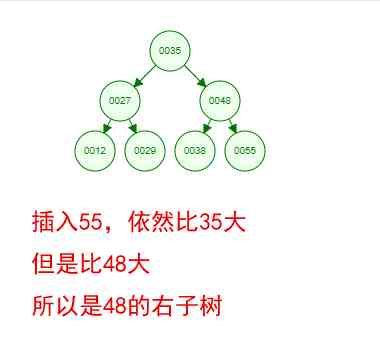
Okay , This is a binary tree ! We can see that , After a series of insertion operations , An unordered set of numbers has become an ordered structure , And this tree satisfies the characteristics of the two binary trees mentioned above !
But if it's the same set of numbers above , We'll arrange them in ascending order and then insert , That is to say, according to [12 27 29 35 38 48 55] The order of insertion , What will happen ?
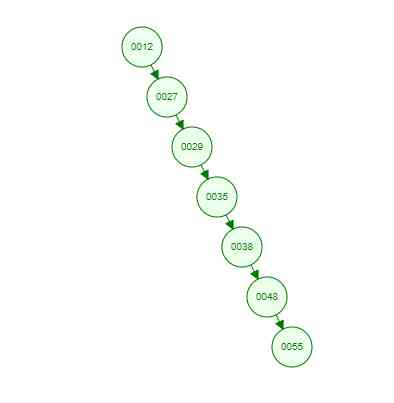
Because it's an ascending insert , The newly inserted data is always larger than the existing node data , So every time I insert... To the right of the node , It eventually led to a serious deviation of this tree !!! This is the worst case scenario , That is, a tree degenerates into a linear list , In this way, the search efficiency is naturally low , The advantage of trees has not been exerted at all !
In order to give full play to the search efficiency of binary tree , Let the binary tree no longer be partial to the family , Keep the balance of all subjects , So there's a balanced binary tree !
Balanced binary trees (AVL Trees)
Balanced binary tree is a special kind of binary tree , So he also satisfies the two characteristics of the binary tree , There is also a feature :
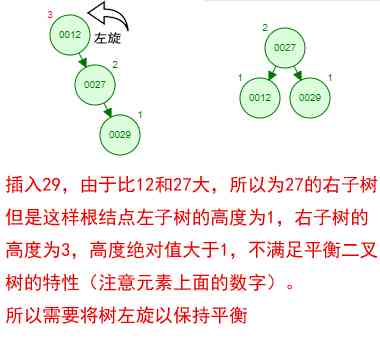
The absolute value of the height difference between its left and right subtrees shall not exceed 1, And both the left and right subtrees are a balanced binary tree .
We also saw the front [35 27 48 12 29 38 55] Insert the finished image , In fact, it is already a balanced two pronged tree .
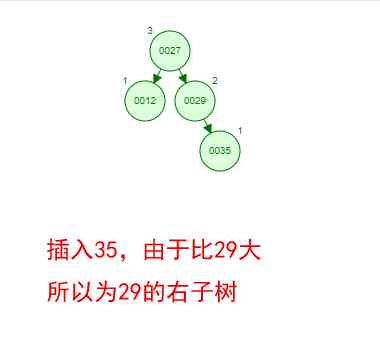
Then if you follow [12 27 29 35 38 48 55] Insert a balanced binary tree in order of , What will happen ? Let's look at the process of insertion and balance :

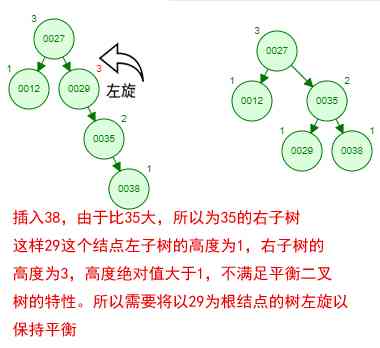

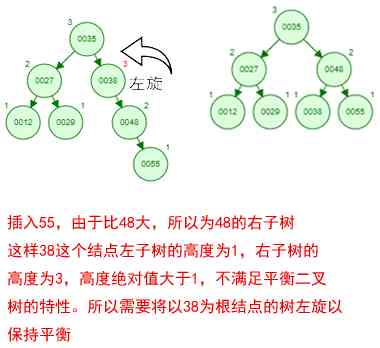
This tree always satisfies several characteristics of balanced binary tree to keep balance ! In this way, our tree will not degenerate into a linear list ! When we need to find a number, we can find it all the way down the tree root , This search efficiency is the same as dichotomy search !
How many nodes can a balanced binary tree hold ? It has something to do with the height of the tree , Suppose the height of the tree is h, The maximum number of nodes per layer is 2(n-1), The maximum number of nodes in the whole tree is 20+21+22+...+2^(h-1). Calculate like this ,100w The height of the data tree is about 20 about , That is to say, there is always 100w Find a data in the balanced binary tree of data , In the worst case, you need 20 Search times . If it's memory operation , It's also very efficient ! But the data in our database is basically on disk , Every node that reads a binary tree is a disk IO, So let's find a piece of data to go through 20 Secondary disk IO? Then performance becomes a big problem ! Then can we compress this tree for a while , So that each layer can accommodate more nodes ? Although I am short , But I'm fat ...
B-Tree
This stout tree is B-Tree, Note that in the middle is the bar of the bar essence, not the subtraction , So don't read B reduce Tree 了 ~
that B-Tree What are the characteristics ? A tree m Step B-Tree Has the following characteristics :
1、 Each node has a maximum of m Child nodes .
2、 Except for root and leaf nodes , Each node has at least m/2( Rounding up ) Child nodes .
3、 If the root node is not a leaf node , That node contains at least two children .
4、 All leaf nodes are on the same layer .
5、 Each node contains k Elements ( keyword ), here m/2≤k<m, here m/2 Rounding down .
6、 Elements in each node ( keyword ) From smallest to largest .
7、 Every element ( keyword ) The value of the left node of the word , Are less than or equal to the element ( keyword ). The value of the right node is greater than or equal to the element ( keyword ).
Does it feel like mother-in-law opens her mouth to ask you for the bride price , Make a list of conditions , And every one of them makes you feel confused ! Let 's take one [0,1,2,3,4,5,6,7] Insert an array of 3 Step B-Tree For example , String up all the conditions , You'll see !


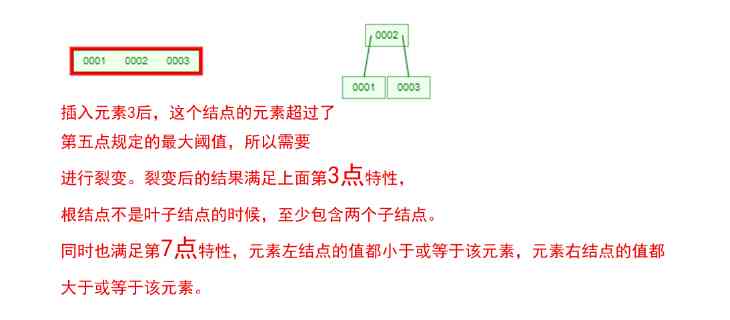
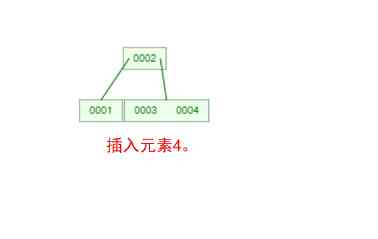
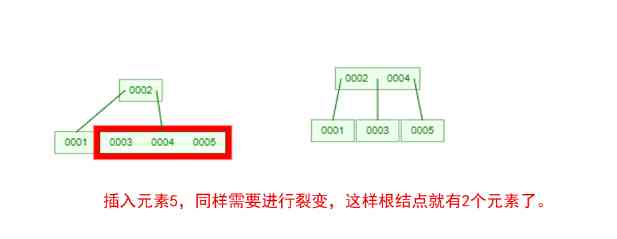
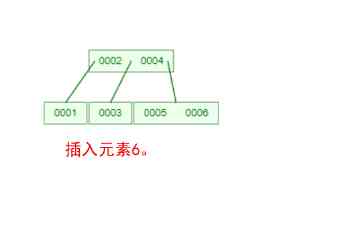
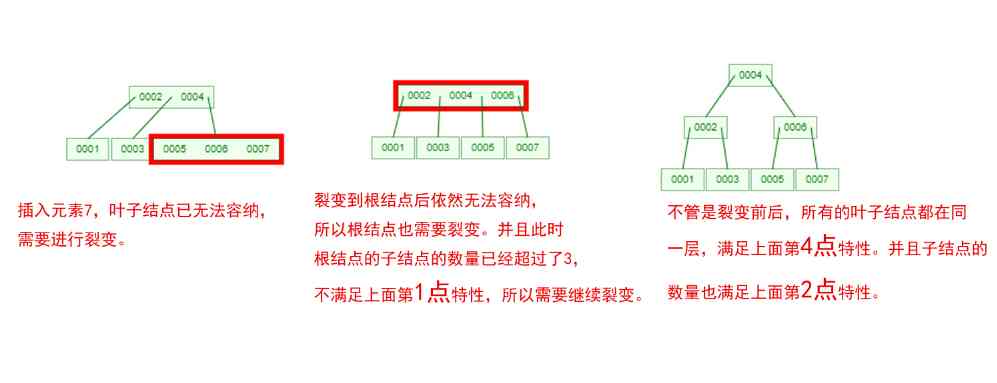
that , Are you right B-Tree A few of the characteristics are clear ? In a binary tree , Each node has only one element . But in B-Tree in , Each node can contain multiple elements , And the non leaf node has a pointer to the child node on the left and right of the element .
If you need to find an element , What about the process ? Let's look at the picture below , If we're going to be down here B-Tree Key words found in 24, The process is as follows
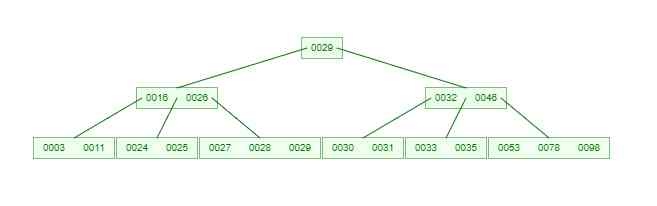
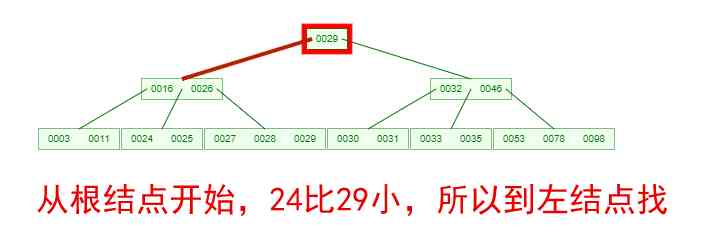
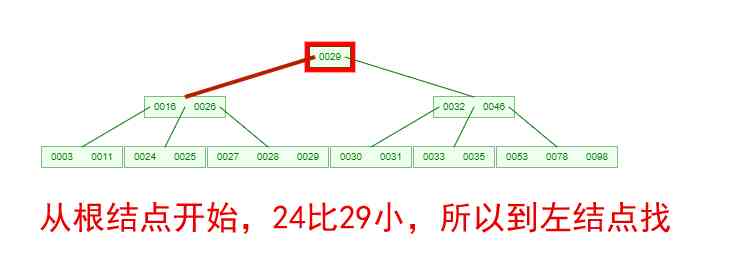
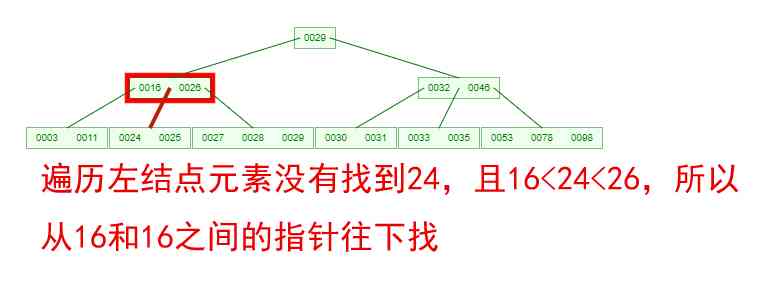
We can see from this process that ,B-Tree The query efficiency of is no higher than that of balanced binary tree . But the number of nodes the query passes through is much smaller , That means a lot less disks IO, This is right
The performance improvement is great .
Front facing B-Tree We can see the diagram of the operation , The elements are similar 1、2、3 Something like that , But the data in the database are all data in one piece , If a database uses B-Tree Data structure of storage data , How to store the data ? Let's look at the next picture
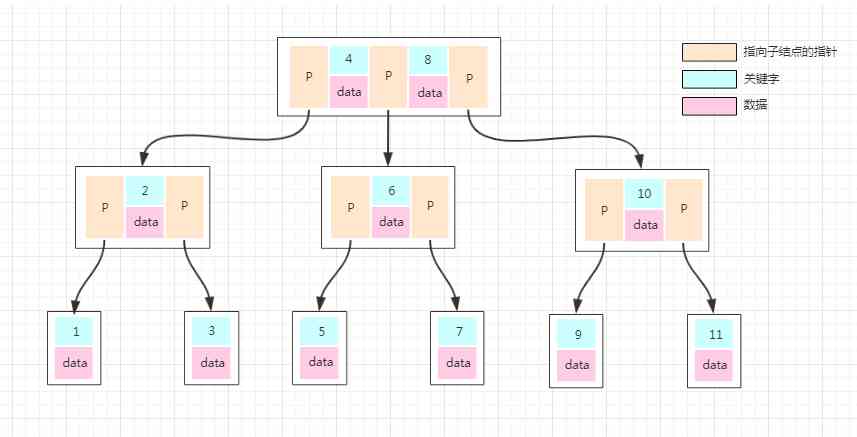
ordinary B-Tree In the node of , Elements are numbers . But in the picture above , We split the element into key-data In the form of ,key It's the primary key of the data ,data It's the specific data . So when we are looking for a number , Just look down the root node ok 了 , Efficiency is relatively high .
B+Tree
B+Tree Is in B-Tree An optimization based on , Make it more suitable to implement the external storage index structure .B+Tree And B-Tree The structure of is very similar to , But there are also a few of their own characteristics :
1、 All non leaf nodes only store keyword information .
2、 All satellite data ( Specific data ) All exist in leaf nodes .
3、 All leaf nodes contain the information of all elements .
4、 There is a chain pointer between all leaf nodes .
If above B-Tree The picture of becomes B+Tree, That should be as follows :

Let's compare it carefully with B-Tree What can be found in the picture of ?
1、 There are only key Information. , Satisfy the above 1 Point characteristics !
2、 There is one under all leaf nodes data Area , Satisfy the above 2 Point characteristics !
3、 The data of non leaf node can be found in leaf node , Elements like root nodes 4、8 It can also be found on the lowest leaf node , Satisfy the above 3 Point characteristics !
4、 Notice the arrow between the leaf nodes in the figure , Satisfied with the above 4 Point characteristics !
B-Tree or B+Tree?
Before we talk about the choice of these two data structures in the database , We also need to know that the operating system reads data from disk to memory in disk blocks (block) In basic units , Data in the same disk block will be read out at one time , It's not about taking what you need . Even if only one byte is needed , The disk will also start at this location , Sequential backward reading of a certain length of data into memory . The theoretical basis for this is the famous Locality principle : When a data is used , Data in the vicinity is often used immediately .
The length of pre reading is generally page (page) Integer multiple . Page is the logical block of computer management memory , Hardware and operating system often divide main memory and disk storage area into continuous blocks of equal size , Each storage block is called a page ( In many operating systems , The page size is usually 4k).
B-Tree and B+Tree How to choose ? What are the advantages and disadvantages ?
1、B-Tree Because non leaf nodes also store specific data , So when you find a keyword, you can return . and B+Tree All the data is in the leaf node , Every time I look up, I get the leaf node . So at the same height B-Tree and B+Tree in ,B-Tree Finding a keyword is more efficient .
2、 because B+Tree All the data is in the leaf node , And there are pointer connections between nodes , When looking for data larger than or smaller than a keyword ,B+Tree Just find the keyword and walk through the list , and B-Tree You also need to traverse the root node of the keyword node to search .
3、 because B-Tree Each node of ( The node here can be understood as a data page ) All store primary keys + Actual data , and B+Tree Non leaf nodes only store keyword information , And the size of each page is limited , So the same page can store B-Tree The data will be better than B+Tree Less storage . So the same amount of data ,B-Tree The depth will be greater , Increase the disk size of the query I/O frequency , And then affect the query efficiency .
In view of the above comparison , So in a common relational database , Is choice B+Tree Data structure to store data ! Now let's mysql Of innodb Storage engine as an example , Other similar sqlserver、oracle The principle is similar !
innodb Engine data storage
stay InnoDB In the storage engine , There is also the concept of page , The default size of each page is 16K, That is, every time data is read 4*4k Size ! Suppose we now have a user table , Let's write in the data
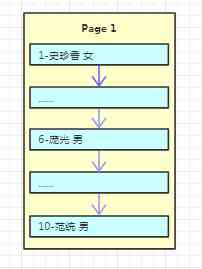
One thing to note here is that , When inserting a new row into a page , In order not to reduce the movement of data , It is usually inserted after the current row or the space left by the deleted row , So in Within a page And It's not completely orderly Of ( The structure of the following page is detailed ), But for the sake of data access order , There is a pointer to the next record in each record , This constitutes a one-way ordered list , But for the sake of demonstration, I arrange them in order !
Because the data is still relatively small , A page can hold , So there's only one root , The primary key and data are also stored in the root node ( The number on the left represents the primary key , Name on the right 、 Gender represents specific data ). Suppose we write 10 After strip data ,Page1 Full of , How will new data be stored when it is written again ? Let's continue to look at the picture below
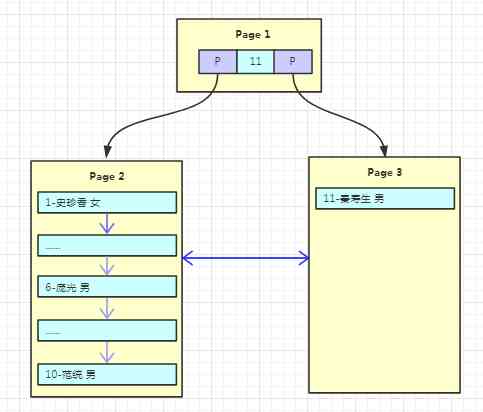
There's a man named “ Qin Shousheng ” A friend of , however Page1 There's no more data , This is where page splitting is needed , Produce a new Page. stay innodb What is the process in ?
1、 Generate new Page2, And then Page1 Copy the contents of to Page2.
2、 Generate new Page3,“ Qin Shousheng ” Data into Page3.
3、 The original Page1 Still as root , But it becomes a page that does not store data but only indexes , And there are two child nodes Page2、Page3.
There are two problems that need to be paid attention to here
1、 Why copy Page1 by Page2 Instead of creating a new page as the root , This reduces the cost of replication by one step ?
If the root node is recreated , The physical address stored in that node may often change , It's not good for finding . And in innodb The middle root node will be read into memory in advance Of , So it's better to fix the physical address of the node !
2、 original Page1 Yes 10 Data , Insert the 11 We split the data , According to the front face B-Tree、B+Tree Understanding of characteristics , Then this is at least one 11 Step tree , The element of each node after fission is at least 11/2=5 individual , Is that the primary key after page fission 1-5 The data is still on the original page , Primary key 6-11 The data will be put on a new page , The root node stores the primary key 6?
If so, the new page space utilization is only 50%, And it leads to more frequent page splits . therefore innodb This has been optimized , New data into the newly created page , Don't move any records of the original page .
With the continuous writing of data , The tree is also growing luxuriantly , Here's the picture
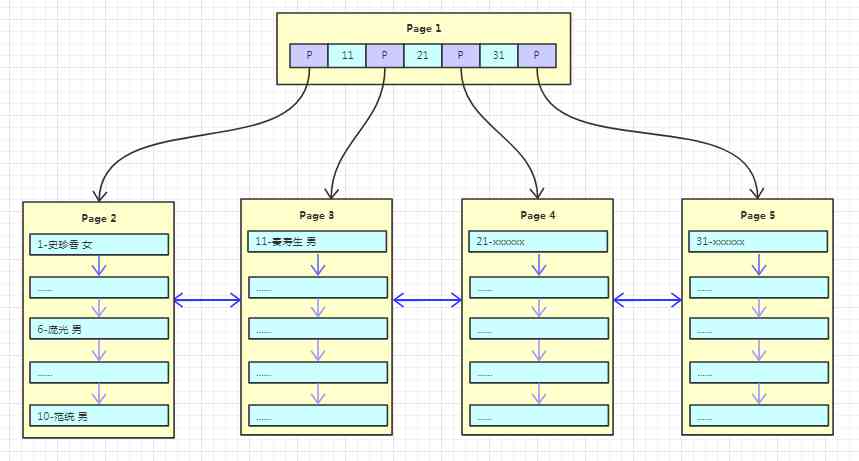
Every time you add data , It's all about filling up a page , Then create a new page continuation , There is an implicit condition here , That's it The primary key increases automatically ! The newly inserted data will not affect the original page when the primary key is added automatically , High insertion efficiency ! And the utilization rate of the page is high ! But if the primary key is unordered or random , That every insert may lead to frequent splitting of the original page , Affect insertion efficiency ! Reduce page utilization ! That's why innodb The reason why the primary key is increased automatically is recommended in !
All the non leaf nodes of this tree have primary keys , What if a table has no primary key ? stay innodb in , If a table has no primary key , By default, the column with unique index will be found , If not , Then an invisible field will be generated as the primary key !
If there is data insertion, there will be deletion , If this user table is frequently inserted and deleted , That can cause data pages to fragment , Page space utilization is low , It can also cause trees to change “ Artificially high ”, Reduce query efficiency ! This can be done by Index reconstruction To eliminate fragmentation and improve query efficiency !
innodb Engine data search
How to find the data inserted ?
1、 Find the page where the data is . This search process is just like what I mentioned earlier B+Tree The search process is the same , Search from root to leaf .
2、 Look for specific data on the page . Read the first 1 Step to find the leaf node data in memory , And then through Search in blocks How to find specific data .
This is the same as looking for a Chinese character in the Xinhua dictionary , First, the index of the dictionary is used to locate the page where the Pinyin of the Chinese character is located , Then go to the designated page to find the specific Chinese characters .innodb Which strategy is used to quickly find a primary key after locating the page in ? We need to start with page structure .
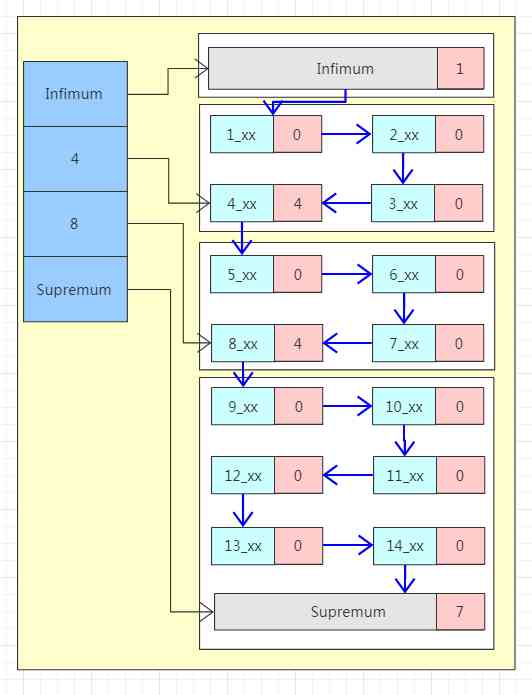
The blue area on the left is called Page Directory, This area is made up of slot form , It's a sparse index structure , That is, there may be more than one record in one slot , Belong to at least 4 Bar record , Belong to at most 8 Bar record . The data in the tank is stored in order , So when we look for a piece of data, we can first find a general position in the slot through dichotomy .
The right area is the data area , Each data page contains multiple rows of data . Pay attention to the top and bottom two special line records Infimum and Supremum, These are two virtual row records . When there is no other user data Infimum The pointer to the next record of points to Supremum, When there is user data ,Infimum The pointer to the next record of points to the smallest user record in the current page , The pointer to the next record of the largest user record in the current page points to Supremum, So far, all the row records in the whole page form a one-way linked list .
The line record is Page Directory Logic is divided into many blocks , There is order between blocks , in other words “4” The primary key of the largest row record in the data block pointed by this slot is higher than “8” The primary key of the smallest row record in the data block pointed by this slot is smaller . But the row records inside the block are not necessarily ordered .
There is one for each line n_owned Region ( The pink area in the picture ),n_owned Identify how many pieces of data this block has , A false record Infimum Of n_owned Value is always 1, Record Supremum Of n_owned The value range of is [1,8], Other user records n_owned Value range of [4,8], And only the largest record in each block n_owned It's worth it , Other users record n_owned by 0.
So when we're looking for a primary key for 6 When recording , Through the first Dichotomy stay Sparse index Find the corresponding slot in , That is to say Page Directory in “8” This slot ,“8” This slot points to the largest record in the data block , And the data is a one-way linked list structure, so it can't be reversed , So we need to find the last slot “4” This slot , And then through “4” The largest user record in this slot has a pointer along the linked list In order to find To the goal record .
Clustered index & Nonclustered indexes
All the previous data storage shows the implementation of clustered index , If the user table above needs to use “ User name ” Build a nonclustered index , How to achieve it ? Let's look at the picture below :
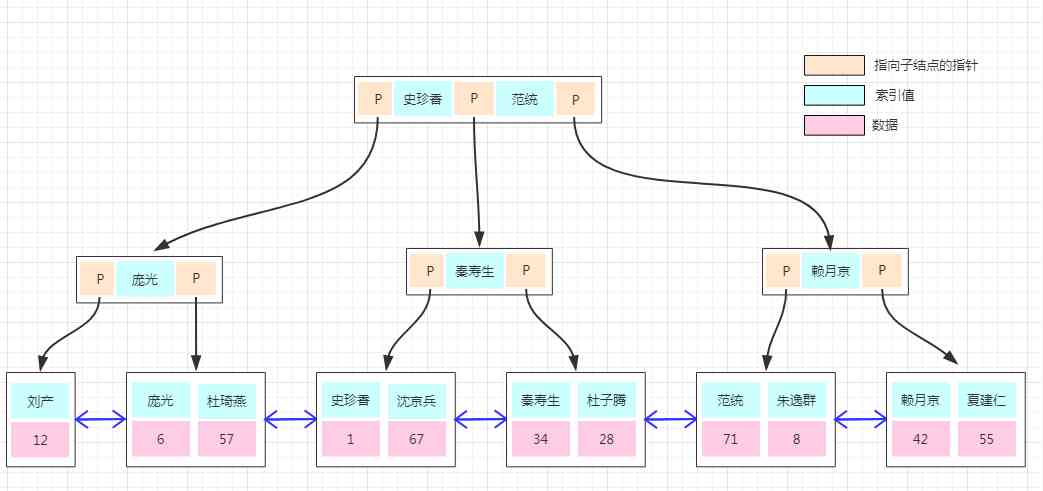
The storage structure of the nonclustered index is the same as before , The difference is that the data stored in the leaf node is no longer specific data , And the clustering index of data key. So the process of searching through a nonclustered index is to find the index first key Of the corresponding clustered index key, And then take the clustered index key Find the corresponding data on the primary key index tree , This process is called Back to the table !
The names in the picture are all from the Internet , I hope you are not hurt by mistake ~_
innodb And MyISAM Comparison of two storage engines
It includes storage and search innodb Engine as an example , that MyISAM And innodb What's the difference in storage ? Hold back your words , Look at the picture :

The picture above shows MyISAM Storage structure of primary key index , The difference we can see is
1、 The data area of the leaf node of the primary key index tree does not store the actual data , It's the address of the data record .
2、 Data is not stored in primary key order , Store... In the order in which it was written .
in other words innodb Engine data is physically stored in primary key order , and MyISAM Engine data is physically stored in the order of insertion . also MyISAM The leaf node of does not store data , So the storage structure of nonclustered index is similar to that of clustered index , When using the nonclustered index to find data, you can directly find the data address through the nonclustered index tree , Unwanted Back to the table , This is more than innodb The search efficiency will be higher !
Index optimization suggestions ?
You will often see some suggestions for using index in many articles or books , for instance
1、like Fuzzy query to % start , Can cause indexes to fail .
2、 The index of a table should not exceed 5 individual .
3、 Try to use overlay index .
4、 Try not to index columns with too much data .
5、...........
6、...........
Many of them are not listed here ! After reading this article , Can we analyze with doubt why we have these suggestions ? Why? like Fuzzy query to % start , Can cause indexes to fail ? Why don't a table build more indexes than 5 individual ? Why? ? Why? ?? Why? ??? Believe to see here you add some of their own thinking should have the answer ?
Last , It's a good way to recommend geek time mysql Course , After learning to understand mysql The underlying principles help a lot !