当前位置:网站首页>ES 数据聚合、数据同步、集群
ES 数据聚合、数据同步、集群
2022-08-04 21:49:00 【从零开始的JAVA世界】
文章目录
1.数据聚合
聚合(aggregations)可以让我们极其方便的实现对数据的统计、分析、运算。例如:
- 什么品牌的手机最受欢迎?
- 这些手机的平均价格、最高价格、最低价格?
- 这些手机每月的销售情况如何?
实现这些统计功能的比数据库的sql要方便的多,而且查询速度非常快,可以实现近实时搜索效果。
1.1.聚合的种类
聚合常见的有三类:
- 桶(Bucket)聚合:用来对文档做分组
- TermAggregation:按照文档字段值分组,例如按照品牌值分组、按照国家分组
- Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
- 度量(Metric)聚合:用以计算一些值,比如:最大值、最小值、平均值等
- Avg:求平均值
- Max:求最大值
- Min:求最小值
- Stats:同时求max、min、avg、sum等
- 管道(pipeline)聚合:其它聚合的结果为基础做聚合
注意:参加聚合的字段必须是keyword、日期、数值、布尔类型 ,不做分词操作的字段。
1.2.DSL实现聚合
现在,我们要统计所有数据中的酒店品牌有几种,其实就是按照品牌对数据分组。此时可以根据酒店品牌的名称做聚合,也就是Bucket聚合。
1.2.1.Bucket聚合语法
语法如下:
GET /hotel/_search
{
"aggs": {
// 定义聚合
"brandAgg": {
//给聚合起个名字
"terms": {
// 聚合的类型,按照品牌值聚合,所以选择term
"field": "brand", // 参与聚合的字段
"size": 20 // 显示的聚合结果数量
}
}
}
}
1.2.2.聚合结果排序
默认情况下,Bucket聚合会统计Bucket内的文档数量,记为_count,并且按照_count降序排序。
我们可以指定order属性,自定义聚合的排序方式:
GET /hotel/_search
{
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"order": {
"_count": "asc" // 按照_count升序排列
},
"size": 20
}
}
}
}
1.2.3.限定聚合范围
默认情况下,Bucket聚合是对索引库的所有文档做聚合,但真实场景下,用户会输入搜索条件,因此聚合必须是对搜索结果聚合。那么聚合必须添加限定条件。
我们可以限定要聚合的文档范围,只要添加query条件即可:
GET /hotel/_search
{
"query": {
"range": {
"price": {
"lte": 200 // 只对200元以下的文档聚合
}
}
},
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 20
}
}
}
}
1.2.4.Metric聚合语法
桶内聚合,使用聚合函数
语法如下:
GET /hotel/_search
{
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 20
},
"aggs": {
// 是brands聚合的子聚合,也就是分组后对每组分别计算
"score_stats": {
// 聚合名称
"stats": {
// 聚合类型,这里stats可以计算min、max、avg等
"field": "score" // 聚合字段,这里是score
}
}
}
}
}
}
1.2.5.小结
aggs代表聚合,与query同级,此时query的作用是?
- 限定聚合的的文档范围
聚合必须的三要素:
- 聚合名称
- 聚合类型
- 聚合字段
聚合可配置属性有:
- size:指定聚合结果数量
- order:指定聚合结果排序方式
- field:指定聚合字段
1.3.RestAPI实现聚合
@Test
public void testAggs() throws IOException {
//创建搜索请求对象
SearchRequest searchRequest = new SearchRequest("hotel");
//查询条件
searchRequest.source().query(QueryBuilders.matchAllQuery());
//聚合条件
searchRequest.source().aggregation(AggregationBuilders.terms("品牌聚合").field("brand").size(10));
//发送搜索请求
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//处理结果
//获取品牌聚合结果
Aggregation aggregation = response.getAggregations().get("品牌聚合");
//类型强转,获取更多功能
Terms terms = (Terms) aggregation;
//获取桶
List<? extends Terms.Bucket> buckets = terms.getBuckets();
//循环桶,获取每个分组结果
for (Terms.Bucket bucket : buckets) {
String key = bucket.getKeyAsString();
long count = bucket.getDocCount();
System.out.println("品牌名:" + key + ",数量为" + count);
}
}
@Test
public void testAggs() throws IOException {
//创建搜索请求对象
SearchRequest searchRequest = new SearchRequest("hotel");
//查询条件
searchRequest.source().query(QueryBuilders.matchAllQuery());
//聚合条件
searchRequest.source().aggregation(AggregationBuilders.terms("品牌聚合").field("brand").size(10). //按照品牌字段进行聚合,显示10条
subAggregation(AggregationBuilders.stats("stats").field("price"))); //子聚合 ,按照价格做聚合函数 min max avg count sum
//发送查询请求
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//处理结果
//获取品牌聚合结果
Aggregation aggregation = response.getAggregations().get("品牌聚合");
//类型强转,获取更多功能
Terms terms = (Terms) aggregation;
//获取桶
List<? extends Terms.Bucket> buckets = terms.getBuckets();
//循环桶,获取每个分组结果
for (Terms.Bucket bucket : buckets) {
String key = bucket.getKeyAsString();
long count = bucket.getDocCount();
System.out.println("品牌名:" + key + ",数量为" + count);
//子聚合结果
Stats stats = bucket.getAggregations().get("stats");
System.out.println("价格平均值:" + stats.getAvgAsString());
System.out.println("价格总和:" + stats.getSumAsString());
System.out.println("价格最大值:" + stats.getMaxAsString());
System.out.println("价格最小值:" + stats.getMinAsString());
}
}
2.数据同步
elasticsearch中的酒店数据来自于mysql数据库,因此mysql数据发生改变时,elasticsearch也必须跟着改变,这个就是elasticsearch与mysql之间的数据同步。
2.1.思路分析
常见的数据同步方案有三种:
- 同步调用
- 异步通知
- 监听binlog
2.1.1.同步调用
方案一:同步调用

基本步骤如下:
- hotel-demo对外提供接口,用来修改elasticsearch中的数据
- 酒店管理服务在完成数据库操作后,直接调用hotel-demo提供的接口,
2.1.2.异步通知
方案二:异步通知
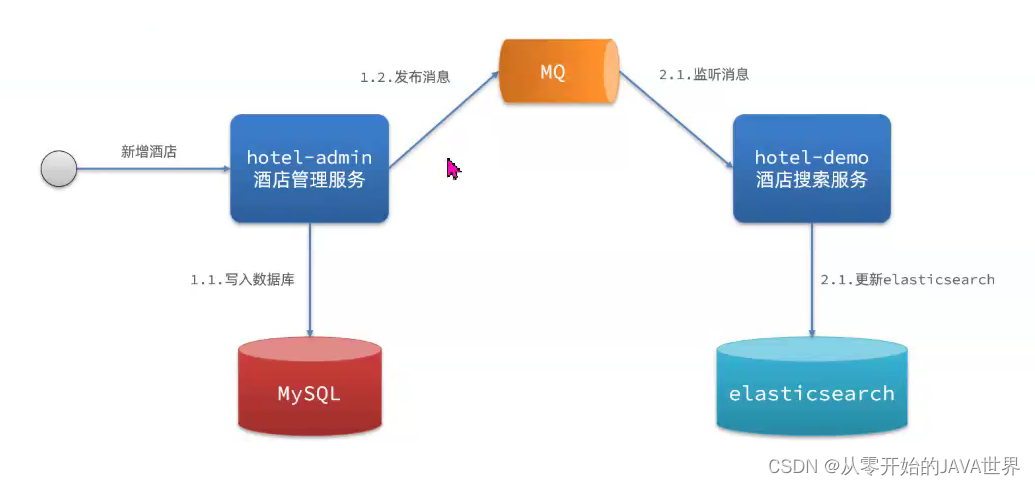
流程如下:
- hotel-admin对mysql数据库数据完成增、删、改后,发送MQ消息
- hotel-demo监听MQ,接收到消息后完成elasticsearch数据修改
2.1.3.监听binlog
方案三:监听binlog
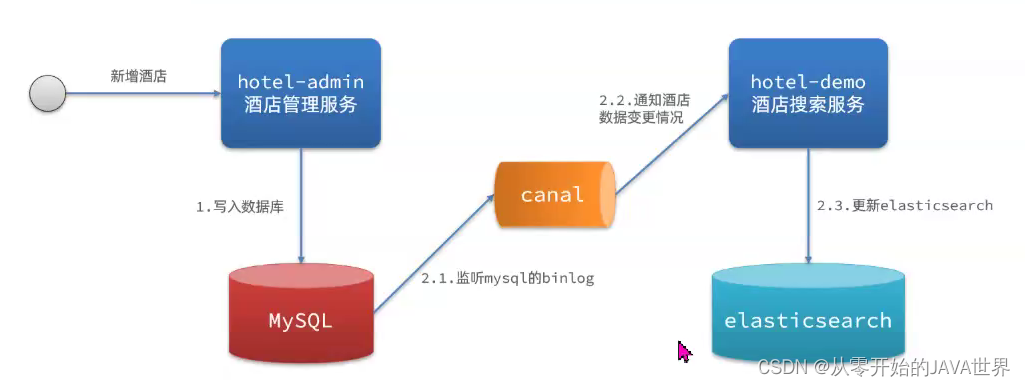
流程如下:
- 给mysql开启binlog功能
- mysql完成增、删、改操作都会记录在binlog中
- hotel-demo基于canal监听binlog变化,实时更新elasticsearch中的内容
2.1.4.选择
方式一:同步调用
- 优点:实现简单,粗暴
- 缺点:业务耦合度高
方式二:异步通知
- 优点:低耦合,实现难度一般
- 缺点:依赖MQ的可靠性
方式三:监听binlog
- 优点:完全解除服务间耦合
- 缺点:开启binlog增加数据库负担、实现复杂度高
3.集群
单机的elasticsearch做数据存储,必然面临两个问题:海量数据存储问题、单点故障问题。
- 海量数据存储问题:将索引库从逻辑上拆分为N个分片(shard),存储到多个节点
- 单点故障问题:将分片数据在不同节点备份(replica )
ES集群相关概念:
集群(cluster):一组拥有共同的 cluster name 的 节点。
节点(node) :集群中的一个 Elasticearch 实例
分片(shard):索引可以被拆分为不同的部分进行存储,称为分片。在集群环境下,一个索引的不同分片可以拆分到不同的节点中
解决问题:数据量太大,单点存储量有限的问题。
主分片(Primary shard):相对于副本分片的定义。
副本分片(Replica shard)每个主分片可以有一个或者多个副本,数据和主分片一样。
数据备份可以保证高可用,但是每个分片备份一份,所需要的节点数量就会翻一倍,成本实在是太高了!
为了在高可用和成本间寻求平衡,我们可以这样做:
- 首先对数据分片,存储到不同节点
- 然后对每个分片进行备份,放到对方节点,完成互相备份
这样可以大大减少所需要的服务节点数量,如图,我们以3分片,每个分片备份一份为例:

现在,每个分片都有1个备份,存储在3个节点:
- node0:保存了分片0和1
- node1:保存了分片0和2
- node2:保存了分片1和2
3.1.集群脑裂问题
3.1.1.集群职责划分
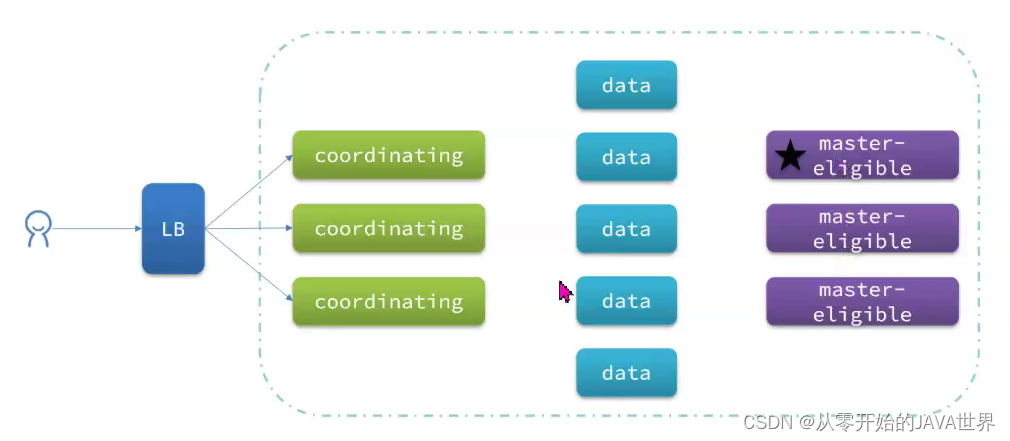
elasticsearch中集群节点有不同的职责划分:

默认情况下,集群中的任何一个节点都同时具备上述四种角色。
但是真实的集群一定要将集群职责分离:
- master节点:对CPU要求高,但是内存要求低
- data节点:对CPU和内存要求都高
- coordinating节点:对网络带宽、CPU要求高
职责分离可以让我们根据不同节点的需求分配不同的硬件去部署。而且避免业务之间的互相干扰。
一个典型的es集群职责划分如图:
3.1.2.脑裂问题
脑裂是因为集群中的节点失联导致的。
例如一个集群中,主节点与其它节点失联:

此时,node2和node3认为node1宕机,就会重新选主:
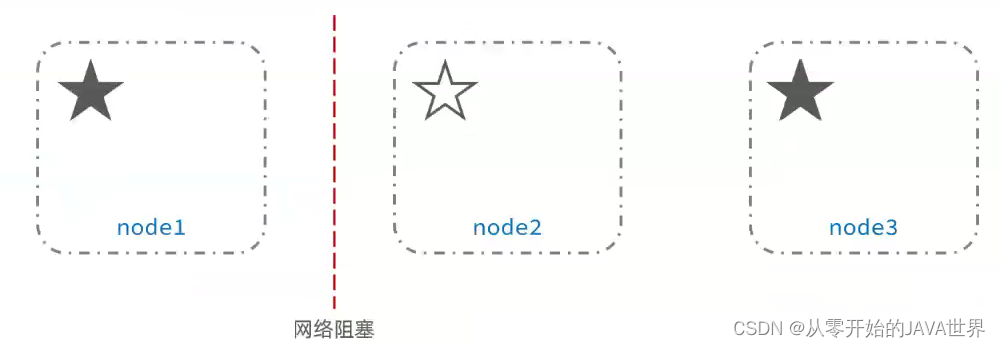
当node3当选后,集群继续对外提供服务,node2和node3自成集群,node1自成集群,两个集群数据不同步,出现数据差异。
当网络恢复后,因为集群中有两个master节点,集群状态的不一致,出现脑裂的情况:

解决脑裂的方案是,要求选票超过 ( eligible节点数量 + 1 )/ 2 才能当选为主,因此eligible节点数量最好是奇数。对应配置项是discovery.zen.minimum_master_nodes,在es7.0以后,已经成为默认配置,因此一般不会发生脑裂问题
例如:3个节点形成的集群,选票必须超过 (3 + 1) / 2 ,也就是2票。node3得到node2和node3的选票,当选为主。node1只有自己1票,没有当选。集群中依然只有1个主节点,没有出现脑裂。
3.1.3.小结
master eligible节点的作用是什么?
- 参与集群选主
- 主节点可以管理集群状态、管理分片信息、处理创建和删除索引库的请求
data节点的作用是什么?
- 数据的CRUD
coordinator节点的作用是什么?
- 路由请求到其它节点
- 合并查询到的结果,返回给用户
3.2.集群分布式存储
当新增文档时,应该保存到不同分片,保证数据均衡,那么coordinating node如何确定数据该存储到哪个分片呢?
3.2.1.分片存储原理
elasticsearch会通过hash算法来计算文档应该存储到哪个分片:

说明:
- _routing默认是文档的id
- 算法与分片数量有关,因此索引库一旦创建,分片数量不能修改!
新增文档的流程如下:
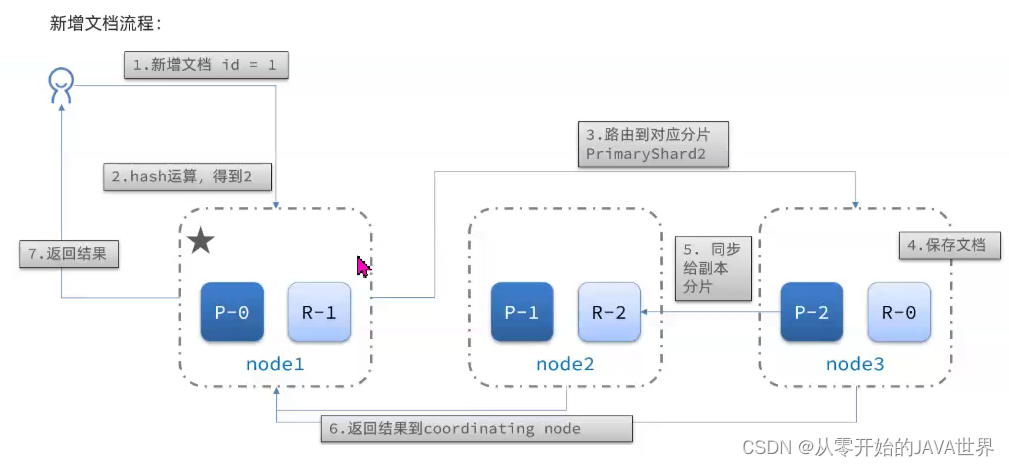
解读:
- 1)新增一个id=1的文档
- 2)对id做hash运算,假如得到的是2,则应该存储到shard-2
- 3)shard-2的主分片在node3节点,将数据路由到node3
- 4)保存文档
- 5)同步给shard-2的副本replica-2,在node2节点
- 6)返回结果给coordinating-node节点
3.3.集群分布式查询
elasticsearch的查询分成两个阶段:
- scatter phase:分散阶段,coordinating node会把请求分发到每一个分片
- gather phase:聚集阶段,coordinating node汇总data node的搜索结果,并处理为最终结果集返回给用户
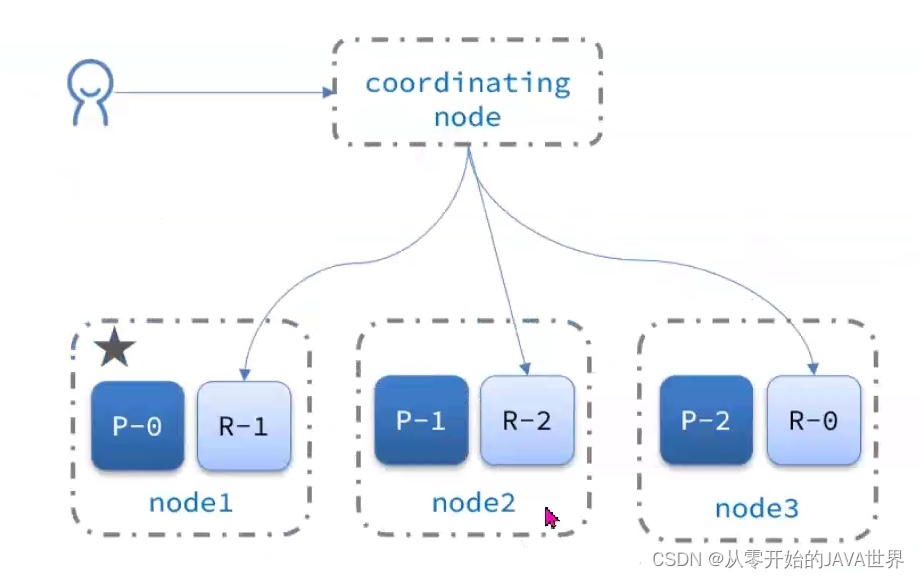
3.4.集群故障转移
集群的master节点会监控集群中的节点状态,如果发现有节点宕机,会立即将宕机节点的分片数据迁移到其它节点,确保数据安全,这个叫做故障转移。
1)例如一个集群结构如图:
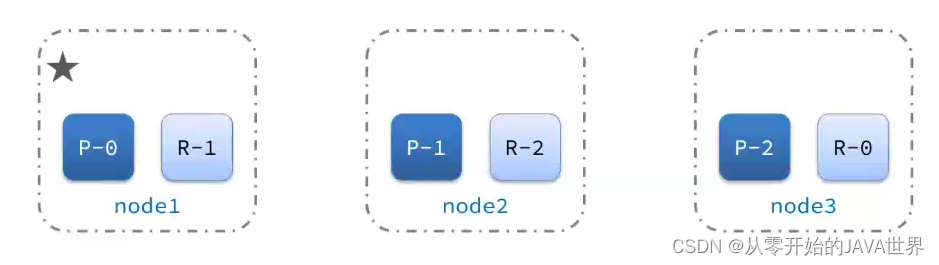
现在,node1是主节点,其它两个节点是从节点。
2)突然,node1发生了故障:
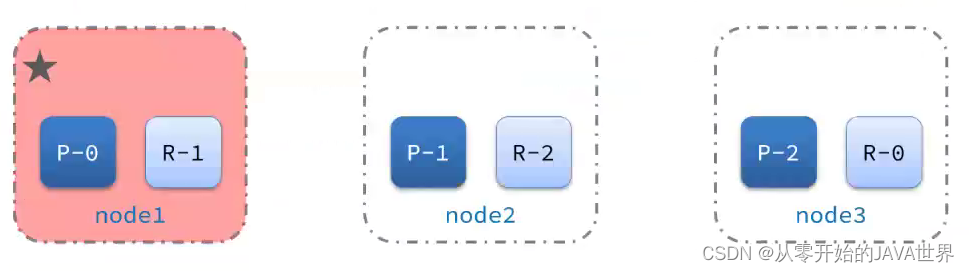
宕机后的第一件事,需要重新选主,例如选中了node2:

node2成为主节点后,会检测集群监控状态,发现:shard-1、shard-0没有副本节点。因此需要将node1上的数据迁移到node2、node3:

边栏推荐
- milvus配置相关
- Why is MySQL query slow?
- rk3399-0.0 svc命令
- ROS播包可视化
- Pinduoduo open platform order information query interface [pdd.order.basic.list.get order basic information list query interface (according to transaction time)] code docking tutorial
- 【Social Marketing】WhatsApp Business API: Everything You Need to Know
- 大势所趋之下的nft拍卖,未来艺术品的新赋能
- Altium Designer 19.1.18 - 画多边形铜皮挖空时,针对光标胡乱捕获的解决方法
- AtCoder Beginner Contest 262 D - I Hate Non-integer Number
- 【分布式】分布式ID生成策略
猜你喜欢
Android 面试——如何写一个又好又快的日志库?
【QT】回调函数的实现
The upgrade and transformation plan of the fortress machine for medium and large commercial banks!Must see!
LayaBox---TypeScript---Problems encountered at first contact

硬件开发定制全流程解析
unity2D横版游戏教程9-对话框dialog
Analysis and treatment of Ramnit infectious virus
JdbcTemplate概述和测试
七夕,当爱神丘比特遇上牛郎和织女

MySQL查询为啥慢了?
随机推荐
LayaBox---TypeScript---structure
【线性代数03】消元法展示以及AX=b的4种解情况
ini怎么使用? C#教程
LeetCode: 406. 根据身高重建队列
关于std::vector<std::string>的操作
强网杯2022——WEB
[QT] Implementation of callback function
The upgrade and transformation plan of the fortress machine for medium and large commercial banks!Must see!
LayaBox---knowledge point
数电快速入门(一)(BCD码和三种基本逻辑运算的介绍)
【线性代数02】AX=b的2种解释和矩阵乘法的5种视角
UDP communication
Hardware factors such as CPU, memory, and graphics card also affect the performance of your deep learning model
数字重塑客观世界,全空间GIS发展正当其时
docker 部署redis集群
数电快速入门(四)(组合逻辑电路的分析以及设计的介绍)
dotnet compress Stream or file using lz4net
Flutter 实现背景图片毛玻璃效果
rk3399-0.0 svc命令
MySQL查询为啥慢了?