当前位置:网站首页>Yolov5 adds attention mechanism
Yolov5 adds attention mechanism
2022-07-05 05:17:00 【Master Ma】
YOLOv5 Adding attention mechanism can be divided into the following three steps :
1.common.py Add attention module to
2.yolo.py Add judgment conditions in
3.yaml Add corresponding modules to the file
One 、CBAM Attention mechanism added
(1) stay common.py Add callable CBAM modular
1. open models In folder common.py file 
2. The following CBAMC3 Copy and paste code into common.py In file
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.f1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu = nn.ReLU()
self.f2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
# Write two , Sequential containers can also be used
# self.sharedMLP = nn.Sequential(
# nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False), nn.ReLU(),
# nn.Conv2d(in_planes // rotio, in_planes, 1, bias=False))
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.f2(self.relu(self.f1(self.avg_pool(x))))
max_out = self.f2(self.relu(self.f1(self.max_pool(x))))
out = self.sigmoid(avg_out + max_out)
return torch.mul(x, out)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
out = torch.cat([avg_out, max_out], dim=1)
out = self.sigmoid(self.conv(out))
return torch.mul(x, out)
class CBAMC3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(CBAMC3, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
self.channel_attention = ChannelAttention(c2, 16)
self.spatial_attention = SpatialAttention(7)
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
# The last standard convolution module is changed to the attention mechanism to extract features
return self.spatial_attention(
self.channel_attention(self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))))
As shown in the figure below , This article pastes it into common.py At the end of 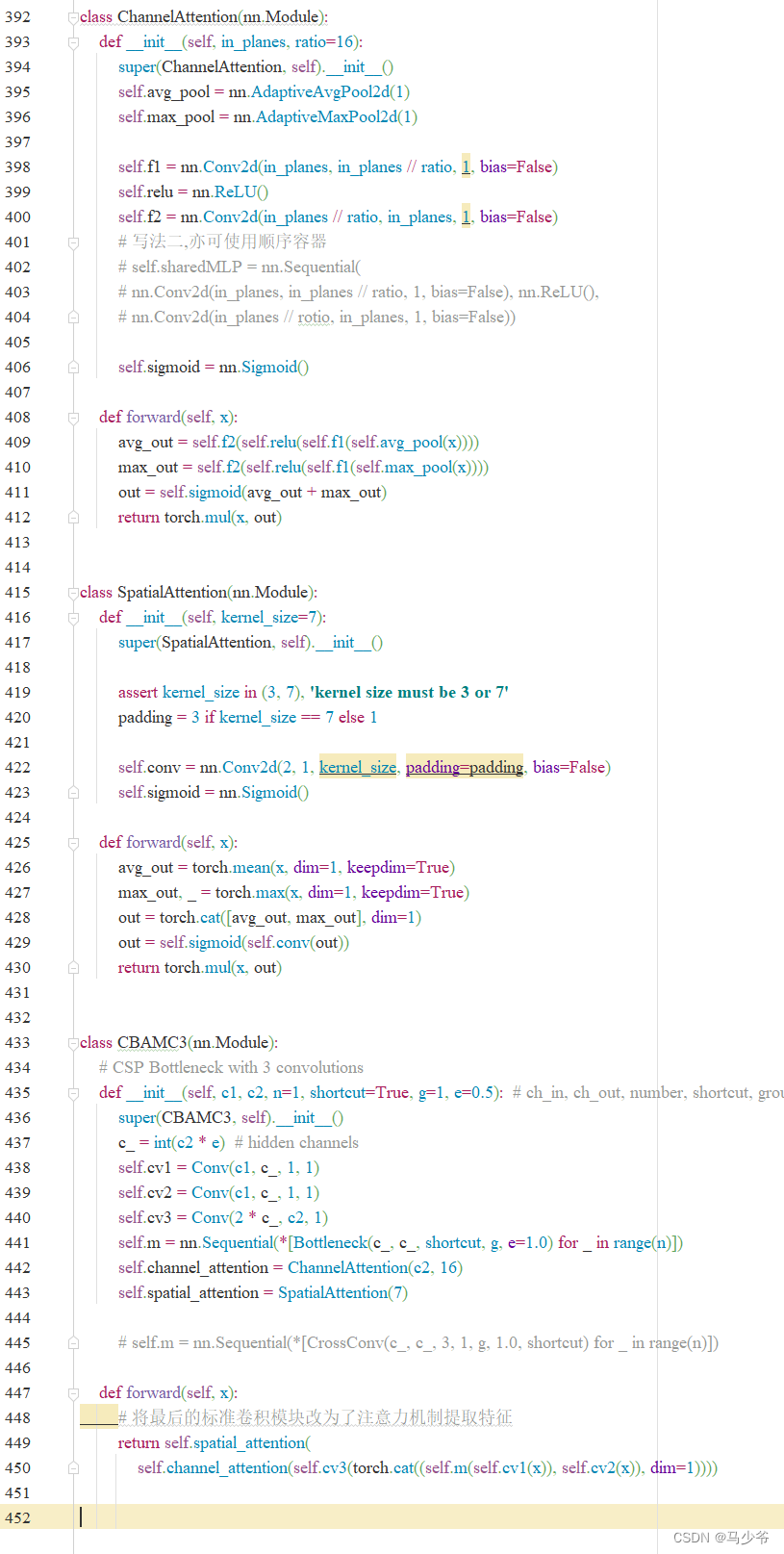
(2) towards yolo.py File to add CBAMC3 Judgment statement
1. open models In folder yolo.py file 
2. Respectively in 239 Row sum 245 Line add CBAMC3, As shown in the figure below 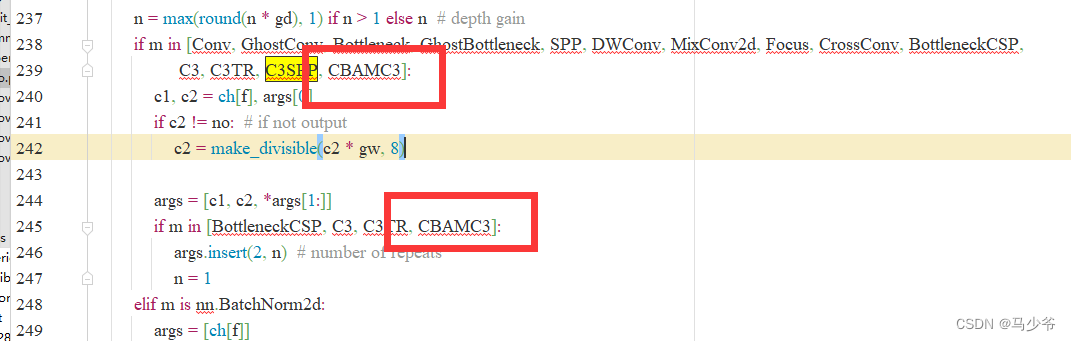
Also remember to click save after the change
3) modify yaml file
Attention mechanisms can be added to backbone,Neck,Head Other parts , You can yaml Modify the structure of the network in the file 、 Add other modules, etc , Next, this article will introduce the backbone network (backbone) add to CBAM Module as an example , This article introduces only one of the ways to add
1. stay yolov5-5.0 Under the project folder , find models Under folder yolov5s.yaml file 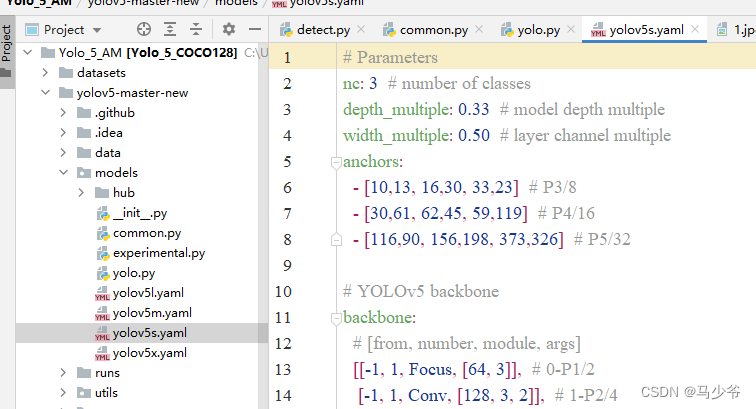
2.backbone In the backbone network 4 individual C3 Module changed to CBAMC3, As shown in the figure below :


So here we are yolov5s Added to the backbone network CBAM Attention mechanism
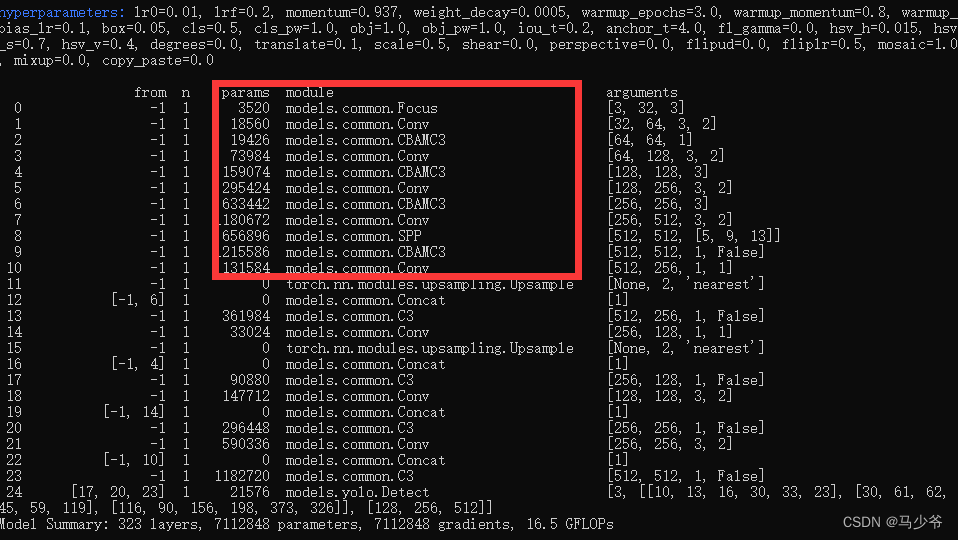
Next, start training the model , We can see CBAMC3 The module has been successfully added to the backbone network
Two 、SE Attention mechanism added
( Steps and CBAM be similar )
(1) stay common.py Add callable SE modular
1. open models In folder common.py file 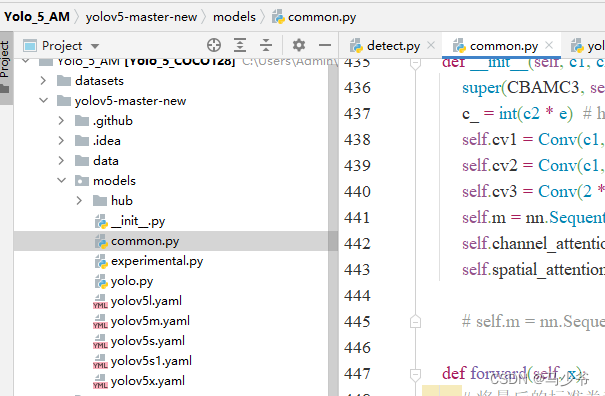
2. The following SE Copy and paste code into common.py In file
class SE(nn.Module):
def __init__(self, c1, c2, r=16):
super(SE, self).__init__()
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.l1 = nn.Linear(c1, c1 // r, bias=False)
self.relu = nn.ReLU(inplace=True)
self.l2 = nn.Linear(c1 // r, c1, bias=False)
self.sig = nn.Sigmoid()
def forward(self, x):
print(x.size())
b, c, _, _ = x.size()
y = self.avgpool(x).view(b, c)
y = self.l1(y)
y = self.relu(y)
y = self.l2(y)
y = self.sig(y)
y = y.view(b, c, 1, 1)
return x * y.expand_as(x)
As shown in the figure below , This article pastes it into common.py At the end of 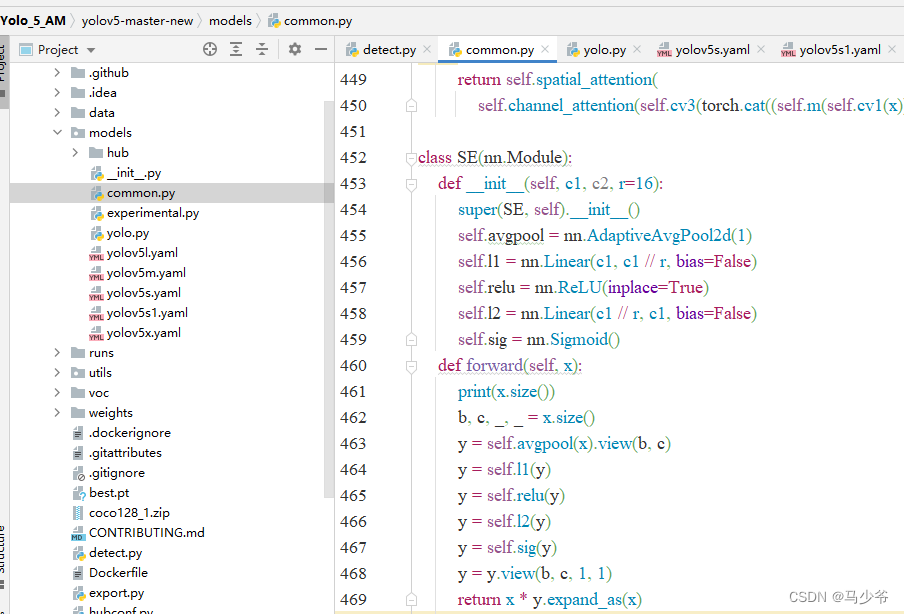
(2) towards yolo.py File to add SE Judgment statement
1. open models In folder yolo.py file 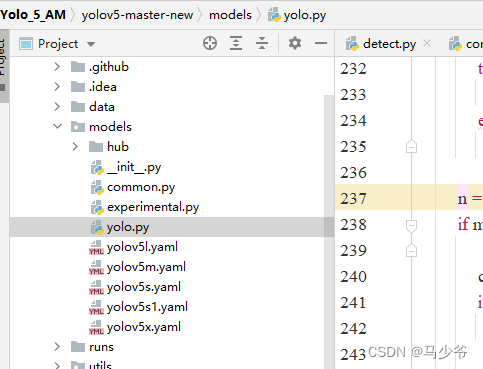
2. Respectively in 238 Row sum 245 Line add SE, As shown in the figure below
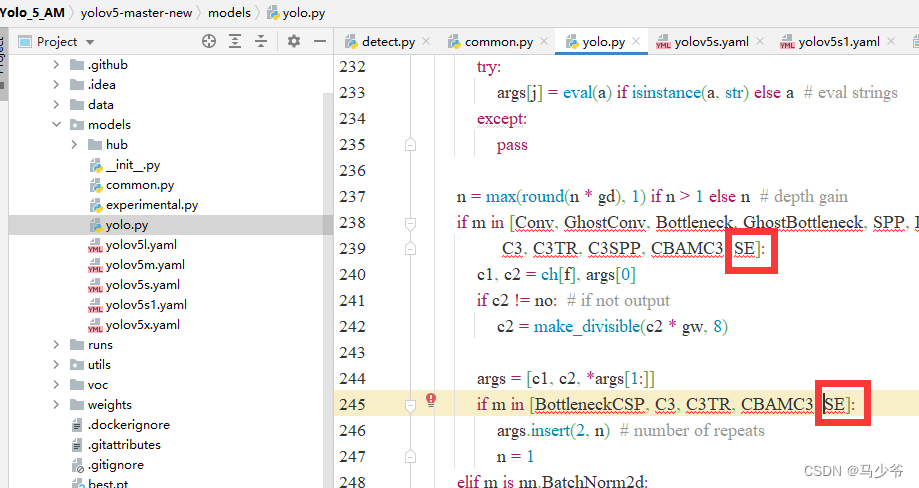
Also remember to click save after the change
(3) modify yaml file
Attention mechanisms can be added to backbone,Neck,Head Other parts , You can yaml Modify the structure of the network in the file 、 Add other modules, etc . And CBAM The same process as adding , Next, this article will introduce the backbone network (backbone) add to SE Module as an example , This article introduces only one of the ways to add
1. stay yolov5-5.0 Under the project folder , find models Under folder yolov5s.yaml file 
2.backbone Add the following code at the end of the backbone network , As shown in the figure below :
( Note that commas are in English , And pay attention to alignment )
[-1, 1, SE, [1024, 4]],
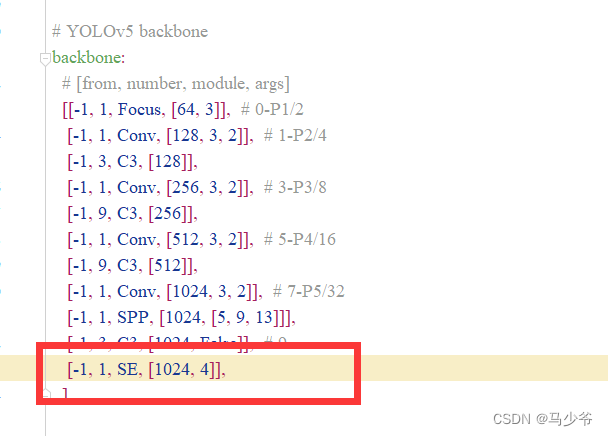
So here we are yolov5s Added to the backbone network SE Attention mechanism
( Run the modified code on the server , Remember to click save in the upper right corner of the text editor )
Next, start training the model , We can see SE The module has been successfully added to the backbone network 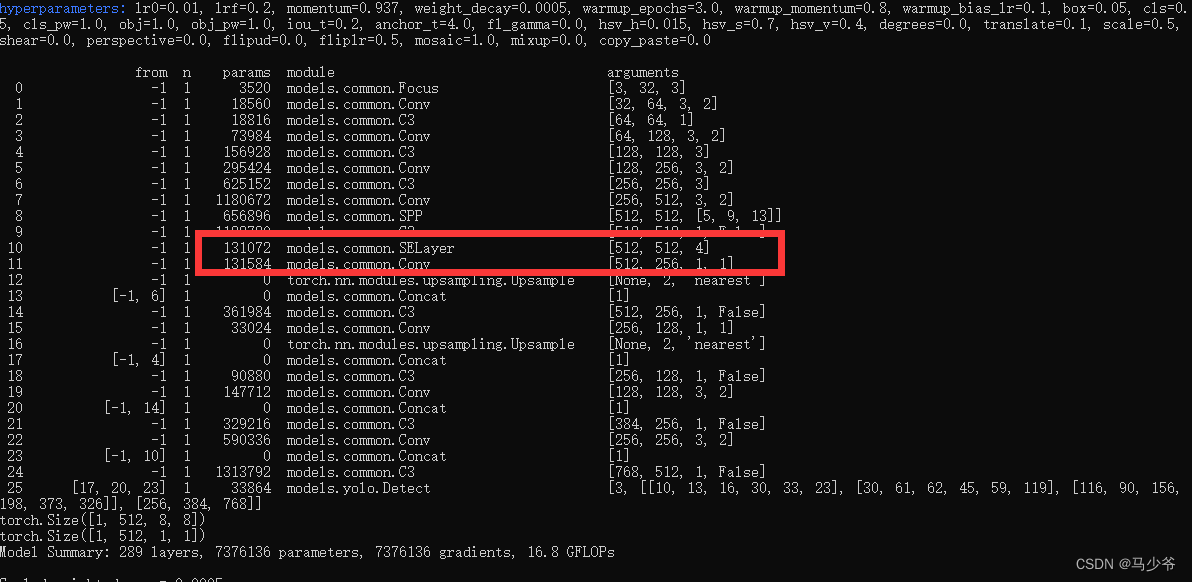
3、 ... and 、 Several other attention mechanism codes
The addition process will not be repeated , Imitate the top CBAM and SE The adding process of the
(1)ECA Attention mechanism code
class eca_layer(nn.Module):
"""Constructs a ECA module.
Args:
channel: Number of channels of the input feature map
k_size: Adaptive selection of kernel size
"""
def __init__(self, channel, k_size=3):
super(eca_layer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# feature descriptor on the global spatial information
y = self.avg_pool(x)
# Two different branches of ECA module
y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
# Multi-scale information fusion
y = self.sigmoid(y)
x=x*y.expand_as(x)
return x * y.expand_as(x)
(2)CA Attention mechanism code :
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CoordAtt(nn.Module):
def __init__(self, inp, oup, reduction=32):
super(CoordAtt, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n, c, h, w = x.size()
x_h = self.pool_h(x)
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return out
reference :https://blog.csdn.net/thy0000/article/details/125016410
边栏推荐
- Magnifying glass effect
- Unity and database
- Unity ugui source code graphic
- Transport connection management of TCP
- C iterator
- Learning notes of "hands on learning in depth"
- Embedded database development programming (VI) -- C API
- Haut OJ 1350: choice sends candy
- Unity sends messages and blocks indecent words
- [turn to] MySQL operation practice (I): Keywords & functions
猜你喜欢

![[转]MySQL操作实战(三):表联结](/img/70/20bf9b379ce58761bae9955982a158.png)

![[trans]: spécification osgi](/img/54/d73a8d3e375dfe430c2eca39617b9c.png)
随机推荐
Collapse of adjacent vertical outer margins
[turn]: Apache Felix framework configuration properties
C # perspective following
Common database statements in unity
Vs2015 secret key
Unity and database
Download xftp7 and xshell7 (official website)
支持多模多态 GBase 8c数据库持续创新重磅升级
Applet Live + e - commerce, si vous voulez être un nouveau e - commerce de détail, utilisez - le!
Lua determines whether the current time is the time of the day
Simple HelloWorld color change
Stm32cubemx (8): RTC and RTC wake-up interrupt
A complete attack chain
GameObject class and transform class of unity
Double pointer Foundation
64 horses, 8 tracks, how many times does it take to find the fastest 4 horses at least
Magnifying glass effect
UE fantasy engine, project structure
[paper notes] multi goal reinforcement learning: challenging robotics environments and request for research
Ue4/ue5 illusory engine, material part (III), material optimization at different distances