当前位置:网站首页>多线程应用的测试与调试
多线程应用的测试与调试
2022-07-06 05:58:00 【瞻邈】
测试和调试就相当于一个硬币的两面——测试代码寻找错误,调试代码纠正错误。幸运的话,你自己调试出所有的错误,而不是让使用该应用的人发现代码漏洞。在我们介绍测试和调试之前,重要的是理解可能会出现哪些问题,让我们先来看看这些问题。
1. 并发相关错误的类型
1.1. 不必要的阻塞
不必要的阻塞是什么意思?首先,线性阻塞是指线程因为要等待某些条件(互斥元、条件变量、时间等)无法继续运行时所处的状态。多线程代码中,常用]些条件,而这些条件常常无法获得满足,因此就出现了不必要的阻塞问题。我们着又会提出下一个问题:为什么这个阻塞是不必要的?因为有其他一些线程在等该阻塞的线程执行一些动作,如果该线程阻塞的话,其他线程也势必阻塞。不必的阻塞又分成以下几种。 不必要的阻塞 活锁——当第一个线程等待第二个线程时,而这第二个线程又在等第一个线)情况时,活锁类似于死锁。活锁与死锁的关键不同在于等待过程不是一个阻;状态而是一个不断的循环检测状态,如自旋锁。严重时,活锁的症状就像死(应用不会执行任何进程),不同仅在于 CPU此时的利用率非常的高,因为现;还在不断的运行检测,只因相互等待而阻塞。不太严重时,当某个随机事件;生时,活锁可能会被解锁,但是,活锁会导致任务较长时间得不到执行,并!在这期间 CPU利用率高。
1.1.1. 死锁
死锁是指第一个线程在等待第二个线程执行后才继续,而第二个线程又在等待第一个线程,如此构成一个线程等待循环状态如果你的线程死锁了,那你的程序将无法继续执行下去。在许多可以预见的况下,多线程中的某一线程是负责与用户接口交互的,在死锁情况下,用户接口会停止应答。而在其他情况下,用户接口仍会应答,只不过有些必要的任无法得到执行,如不会返回搜索结果或者不会打印文件等。
1.1.2. 活锁
当第一个线程等待第二个线程时,而这第二个线程又在等待第一个线程情况时,活锁类似于死锁。活锁与死锁的关键不同在于等待过程不是一个阻塞状态而是一个不断的循环检测状态,如自旋锁。严重时,活锁的症状就像死锁(应用不会执行任何进程),不同仅在于CPU此时的利用率非常的高,因为现在还在不断的运行检测,只因相互等待而阻塞。不太严重时,当某个随机事件发生时,活锁可能会被解锁,但是,活锁会导致任务较长时间得不到执行,并且在这期间 CPU利用率高。
1.1.3. 在I/O 或其他外部输入的阻塞
当你的线程阻塞是因为等待某外部输入而无法继续执行,可能这个外部输入永远都不到来,那么这种阻塞就称之为基于等待I/O 或其他外部输入的阻塞。因此,不希望出现一个线程因等待外部输入而阻塞,其他线程有因为要等待这个线程的运行而阻塞的情况出现。
1.2. 竞争条件
竞争条件是多线程代码中的问题最常见的原因——许多死锁和活锁实际上是竞争条件的表现。并不是所有的竞争条件都是有问题的,竞争条件发生的时间取决于各个独立线程操作的先后顺序。许多竞争条件是有益的。例如,到底哪个线程来处理任务队列中的下一个任务是不确定的。然而,许多并发错误的产生是由于竞争条件。竞争条件常常产生下面几种错误类型。
1.2.1. 数据竞争
数据竞争是一种特殊的竞争条件。因为没有同步好对某个共享内 存的并行访问,因此,数据竞争会造成未定义的操作出现。当错误地使用原子操作来同步线程或者想通过共享数据来避免互斥元死锁时,常常会发生数据竞争。
1.2.2. 破坏不变量
常常表现为悬挂指针(因为另一个线程删除了被访问的数据)、随机存储损坏(线程由于局部更新而造成的读取数据不一致)或者双闲状态(如当两个线程从同一队列中弹出相同的值,并且这两个线程因此而删除一些相关数据)等。破坏不变量常指不变量在时间或数值上的改变。如果多个线程要求以特定的顺序执行,那么不正确同步可能会产生由于线程执行顺序错误而引起的竞争条件。
1.2.3. 生存期问题
人们常常会将生存期问题归结为破坏不变量问题,但实际上生存期问题是竞争条件产生的另一个独立的问题分类。在这个分类中的错误的基本问题是线程会超时访问某些数据,而这些数据可能已经被删除、销毁或者访问的内存其实已经被另一个对象重用。当一个线程要参考某一局部变量,而这个局部变量已经不在该线程访问能力之内了,这样就会造成生存期问题。 当线程的生存时间与它可以操作的数据之间没有某种限制规则时,那么,就极有可能出现在线程结束之前该数据就已被销毁,而造成线程访问错误的问题。如果在线程中调用 join()来让数据等到线程完成后再销毁,那你需要保证当发生异常时,可以跳过join()函数的执行,这是线程异常的基本安全保障。
竞争条件是问题杀手。死锁和活锁会导致任务长时间得不到执行。通常,你可以添加一个调试器来运行区分哪些线程陷入死锁或者活锁,并且哪些并发对象是相互矛盾的。
在整个代码的任何地方都可能出现上面介绍的数据竞争、破坏变量和生命周期的问题的症状(如随机崩溃或者不正确的输出),代码可能会重写后面其他程序可能会用到的内存,导致编译出错。编译给出的错误定位往往完全与出错代码无关,可在程序执行很久后,才能暴露该错误。这类错误往往是由共享系统内存造成的,就算你小心翼翼地试图指定某线程访问某数据,并且保证正确同步,但是,任何线程都有可能重写应用程序中其他线程需要使用的数据。
至此,我们简要明确了我们将要遇到的错误类型,下面让我们看看,我们该怎样来定位错误实例,并解决它们。
2. 定位并发相关的错误的技巧
就算是检阅你自己的代码,你还是可能会漏掉一些错误。因此,无论何时,你都要确保你的代码可以执行,即使代码无法顺利执行,你也要保持平和的心态。因此,我们会介绍一下与检阅代码相关的一些多线程测试和调试技巧。
2.1. 审阅代码以定位潜在的错误
当检阅多线程代码来纠正并行相关的错误时,彻底仔细地阅读非常重要,要像一把细齿梳子一样仔细地阅读代码。如果可能让他人帮你检阅你的代码,因为他们没有参与代码的编写,他们不得不想清楚代码是如何工作的,因此,会发现很多遗漏的错误。这需要代码的阅读者有充足的时间来仔细负责地检阅代码,而不是简单快速地过一遍。大多数并行错误不是简单快速的扫视代码所能发现的,这些错误往往需要微妙的时机才会出现。
如果你让你的同事帮你检阅你的代码,这个代码对他来说是完全陌生的。因此,他们会从不同的视角来看问题,并指出一些你未发现的错误。如果你找不到同事帮你检阅代码,你可以找朋友帮忙,甚至将代码发到网络上寻求帮助。如果你实在找不到人帮你检阅代码,或者,他们也无法找出问题,别急,你还可以这么做。对于初学者来说,将代码搁置一段时间,去做其他事情,如编写该程序的其他部分、读书、散步等。在这段时间内,当你集中精神做其他事时,你的潜意识还在想着这个问题。同时,当你重新回到该代码时,代码已经不那么熟悉了,这样你可能就会以一种不同的视角来检阅你的代码。
让别人审阅代码的替代方法是自己审阅。一个有用的技巧是试图解释它是如何工作的细节给别人。这个别人甚至可以不是实体的人,如布偶熊或橡胶鸡,我个人认为编写详细的注释极有帮助。你要解释,每一行代码有什么作用,会发生什么,访问的数据等。你要不断地自我提问并解释回答。
审阅多线程代码时需要思考的问题
下面列出一些具体的而非全部的,我喜欢问的一些问题。你也可以找到其他一些你比较关注的问题。不再多说了,先将这些问题列出以便参考。
- 哪些数据是需要保护,防止并行访问的?
- 如何保证你的数据是被保护的?
- 此时其他线程执行到代码的何处?
- 该线程用的是哪些信号量?
- 其他线程持有哪些信号量?
- 该线程各操作之间有先后顺序的要求吗?在其他线程中存在这样的问题吗?这些要求如何强制执行?
- 该线程载入的数据是否有效?该数据是否已经被其他线程修改了?
- 如果你假设其他线程可能正在修改该数据,那么可能会导致什么样的后果以及如何保证这样的事情永不发生?
最后一个问题是我最喜欢问的问题,因为它确实能帮我理清楚线程之间的关系。通过假设某行代码存在错误,你就可以像个侦探一样追查原因。为了说服你自己,代码没有错误,你需要考虑到所有情况和可能排序。当数据在其生命期内受多个信号量保护时,这个方法非常有用。
列举的倒数第二个问题同样也很重要,因为它解决了一个常常会犯的简单错误,如果你释放后再重新获取该信号量你必须假设其他线程已经修改了该共享数据。很明显,如果互斥锁因为它们对于对象来说是内部的不是立即可见的一你可能在不知不觉中就那么做了。
2.2. 通过测试定位并发相关的错误
开发单线程应用时,应用测试比较简单耗时。首先,你需要区分所有可能的输入数据集(至少包括一些典型的输入测试集)并且对这些输入数据集进行测试。如果应用程序能够正确执行并且产生正确的输出,说明这个应用程序对于给定的输入集能够正常运行。如果测试到错误状态,处理则会比正确运行的情况复杂。但是,基本思想是相同的——建立初始化条件执行应用程序。
测试多线程代码相对于单线程来说难得多,因为合理的调度线程是不确定的,因此线程调度的差异会导致运行的变化。因此,即使应用程序运行同一组输入数据,如果代码中潜伏有竞争条件的话,仍然有可能会导致有时运行正确有时运行出错。因为有潜在的竞争条件并不意味着代码执行总是失败,仅仅是有时有可能会失败。
鉴于固有的难以再现并发相关的错误,因此,需要仔细地设计测试程序。你希望每次测试能够确定问题可能存在的最少的代码,那么当测试失败时,你就可以更好地隔离出错代码——测试并行队列最好能够直接测试并行压栈和出栈工作而不是测试使用并行队列的整个代码块。
我们值得通过测试消除并发来证明问题是并发相关的。如果你让所有程序运行在一个线程时出错,该错只是一个普通的错误而非一个并发相关的错误。追踪错误的初始发生位置而不是被你的测试工具测试发现的错误位置是非常重要的。这是因为即使错误发生在你应用的多线程部分,也并不意味着它就是并发相关的。如果你使用线程池来管理并发等级,通常你可以通过设置配置参数来指定工作线程。如果你手动地管理线程,你就需要修改代码以便使用单个线程测试来进行测试。一方面,你可以将你的线程减少到一个,这样就可以根除并发;另一方面,如果在单核系统中没有错误(即使是一个多线程应用),但是在多核系统或多处理器系统中出错,那么就是竞争条件错误和可能同步或内存顺序错误。
2.3. 可测试性设计
测试多线程代码是困难的,所以你会想怎样才能使代码易于测试呢?你能做的最重要的事情之一就是设计易于测试的代码。现有设计易于测试代码的技术大都用于单线程代码,但是,其中许多技术也同样可以应用多线程。通常,做到以下几点后,代码就比较易于测试了。
- 每个函数功能和类的划分清晰明确。
- 函数扼要简洁。
- 你的测试代码可以完全控制你的被测试代码的周围的环境。
- 被测试的需要特定操作的代码应该集中在一块而不是分散在整个系统中。
- 在你写测试代码之前你要先考虑如何测试代码。
所有以上提到的都可以应用在多线程代码中。事实上,我认为上述几点更多的应用于解决多线程代码的易测性而非单线程代码的易测性。上述最后一条非常重要,即使你编写应用代码之前,此时还远没有到写测试代码的那一步,在你编写应用代码之前也有必要考虑怎样测试它——使用什么样的输入,哪些条件下可能会出错,怎样找到代码潜在的错误等。 设计易干测试的并行代码最好的方法之一就是消除并发。如果你可以将代码分割成多个部分来负责要操作的通信数据与多个线程之间的通信路径,这样,你就极大地减少了问题。操作被一个单线程访问的数据时的这些应用部分可以使用正常的单线程技术来进行测试。这样,那些难以测试的用于处理线程之间通信和确保一个时间内仅有一个线程访问特定数据块的并发代码部分就变得比较少,测试出现错误时,也更加容易进行追踪错误源头。
例如,如果你的应用被设计成一个多线程的的状态机,那么你就可以将它分解成多个部分。用于为每个可能的输入集确保状态转换和操作的正确性的线程的状态逻辑可以通过单线程技术独立的进行测试,并且通过测试工具提供的测试输入集,可以同样应用到其他线程。接着,通过测试代码中特别设计多并发线程和简单的状态逻辑,核心状态机和确保各事件按正确的顺序到达正确的线程的信息路由的代码可以独立的进行测试。
可选地,如果你将代码分解成多个代码块,读共享数据/迁移数据/更新共享数据,你可以使用所有的单线程技术来测试迁移数据代码块部分,因为此时这部分代码仅是一个单线程代码。测试一个多线程迁移困难的问题可以降级为测试读共享数据块和更新共享数据块中的一个,哪个简单选哪个。
需要注意的是库函数调用能够使用内部变量来存储状态,然后,如果多个线程使用相同的库函数调用集在多线程之间实现共享。因为代码访问共享数据不是立即表现出来的,因此,多线程的共享还存在一些问题。然而,随着你对这些库函数调用的学习,多线程共享仍然是个问题。这时,你要么添加适当的保护和同步或者使用可替代的对于多线程的并行访问来说安全函数。
2.4. 多线程测试技术
你需要思考你想要测试的场景并且编写一些小的代码来测试函数功能。那么,你怎样确保那些存在潜在的问题的时间调度通过小的测试练习解决它的潜在错误呢? 事实上,有许多方法可以做到这点,如暴力测试或者压力测试。
2.4.1. 暴力测试
暴力测试的核心思想是穷举所有可能情况看代码是否能够正常而不出现错误。最典型的方法是多次运行代码,并且尽可能地一次运行多个线程。如果一个错误仅在多个线程以某一特定顺序运行时出现,那么运行的代码越多,出错的可能性就越大。如果你仅测试一次并且通过了测试,你可能自信地以为代码没有问题,能够工作。如果你一批运行十次并且每次都能通过测试,你就会更加自信。如果你测试了十亿次,并且每次都通过测试,那你就会对你的代码自信无比。
你的自信程度取决于你通过测试的次数。如果你的测试结果非常精确,测试甚至可以精确地概括到线程安全队列的话,这样的穷举测试会让你对自己的代码无比自信;另一方面,如果被测试的代码非常的多,可能的排列数非常多,运行即使十亿次也仅会产生一点点自信。
穷举测试的缺点是它可能会让人产生盲目的自信。可能你编写的测试环境不会产生错误,就算你运行多次也不会出现错误,但是,换一个稍微不同的环境就会每次测试都出错。最坏的情况就是在你的测试系统中不会出现有问题的测试环境因为你测试是在一个特殊的环境。除非你的代码运行的环境与你代码测试运行的环境一模一样,并且相应的硬件和操作系统也不会引起任何错误出现。
这里给出的一个典型的例子就是在一个单处理系统上测试一个多线程应用。因为每个线程都要求运行在同一个处理器上,所有的任务都是自动串行进行的,那么在多处理器上可能遇到的许多竞争条件和双向缓存问题在单处理器系统中都不复存在了。这不仅仅是变量的问题;不同的处理器体系结构产生不同的同步和设备时序问题。
2.4.2. 组合仿真测试
组合仿真测试是指在一种特殊的仿真代码真实运行环境的软件上运行你的代码。你将注意到这个软件允许你在一个单物理计算机上运行多个虚拟机,这些虚拟机和硬件的特性是被上层软件竞争调用。不同于仿真系统,模拟软件能够记录线程数据访问、锁、原子操作等的先后顺序。然后,使用C++内存模型的规则重复运行每组允许的组合操作来识别竞争条件和死锁。
虽然如此全面的测试组合能够保证找到系统中的所有错误,但是,许多小的错误,往往需要花费大量的时间来发现它,因为组合操作的排列数会随着线程数和每个线程的操作数增长而呈现指数增长的趋势。因此组合测试技术最好保留到对代码片段进行精细测试时再用,而不是应用对整个应用程序的测试。组合测试的一个明显的缺点就是它需要依赖于仿真软件处理你代码中操作的能力。
组合测试技术可以用来在正常条件下反复测试你的代码,但是,这种技术可能会漏查一些错误,因此,你需要一种技术,这种技术可以让你在各种特定的条件下反复测试你的代码。有这样一种技术存在吗?
使用在测试运行时发现问题的库函数就是这样一种技术。
2.4.3. 使用特殊的库函数来检测测试暴露出的问题
尽管这种技术无法提供全面检查组合的模拟测试,但是,你可以使用一些特别的库函数同步基本单元来找到大部分错误,这些同步基本单元如互斥元、锁和条件变量等。例如,常用的要求对一块共享数据使用互斥锁。当你访问数据时,如果检测到互斥锁,就可以证实当访问数据时,调用线程已将该互斥元锁住了并且报告访问失败。通过标记你的共享数据,你可以使用库函数来检查数据共享。
如果有一个特殊线程一次拥有多个互斥元,应用库函数还可以记录锁的顺序。如果另一个线程在不同的时序锁住该互斥元,即使测试运行时没有出错,也会将之标记成一个可能的死锁。
测试多线程的另一类特殊的库函数是通过多个线程中将获得锁的那个线程或者通过notify_one()函数调用一个竞态变量的线程的控制权交给测试人员来实现线程的原子属性,如互斥元和条件变量。这样可以让你建立特定的测试场景并且验证代码在这些特定场景内是否能顺利运行。
此外,在C++标准库函数中也有一部分可用于测试的库函数,我们可以在我们的测试工具中调用这些标准库函数。 看完执行测试代码的不同方式之后,现在我们来看看构建测试代码来实现你希望的调度顺序的方法。
参考文献
C++并发编程实践
边栏推荐
- [C language syntax] the difference between typedef struct and struct
- MPLS test report
- 查询生产订单中某个(些)工作中心对应的标准文本码
- AUTOSAR from getting started to becoming proficient (10) - embedded S19 file analysis
- Cognitive introspection
- The difference and usage between continue and break
- H3C V7 switch configuration IRF
- P2802 回家
- 什么是独立IP,独立IP主机怎么样?
- Web服务连接器:Servlet
猜你喜欢
![[untitled]](/img/5d/028b9d19e9a2b217f40198d4631db2.png)
[untitled]

巨杉数据库再次亮相金交会,共建数字经济新时代
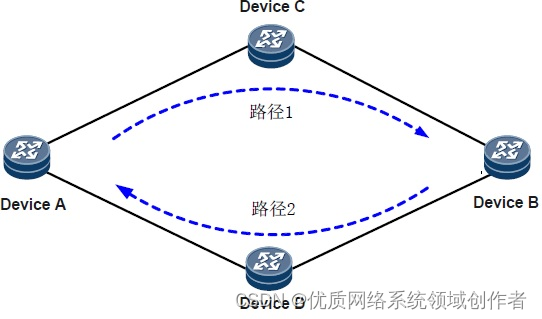
Huawei BFD configuration specification

B站刘二大人-Softmx分类器及MNIST实现-Lecture 9
Jushan database appears again in the gold fair to jointly build a new era of digital economy

The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower

The digital economy has broken through the waves. Is Ltd a Web3.0 website with independent rights and interests?
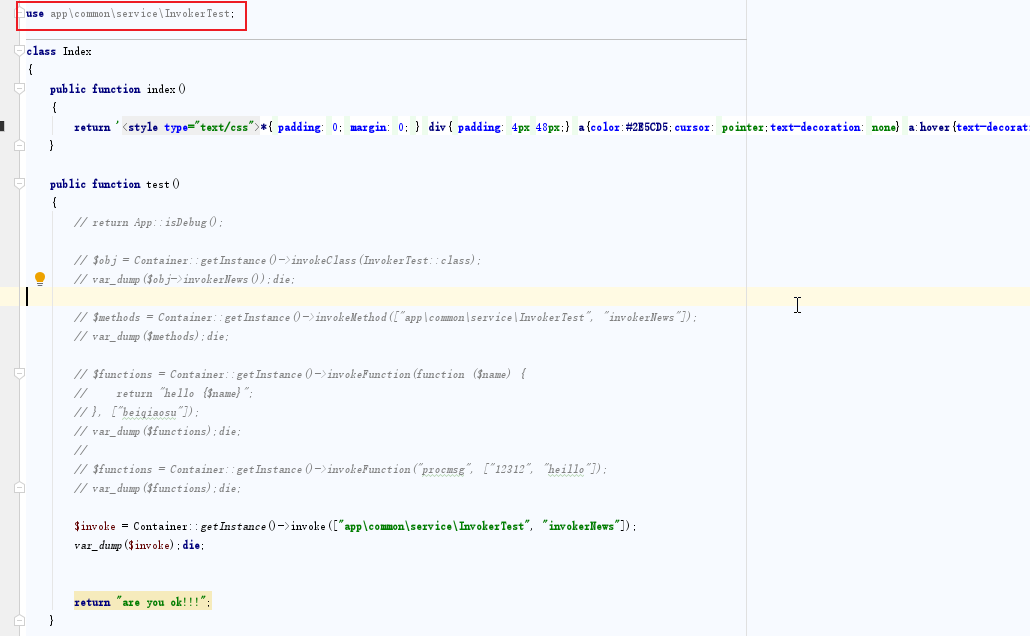
How to use the container reflection method encapsulated by thinkphp5.1 in business code
![[paper reading] nflowjs: synthetic negative data intensive anomaly detection based on robust learning](/img/9c/2753f68ecec3555aaca23800dada1e.png)
[paper reading] nflowjs: synthetic negative data intensive anomaly detection based on robust learning
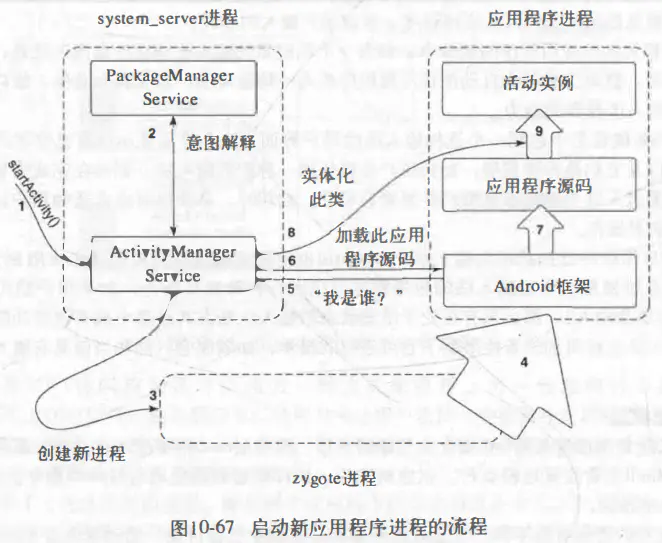
进程和线程
随机推荐
【LeetCode】Day96-第一个唯一字符&赎金信&字母异位词
Hongliao Technology: Liu qiangdong's "heavy hand"
Processes and threads
Web服务连接器:Servlet
HCIA review
Memory and stack related concepts
Cannot build artifact 'test Web: War expanded' because it is included into a circular depend solution
Go language -- language constants
[C language syntax] the difference between typedef struct and struct
进程和线程
LTE CSFB process
Dynamic programming -- knapsack problem
清除浮动的方式
The usage and difference between strlen and sizeof
【SQL server速成之路】——身份驗證及建立和管理用戶賬戶
[SQL Server fast track] - authentication and establishment and management of user accounts
Summary of data sets in intrusion detection field
[email protected] raspberry pie
B站刘二大人-线性回归 Pytorch
华为BFD的配置规范