当前位置:网站首页>(August 10, 2021) web crawler learning - Chinese University ranking directed crawler
(August 10, 2021) web crawler learning - Chinese University ranking directed crawler
2022-07-04 11:19:00 【Kosisi】
Web crawler learning
- 1 Requests
- 2 Beautiful Soup library
- 3 bs4 example - Chinese universities rank directional reptiles
Source of the course : Mu class course
Record my learning process
Study for a long time : Three days
1 Requests
1.1 Requests The installation of the library
stay anaconda Install in requests library , Because of my python The environment is anaconda Build a virtual environment .
Only need anaconda Prompt Enter the following code in :
conda install requests
After the installation is successful, you can install it in cmd Try it out . In the use of pycharm call requests library , I need to configure its interpreter , I have encountered such problems several times before , Use it clearly anaconda Module installed , But in pycharm Cannot call , Later, it was found that the interpreter was not configured .
stay setting>Project:pyfile>Project Interpreter Middle configuration , Here's the picture :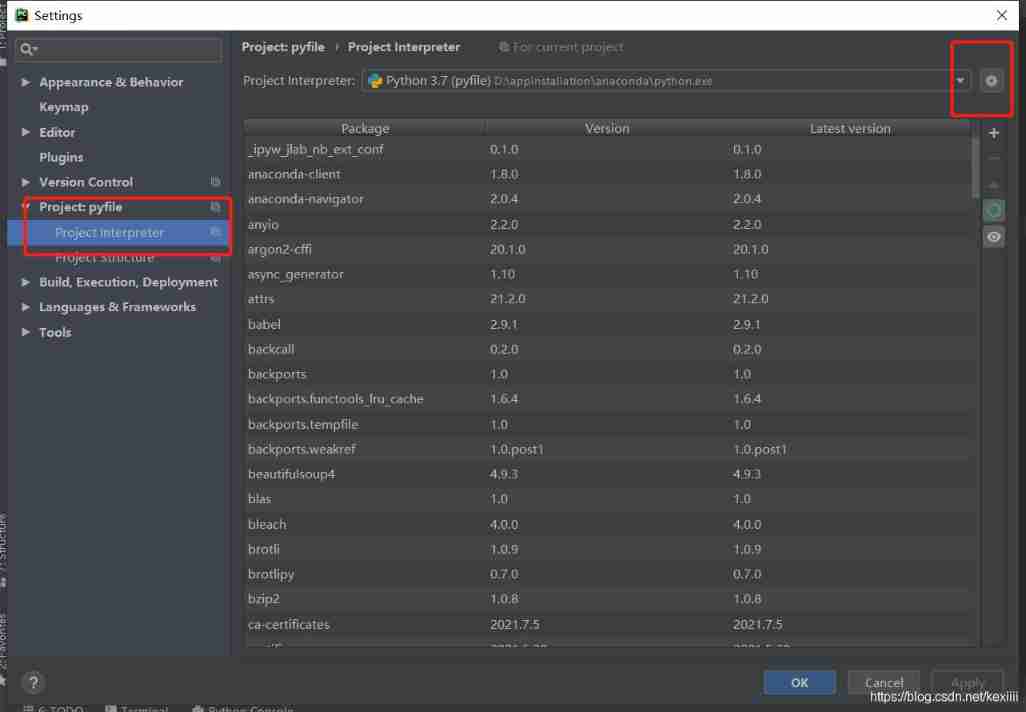
My choice is anaconda Install in python The location of , Can be confirmed .
Start a pleasant reptile journey !
1.2 Requests Library 7 Main methods
| Method | explain |
|---|---|
| requests.request() | Construct a request , Basic methods supporting the following methods |
| requests.get() | obtain HTML The main method of web page , Corresponding to HTTP Of GET |
| requests.head() | obtain HTML Web page header information method , Corresponding to HTTP Of HEAD |
| requests.post() | towards HTML Web submission POST Requested method , Corresponding to HTTP Of POST |
| requests.put() | towards HTML Web submission PUT Requested method , Corresponding to HTTP Of PUT |
| requests.patch() | towards HTML Submit local modification request for web page , Corresponding to HTTP Of PATCH |
| requests.delete() | towards HTML Page submit delete request , Corresponding to HTTP Of DELETE |
1.2.1 request() Method
request Method :requests.request(method, url, **kwargs)
method: Request mode , Corresponding get/put/post etc. 7 Methods , namely HTTP Those functions of .
url: To get the page url link
**kwargs:13 Parameters to control access , All are optional
1)params: Dictionaries or byte sequences , Add as a parameter to url in ;
import requests
kv = {
'key1': 'value1', 'key2': 'value2'}
r = requests.request('GET', 'http://python123.io/ws', params=kv)
print(r.url)
Output gets :https://python123.io/ws?key1=value1&key2=value2
Through this method , You can add some key value pairs to url in , bring url On another visit , Not only this resource is accessed , At the same time, these parameters are brought in , The server depends on these parameters , Filter some resources and return .
2)data: Dictionaries 、 Byte sequence or file object , As Request The content of ; The focus is on providing or submitting resources to the server . The resources submitted are not placed in url In the link , It's on the url Where the link corresponds , Store as data .
import requests
kv = {
'key1': 'value1', 'key2': 'value2'}
r = requests.request('POST', 'http://python123.io/ws', data=kv)
3)json:JSON Formatted data , As Request The content of
It can also be submitted to the server as part of the content .
4)headers: Dictionaries ,HTTP Customize the beginning ; It corresponds to a url Initiated during the visit HTTP Header fields , In other words, we can use this field to customize access to a url Of HTTP The head of the agreement .
We can define a dictionary hd = {'user-agent': 'Chrome/10'} To modify the HTTP In the agreement user-agent Field , We put user-agent Turn into Chrome/10,r = requests.request('POST', 'http://python123.io/ws', headers=hd) When visiting a link , We can assign such fields to headers, here headers When accessing the server again , What the server sees user-agent The field is Chrome/10, That is to say Chrome The tenth version of the browser ; This method of simulating browsers is in header Field .
4)cookies: It refers to a dictionary or CookieJar,Request Medium cookie, from HTTP Chinese analysis cookie
auth: It's a tuple type , Support HTTP Authentication function
5)files: Dictionary type , Fields used when transferring files to the server
import requests
fs = {
'file': open('data.xls', 'rb')}
r = requests.request('POST', 'http://python123.io/ws', files=fs)
With file And the corresponding file are key value pairs , Corresponding to relevant url On .
6)timeout: Set the timeout , Seconds per unit
You can set up a timeout Time , If in timeout Within time , Our request was not returned , Then there will be a timeout It's abnormal .
r = requests.request('GET', 'http://www.baidu.com', timeout=10)
7)proxies Field : Dictionary type , Set the access proxy server , You can add login authentication .
as follows , Use two agents , One is http The proxy used when accessing , User name and password settings can be added to the agent , Let's add another https Proxy server for , When we visit Baidu again IP The address is the proxy server IP Address , Using this field can effectively hide the source of users' crawling web pages IP Address information , It can effectively prevent the reverse tracking of reptiles .
import requests
pxs = {
'http': 'http://user:[email protected]:1234',
'https': 'https:10.10.10.1:4321'}
r = requests.request('GET','http://www.baidu.com', proxies=pxs)
8)allow_redirects:True/False, The default is True, Redirection switch ; This switch indicates whether to allow url Redirect .
stream:True/False, The default is True, Get content, download now switch .
verify Field :True/False, The default is True, authentication SSL Certificate switch .
sert: Is to save local SSL Field of the certificate path
1.2.2 get() Method
The simplest application method is r=requests.get(url), Construct a... That requests resources from the server Request object , Returns a... That contains server resources Response object , use r To represent all relevant resources returned .
The complete usage method contains three parameters :requests.get(url, params=None, **kwargs)
url: To get the page url link
params:url Extra parameters in , Dictionary or byte stream format , Optional
**kwargs:12 Parameters to control access
understand Response The coding : yes , we have header There is charset, That means there are coding requirements , It would be , But not all URLs can return this value , So the default code is ISO-8859-1, But this code cannot parse Chinese . When we use encoding When the content cannot be returned correctly , To use apparent_encoding To analyze the coding method from the content .
| attribute | explain |
|---|---|
| r.encoding | from HTTP header Guess the response content encoding method in |
| r.apparent_encoding | The encoding method of response content analyzed from content ( Alternative encoding ) |
You can pass the following code test :
import requests
r = requests.get('http://www.baidu.com')
# Check the status code
print(r.status_code)
print(r.text)
print(r.encoding)
print(r.apparent_encoding)
# Change the encoding , And the output
r.encoding = 'utf-8'
print(r.text)
1.2.3 Common code framework
Usually use get() function , The biggest function is to make users visit web pages more effective, stable and reliable .
Because the network connection is risky , Therefore, exception handling is very important ,Requests There are six common connection exceptions in the Library , The last one is trigger generation :
| abnormal | explain |
|---|---|
| requests.ConnectionError | Network connection error exception , Such as DNS The query fails 、 Refuse to connect, etc |
| requests.HTTPError | HTTP Error exception |
| requests.URLRequired | URL Missing abnormality |
| requests.ToolManyRedirects | Exceeded the maximum number of redirections , Generate redirection exception |
| requests.ConnectTimeout | Connection to remote server timeout exception |
| requests.Timeout | request URL Overtime , Generate timeout exception |
| r.raise_for_status() | If not 200, Cause abnormal requests.HTTPError |
The code framework is as follows ( If the state is not 200, trigger HTTPError abnormal , Judge whether the network connection is normal ):
def getHTMLText():
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ' Cause abnormal '
if __name__ == '__main__':
url = 'http://www.baidu.com'
print(getHTMLText())
1.2.4 HTTP Agreement and Requests Other methods
HTTP,Hypertext Transfer Protocol, Hypertext transfer protocol , It's based on “ Request and response ” Mode 、 Stateless application layer protocol . That is, the user initiates a request , The server responds , Stateless means that there is no correlation between the first request and the second request , Application layer protocol refers to that the protocol works in TCP The agreement above .
HTTP The agreement adopts URL As a sign to locate network resources .
URL The format is as follows :http://host[:port][path]
There are three fields after two backslashes ,host To express legitimate Internet Host domain name or IP Address ;port Represents the port number , The default port is 80;path Is the path to the requested resource .URL It's through HTTP Protocol access to resources Internet route , One URL Corresponding to a data resource .
HTTP Protocol operations on resources
| Method | explain |
|---|---|
| GET | The request for URL Location resources |
| HEAD | The request for URL Response message report for location resource , That is to get the header information of the resource |
| POST | Request to URL The location of the resource is followed by new data |
| PUT | Request to URL Location inch is a resource , Covering the original URL Location resources |
| PATCH | Request partial update URL Location resources , That is, to change part of the resources of the service |
| DELETE | Request to delete URL Location stored resources |
User pass GET perhaps HEAD Get all the information or header information , If you want to put your resources in URL Use the corresponding position PUT、POST、PATCH Method . When faced with huge resources , use PATCH You can only modify what you need , You can save bandwidth .
Use head() Method
requests.head(url,**kwargs)
**kwargs:13g Access control parameters
Use post() And other methods
towards URL POST A dictionary , The automatic code is form( Forms ), The string will default to data Next .
put() Methods and post() The method is similar to .
requests.post(url, data=None, json=None,**kwargs)
requests.put(url, data=None, **kwargs)
requests.patch(url, data=None, **kwargs)
requests.delete(url, **kwargs)
1.3 Robots agreement
Robots Exclusion Standard Exclusion criteria for web crawlers
effect : The website tells web crawlers which pages can be crawled , What can't be .
form : Under the root directory of the website robots.txt file .
After domain name , Input robots.txt, Such as https://www.taobao.com/robots.txt
Robots Basic protocol syntax :
User-agent:*
Disallow:/
* On behalf of all ,/ Represents the root directory
How to comply , Web crawlers should be able to identify automatically or manually robots.txt, Then crawl the content , The reptiles are good , The Bureau entered early , It's better to abide by the rules . Of course, if the number of visits is small , Not involving commercial interests , If it is not illegal, it can still not be observed .
1.4 First try
1.4.1 Try to crawl the commodity information of Taobao, jd.com and other websites
import requests
url1 = 'https://item.taobao.com/item.htm?id=638296572648'
url2 = 'https://item.jd.com/100023800830.html'
try:
kv = {
'user-agent': 'Mozilla/5.0'}
r = requests.get(url2, headers=kv)
# Check the status code
print(r.status_code)
# View encoding
print(r.encoding)
print(r.request.headers)
r.raise_for_status()
print(r.text[:10000])
except:
print(' Crawling failed ')
1.4.2 Try to submit information to the search engine , And return the content
Baidu keyword interface :
https://www.baidu.com/s?wd=keyword
360 Keyword interface :
https://so.com/s?q=keyword
good heavens , Baidu search will have security verification , Then I tried bing Search for
import requests
url = 'https://cn.bing.com/search'
kv1 = {
'q': 'python'}
try:
kv = {
'user-agent': 'Mozilla/5.0'}
r = requests.get(url, headers=kv, params=kv1)
r.encoding = r.apparent_encoding
r.raise_for_status()
print(r.text[:20000])
except:
print(' Crawling failed ')
Then I simply tried jd.com to search for items , just so so , Although I don't know why two parameters are ok , One is wrong , It shows that login is required .
import requests
url1 = 'https://search.jd.com/Search'
kv1 = {
'wq': ' men's wear ', 'keyword': ' men's wear '}
try:
kv = {
'user-agent': 'Mozilla/5.0'}
r = requests.get(url1, headers=kv, params=kv1)
r.raise_for_status()
print(r.text[:20000])
except:
print(' Crawling failed ')
1.4.3 IP Automatic search of address home
This is OK , It is necessary to figure out what key fields to fill , Like others IP Query the website may not be submitted in this way .
import requests
url1 = 'https://m.ip138.com/iplookup.asp?ip='
try:
kv = {
'user-agent': 'Mozilla/5.0'}
r = requests.get(url1+'202.204.80.112', headers=kv)
r.encoding = r.apparent_encoding
r.raise_for_status()
print(r.text[:20000])
except:
print(' Crawling failed ')
2 Beautiful Soup library
2.1 Install library and call
Installation or use conda install beautifulsoup4
But it should be noted that when calling ,from bs4 import BeautifulSoup
Use one html Web page to demonstrate , get HTML Source code
How to get the source code :
- Get it manually on the web
- requests.grt() To get
import requests
from bs4 import BeautifulSoup
url1 = 'http://python123.io/ws/demo.html'
try:
kv = {
'user-agent': 'Mozilla/5.0'}
r = requests.get(url1, headers=kv)
demo = r.text
# give demo, At the same time, the interpreter , Here is HTML Interpreter
soup = BeautifulSoup(demo, 'html.parser')
print(soup.prettify())
r.raise_for_status()
print(r.text[:20000])
except:
print(' Crawling failed ')
Therefore use bs4 Just two lines
from bs4 import BeautifulSoup
soup = BeautifulSoup('<p>data</p>', 'html.parser')
The first parameter is the one we need to parse html Format information , The second is the parser .
2.2 soup The basic elements of the library
Beautiful Soup Class
| The basic elements | explain |
|---|---|
| Tag | label , The most basic information organization unit , Use them separately <> and </> Mark the beginning and the end |
| Name | Name of label ,<p>… The name of is ’p’, Format :<tag>.name |
| Attributes | Attributes of the tag , Dictionary organization , Format :<tag>.attrs |
| NavigableString | Non attribute string in tag ,<>…</> Middle string , Format :<tag>.string |
| Comment | The comment part of the string in the tag , A special kind Comment type |
Get title label content soup.title
Get link tags soup.a, In this way, only the first tag content can be obtained
How to get the tag name soup.a.name
You can also check that the father of the tag is soup.a.parent.name
You can also continue to look up , Use .name To get the name , Use .parent.name Look at the parent class , Output as a string
View the attribute information of the tag , The attribute of the label is the relevant area in the label that indicates the characteristics of the label , Organize... In dictionary form , The attribute name and the key value pair of the attribute are given , You can use a dictionary to extract each attribute ,soup.a.attrs
View label types ,type(soup.a), See how label types are defined :<class 'bs4.element.Tag'>.
tag Labels can have 0 One or more properties , Use when there are no attributes .attrs The obtained dictionary is empty , But you can get a dictionary with or without attributes .
obtain Tag Labeled NavigableString attribute , That is, the content between the two angle brackets , Use soup.a.string, The type of <class 'bs4.element.NavigableString'>
Again html Use in <!..> To represent a comment , The output comment section can be used .string To output , Check its type to confirm .
2.3 be based on bs4 Of HTML Content traversal method
Need to be right HTML Understand the basic format .
Understand the basic format , You can understand several traversal methods :
- The downward traversal mode from the root node to the leaf node
- The uplink traversal mode from the leaf node to the root node
- Traverse each other between peer nodes
Pictured :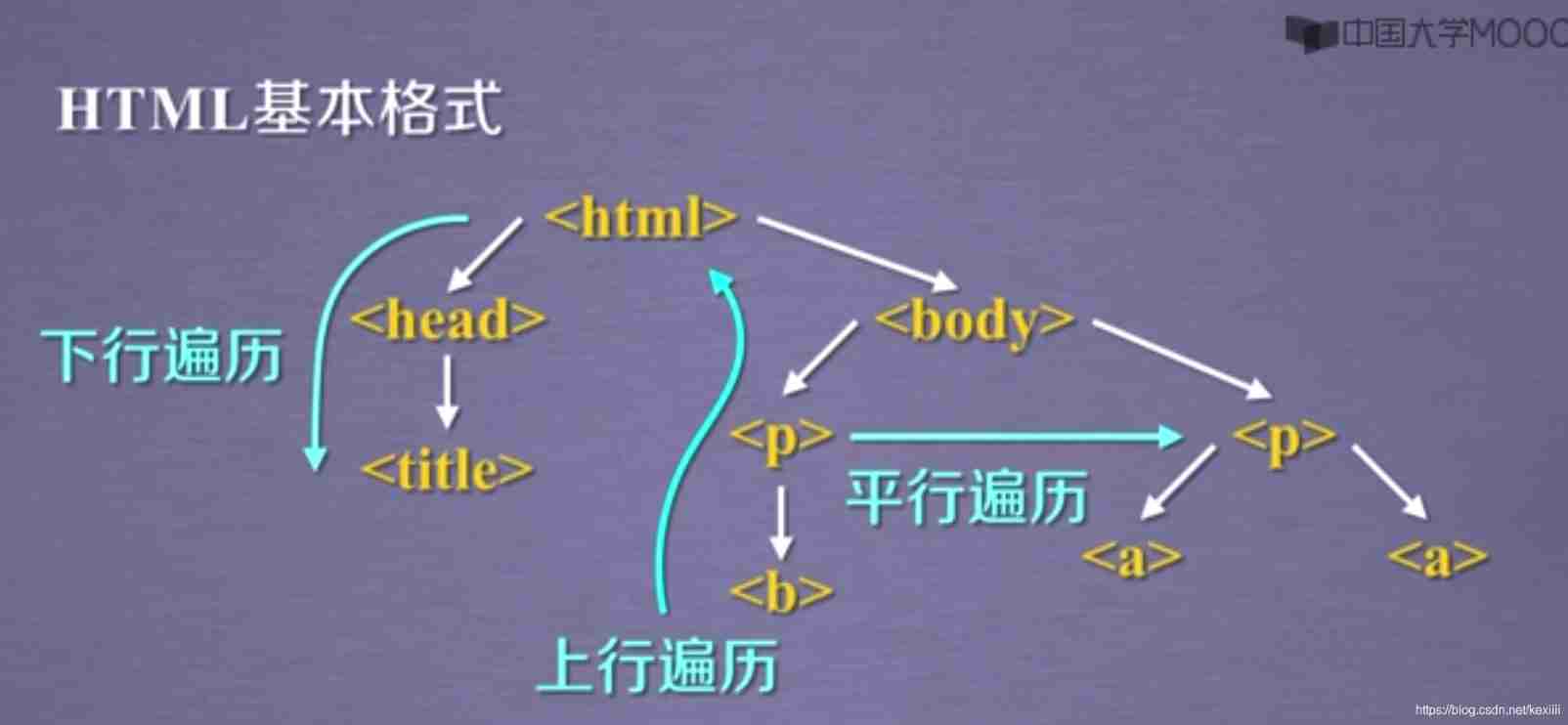
2.3.1 Down traversal
The downstream traversal of the number of tags contains three attributes
| attribute | explain |
|---|---|
| .contents | List of child nodes , take <tag> All child nodes are put into the list |
| .children | The iteration type of the child node , And .contents similar , Used to loop through the child nodes |
| .descendants | The iteration type of the descendant node , Include all descendant nodes , For loop traversal |
For the child node of the label, it includes not only the label node , It also includes string nodes , such as '\n'
Traverse the way :
for child in soup.body.children:
print(child)# Traverse the son node
for child in soup.body.descendants:
print(child)# Traversing child nodes
2.3.2 Up traversal
Two properties of uplink traversal
| attribute | explain |
|---|---|
| .parent | The parent tag of the node |
| .parents | Iteration type of node ancestor label , Used to loop through the predecessor nodes |
Label tree upstream traversal code
soup = BeautifulSoup(demo, 'html.parser')
for parent in soup.a.parents:
if parent is None:
print(parent)
else:
print(parent.name)
When traversing all the ancestor tags of a tag , Will traverse to soup In itself , and soup Our ancestors did not exist .name Information about , So we need to make a distinction , If our ancestors were none, We can't print this information .
2.3.3 Parallel traversal
beautifulsoup4 The library provides a total of 4 Parallel traversal properties :
| attribute | explain |
|---|---|
| .next_sibling | Back according to HTML Next parallel node label in text order |
| .previous_sibling | Back according to HTML The label of the previous parallel node in the text order |
| .next_siblings | Iteration type , Back according to HTML All subsequent parallel node labels in text order |
| .previous_siblings | Iteration type , Back according to HTML The text order is preceded by all parallel node labels |
The parallel traversal of the number of tags is conditional , All parallel traversals must occur under the same parent node , If the labels under the same parent node do not form a parallel traversal relationship . In our data structure ,title and p The label is not , and body Of the two p Labels are parallel labels .
Because of existence NavigableString The string in the element is also regarded as a node , The parallel nodes corresponding to labels in turn are not necessarily labels .
Parallel traversal :
for sibling in soup.a.next_siblings:
print(sibling)# Traversing subsequent nodes
for sibling in soup.a.previous_siblings:
print(sibling)# Traverse the preceding nodes
2.4 be based on bs4 Library HTML Format and code
- Also is to let html The content is displayed more friendly
bs4 The library providesprettifyMethod , Each label and content can be displayed separately . Be able to soup Handle , It can also handle each label .soup.prettify()perhapssoup.a.prettify(). - Coding problem :bs4 How the library will be read html Files or strings are converted to UTF8 code , Yes python3.x The default encoding of the series is consistent .
2.5 Information organization and extraction methods
2.5.1 Three forms of information mark
General types of information markers :
XML、JSON and YAML
- XML It's Extended Markup Language , And HTML near ; The way of information expression based on labels ,
<name>...</name>perhaps<name />When the content is empty, a pair of angle brackets can be used , You can also insert notes<!-- --> - JSON (JavaScript Objext Notation) That is, it is JavaScript An expression of object-oriented information in ; There are types of key value pairs to build information expression , A typed string is quoted in double quotation marks , The numbers are not etc. .
key : value, When multiple values are usedkey : [ value 1, value 2], Key value pairs can be nested , Use at this time {,} In the form of . It is generally used where the program deals with interfaces , Can be part of the program code , And is directly run by the program , The defect is that the annotation cannot be reflected . - YAML (YAML Ain`t Markup Language), Its full name is a recursive definition , The typeless key value pairs are used to build , That is to say There are no double quotes for either keys or values , Describe the relationship in indented form ; Use the minus sign to express the coordinate relationship ; A key may correspond to multiple values , Then use a minus sign before each value to indicate juxtaposition ; Use vertical line | To represent the whole block of data , Across multiple lines or with a large amount of information , use # Notation , Key value pairs can be nested . At present, it is mainly used in the configuration files of various systems , It's easy to read with notes .
2.5.2 The general method of information extraction
1) The tag form of complete parsing information , Then extract the key information
Need to tag parser , As before html The parser , Use bs4 Tag tree to traverse .
2) Ignore the sign form , Search for key information directly ( Text lookup function , Such as find_all() Method )
3) Of course, the best is to combine , Combining formal parsing and search methods , Extract key information .
example : extract html All in URL link
Ideas : First step : Search all <a> label
The second step , use <a> Parsing format of tag , extract href attribute , Get linked content
from bs4 import BeautifulSoup
url1 = 'http://python123.io/ws/demo.html'
try:
kv = {
'user-agent': 'Mozilla/5.0'}
r = requests.get(url1, headers=kv)
demo = r.text
soup = BeautifulSoup(demo, 'html.parser')
for link in soup.find_all('a'):
print(link.get('href'))
r.raise_for_status()
except:
print(' Crawling failed ')
2.5.3 be based on bs4 Library HTML Content search method
1)
bs4 The library provides a way to find <>.find_all(name, attrs, recursive, string, **kwargs), This method can be found in soup Search for information in the traversal of , Returns a list type , Store search results .
- name: Refers to the retrieval string of the label name . such as
soup.find_all('a'), Output a containing all a List of tags ; If you look for two tags , Then you can usesoup.find_all(['a', 'b']), Pass as the first parameter in the form of a list . If the label name we give is true, The current... Will be displayed soup All tag information for . - sttrs: Is the search string for the tag attribute value , Can label attribute retrieval , It can retrieve whether the attribute of the tag contains some character information , Such as
soup.find_all('p', 'course')To check p Whether the label contains course character string , Return a list , It is given with course Property value p label ; You can also directly make relevant conventions on attributes , example : lookup ID Attribute is equal to the link1 As a lookup element ,soup.find_all(id='link1'), If there is no such label , Then an empty list will be returned . - recursive: Is a Boolean value , Indicates whether to search all descendants , The default is true, If you only want to search for things at the node level of your son , It can be changed to false.
- string: Refers to the string parameter that retrieves the string field in the middle of the label ;
soup.find_all(string = re.compile('python'))
2)
because find_all() Functions are common , So in bs4 There are abbreviations in the Library :<tag>(...) Equivalent to <tag>.find_all(...), Yes soup The same is true of variables , Change the label to soup that will do .
3) also find_all() Method extension method
| Method | explain |
|---|---|
| <>.find() | Search and return only one result , String type , Same as .find_all() Parameters |
| <>.find_parents() | Search the predecessor node for , Return list type , Same as .find_all() Parameters |
| <>.find_parent() | Return a result in the predecessor node , String type , Same as .find() Parameters |
| <>.find_next_siblings() | Search for... In subsequent parallel nodes , Return list type , Same as .find_all() Parameters |
| <>.find_next_sibling() | Return a result in the subsequent parallel nodes , String type , Same as .find() Parameters |
| <>.find_previous_siblings() | Search the preceding parallel nodes , Return list type , Same as .find_all() Parameters |
| <>.find_previous_sibling() | Return a result in the preceding parallel node , String type , Same as .find() Parameters |
3 bs4 example - Chinese universities rank directional reptiles
3.1 Basic information of the instance
Use the ranking website of Shanghai Jiaotong University to query :https://www.shanghairanking.cn/rankings/bcur/2021
Input : University Rankings URL link
Output : Screen output of university ranking information ( ranking 、 University name and total score )
technology roadmap :requests-bs4
Directional reptiles : For input only URL To climb , Do not extend crawl .
Programming :
step 1: Get university rankings from the web , Defined function get_html_text()
step 2: Extract information from web content to a suitable data structure , Defined function text_to_list()
step 3: Use data structure to display and output results univ_list_print()
Looking at the source code, we found that , Ranking information is stored in <tbody data-v-3ba213b8=""> In this table label , In which the , All the information of every university is encapsulated in <tr><\tr> in , Every message is <td><\td> Contains . So we need to find tbody label , And then again tbody Parsing in the tag tr label , And then tr In the tag td Find the label , Find relevant information and put it in the list .
3.2 Code writing
#!/usr/bin/python
import requests
from bs4 import BeautifulSoup
import bs4
def get_html_text(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print(' Crawling failed ')
return ''
def text_to_list(univ_info, html):
soup = BeautifulSoup(html, 'html.parser')
# lookup tbody label , And make a traversal of its children
for tr in soup.find('tbody').children:
# Exclude other information of non label classes of other nodes , Like strings
if isinstance(tr, bs4.element.Tag):
# Get one of them td Label content
tds = tr('td')
univ_info.append([tds[0].text.strip(), tds[1].text.strip(), tds[4].text.strip()])
def univ_list_print(univ_info, num):
print('{:^10}\t{:^16}\t{:^10}'.format(' ranking ', ' School name ', ' Total score '))
for i in range(num):
u = univ_info[i]
print('{:^10}\t{:^16}\t{:^14}'.format(u[0], u[1][:8], u[2]))
def main():
univ_info = []
url = 'https://www.shanghairanking.cn/rankings/bcur/2021'
html = get_html_text(url)
text_to_list(univ_info, html)
univ_list_print(univ_info, 20) # 20 school
if __name__ == '__main__':
main()
1) Because the content of the tutorial was many years ago , So some things need to be changed , For example, the td The method of transferring label content into the list needs to be changed , The tutorial uses .string But because of the change of the website , Will style="display:none" Also pass in the list , There will be a mistake :TypeError: unsupported format string passed to NoneType.__format__
I went online to find a solution : Problem solving :TypeError: unsupported format string passed to NoneType.format
Qiangwa !CSDN God forever !
2) At first, I found that the error report was AttributeError: 'NoneType' object has no attribute 'children', Yes , A lot of mistakes , one by one , I read what the Internet said , They actually made a mistake in the first function , But the first function uses try-except To solve abnormal problems , So return an empty list , Cause subsequent problems , No descendants . They are timeout Wait for the key words to be written incorrectly , I looked and found that some of the code I debugged blindly at the beginning was not deleted , Hahahaha, this problem has been solved , I also reacted when I saw that it was an empty list , So I am except Exception handling has added statements :print(' Crawling failed ').
3) When outputting the name of the University , I found that a lot of strings were output , There is a university name followed by the English name of the University and the University label , Later, check the source code , Found that the name of the university is just <a><\a> In the label ; So there is a solution : This method looks orthodox , take a The content of the label is exported separately , Incoming list . The second way is , When I look at the output , Directly intercept the front string . Smile to cry , I want to be convinced of my wit .
4) The output table will still be uneven , Mainly because some universities have too long names 了 , It's a little uncomfortable for obsessive-compulsive disorder , terms of settlement : The source is from the brother above , I really can't .
tplt = "{0:^10}\t{1:{3}^12}\t{2:^10}"
# 0、1、2 For slot ,{3} Means if the width is not enough , Use format Of 3 At position No chr(12288)( Chinese space ) Fill in
print(tplt.format(" ranking "," School name "," Total score ",chr(12288)))
3.3 Optimize the implementation
1) The above solution is the output of university name def text_to_list(univ_info, html): The content of this function is modified as follows
afile = tr('a')
tds = tr('td')
univ_info.append([tds[0].text.strip(), afile[0].string, tds[4].text.strip()])
function def univ_list_print(univ_info, num): modify
def univ_list_print(univ_info, num):
print('{:^10}\t{:^16}\t{:^10}'.format(' ranking ', ' School name ', ' Total score '))
for i in range(num):
u = univ_info[i]
print('{:^10}\t{:^16}\t{:^14}'.format(u[0], u[1], u[2]))
2) Alignment issues
format Relevant conventions in methods
| : | < fill > | < alignment > | < Width > | , | <. precision > | < type > |
|---|---|---|---|---|---|---|
| Leading symbols | A single character for padding | < Align left > Right alignment ^ Align center | Set output width of slot | The thousands separator for numbers is for integers and floating-point numbers | The precision of the floating-point mouse part or the maximum output length of the string | Integer types b c d o x X Floating point type e E f % |
Output Chinese characters , When the width of Chinese characters is not enough , Fill in with Western characters ; Chinese and Western characters occupy different widths .
Optimize 1:
Chinese characters are not wide enough , Use Chinese characters to fill
Ow ! Fill in with spaces of Chinese characters chr(12288)( This is utf-8 Code the space corresponding to Chinese characters )
Typesetting is very comfortable ( Adjust the left alignment and character width as shown in the following figure )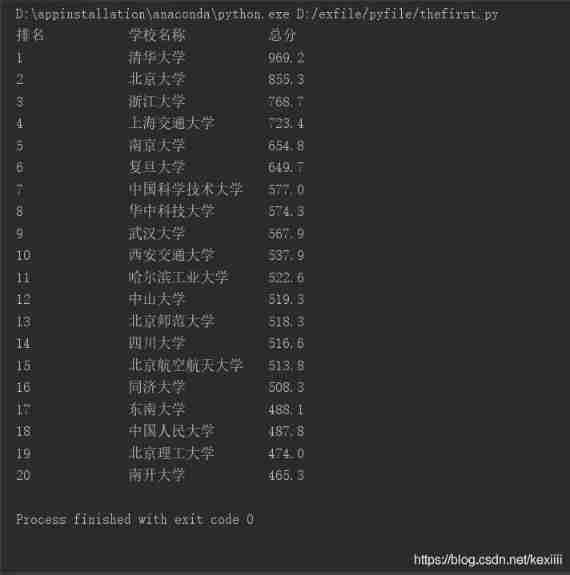
边栏推荐
猜你喜欢
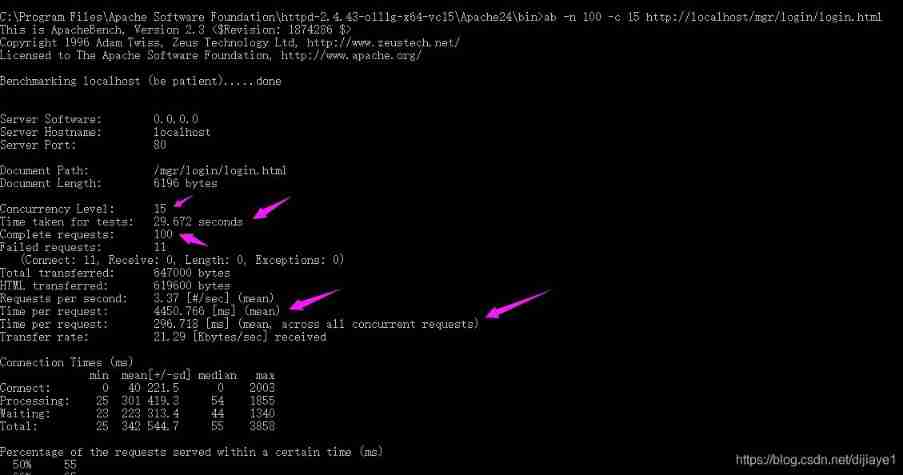
Day01 preliminary packet capture
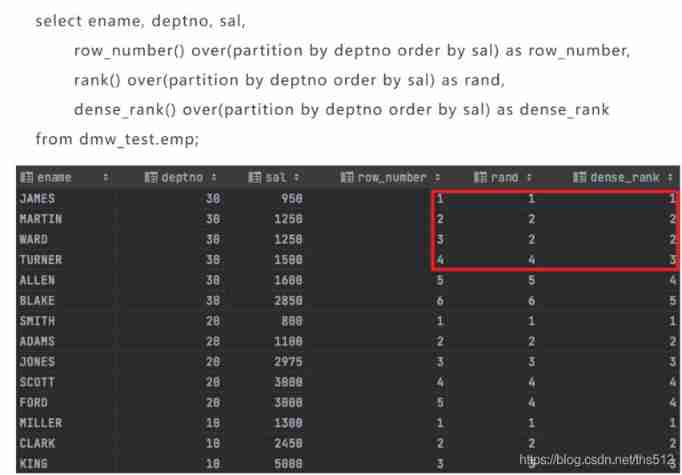
Analysis function in SQL
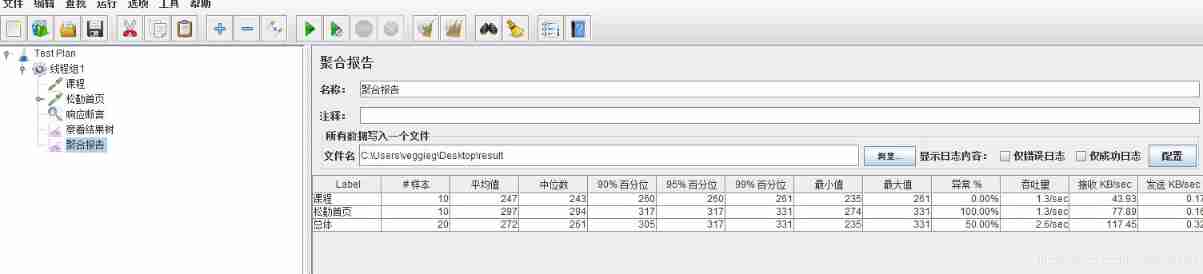
JMeter Foundation
Oracle11g | getting started with database. It's enough to read this 10000 word analysis
Ten key performance indicators of software applications
Replace() function
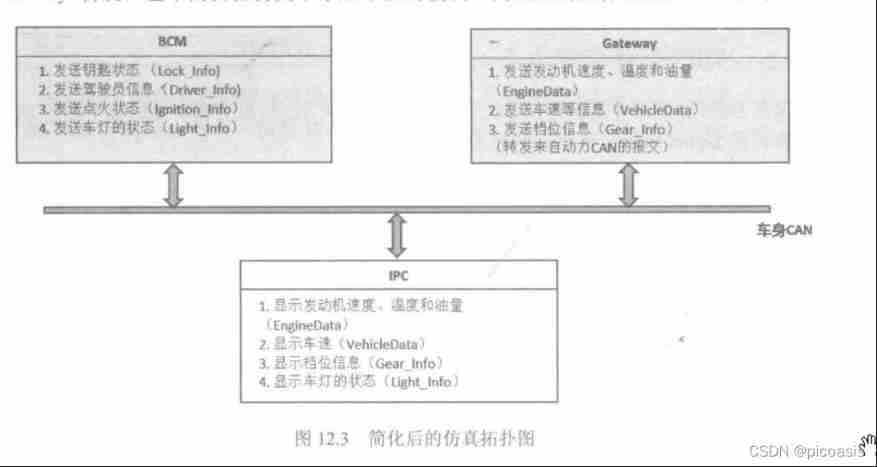
Canoe - the third simulation project - bus simulation - 2 function introduction, network topology
Properties and methods of OS Library
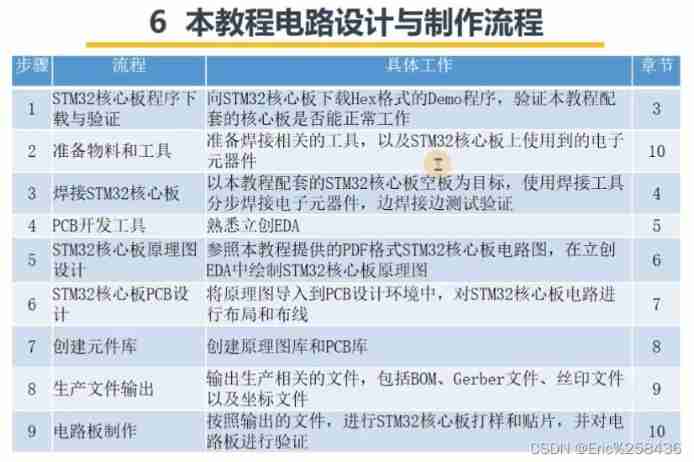
Introduction to Lichuang EDA
Login operation (for user name and password)
随机推荐
unit testing
Local MySQL forgot the password modification method (Windows)
thread
Introduction to Lichuang EDA
Analysis function in SQL
Design and common methods of test case documents
For and while loops
Heartbeat error attempted replay attack
Using terminal connection in different modes of virtual machine
Install freeradius3 in the latest version of openwrt
Strings and characters
Automatic translation between Chinese and English
Summary of Shanghai Jiaotong University postgraduate entrance examination module firewall technology
If function in SQL
Configure SSH key to realize login free
QQ get group settings
Foreach (system.out:: println) usage
LxC shared directory addition and deletion
The most ideal automated testing model, how to achieve layering of automated testing
Fundamentals of software testing