Preface
This experiment requires the implementation of a hash table based on linear detection , But different from the hash table directly in memory , The experiment assumes that the hash table is very large , Unable to put the whole into memory , Therefore, we need to split the hash table , Put multiple key value pairs in one Page in , Then, it is combined with an experiment Buffer Pool Manager Eat together . The approximate structure of the hash table is shown in the following figure :

Here is how to implement a thread safe hash table .
Code implementation
Page Layout
As can be seen from the above figure , Multiple key value pairs are placed in Page Inside , As Page The data of is stored on disk . In order to better organize and manage these key value pairs , Experimental task 1 requires us to implement two classes :HashTableHeaderPage and HashTableBlockPage,HashTableHeaderPage preserved block index To page id And other hash table metadata , There is only one hash table HashTableHeaderPage, and HashTableBlockPage There can be multiple .
Hash Table Header Page
HashTableHeaderPage There are several fields :
| Field | size | describe |
|---|---|---|
lsn_ | 4 bytes | Log sequence number (Used in Project 4) |
size_ | 4 bytes | Number of Key & Value pairs the hash table can hold |
page_id_ | 4 bytes | Self Page Id |
next_ind_ | 4 bytes | The next index to add a new entry to block_page_ids_ |
block_page_ids_ | 4080 bytes | Array of block page_id_t |
These fields total 4096 byte , It happens to be a Page Size , stay src/include/common/config.h You can modify PAGE_SIZE Size . The implementation code of this class is as follows :
namespace bustub {
page_id_t HashTableHeaderPage::GetBlockPageId(size_t index) {
assert(index < next_ind_);
return block_page_ids_[index];
}
page_id_t HashTableHeaderPage::GetPageId() const { return page_id_; }
void HashTableHeaderPage::SetPageId(bustub::page_id_t page_id) { page_id_ = page_id; }
lsn_t HashTableHeaderPage::GetLSN() const { return lsn_; }
void HashTableHeaderPage::SetLSN(lsn_t lsn) { lsn_ = lsn; }
void HashTableHeaderPage::AddBlockPageId(page_id_t page_id) { block_page_ids_[next_ind_++] = page_id; }
size_t HashTableHeaderPage::NumBlocks() { return next_ind_; }
void HashTableHeaderPage::SetSize(size_t size) { size_ = size; }
size_t HashTableHeaderPage::GetSize() const { return size_; }
} // namespace bustub
Hash Table Block Page
HashTableBlockPage Contains multiple slot, Used to save key-value pairs , So this class defines the query 、 Functions that insert and delete key value pairs . To track each slot Usage situation , This class contains the following three data members :
occupied_: The first i Location 1 Express Page Of the i individual slot Key value pairs are stored on the or key value pairs were previously stored but then deleted ( Play the role of a tombstone )readable_: The first i Location 1 Express Page Of the i individual slot Key value pairs are stored onarray_: An array used to hold key value pairs
The size of each key value pair is sizeof(std::pair<KeyType, ValueType>) byte ( Write it down as PS), Each key value pair corresponds to two bit(occupied and readable) namely 1/4 Bytes , So a Page Can save up to BLOCK_ARRAY_SIZE = PAGE_SIZE / (PS + 1/4) Key value pairs , each Page Yes BLOCK_ARRAY_SIZE individual slot.
because occupied_ and readable_ Is defined as char Array , So we need two auxiliary functions GetBit and SetBit To visit No i Bit of bit .
namespace bustub {
/**
* Store indexed key and and value together within block page. Supports
* non-unique keys.
*
* Block page format (keys are stored in order):
* ----------------------------------------------------------------
* | KEY(1) + VALUE(1) | KEY(2) + VALUE(2) | ... | KEY(n) + VALUE(n)
* ----------------------------------------------------------------
*
* Here '+' means concatenation.
*
*/
template <typename KeyType, typename ValueType, typename KeyComparator>
class HashTableBlockPage {
public:
// Delete all constructor / destructor to ensure memory safety
HashTableBlockPage() = delete;
KeyType KeyAt(slot_offset_t bucket_ind) const;
ValueType ValueAt(slot_offset_t bucket_ind) const;
bool Insert(slot_offset_t bucket_ind, const KeyType &key, const ValueType &value);
void Remove(slot_offset_t bucket_ind);
bool IsOccupied(slot_offset_t bucket_ind) const;
bool IsReadable(slot_offset_t bucket_ind) const;
private:
bool GetBit(const std::atomic_char *array, slot_offset_t bucket_ind) const;
void SetBit(std::atomic_char *array, slot_offset_t bucket_ind, bool value);
std::atomic_char occupied_[(BLOCK_ARRAY_SIZE - 1) / 8 + 1];
// 0 if tombstone/brand new (never occupied), 1 otherwise.
std::atomic_char readable_[(BLOCK_ARRAY_SIZE - 1) / 8 + 1];
MappingType array_[0];
};
} // namespace bustub
The implementation code is as follows :
namespace bustub {
template <typename KeyType, typename ValueType, typename KeyComparator>
KeyType HASH_TABLE_BLOCK_TYPE::KeyAt(slot_offset_t bucket_ind) const {
return array_[bucket_ind].first;
}
template <typename KeyType, typename ValueType, typename KeyComparator>
ValueType HASH_TABLE_BLOCK_TYPE::ValueAt(slot_offset_t bucket_ind) const {
return array_[bucket_ind].second;
}
template <typename KeyType, typename ValueType, typename KeyComparator>
bool HASH_TABLE_BLOCK_TYPE::Insert(slot_offset_t bucket_ind, const KeyType &key, const ValueType &value) {
if (IsReadable(bucket_ind)) {
return false;
}
array_[bucket_ind] = {key, value};
SetBit(readable_, bucket_ind, true);
SetBit(occupied_, bucket_ind, true);
return true;
}
template <typename KeyType, typename ValueType, typename KeyComparator>
void HASH_TABLE_BLOCK_TYPE::Remove(slot_offset_t bucket_ind) {
SetBit(readable_, bucket_ind, false);
}
template <typename KeyType, typename ValueType, typename KeyComparator>
bool HASH_TABLE_BLOCK_TYPE::IsOccupied(slot_offset_t bucket_ind) const {
return GetBit(occupied_, bucket_ind);
}
template <typename KeyType, typename ValueType, typename KeyComparator>
bool HASH_TABLE_BLOCK_TYPE::IsReadable(slot_offset_t bucket_ind) const {
return GetBit(readable_, bucket_ind);
}
template <typename KeyType, typename ValueType, typename KeyComparator>
bool HASH_TABLE_BLOCK_TYPE::GetBit(const std::atomic_char *array, slot_offset_t bucket_ind) const {
return array[bucket_ind / 8] & (1 << bucket_ind % 8);
}
template <typename KeyType, typename ValueType, typename KeyComparator>
void HASH_TABLE_BLOCK_TYPE::SetBit(std::atomic_char *array, slot_offset_t bucket_ind, bool value) {
if (value) {
array[bucket_ind / 8] |= (1 << bucket_ind % 8);
} else {
array[bucket_ind / 8] &= ~(1 << bucket_ind % 8);
}
}
// DO NOT REMOVE ANYTHING BELOW THIS LINE
template class HashTableBlockPage<int, int, IntComparator>;
template class HashTableBlockPage<GenericKey<4>, RID, GenericComparator<4>>;
template class HashTableBlockPage<GenericKey<8>, RID, GenericComparator<8>>;
template class HashTableBlockPage<GenericKey<16>, RID, GenericComparator<16>>;
template class HashTableBlockPage<GenericKey<32>, RID, GenericComparator<32>>;
template class HashTableBlockPage<GenericKey<64>, RID, GenericComparator<64>>;
} // namespace bustub
Hashtable
Statement
The experiment requires us to insert hash table 、 lookup 、 Delete and resize , The corresponding class declaration is as follows , In order to complete these operations , We have defined several more private auxiliary functions and member variables :
namespace bustub {
#define HASH_TABLE_TYPE LinearProbeHashTable<KeyType, ValueType, KeyComparator>
template <typename KeyType, typename ValueType, typename KeyComparator>
class LinearProbeHashTable : public HashTable<KeyType, ValueType, KeyComparator> {
public:
explicit LinearProbeHashTable(const std::string &name, BufferPoolManager *buffer_pool_manager,
const KeyComparator &comparator, size_t num_buckets, HashFunction<KeyType> hash_fn);
bool Insert(Transaction *transaction, const KeyType &key, const ValueType &value) override;
bool Remove(Transaction *transaction, const KeyType &key, const ValueType &value) override;
bool GetValue(Transaction *transaction, const KeyType &key, std::vector<ValueType> *result) override;
void Resize(size_t initial_size);
size_t GetSize();
private:
using slot_index_t = size_t;
using block_index_t = size_t;
enum class LockType { READ = 0, WRITE = 1 };
/**
* initialize header page and allocate block pages for it
* @param page the hash table header page
*/
void InitHeaderPage(HashTableHeaderPage *page);
/**
* get index according to key
* @param key the key to be hashed
* @return a tuple contains slot index, block page index and bucket index
*/
std::tuple<slot_index_t, block_index_t, slot_offset_t> GetIndex(const KeyType &key);
/**
* linear probe step forward
* @param bucket_index the bucket index
* @param block_index the hash table block page index
* @param header_page hash table header page
* @param raw_block_page raw hash table block page
* @param block_page hash table block page
* @param lock_type lock type of block page
*/
void StepForward(slot_offset_t &bucket_index, block_index_t &block_index, Page *&raw_block_page,
HASH_TABLE_BLOCK_TYPE *&block_page, LockType lockType);
bool InsertImpl(Transaction *transaction, const KeyType &key, const ValueType &value);
inline bool IsMatch(HASH_TABLE_BLOCK_TYPE *block_page, slot_offset_t bucket_index, const KeyType &key,
const ValueType &value) {
return !comparator_(key, block_page->KeyAt(bucket_index)) && value == block_page->ValueAt(bucket_index);
}
inline HashTableHeaderPage *HeaderPageCast(Page *page) {
return reinterpret_cast<HashTableHeaderPage *>(page->GetData());
}
inline HASH_TABLE_BLOCK_TYPE *BlockPageCast(Page *page) {
return reinterpret_cast<HASH_TABLE_BLOCK_TYPE *>(page->GetData());
}
/**
* get the slot number of hash table block page
* @param block_index the index of hash table block page
* @return the slot number of block page
*/
inline size_t GetBlockArraySize(block_index_t block_index){
return block_index < num_pages_ - 1 ? BLOCK_ARRAY_SIZE : last_block_array_size_;
}
// member variable
page_id_t header_page_id_;
BufferPoolManager *buffer_pool_manager_;
KeyComparator comparator_;
std::vector<page_id_t> page_ids_;
size_t num_buckets_;
size_t num_pages_;
size_t last_block_array_size_;
// Readers includes inserts and removes, writer is only resize
ReaderWriterLatch table_latch_;
// Hash function
HashFunction<KeyType> hash_fn_;
};
} // namespace bustub
Constructors
In the constructor, it is responsible for num_buckets ( That is to say slot The number of ) Distribute Page, the last one Page Of slot The number may be less than the previous Page. Here will also be each HashTableBlockPage Corresponding page_id Save to page_ids_ Members inside , Then you don't need to just know someone HashTableBlockPage Of page_id And find BufferPoolManager Ask for HashTableHeaderPage.
template <typename KeyType, typename ValueType, typename KeyComparator>
HASH_TABLE_TYPE::LinearProbeHashTable(const std::string &name, BufferPoolManager *buffer_pool_manager,
const KeyComparator &comparator, size_t num_buckets,
HashFunction<KeyType> hash_fn)
: buffer_pool_manager_(buffer_pool_manager),
comparator_(comparator),
num_buckets_(num_buckets),
num_pages_((num_buckets - 1) / BLOCK_ARRAY_SIZE + 1),
last_block_array_size_(num_buckets - (num_pages_ - 1) * BLOCK_ARRAY_SIZE),
hash_fn_(std::move(hash_fn)) {
auto page = buffer_pool_manager->NewPage(&header_page_id_);
page->WLatch();
InitHeaderPage(HeaderPageCast(page));
page->WUnlatch();
buffer_pool_manager_->UnpinPage(header_page_id_, true);
}
template <typename KeyType, typename ValueType, typename KeyComparator>
void HASH_TABLE_TYPE::InitHeaderPage(HashTableHeaderPage *header_page) {
header_page->SetPageId(header_page_id_);
header_page->SetSize(num_buckets_);
page_ids_.clear();
for (size_t i = 0; i < num_pages_; ++i) {
page_id_t page_id;
buffer_pool_manager_->NewPage(&page_id);
buffer_pool_manager_->UnpinPage(page_id, false);
header_page->AddBlockPageId(page_id);
page_ids_.push_back(page_id);
}
}
lookup
Hash table uses linear detection method to find key value pairs , Because the experiment requires that the hash table supports inserting key value pairs with different values of the same key , Therefore, in the process of linear detection, you need to insert the values of all the same keys result Vector :
template <typename KeyType, typename ValueType, typename KeyComparator>
bool HASH_TABLE_TYPE::GetValue(Transaction *transaction, const KeyType &key, std::vector<ValueType> *result) {
table_latch_.RLock();
// get slot index, block page index and bucket index according to key
auto [slot_index, block_index, bucket_index] = GetIndex(key);
// get block page that contains the key
auto raw_block_page = buffer_pool_manager_->FetchPage(page_ids_[block_index]);
raw_block_page->RLatch();
auto block_page = BlockPageCast(raw_block_page);
// linear probe
while (block_page->IsOccupied(bucket_index)) {
// find the correct position
if (block_page->IsReadable(bucket_index) && !comparator_(key, block_page->KeyAt(bucket_index))) {
result->push_back(block_page->ValueAt(bucket_index));
}
StepForward(bucket_index, block_index, raw_block_page, block_page, LockType::READ);
// break loop if we have returned to original position
if (block_index * BLOCK_ARRAY_SIZE + bucket_index == slot_index) {
break;
}
}
// unlock
raw_block_page->RUnlatch();
buffer_pool_manager_->UnpinPage(raw_block_page->GetPageId(), false);
table_latch_.RUnlock();
return result->size() > 0;
}
GetIndex Functions are based on key Calculate the corresponding slot_index、block_index and bucket_index( Namely slot offset), Combined with the above figure, we can understand the working principle of this function :
template <typename KeyType, typename ValueType, typename KeyComparator>
auto HASH_TABLE_TYPE::GetIndex(const KeyType &key) -> std::tuple<slot_index_t, block_index_t, slot_offset_t> {
slot_index_t slot_index = hash_fn_.GetHash(key) % num_buckets_;
block_index_t block_index = slot_index / BLOCK_ARRAY_SIZE;
slot_offset_t bucket_index = slot_index % BLOCK_ARRAY_SIZE;
return {slot_index, block_index, bucket_index};
}
In the process of linear detection , We may start from one HashTableBlockPage Skip to the next , It needs to be updated at this time bucket_index and block_index:
template <typename KeyType, typename ValueType, typename KeyComparator>
void HASH_TABLE_TYPE::StepForward(slot_offset_t &bucket_index, block_index_t &block_index, Page *&raw_block_page,
HASH_TABLE_BLOCK_TYPE *&block_page, LockType lockType) {
if (++bucket_index != GetBlockArraySize(block_index)) {
return;
}
// move to next block page
if (lockType == LockType::READ) {
raw_block_page->RUnlatch();
} else {
raw_block_page->WUnlatch();
}
buffer_pool_manager_->UnpinPage(page_ids_[block_index], false);
// update index
bucket_index = 0;
block_index = (block_index + 1) % num_pages_;
// update page
raw_block_page = buffer_pool_manager_->FetchPage(page_ids_[block_index]);
if (lockType == LockType::READ) {
raw_block_page->RLatch();
} else {
raw_block_page->WLatch();
}
block_page = BlockPageCast(raw_block_page);
}
Insert
The experiment requires that the hash table is not allowed to insert existing key value pairs , At the same time, if you return to the original position during the insertion process , Explain that there is no available slot Used to insert key value pairs , At this time, you need to double the size of the hash table . because Resize The function of also needs to use the insert operation , If called directly Insert A deadlock occurs , So here we use InsertImpl To achieve insertion :
template <typename KeyType, typename ValueType, typename KeyComparator>
bool HASH_TABLE_TYPE::Insert(Transaction *transaction, const KeyType &key, const ValueType &value) {
table_latch_.RLock();
auto success = InsertImpl(transaction, key, value);
table_latch_.RUnlock();
return success;
}
template <typename KeyType, typename ValueType, typename KeyComparator>
bool HASH_TABLE_TYPE::InsertImpl(Transaction *transaction, const KeyType &key, const ValueType &value) {
// get slot index, block page index and bucket index according to key
auto [slot_index, block_index, bucket_index] = GetIndex(key);
// get block page that contains the key
auto raw_block_page = buffer_pool_manager_->FetchPage(page_ids_[block_index]);
raw_block_page->WLatch();
auto block_page = BlockPageCast(raw_block_page);
bool success = true;
while (!block_page->Insert(bucket_index, key, value)) {
// return false if (key, value) pair already exists
if (block_page->IsReadable(bucket_index) && IsMatch(block_page, bucket_index, key, value)) {
success = false;
break;
}
StepForward(bucket_index, block_index, raw_block_page, block_page, LockType::WRITE);
// resize hash table if we have returned to original position
if (block_index * BLOCK_ARRAY_SIZE + bucket_index == slot_index) {
raw_block_page->WUnlatch();
buffer_pool_manager_->UnpinPage(raw_block_page->GetPageId(), false);
Resize(num_pages_);
std::tie(slot_index, block_index, bucket_index) = GetIndex(key);
raw_block_page = buffer_pool_manager_->FetchPage(page_ids_[block_index]);
raw_block_page->WLatch();
block_page = BlockPageCast(raw_block_page);
}
}
raw_block_page->WUnlatch();
buffer_pool_manager_->UnpinPage(raw_block_page->GetPageId(), success);
return success;
}
Resize
Because the experiment assumes that the hash table is large , So we can't save all the original key value pairs into memory , Then adjust HashTableHeaderPage Size , Reuse HashTableBlockPage And create a new Page, Then re insert the key value pair . Instead, you should directly create new HashTableHeaderPage and HashTableBlockPage , And delete the old hash table page :
template <typename KeyType, typename ValueType, typename KeyComparator>
void HASH_TABLE_TYPE::Resize(size_t initial_size) {
table_latch_.WLock();
num_buckets_ = 2 * initial_size;
num_pages_ = (num_buckets_ - 1) / BLOCK_ARRAY_SIZE + 1;
last_block_array_size_ = num_buckets_ - (num_pages_ - 1) * BLOCK_ARRAY_SIZE;
// save the old header page id
auto old_header_page_id = header_page_id_;
std::vector<page_id_t> old_page_ids(page_ids_);
// get the new header page
auto raw_header_page = buffer_pool_manager_->NewPage(&header_page_id_);
raw_header_page->WLatch();
InitHeaderPage(HeaderPageCast(raw_header_page));
// move (key, value) pairs to new space
for (size_t block_index = 0; block_index < num_pages_; ++block_index) {
auto old_page_id = old_page_ids[block_index];
auto raw_block_page = buffer_pool_manager_->FetchPage(old_page_id);
raw_block_page->RLatch();
auto block_page = BlockPageCast(raw_block_page);
// move (key, value) pair from each readable slot
for (slot_offset_t bucket_index = 0; bucket_index < GetBlockArraySize(block_index); ++bucket_index) {
if (block_page->IsReadable(bucket_index)) {
InsertImpl(nullptr, block_page->KeyAt(bucket_index), block_page->ValueAt(bucket_index));
}
}
// delete old page
raw_block_page->RUnlatch();
buffer_pool_manager_->UnpinPage(old_page_id, false);
buffer_pool_manager_->DeletePage(old_page_id);
}
raw_header_page->WUnlatch();
buffer_pool_manager_->UnpinPage(header_page_id_, false);
buffer_pool_manager_->DeletePage(old_header_page_id);
table_latch_.WUnlock();
}
Delete
The delete operation is very similar to the find operation , But what will be found slot It's just a tombstone :
template <typename KeyType, typename ValueType, typename KeyComparator>
bool HASH_TABLE_TYPE::Remove(Transaction *transaction, const KeyType &key, const ValueType &value) {
table_latch_.RLock();
// get slot index, block page index and bucket index according to key
auto [slot_index, block_index, bucket_index] = GetIndex(key);
// get block page that contains the key
auto raw_block_page = buffer_pool_manager_->FetchPage(page_ids_[block_index]);
raw_block_page->WLatch();
auto block_page = BlockPageCast(raw_block_page);
bool success = false;
while (block_page->IsOccupied(bucket_index)) {
// remove the (key, value) pair if find the matched readable one
if (IsMatch(block_page, bucket_index, key, value)) {
if (block_page->IsReadable(bucket_index)) {
block_page->Remove(bucket_index);
success = true;
} else {
success = false;
}
break;
}
// step forward
StepForward(bucket_index, block_index, raw_block_page, block_page, LockType::WRITE);
// break loop if we have returned to original position
if (block_index * BLOCK_ARRAY_SIZE + bucket_index == slot_index) {
break;
}
}
raw_block_page->WUnlatch();
buffer_pool_manager_->UnpinPage(raw_block_page->GetPageId(), success);
table_latch_.RUnlock();
return success;
}
Get size
Finally, get the size of the hash table , Go straight back to num_buckets_ That's it :
template <typename KeyType, typename ValueType, typename KeyComparator>
size_t HASH_TABLE_TYPE::GetSize() {
return num_buckets_;
}
test
The test results of hash table are as follows ,6 All tests passed :
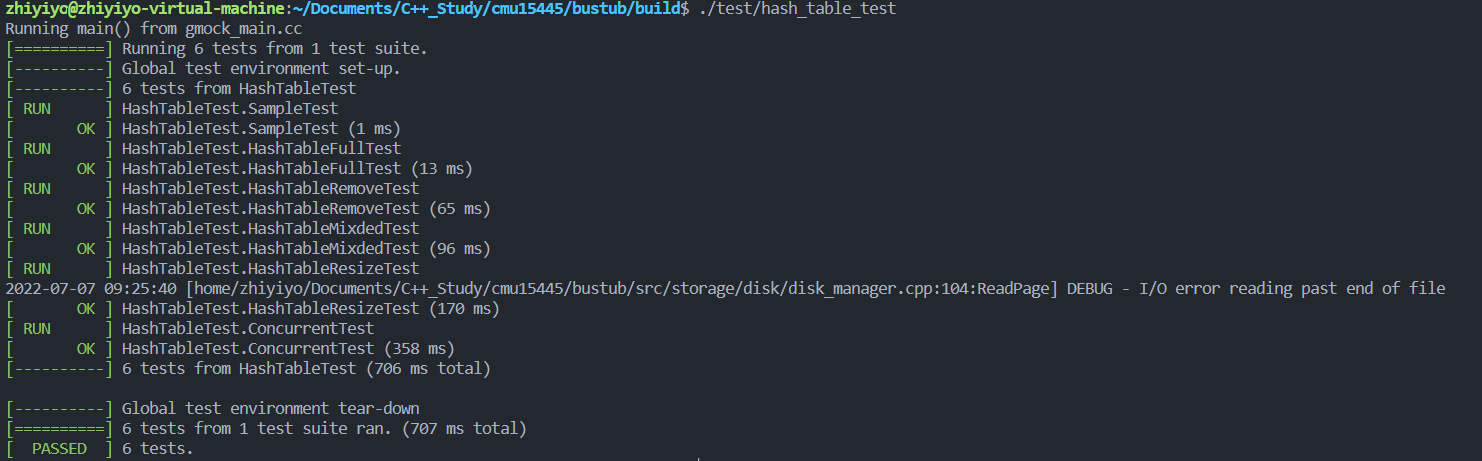
summary
This experiment mainly investigates the linear detection hash table 、 Understanding of buffer pool manager and read / write lock , The difficulty is slightly higher than that of the previous experiment , But after understanding the structure diagram of hash table, it should not be difficult to complete the experiment , above ~~



![Drive HC based on de2115 development board_ SR04 ultrasonic ranging module [source code attached]](/img/ed/29d6bf21f857ec925bf425ad594e36.png)