当前位置:网站首页>超标量处理器设计 姚永斌 第9章 指令执行 摘录
超标量处理器设计 姚永斌 第9章 指令执行 摘录
2022-07-07 09:51:00 【岐岇】
9.1 概述
执行阶段负责指令的执行,在流水线的之前阶段做了那么多的事情,就是为了将指令送到这个阶段进行执行。在执行阶段,接受指令的源操作数,对其进行规定的操作,例如加减法、访问存储器、判断条件等,然后这个执行的结果会大于处理器的状态进行更新,例如写到物理寄存器堆,写到存储器中,或者从特定的地址取指令等,同时这个执行结果可以作为其他指令的源操作数(这就是旁路)。
一般RISC指令集都包括下面的操作类型:
(1)算术运算,例如加减法、乘除法、逻辑运算和移位运算等;
(2)访问存储器;
(3)控制程序流的操作,包括分支、跳转、子程序调用、子程序返回等类型;
(4)特殊指令,用来实现一些特殊功能的指令,例如对于支持软件处理TLB缺失的架构,访问协处理器,存储器隔离等。
不同类型的指令有着不同的复杂度,因此在FU中的执行时间也是不同的,这称为不同的latency,并且在现代的处理器当中,为了获得更大的并行度,一般都会同时使用几个FU进行并行的运算。
每个FU都有不同的延迟时间,FU的个数决定了每周期最大并行执行的指令个数,也就是前文所说的issue width。
FU在运算完成后,并不会使用它的结果马上对处理器的状态进行更新(Architecture state),例如它不会马上将结果写到逻辑寄存器中,而是将结果写到临时的地方,例如写到物理寄存器中,这些状态称为推测状态(speculative state),等到一条指令顺利离开流水线的时候,它才会真正地对处理器的状态进行更新。
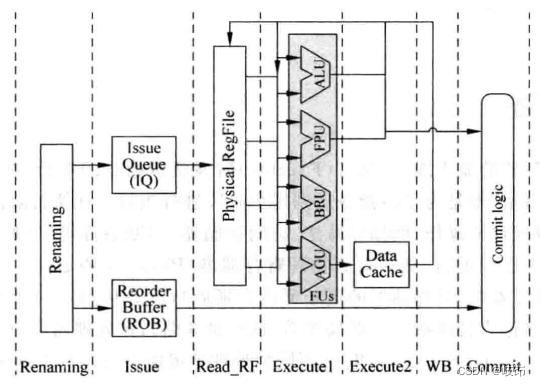
其中,FPU用来对浮点数进行运算;ALU用来对整数进行算术和逻辑运算;AGU(Address Genneration Unit)用来计算访问存储器的地址,当使用虚拟存储器时,AGU计算的地址是虚拟地址,还需要将其转换为物理地址;BRU(Branch Unit)用来对控制程序流的指令计算目标地址。
执行阶段另一个重要部分就是旁路网络bypassing network,它复杂将FU的运算结果马上送到需要它的地方,例如物理寄存器堆,所有FU的输入端,Store Buffer中等。在现代超标量处理器中,如果想要背靠背地执行相邻的相关指令,旁路网络是必须的,但是随着每周期可以并行执行的指令个数的增多,旁路网络变得越来越复杂,已经成为处理器中中制约速度提升的一个关键部分了。
假设先不考虑旁路网络,那么指令的操作数可以来自于物理寄存器堆(对应非数据捕捉结构),或者来自于payload RAM(对应数据捕捉结构),那么此处仍需要考虑一个问题:每个FU和物理寄存器堆或payload RAM的各个读端口应该怎样对应起来?
其实,这是通过之前讲过的仲裁电路关联起来的,每个FU都和一个1-of-M的仲裁电路是一一对应的,每个仲裁电路如果选择了一条指令,这条指令就会读取物理寄存器堆或者payload,从而得到相应的操作数,然后就可以将这条指令送到相应的FU中执行了。
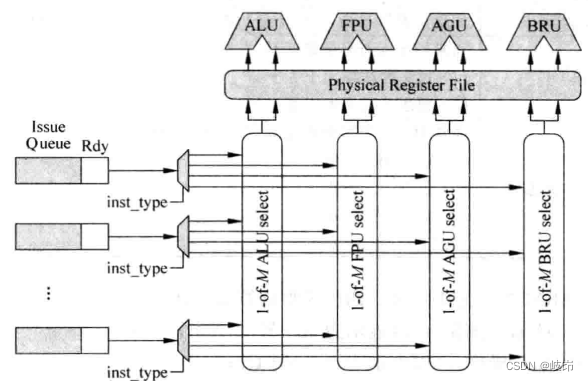
图中每个FU都有一个1-of-M的仲裁电路,这个仲裁电路对应着物理寄存器堆栈固定的读端口。物理寄存器堆栈总共需要的读端口的个数和issue width是直接相关的,如果对处理器追求更大的并行度,就需要更大的issue width,也就意味着物理寄存器堆栈需要更多的读端口,这又会制约处理器速度的提高,因此现代的处理器为了解决这个矛盾,多采用cluster结构。
9.2 FU的类型
9.2.1 ALU
它负责对整数类型的数据进行计算,得到整数类型的结果,它一般被称作ALU。整数的加减,逻辑,移位运算,甚至是简单的乘除法,数据传输指令,例如mov指令和数据交换类型的指令,分支指令的目标地址计算,访问存储器的地址计算等,都会在这个FU中完成,具体的运算类型取决于处理器微架构的设计。
在ALU中加入乘除法操作后,会使ALU的执行时间是一个变化的值,例如执行简单的加减法指令需要一个周期,而执行乘除法需要32个周期,这样会给旁路的功能带来一定的麻烦。
一个典型的ALU可能是:
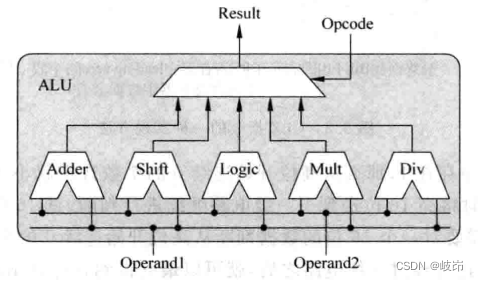
ALU中所有计算单元都会收到同一条指令的操作数,因此它们都会进行计算,最后需要根据这条指令的类型来选择合适的结果,由于一条指令只需要一个计算单元计算,但是实际上所有的计算单元都进行了运算,这样会浪费一部分功耗,可以在每个计算单元之前都加入寄存器来锁定指令的操作数,根据指令的类型来选择性更新这些操作数寄存器,可以节省一定功耗。
为了追求比较简单的并行度,高性能的处理器都会选择将乘法器单独使用一个FU来实现,并且在这个FU中支持乘累加的功能,这样可以快速执行指令集中乘累加类型的指令。有时候处理器出于功耗和成本的考虑,会将整数类型的乘法功能在浮点运算的FU中完成。这样肯定会导致乘法指令需要的执行周期数变大,但是考虑到这种做法会节省面积,而且很多应用并不会使用太多的乘除法,所以也能接受。
9.2.2 AGU
AGU用来计算地址,访问存储器类型的指令(load/store)通常会在指令中携带它们想使用的存储器地址,AGU负责对这些指令进行处理,计算出指令中所携带的地址。其实在普通流水线的处理器中,都是在ALU中计算这个地址,但是在超标量处理器中,由于需要并行地执行指令,而且访问存储器类型指令的执行效率直接影响了处理器的性能,所以单独使用一个FU来计算它的地址。AGU的计算过程取决于指令集。
如果处理器支持虚拟寻址,那么经过AGU运算得到的地址就是虚拟地址,还需要经过TLB等部件转换为物理地址,只有物理地址才可以直接访问存储器(在一般的处理器中,L2 Cache以及更下层的存储器都是使用物理地址进行寻址的),因此在支持虚拟存储器的处理器中,AGU只是完成了地址转换的一小部分,它只是冰山下的一角,真正的重头戏是从虚拟地址转换为物理地址,以及从物理地址得到数据的过程。
9.2.3 BRU
BRU负责处理程序控制流control flow类型的指令,如分支指令branch,跳转指令jump,子程序调用和子程序返回等指令。这个FU负责将这些指令所携带的目的地址计算出来,并根据一定条件来决定是否使用这些定制,同时在这个FU中还会对分支预测正确与否进行检查,一旦发现分支预测失败了,就需要启动相应的恢复机制。对于RISC处理器的PC寄存器来说,它的来源有三种:
(1)顺序执行时,next_PC = PC + N, N等于每次取指令的字长;
(2)直接类型的跳转,next_PC = PC + offset, offset是指令所携带的立即数,它指定了相对于当前分支指令的的PC值的偏移量,由于这个立即数不会随着程序的执行而改变,因此这种类型的指令的目标地址也是比较容易预测的。
(3)间接指令,指令中直接指定一个通用寄存器的值作为PC值,next_PC=GPR[Rs],这种类型的指令也被称为绝对类型跳转。由于随着程序的执行,通用寄存器的值会变化,所以这种类型指令的目标地址不容易被预测,如果可以直接使用直接类型的跳转指令实现同样的功能,就尽量不要使用这种间接式类型的跳转指令。
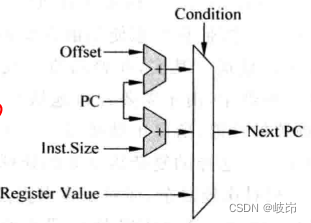
BRU运算单元的实现原理图,这个FU其主要完成了两部分工作,即计算分支指令的目标地址,并判断分支条件是否成立。
一般来说,分支指令可以分为两种,一种是有条件的,一种是无条件的。
ARM和PowerPC等处理器则使用了不同的方法,在每条指令的编码中都加入了条件码,根据条件码的值来决定指令是否执行。因为每条指令都有这个条件码,所以每条指令其实都可以无条件执行,而不仅限于分支类型的指令,这样相当于把程序中的控制相关性用数据相关性替代了。
对于每条指令都是用条件执行的好处是可以降低分支指令使用的频率,而在超标量处理器中,只要使用分支指令,就有可能存在预测错误的风险,因此从这个角度看,这种条件执行的实现方式可以获得更好的性能,但是它也是一把双刃剑,因为条件码占据了指令解码的一部分,导致指令中实际可以分配给通用寄存器的部分变少了。
当需要条件执行的指令很多时,流水线会存在大量无效的指令,这样反而使效率降低了,从这些角度来看,对每条指令都使用条件执行时降低了性能。
在超标量处理器中使用条件执行,会给寄存器重命名的过程带来额外的麻烦。由于寄存器重命名阶段无法得到需要的条件值,因此无法有选择地对寄存器进行重命名,导致了问题发生。
超标量处理器如果实现条件执行,要解决寄存器重命名的问题,最简单的方法就是停止流水线。等等到这条指令的条件被计算出来,才对它后面的指令进行重命名,虽然不会发生错误,但是效率的确不高。当然,也可以采用预测的方法来解决这个问题,而预测错误时,需要对处理器的状态进行恢复,将其和之后的指令从流水线抹掉,并将这些指令对RAT的更改进行恢复,然后重新将这些指令取到流水线中。
条件执行的指令需要根据条件寄存器的值来决定是否执行,例如ARM处理器中的每个条件执行的指令都需要读取条件寄存器CPSR。
对于每一条要修改CPSR寄存器的指令来说,CPSR寄存器都相当于这条指令的一个目的寄存器。在超标量处理器中,也需要到CPSR寄存器重命名,后续的条件执行指令都会将CPSR寄存器作为一个源寄存器来看待。不过,由于CPSR寄存器的宽度小于普通的通用寄存器,所以一般会为CPSR寄存器的重命名过程单独使用一个物理寄存器堆。这就相当于在普通指令的增加了一个目的寄存器和一个源寄存器,使寄存器重命名的复杂度有所上升,导致了功耗增大。
无条件的分支指令总是将调整地址写到PC中,用来进行子程序调用的CALL指令和子程序返回的Return指令。
对于实现了分支预测功能的超标量处理器来说,BRU功能单元还有一个更为重要的功能,那就是负责对分支预测是否正确进行检查。在流水线取指令阶段或解码阶段会将所有预测跳转的分支指令按照程序中指定的顺序保存到一个缓存中,这个缓存可以成为分支缓存branch stack,在分支缓存中存储了所有预测跳转的分支指令。
检查分支预测的正确性,会有四种结果:
(1)一条分支指令在BRU功能单元中得到的结果是发生跳转,并且在分支缓存中找到了这条分支指令,跳转地址也相同,证明分支预测正确。
(2)一条分支指令在BRU功能单元中得到的结果是发生跳转,并且在分支缓存中没有找到了这条分支指令,跳转地址也相同,证明分支预测失败。
(3)一条分支指令在BRU功能单元中得到的结果是不发生跳转,并且在分支缓存中没有找到了这条分支指令,跳转地址也相同,证明分支预测正确。
(4)一条分支指令在BRU功能单元中得到的结果是不发生跳转,并且在分支缓存中找到了这条分支指令,跳转地址也相同,证明分支预测失败。
如果发现分支指令预测失败,那么就需要启动处理器的状态恢复流程。如果发现分支预测正确,并且这条分支指令之前所有的分支指令都已经正确执行,那么只需要释放这条分支指令所占据的资源就哭了。
还需要考虑的一个问题是分支指令需要乱序执行吗?
在流水线中可以同时存在多条分支指令,这些分支指令都会被进行分支预测,然后统一放到BRU功能单元对应的额发射队列中,由于分支指令有如下两个主要的源操作数。
(1)条件寄存器,分支指令根据条件寄存器的值来决定是否进行跳转,条件寄存器的值在分支指令进入到发射队列时可能还没有被计算出来。
(2)源操作数,对于直接跳转的分支指令,目标地址的计算来自于PC+offset,其中offset一般以立即数的形式存在于指令当中。
进入到发射队列的所有分支指令,有可能出现的情况是后进入到流水线的分支指令的所有源操作数都已经准备好 ,可以进入BRU功能单元进行计算,而先进入的分支指令可能还未准备好。从这个方面来说,对分支指令采用乱序执行是可以提高一些性能,但是后进入到流水线的分支指令严重依赖前面的分支指令的结果,若前面的分支指令发现自己分支预测失败了,后续这些分支指令在BRU中被执行的过程就是做了无用功,浪费了功耗。
综合看起来,如果将性能放在第一位,那么可以使用乱序的方式来执行分支指令,而如果要顾及功耗,那么顺序执行分支指令是一个明智的选择。
9.2.4 其他FU
例如处理器如果支持浮点运算,那么就需要浮点运算的FU;很多处理器还支持多媒体扩展指令,则也需要相应的FU来处理。
9.3 旁路网络
由于超标量处理器中的指令时乱序执行的,而且存在分支预测,所以这条指令的结果未必正确,此时称这个结果时推测状态,一条指令只有在顺利地离开流水线的时候,才会被允许将它的结果对处理器进行更新,此时这条指令的状态就变为了正确状态(Architecture state),此时可能距离这个结果被计算出来已经很久了,后续的指令不可能等到这条顺利地离开流水线的时候才是用它的结果。
一条指令只有到了流水线的执行阶段才真正需要操作数了,到了执行阶段的末尾就可以得到它的结果,因此只需要从FU的输出端到输入端架起一个通路,就可以将FU的结果送到所有FU的输入端。当然,在处理器内部的很多地方可能也需要这个结果,例如物理寄存器堆、payload RAM等,因此需要将FU的结果也送到这些地方,这些通路是由连线和多路选择器组成的,通常被称为旁路网络,它是超标量处理器能够在如此深的流水线情况下,可以背靠背执行相邻的相关指令的关键技术。
为了降低处理器的周期时间的影响,源操作数从物理寄存器堆读取出来后,还需要经过一个周期时间,才能够到达FU的输入端,这个周期在流水线中称为Source Derive阶段。同理,FU将一条指令的结果计算出来之后,还需要经过复杂的旁路网络才能到达所有FU的输入端,因此将这个阶段页单独做成流水线。

现在可以知道,要使两条存在写后读相关性的指令背靠背的执行,必须有两个条件,指令被仲裁电路选中的那个周期进行唤醒,还有就是旁路网络。
一个周期内进行仲裁和唤醒操作会严重地制约处理器的周期时间,而现在又引入旁路网络,需要将FU的结果送到每个可能需要的地方,在真实的处理器中,旁路网络需要大量的布线和多路选择器,已经成为现代处理器当中一个关键的部分,它影响了处理器的面积、功耗、关键路径和物理上的布局。
在IBM的Power处理器中,两条相邻的相关指令在执行的时候,它们之间存在气泡bubble,但是这些气泡可以使用其他不相干的指令来代替,因为它们都是乱序执行的处理器,只要能够找到不相干的指令,就能够缓解这种设计对性能的负面影响。
9.3.1 简单设计的旁路网络
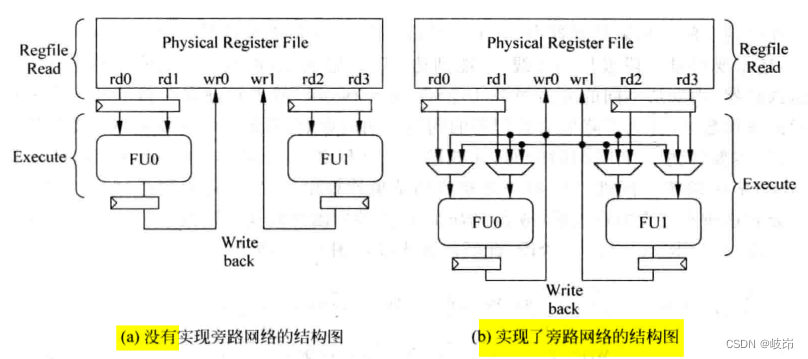
在不实现旁路网络中,FU的操作数直接来自于物理寄存器堆,FU的结果也直接送到物理寄存器堆中,一个FU要想使用另一个FU的计算结果只能通过物理寄存器获得。
在实现旁路网络中,每个FU的操作数可以有三个来源,即物理寄存器,自身FU的结果,其他FU的结果。同时,每个FU的输出处理送到物理寄存器堆之外,还需要通过一个总线送到所有FU输入端的多路选择器中。
很多FU都有多个功能,也就是有多个计算单元。对这一的FU需要使用一个多路选择器,从不同的计算单元中选择出合适的结果输送到旁路网络上,这样的设计成为bypass sharing。但是,当一个FU,不同的计算单元需要的周期数不同时,例如乘法操作需要32个周期,逻辑运算需要1个周期,此时如果采用正常的执行,就可以出现同一个FU中两个计算单元的结果在同一个周期内被计算出来,都想通过这个FU对应的旁路网络进行传送,这样就产生了冲突。

对于旁路网络使用的冲突而言,最简单的方法就是先假设不会存在冲突。
假设一个仲裁电路对应的FU可以计算三种类型的指令,在这个FU中就有三个计算单元,它们的latency分别是1,2和3,则:
(1)当本周期执行latency=3时指令,在下个周期不允许执行latency=2,在下下个周期不允许执行latency=1的指令;
(2)当本周期执行latency=2时指令,在下下周期不允许执行latency=1的指令;
(3)当本周期执行latency=1时指令,没有限制;
为了达到这个功能,对每一个仲裁电路都设置一个位宽为两位的控制寄存器,高位用来拦截所有latency=2的指令,低位用来拦截所有latency=1的指令,这两个二位控制寄存器每周期都会逻辑右移移位。相应的,在发射队列中每个表项中都增加两个型号,分别用来指示它其中的指令的latency是1还是2。
9.3.2 复杂设计的旁路网络
在比较复杂的流水线中,数据从物理寄存器中被读取出来之后,需要经过一个周期Source Drive阶段才可以到达FU的输入端,而FU输出的结果也需要经过一个周期Result Derive才能够到达需要的地方,这些变化导致了旁路网络也需要相应的变化。
在复杂的流水线中加入旁路网络,使得设计的复杂度增大,对处理器的周期时间造成一定的负面影响。
在流水线的执行阶段,其操作数除了来自于上一级流水线,还可以来自于两个FU计算的结果,它们来自于流水线的Result Derive阶段;而在流水线Source Drive阶段,其操作数除了来自于上一级流水线,还可以来自于以前指令的结果,从之前的流水线示意图可以看出,这些结果分布在流水线的Result Drive阶段和Write back结果。要实现这样的旁路网络,需要复杂的布线资源和多路选择器的配合才可以完成。
在复杂流水线使用旁路网络的过程,一条指令从FU中将结果计算出来,需要经过流水线的两个阶段Result Derive和Write Back,才可以写到通用寄存器中,在这两个周期内,这条指令的结果都可以输出到旁路网络上;而一条指令读完通用寄存器后,直到真正到FU中执行之前的两个阶段Source Drive和Execute,都可以接收旁路网络送出来的值。
当一条指令处于流水线的Data Read阶段,需要读取物理寄存器时,而产生它的操作数的指令此时正处于流水线的Write back阶段,此种情况下不需要使用旁路网络,因为这条指令可以直接从物理寄存器中读到所需要的操作数(假设物理寄存器时前半个周期写,后半个周期读)。

当两条指令之间相隔的指令超过两条时,就不在需要通过旁路网格获得操作数了,而是可以直接通过寄存器获得操作数,对于两条相关性指令而言:
(1)当两条相关的指令处于相邻周期,这个旁路网络只能发生在流水线的Execute和Result Derive两个阶段之间。
(2)当两条相关指令之间相差一个周期时,一条指令使用它前面的前面那个周期的指令的结果,因此旁路网络可能发生在流水线的Source Derive和Result Derive两个阶段之间,也可以发生在Execute和Write back之间。
(3)当两条相关指令之间间隔了两个周期时,一条指令使用它前面的前面的前面的指令的结果,因此这旁路网格只可能发生在Source Derive和Write Back之间。
流水线增加了两级,导致此时旁路网络的复杂度已经很高,处理需要数量比较多的多路选择器之外,还需要更多的更长的总线用来传输需要旁路的值。
现代处理器都追求很快的速度,很高的并行度,也就是需要更多的FU,因此不可能在任意的FU之间都设置旁路的路径,这样会需要大量的布线资源,造成严重的连线延迟。
实际上,并不需要在所有的FU之间都设置旁路网络。例如,AGU进行地址计算的时候,一般都会使用ALU的计算结果,反之,ALU不会使用AGU的计算结果,因此在ALU和AGU之间的旁路网络是单向的。
同时load/store单元,只有load指令的结果才会被其他指令所使用,store指令则不会有这种需求。
浮点单元一般都有自己专用的旁路网络,整数指令不会直接使用浮点运算结果,因此浮点FU到整数FU的旁路网络也并不需要。随着流水线级数的增大,旁路网络无法继续跟随下去,这也是无法任意妄为地增加流水线级数的一个原因。
9.4 操作数的选择
在FU的输入端,需要从物理接存起的输出或者所有的旁路网络中进行选择,找到FU的真正需要的源操作数,这个任务是由多路选择器来完成的,既然有那么多的源头可供选择,就需要对应的信号来控制这个多路选择器,那么这个控制信号来自于何处?
所有的物理寄存器的这些信息可以保存在一个表格中,这个表格就是ScoreBoard,在这个表格中,记录了一个物理寄存器在它的生命周期内经过的地方。

在ScoreBoard中,对每个寄存器来说,记录了两个内容:
(1)FU#:这个寄存器会从哪个FU中被计算出来,当需要从旁路网络中取得物理寄存器的值时,需要知道他来自于哪个FU,这样可以控制多路选择器来选择对应的值,当一条指令被仲裁电路选中的时候,如果这条指令存在目的寄存器,就将这条指令在哪个FU中执行的信息写到上面的表格中。
(2)R:表示这个物理寄存器的值已经从FU中计算出来,并且被写到了物理寄存器堆中,后续的指令如果要是用这个物理寄存器,就可以直接从PRF中读取,由于只需要表示这个寄存器是否在PRF中,使用一位的信号就可以了,0表示这个物理寄存器不再PRF中,需要从旁路网络中取得这个值,1表示可以从PRF中读取这个值。
某指令在流水线的Select阶段,会将它在那个FU中执行的信息写到SocreBoard表格的状态为FU#中,在流水线的Write Back阶段,会将计算的结果写到物理寄存器堆中,同时会对ScoreBoard也进行更新,会读取这个表格,就可以得到指令在那个FU中执行的信息了,也就可以从对应的旁路网络中选择合适的值。
由于读取ScoreBoard的过程发生在流水线的Execute阶段,这会对处理器的周期时间造成一定的负面影响,当处理器的频率要求比较高时,这种做法可能就无法满足要求。
每个FU在将一条指令的计算结果进行广播的同时,也将这条指令的目的寄存器编号一并跟随进行广播。
在FU输入端的多路选择器旁边增加了很多比较器,相应地也会增大一些面积和功耗,但是这样设计结构简单,不需要任何控制逻辑,在一定程度上也能减少设计的复杂度,进而减少面积和功耗。
随着可以生产生旁路数据的流水段的增多,这些多路选择器的输入源也会随之增阿基,这样就在每个多路选择器旁边产生了大量的比较逻辑,这也是深流水线带来的负面影响。
现代的处理器提高频率的一大利器就是依靠工艺尺寸的缩小,同时处理器性能的提高主要依靠一些架构方面的预测算法。
9.5 cluster
当前的超标量设计方法导致硬件越来越复杂,例如需要更多端口的物理寄存器和存储器、更多的旁路网络等,这些多端口的部件会导致处理器的面积和功耗增加,严重地制约处理器频率的提高。因此产生了一种设计理念-Cluster
之前在发射队列中,通过将一个统一的发射队列分开为多个独立的发射队列,能够减少仲裁电路等部件的设计复杂度,并加快速度。在FU的设计中,将浮点FU和整数FU的旁路网络分开,可以大大减少旁路网络的复杂度等。
Cluster结构将上面这种理念进行扩展,应用到处理器内部的物理寄存器堆,发射队列,旁路网络等各种部件。
9.5.1 Cluster IQ
随着每周期可以并行执行的指令个数的增多,对于采用集中式的发射队列来说,要求更多的读写端口和更大的容量,导致面积和延迟都会增大,再加上发射队列本来就处于处理器内部的关键路径上,所以采用集中式发射队列很难满足现代处理器对性能的要求。通过将它分为多个晓得分布式发射队列,每个发射队列对应一个或少数几个仲裁电路和FU,这样每个分布式的发射队列只需要存储对应的FU中能够执行的指令,使复杂度得以降低,这种Cluster IQ优点在于:
(1)可以减少每个分布式发射队列的端口个数;
(2)每个分布式发射队列的仲裁电路只需要从少量的指令中进行选择,因此可以加快每个冲裁电路的速度。
(3)由于分布式发射队列的容量比较小,它其中被唤醒的速度也会比较快。
、缺点则是:一个分布式发射队列中,被仲裁电路选中的指令对其他发射队列中队列进行唤醒时,由于需要经过更长的主线,所以这部分的延迟会增大。跨越不同的Cluster之间进行唤醒的这个过程需要增加一级流水线,这样当两条存在相关性的相邻指令恰巧属于不同的Cluster时,它们就不能背靠背地执行了,而是在流水线中引入了一个bubble。
对每个采用cluster结构的发射队列使用一个物理寄存器堆。这相当于将物理寄存器堆复制了一份,对于每个cluster内部的指令来说,都可以直接从物理寄存器堆中读取操作数,每个FU都在自己所属的cluster内使用旁路网络,减少了旁路网络的复杂度。当然,这样的设计要求两个物理寄存器堆的内容要保持一致,要求每个FU在更新自己的Cluster的寄存器的堆栈时,还需要更新另一个cluster内的寄存器,因此中的看来,这样的设计可以将寄存器堆的读端口个数减少一半,但是寄存器堆的写端口个数并没有减少。
通过减少寄存器堆的端口个数,避免了一个过于臃肿的寄存器堆成为处理器中的关键路径。
物理寄存器cluster设计的缺点是很明显的,为了减少复杂度,旁路网络不能跨越cluster,当两个存在相关性的连续的指令属于两个不同的cluster时,后续的指令要等到前面的指令更新完寄存器堆之后,才能够从寄存器堆中读取操作数。
9.5.2 Cluster bypass
要提高处理器的性能,需要每周期可以并行执行更多的指令,也就需要更多的FU来支持,这会导致旁路网络的复杂度也随之显著增加。
对旁路网络使用cluster结构,将两个FU分布在两个Cluster中,每个FU不能将它的结果送到其他的FU中,只能送到自身的旁路网络中,也就是说,旁路网络只能分布在每个cluster内部。
当旁路网络复杂度降低,流水线中的Source Drive和Result Drive两个流水段都可以去掉了,这就相当于节省了两级流水线,加快了跨越不同的cluster之间的相关指令执行的速度。如果相关指令属于不同的cluster,则只能通过寄存器堆传递操作数,当流水线没有了Source Drive和Result Drive阶段后,两条属于不同的相关指令之间只需间隔一个周期就可以了。硬件很容易找到一条不相干的指令插入这个周期来执行,这样简化旁路网络的同时,并没有造成性能的明显下降。
同时处理器其主频的提高又要求周期时间越来越小,可能导致寄存器不能像之前那样,在前半个周期写入,在后半个周期读取,这样就导致相邻的相关性指令需要间隔的周期数有所增加。
在顺序执行的处理器中,一般都不会对旁路网络采用激进cluster结构,而是尽量会采用完全的旁路网络,以降低相邻的相关性指令所引入的流水线气泡。
目前讲述的Cluster IQ的设计方法中,如果两条相邻的相关指令属于两个不同的发射队列,则跨越发射队列间的唤醒过程会引入一个周期的延迟,而两条相关指令属于两个不同的cluster FU,则跨越FU之间的旁路网络也需要一个周期的延迟,那么综合来看,是不是两个延迟会进行叠加呢?答案是可以的!
9.6 存储器指令的加速
9.6.1 memory disambiguation
在讲述寄存器之间的相关性时,即RAW,WAW,WAR,都是可以在流水线解码阶段发现并解决的。而对于存储器类型指令来说,访问存储器的地址是在执行过程动态地计算出来的,只有经过流水线的执行阶段,才可以得到访问存储器的真正地址,例如:
ST R0 #15[R1]
LD R3 #10[R2]
在流水线的解码阶段是不可能知道这两条访问存储器的指令不存在RAW相关性,只有过了流水线的执行阶段,当这条指令的地址都被计算出来之后,才可以知道。
对于访问存储器的指令来说,是没有办法对这些地址也进行重命名来消除WAW和WAR这两种相关性。
对于访问存储器的指令来说,这三种相关性WAW,WAR, RAW都是需要考虑的,虽然从理论上地说,访问存储器的指令之间也是可以乱序执行,但是一旦发现这三种相关性有任何一种发生了违例。就需要处理。这在一定程度上增加了设计难度,也为了保持存储器的正确性,大部分处理器中的store指令都是顺序执行的,这样可以避免WAW相关性,load指令可以有不同的实现方式,主要分为三种:
(1)完全的顺序执行,这是最保守的一种方法了;
(2)部分乱序执行,顺序执行的store指令将程序划分了不同的块,每当一条store指令的地址被计算出来之后,这条store指令和后面的store指令之间所有的load指令可以乱序执行,这种方式避免WAR相关性的发生,同时也可以降低对RAW相关性的检测难度。
(3)完全乱序执行,load指令不再受到store指令的限制,只要load指令准备好了,就可以送到FU中执行。WAR和RAW这两种相关性都是需要在流水线中处理。
1. 完全的顺序执行
由于load指令一般处于相关性的顶端,这种方法不能使load指令尽可能地提前执行,导致所有相关指令的执行都比较晚,使用这种方法的处理器,性能自然就比较低了,尤其在超标量处理器中,基本上不会采用这样的保守的设计方法。
2. 部分的乱序执行
虽然store指令是in-order执行,但是出于两条store指令之间的所有load指令却可以乱序执行,当一条store指令被仲裁电路选中之后,位于它后面的所有load指令就有资格参与仲裁的过程。
这个方法的本质就是当一条store指令所携带的地址被计算出来之后,在它之后进入到流水线的所有load指令就可以具备条件去判断RAW的相关性,每条load指令将它携带的地址计算出来之后,需要和前面store指令的携带地址进行比较。为了实现这个功能,就需要一个缓存来保存那些已经被冲裁电路选择,但是还没有顺利地离开流水线的store指令,可以将这个缓存称为store buffer。
即使laod指令和store指令携带的地址相等,它们之间也没有RAW相关性,load指令所需要的数据不应该来自于store指令,所以这需要一种机制。当load指令和store buffer的store指令进行比较地址时,需要知道哪些store指令在自己前面,哪些store指令在自己后面,对于RAW而言,只需要关注哪些在自己前面的store指令即可,因此需要对这些load/store指令前后顺序进行标记,标记的来源有如下几种:
(a)PC值,但是当store指令之后有一个向前跳转指令时,通过PC值就无法分辨真实的先后顺序了。
(b)ROB的编号,在ROB中记录着所有指令进入流水线的先后顺序,因此指令在ROB的地址可以用来表示他们之间的先后顺序。但是ROB中存储的所有指令,其中只有一部分是load/store指令,如果使用这个标号,必然是很稀疏的,而这些标号要与大小比较,这样造成比较器使用比较大的位宽,浪费了面积和功耗。
(c)在流水线的解码阶段,为每一条load/store指令分配一个编号,这个编号的宽度需要根据流水线中最多支持的load/store指令的个数来决定的。
不管怎么说,这样部分地将load指令进行乱序执行的方法虽然可以提高一些性能,但是在很多时候仍然不能够以最大的限度挖掘程序之间存在并行性。
3.完全的乱序执行
store指令仍然是in-order,但是load指令将不再受限于它前面的store指令,只要laod操作数准备好了,就可以向仲裁电路根据一定的原则,例如oldest-first原则,选择一条合适load指令送到FU中执行。在这种方法中,可以使load/store指令共用一个发射队列,采用每周期只选择一条load/store指令的设计,也可以采用每周期同时选择一条laod和一条store指令的设计。
还可以使load/store指令使用独立的发射队列,也就是说,load指令单独使用发射队列,store指令也单独使用一个发射队列,这样store指令可以简答地使用FIFO结构,不必使用年龄比较类型的仲裁电路。
对于RISC处理器来说,有数量丰富的通用寄存器,所以程序中很多变量可以直接放到寄存器中,这样在实际的程序当中,store/load指令之间存在RAW相关性的情况并不是很多,而且,通过提前执行load指令,可以尽快地唤醒更多的相关指令。
反观CISC处理器,因为可用的寄存器很少,所以经常需要与存储器打交道,许多操作数都需要放到存储器中,这样store/load之间存在RAW相关性就很多了。
9.6.2 非阻塞Cache
I-Cache由于只需要读取,而且取指令要求串行的顺序,所以对他的处理是特殊的,不能简答地采用非阻塞的方式。故本小节只介绍D-Cache。
在存储器中,只有访问存储器的指令,例如load/store指令,才可以访问D-Cache。
(1)对于laod指令来说,如果需要的数据不在D-Cache中,就发生了缺失,需要从下一级的物理存储器中取得数据,并在D-Cache中按照某种算法,找到一个Cache line进行写入,如果被写入的Cache line是dirty,还需要将这个line的data block先写回到物理内存中。
(2)对于store指令来说,如果它携带的地址不在D-Cache中,那么对于write back+write allocate类型的Cache来说,需要首先从物理内存中找到这个地址对应的datablock,将其读取出来,和store指令所携带的数据进行合并,并从D-Cache中按照某种算法,找到一个Cache line,将合并之后的数据写到这个Cache line中;如果被替换的这个Cache line已经被标记为dirty,那么在被写入之前,还需要先将这个被覆盖的line中data block写回到物理内存中,这样才能放心地将合并之后的数据写到这个Cache line中。
不管是load还是store指令,当发生D-Cache miss时,D-Cache和物理内存都是需要交换数据,这个过程一般需要多个周期才能完成。如果在这个周期之内,又发生了D-Cache miss,该如何处理?
最简单的方法就是在D-Cache发生缺失并且被解决之前,使D-Cache与物理内存之间的数据通路被锁定,只处理当前这个缺失的数据,处理器不能够再执行其他load/store指令。这样的阻塞大大减少了程序执行时可以寻找的并行性。使处理器的性能无法提高。
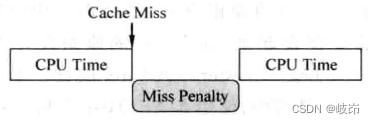
产生D-Cache miss的laod/store指令阻塞了后面的load/store指令的执行,所以这种设计方法为阻塞 Cache,在发生阻塞的这段时间,处理器只能暂停执行,无法做其他有用的事情。
如果在发生D-Cache缺失的时候,处理器可以继续执行后面的load/store指令,这种设计方法就称为非阻塞Cache,有时候也称为lookup-free Cache,非阻塞Cache允许处理器在发生D-Cache miss时候继续执行新的load/store指令。
其实非阻塞Cache并不是乱序执行的超标量处理器的专属品,在顺序执行的处理器中也有这种方法。
面对store指令来说,当发生misss时,需要将存储的数据和这个数据块进行合并,然后将合并之后的数据写到D-Cache中。
药支持非阻塞的操作方式,在处理器中需要将那些已经产生D-Cache miss 的load/store指令保存起来。利用Miss Status Holding Register部件,该部件由两部分组成:
(a)首次缺失:对于一个给定的地址来说,访问D-Cache时第一次产生的缺失称为首次缺失;
(b)再次缺失:在发生首次缺失并且没有被解决完毕之前,后续的访问存储器的指令再次访问这个缺失的Cache line,这时就称为再次缺失,这里需要注意两点,一是再次缺失并不仅仅是指单独的一次缺失,在这个Cache line被取回到D-Cache之前,后续访问这个Cache line的所有load/store指令都会再次缺失;二是再次缺失使用的地址未必和首次缺失使用的地址是一样的,只要它们属于同一个Cache line即可。
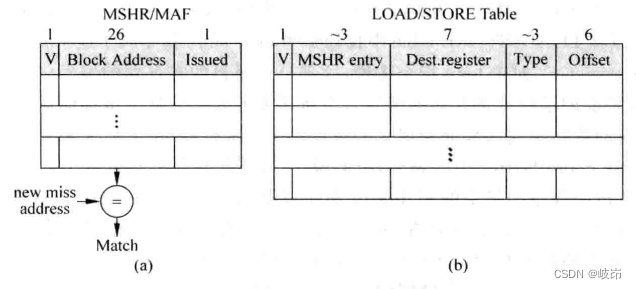
MSHR主体包括三项内容:
(a)V:valid位,用来指示当前的表项是否被占用,当发生首次缺失时,MSHR本体中的一个表项会被占用,此时valid位会被标记为1,当所需要的Cache line从下级存储器中取回来时,会释放MSHR本体中被占用的表项,因此valid位会被清零。
(b)Block Address:指的是Cache line中数据块的公共地址,假设物理地址是32位,对于一个大小为64字节的数据块来说,需要6位的地址才能找到数据块的某个字节,因此数据块的公共地址就需要32-6=26位。每次当load/store指令发生D-Cache miss时,都会在MSHR的本体中查到它所需要的数据块是否处于正在被取回的过程中,这需要个Block Address这一项进行比较才知道,通过这种方式,所有访问同一个数据块的指令只需要处理一次就可以了,避免存储带宽浪费。
(c)Issueed:表示首次缺失的load/store指令是否已经开始处理,即是否已经开始从下一级存储器取回数据的过程,由于存储器的带宽有限,占用MSHR本体的首次缺失不一定马上就会被处理,而是需要等到条件满足的时候,才会向下一级存储器发出读数据的请求。
还有一点需要注意,对一个发生缺失的数据来说,如果访问这个数据的所有load/store指令都处于分支预测失败的路径上,那么即使这个数据被下一级存储器中取出来,也不应该写到D-Cache中,这样可以保护D-Cache不会受到分支预测失败指令的影响。
在超标量处理器中,由于乱序执行的原因,可能会导致过多的load/store指令处于分支预测失败的路径上,这样增加了D-Cache缺失的概率,导致有比实际更多的D-Cache缺失需要处理。
9.6.3 关键字优先
当执行一条访问存储器的指令而发生D-Cache miss时,会将这条指令所需要整个数据块都从下一级存储器中取出来,如果考虑到预取,还需要将相邻的下一个数据块页取出来,通常一个数据块中包括的数据是比较多的,例如64字节。
如果等到数据块中所有数据都写到D-Cache之后才将所需要的数据送给CPU,这可能会让CPU等待一段时间,为了加快执行速度,可以对D-Cache的下一级存储器进行改造,使数据的读取顺序发生改变。
如果访问存储器的指令所需要的数据位于数据块的第6个字,那么此时可以使下一级存储器的读取从第6个字开始,当读取到数据末尾时,再从头开始将剩下的第0~5个字读取出来,这样做的好处是当下级存储器返回第一个字的时候,CPU就可以得到所需要的数据而继续执行了,而D-Cache会继续完成其他数据的填充工作,这就相当于将CPU的执行和Cache的填充两部分工作进行了重叠,提高了整体的执行效率,这就是关键字有限Critical Word First。当然,下级存储器系统需要增阿基硬件才能够支持这种特性,这在一定程度上增大了硅片面积和功耗。
9.6.4 提前开始
如果不相付出成本,那么可以采用提前开始的方法Early Restart的方法。这种方法不会改变存储器系统对于数据的读取顺序。
当指令所需要的数据,也就是第6个字,被从下一级存储器取出来时,就可以让CPU恢复执行了,此时数据块剩余的数据可以继续进行读取,这部分时间和CPU执行时间进行了交叠,这样提高了CPU的执行效率。
边栏推荐
- Design intelligent weighing system based on Huawei cloud IOT (STM32)
- 聊聊SOC启动(六)uboot启动流程二
- 问下flinkcdc2.2.0的版本,支持并发,这个并发是指多并行度吗,现在发现,mysqlcdc全
- Some opinions and code implementation of Siou loss: more powerful learning for bounding box regression zhora gevorgyan
- 清华姚班程序员,网上征婚被骂?
- 关于在云服务器上(这里用腾讯云)安装mysql8.0并使本地可以远程连接的方法
- SwiftUI Swift 内功之 Swift 中使用不透明类型的 5 个技巧
- 总结了200道经典的机器学习面试题(附参考答案)
- Flet教程之 19 VerticalDivider 分隔符组件 基础入门(教程含源码)
- Briefly introduce closures and some application scenarios
猜你喜欢
千人規模互聯網公司研發效能成功之路

禁锢自己的因素,原来有这么多

Web端自动化测试失败的原因
How to add aplayer music player in blog
About the application of writing shell script JSON in JMeter
La voie du succès de la R & D des entreprises Internet à l’échelle des milliers de personnes

Poor math students who once dropped out of school won the fields award this year

LeetCode - 面试题17.24 最大子矩阵

Zhou Yajin, a top safety scholar of Zhejiang University, is a curiosity driven activist
Le Cluster kubernets en cours d'exécution veut ajuster l'adresse du segment réseau du pod
随机推荐
Briefly introduce closures and some application scenarios
Talk about SOC startup (x) kernel startup pilot knowledge
禁锢自己的因素,原来有这么多
Excel公式知多少?
STM32 entry development uses IIC hardware timing to read and write AT24C08 (EEPROM)
对比学习之 Unsupervised Learning of Visual Features by Contrasting Cluster Assignments
STM32 entry development NEC infrared protocol decoding (ultra low cost wireless transmission scheme)
Flet教程之 19 VerticalDivider 分隔符组件 基础入门(教程含源码)
科普达人丨一文弄懂什么是云计算?
《论文阅读》Neural Approaches to Conversational AI(1)
electron添加SQLite数据库
Apprentissage comparatif non supervisé des caractéristiques visuelles par les assignations de groupes de contrôle
聊聊SOC启动(六)uboot启动流程二
基于华为云IOT设计智能称重系统(STM32)
核舟记(一):当“男妈妈”走进现实,生物科技革命能解放女性吗?
[system design] index monitoring and alarm system
CMU15445 (Fall 2019) 之 Project#2 - Hash Table 详解
Test the foundation of development, and teach you to prepare for a fully functional web platform environment
Qt|多个窗口共有一个提示框类
【时间格式工具函数的封装】