当前位置:网站首页>10 pictures open the door of CPU cache consistency
10 pictures open the door of CPU cache consistency
2022-07-07 13:27:00 【Young】
Preface
Go straight up , Not much BB 了 .
Text
CPU Cache Data written to
as time goes on ,CPU And memory access performance is becoming more and more different , And then in CPU It's embedded inside CPU Cache( Cache ),CPU Cache leave CPU The core is quite close , So its access speed is very fast , So it acts as CPU Cache role between and memory .
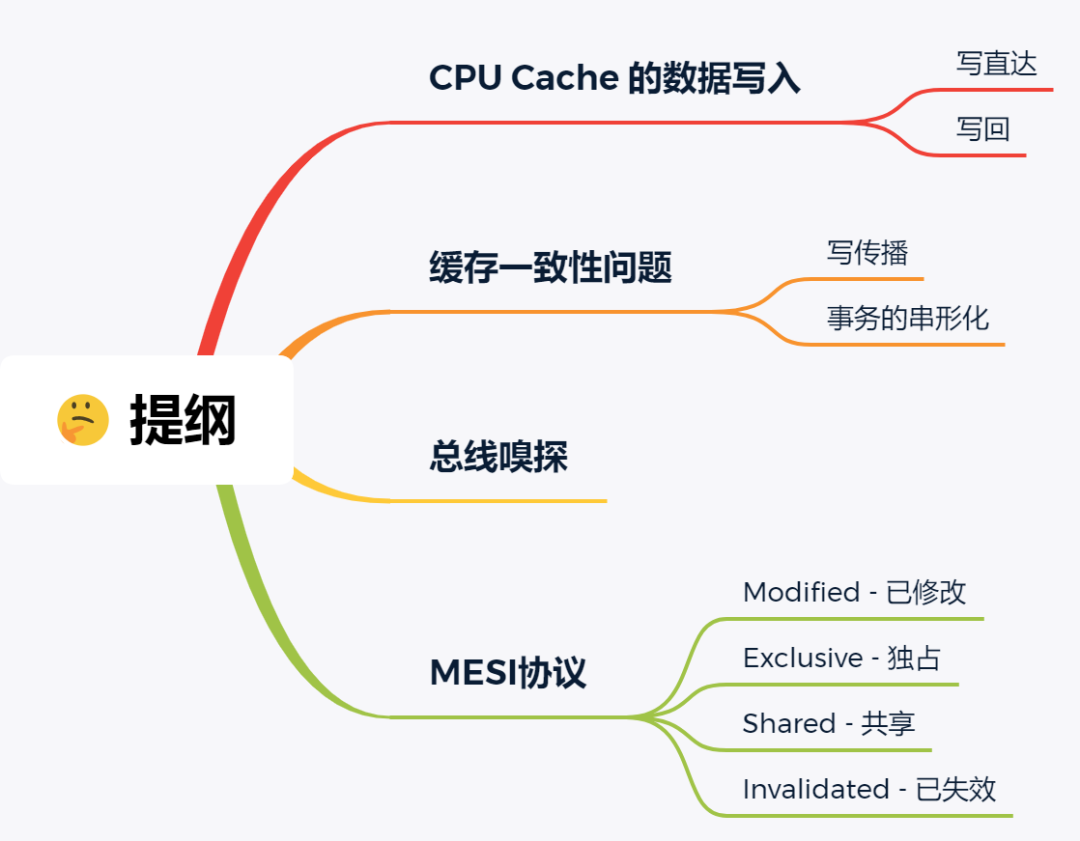
CPU Cache It is usually divided into three levels of cache :L1 Cache、L2 Cache、L3 Cache, The lower the level, the more you leave CPU The closer the core is , Access speed is also fast , But the storage capacity will be relatively small . among , In multicore CPU in , Each core has its own L1/L2 Cache, and L3 Cache It's shared by all the cores .
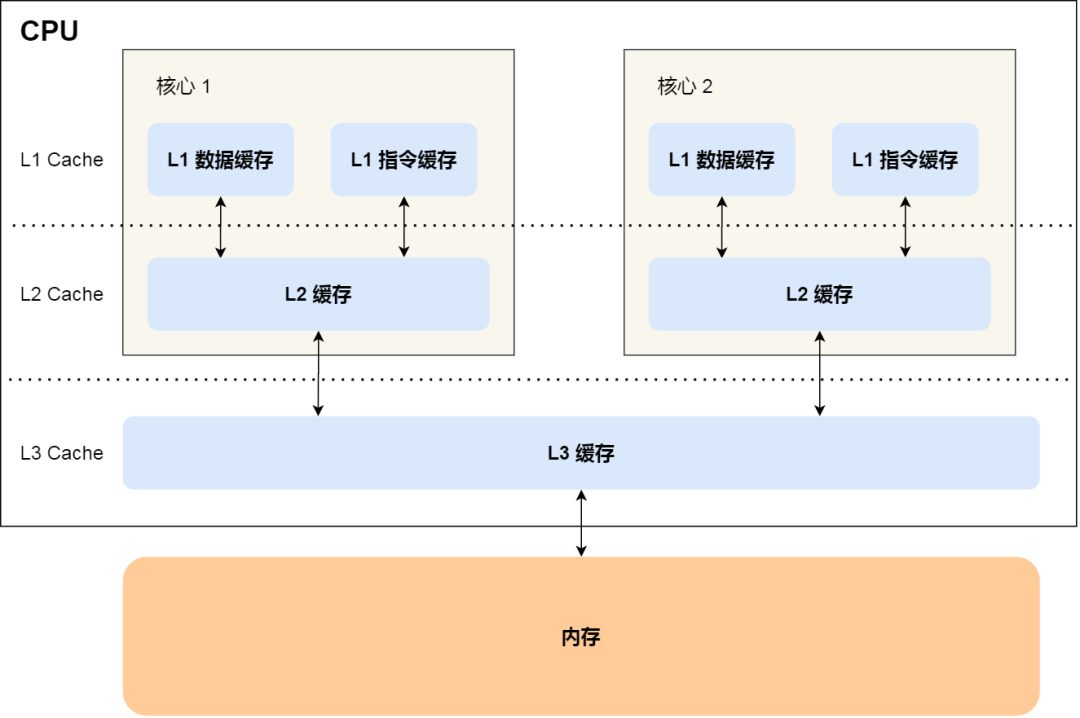
Let's take a quick look CPU Cache Structure ,CPU Cache It's made up of a lot of Cache Line Composed of ,CPU Line yes CPU The basic unit of data read from memory , and CPU Line It's made up of various signs (Tag)+ Data blocks (Data Block) form , You can see clearly in the figure below :
We certainly expect CPU When reading data , From as much as possible CPU Cache Read from , Instead of getting data from memory every time . therefore , As a programmer , We need to write code with a high cache hit rate as much as possible , This effectively improves the performance of the program , Specific measures , You can refer to my last article 「 How to write let CPU Faster code ?」
in fact , It's not just reading data , And write operations , So if the data is written to Cache after , Memory and Cache The corresponding data will be different , In this case Cache And memory data are inconsistent , So we must put Cache To synchronize the data in memory .
The problem is coming. , When will it be Cache Write the data back to memory ? In order to deal with this problem , Here are two ways to write data :
- Write direct (Write Through)
- Write back to (Write Back)
Write direct
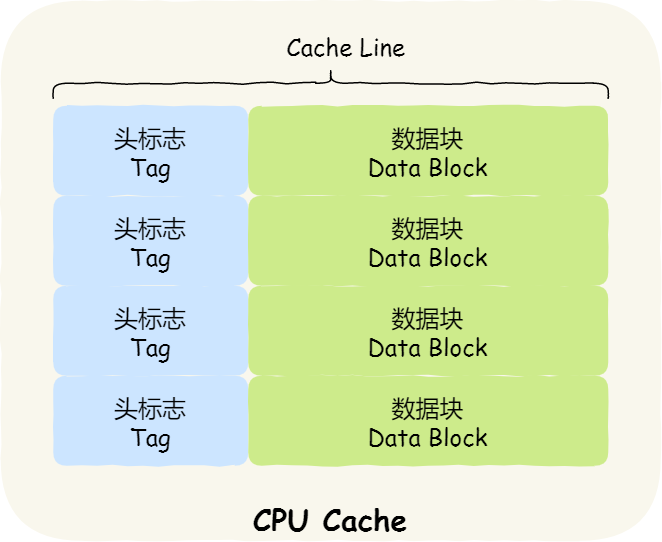
Keep memory and Cache The easiest way to be consistent is , Write data to both memory and Cache in , This method is called Write direct (*Write Through*).
In this way , Before writing, it will judge whether the data is already in CPU Cache Inside the :
- If the data is already in Cache Inside , First update the data to Cache Inside , Then write it to memory ;
- If the data is not in Cache Inside , Just update the data to the memory .
Direct writing is intuitive , It's also very simple. , But the problem is obvious , Whether the data is there or not Cache Inside , Every write operation will write back to memory , This will take a lot of time to write , There is no doubt that performance will be greatly affected .
Write back to
Since write direct, because each write operation will write data back to memory , And the performance is affected , So in order to reduce the frequency of data writing back to memory , And that's what happened Write back to (*Write Back*) Methods .
In the writeback mechanism , When a write operation occurs , New data is only written to Cache Block in , Only when the modified Cache Block「 Be replaced 」 You need to write it to memory when you need to , Reduce the frequency of data writing back to memory , This will improve the performance of the system .
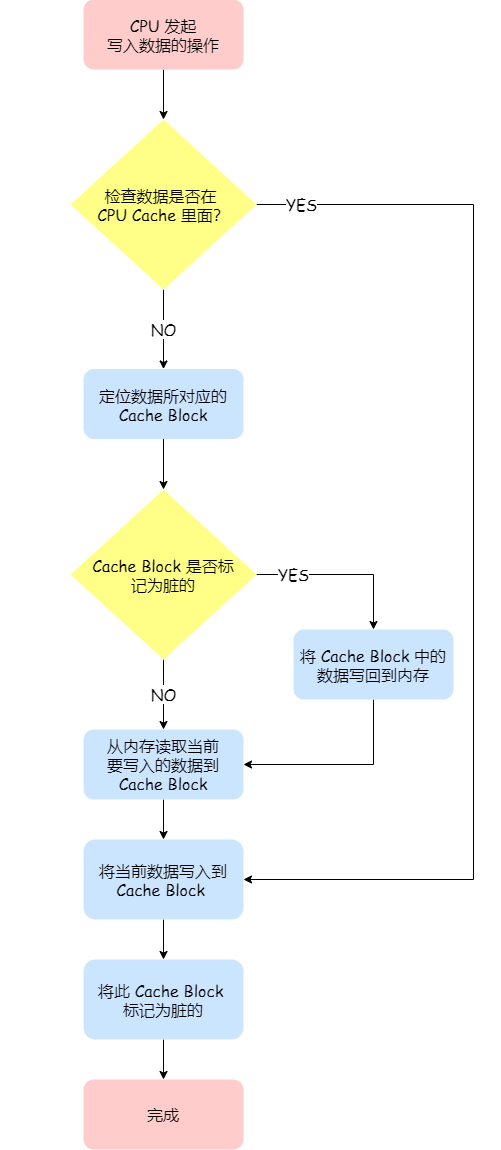
How to do it ? Let's talk about it in detail :
- If when a write occurs , The data is already in CPU Cache Words in Li , Update the data to CPU Cache in , At the same time mark CPU Cache This one in Cache Block For dirty (Dirty) Of , This dirty mark represents this time , We CPU Cache This one inside Cache Block Data and memory are inconsistent , In this case, it is not necessary to write data to memory ;
- If when a write occurs , The data corresponds to Cache Block There is 「 Other memory address data 」 Words , Just check this Cache Block Whether the data in is marked as dirty , If it's dirty , We're going to put this Cache Block Write the data back to memory , Then the current data to be written , Write to this Cache Block in , Also label it dirty ; If Cache Block The data in it is not marked dirty , Then write the data directly to this Cache Block in , And then put this Cache Block Just mark it dirty .
You can find this method of writing back , Writing data to Cache When , Only in cache miss , At the same time, the data corresponds to Cache Medium Cache Block In the case of dirty marks , Will write data to memory , And in the case of cache hits , Then after writing Cache after , Just put the data corresponding to Cache Block Mark it dirty , Instead of writing to memory .
The advantage of this is , If we can hit the cache for a large number of operations , So most of the time CPU No need to read or write memory , Natural performance is much higher than write direct .
Cache consistency issues
Now? CPU It's all multi-core , because L1/L2 Cache It's unique to multiple cores , So it's going to be multi-core Cache consistency (*Cache Coherence*) The problem of , If you can't guarantee cache consistency , It may lead to wrong results .
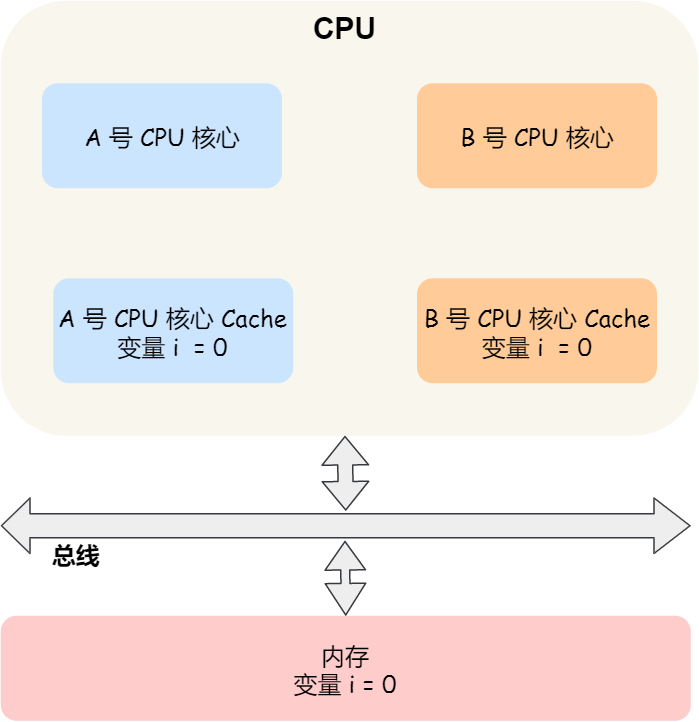
How does the cache consistency problem happen ? We take a two core CPU As an example, take a look at .
hypothesis A No. 1 core and B Core 2 runs two threads at the same time , All operate on the same variable i( The initial value is 0 ).
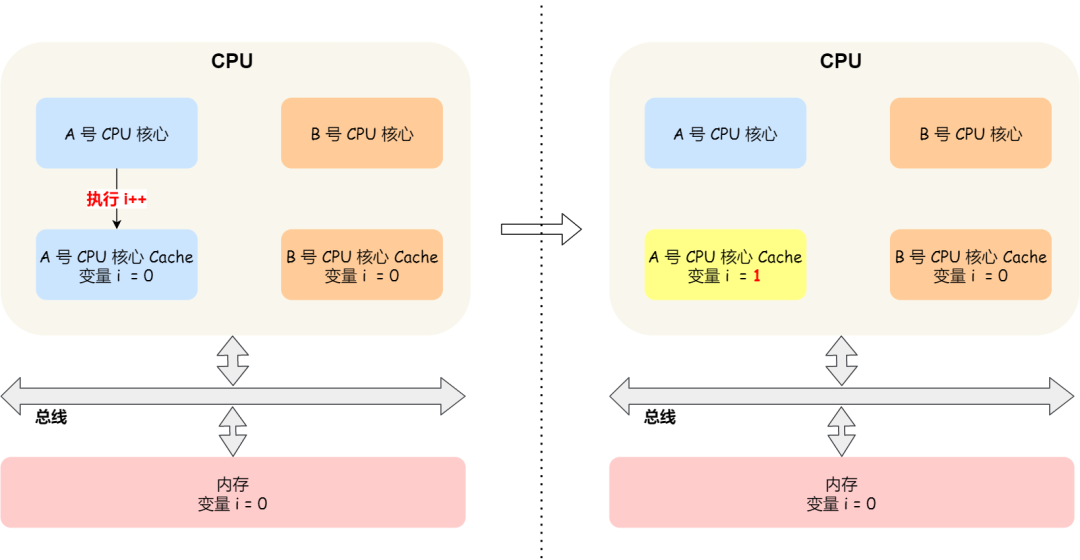
At this moment if A Core number one executed i++ At the time of statement , In order to consider performance , Using the writeback strategy we mentioned earlier , First put the value as 1 Write the execution result of to L1/L2 Cache in , And then put L1/L2 Cache Corresponding Block Marked dirty , At this time, the data is not synchronized to the memory , Because of the writeback strategy , Only in A This in the core of number one Cache Block When it comes to being replaced , Data will be written to memory .
If it's next to B Core number 1 tries to read from memory i The value of the variable , It will read the wrong value , Because just now A Core update i The value has not been written to memory , The value in memory is still 0. This is called cache consistency ,A No. 1 core and B The cache of core No , It's inconsistent at this time , This will result in errors in the execution results .
that , To solve this problem , There needs to be a mechanism , To synchronize the cached data in two different cores . If we want to implement this mechanism , Make sure you do the following 2 spot :
- The first point , Some CPU In the core Cache When data is updated , It has to spread to other core Cache, This is called Write and spread (*Wreite Propagation*);
- Second point , Some CPU The sequence of operations on the data in the core , The order must look the same in the other cores , This is called Serialization of transactions (*Transaction Serialization*).
The first point is that it's easy to understand the communication , When a core is in Cache Updated data , You need to synchronize to other cores Cache in .
For the second point, the serialization of transactions , Let's take an example to understand it .
Suppose we have one that contains 4 The core CPU, this 4 Each core operates on a common variable i( The initial value is 0 ).A No. 1 core first put i Value to 100, And at the same time ,B No. 1 core first put i Value to 200, Here are two changes , Metropolis 「 spread 」 To C and D Number one core .
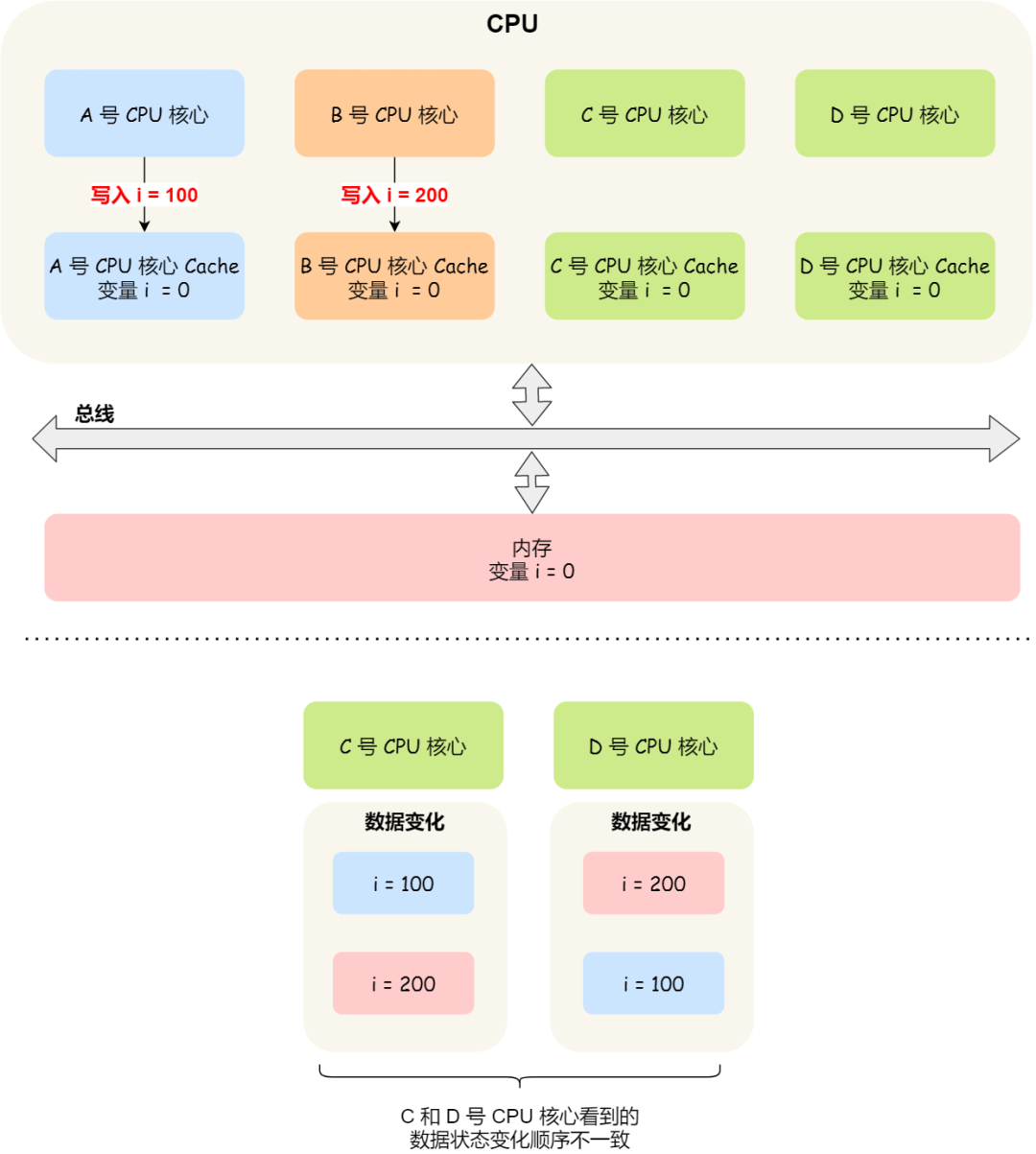
So here's the problem ,C Core number one received it first A Core update data event , Again B Core update data event , therefore C The variable seen by the core No i It's first to become 100, Later into 200.
And if the D Core number one received the event in reverse , be D Core No. 2 sees variables i First become 200, And then become 100, Although it's written and spread , But each Cache The data in it is still inconsistent .
therefore , We need to make sure C No. 1 core and D You can see it in the core Data changes in the same order , Like variables i It's all turned into 100, And then become 200, This process is the serialization of transactions .
To achieve transaction serialization , To do it 2 spot :
- CPU The core is for Cache Operation of data in , Need to synchronize with other CPU The core ;
- To introduce 「 lock 」 The concept of , If two CPU With the same data in the core Cache, So for this Cache Update of data , Only when you get it 「 lock 」, In order to update the corresponding data .
Let's take a look at , What technologies are used to implement write propagation and transaction serialization .
Bus sniffer
The principle of writing communication is to be someone CPU Core updated Cache Data in , To broadcast the event to other cores . The most common implementation is Bus sniffer (*Bus Snooping*).
I still use the front i Variable example to illustrate the working mechanism of bus sniffer , When A Number CPU The core changes L1 Cache in i The value of the variable , Broadcast this event to all other cores through the bus , Then each CPU The core will listen for broadcast events on the bus , And check if there is the same data in your own L1 Cache Inside , If B Number CPU The core L1 Cache There's this data in , Then you also need to update the data to your own L1 Cache.
You can find , Bus sniffing is simple , CPU You need to monitor all the activities on the bus all the time , But regardless of the other core Cache Whether to cache the same data , All need to send out a broadcast event , This will undoubtedly increase the load on the bus .
in addition , The bus sniffer only guarantees a certain CPU The core Cache This event can be updated by other CPU The core knows , But there is no guarantee that transactions will be serialized .
therefore , There is a protocol based on bus sniffer mechanism to achieve transaction serialization , The state machine mechanism is also used to reduce the bus bandwidth pressure , This agreement is MESI agreement , This Agreement does CPU Cache consistency .
MESI agreement
MESI The agreement is actually 4 The initial letter abbreviation of a state word , Namely :
- Modified, The modified
- Exclusive, Monopoly
- Shared, share
- Invalidated, Has lapsed
These four states are used to mark Cache Line Four different states .
「 The modified 」 State is the dirty mark we mentioned earlier , On behalf of Cache Block The data on has been updated , But it hasn't been written to memory yet . and 「 Has lapsed 」 state , It means this Cache Block The data in it is invalid , The data of this state cannot be read .
「 Monopoly 」 and 「 share 」 All states represent Cache Block The data in it is clean , in other words , This is the time Cache Block The data in memory is consistent with the data in memory .
「 Monopoly 」 and 「 share 」 The difference is , In the exclusive state , Data is only stored in one CPU The core Cache in , Others CPU The core Cache No such data . This is the time , If you want to exclusive Cache Writing data , You can write directly and freely , And you don't have to inform the others CPU The core , Because you're the only one with this data , There is no cache consistency problem , So you can manipulate the data at will .
in addition , stay 「 Monopoly 」 State data , If there are other cores that read the same data from memory to their respective Cache , So at this point , Data in the exclusive state becomes shared .
that ,「 share 」 States represent the same data in multiple CPU The core Cache It's all in it , So when we want to update Cache When the data is inside , Cannot be modified directly , But to all the others first CPU Core broadcast a request , Ask for the other core Cache Corresponding Cache Line Marked as 「 Invalid 」 state , Then update the current Cache The data in it .
Let's take a look at these four specific state transitions :
- When A Number CPU The core reads variables from memory i Value , Data is cached in A Number CPU The core of their own Cache Inside , At this time other CPU The core Cache The data is not cached , So mark Cache Line Status as 「 Monopoly 」, At this point the Cache The data in is consistent with memory ;
- then B Number CPU The core also reads variables from memory i Value , Messages are sent to other CPU The core , because A Number CPU The core has already cached the data , So the data will be returned to B Number CPU The core . At this time , A and B The core caches the same data ,Cache Line The state of will become 「 share 」, And its Cache The data in is consistent with the memory ;
- When A Number CPU The core needs to be modified Cache in i The value of the variable , Find the data corresponding to Cache Line The state of is shared , To all the others CPU Core broadcast a request , Ask for the other core Cache Corresponding Cache Line Marked as 「 Invalid 」 state , then A Number CPU The core is updated Cache The data in it , At the same time mark Cache Line by 「 The modified 」 state , here Cache The data in is inconsistent with the memory .
- If A Number CPU The core 「 continue 」 modify Cache in i The value of the variable , Because of the Cache Line yes 「 The modified 」 state , So there's no need to give other CPU The core sends messages , Just update the data directly .
- If A Number CPU The core Cache Inside i Variable corresponding Cache Line To be 「 Replace 」, Find out Cache Line Status is 「 The modified 」 state , The data will be synchronized to memory before replacement .
therefore , Can be found when Cache Line Status is 「 The modified 」 perhaps 「 Monopoly 」 In the state of , Modifying and updating its data does not need to be broadcast to other CPU The core , This reduces the bus bandwidth pressure to a certain extent .
in fact , Whole MESI A finite state machine can be used to represent its state flow . And a little bit more , For events triggered by different states , Maybe it's from local CPU Broadcast events from the core , It can also come from other CPU Broadcast events sent by the core through the bus . The picture below shows MESI State diagram of the protocol :
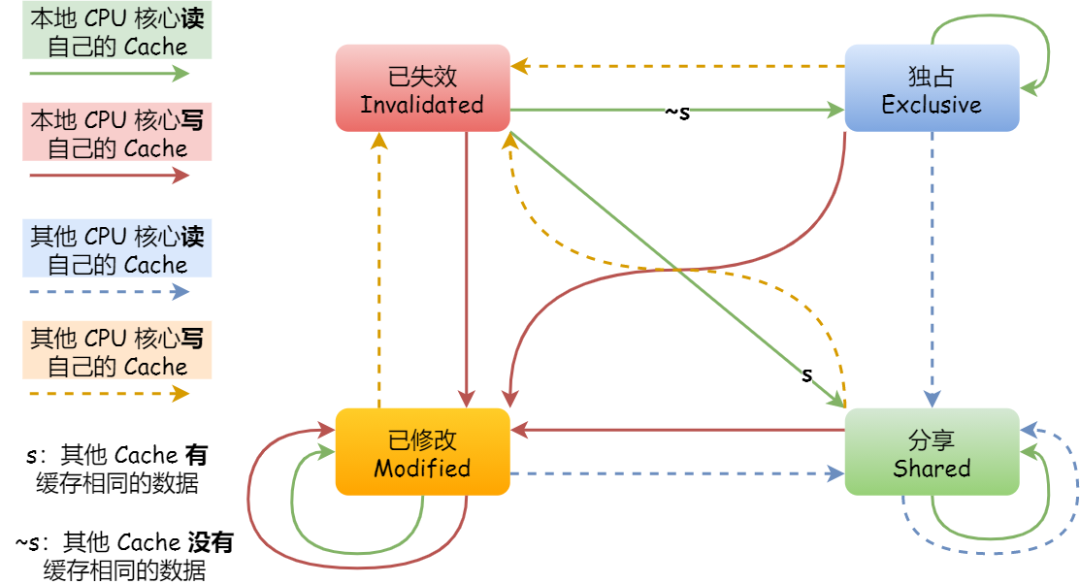
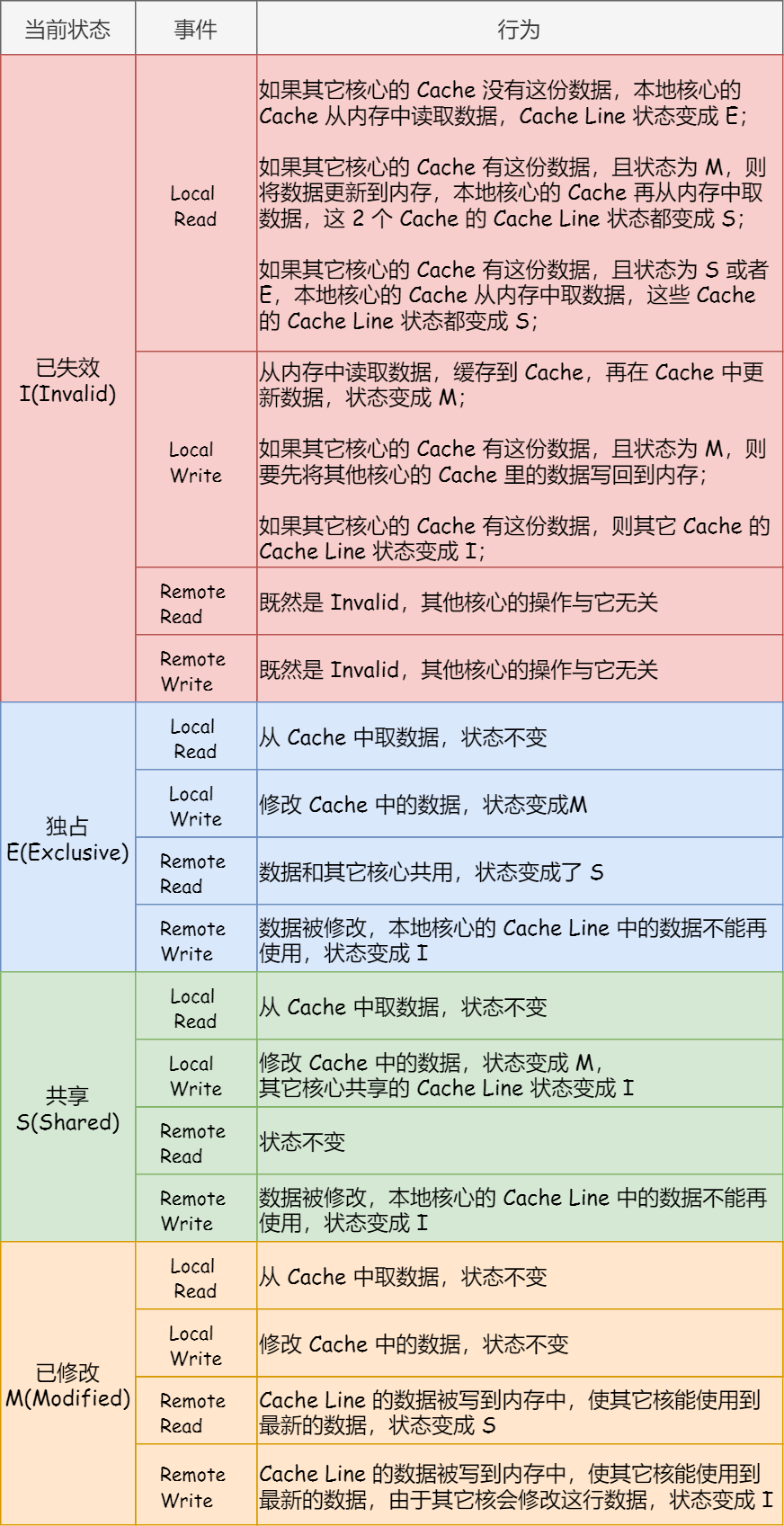
MESI The flow process between the four states of the agreement , I put it together in the following table , You can see in more detail the reasons for each state transition :
summary
CPU When reading and writing data , It's all in CPU Cache Reading and writing data , as a result of Cache leave CPU Very close , Read and write performance is much higher than memory . about Cache There's no cache in it CPU This case of data that needs to be read ,CPU Data will be read from memory , And cache the data to Cache Inside , Last CPU Again from Cache Reading data .
And for data writing ,CPU Will be written to Cache Inside , Then write it to memory at the right time , Then there is 「 Write direct 」 and 「 Write back to 」 These two strategies ensure that Cache Data consistency with memory :
- Write direct , As long as there is data written to , Will directly write data into memory , This way is simple and intuitive , But performance is limited by the speed of memory access ;
- Write back to , For already cached in Cache Write data to , Just update its data , No need to write to memory , Only when you need to exchange dirty data from the cache , To synchronize the data to the memory , In this way, the cache hit rate is high , Performance will be better ;
Today, CPU It's all multi-core , Each core has its own L1/L2 Cache, Only L3 Cache It's shared among multiple cores . therefore , We need to make sure that the multi-core cache is consistent , Otherwise, there will be wrong results .
To achieve cache consistency , The key is to satisfy 2 spot :
- The first point is to write about communication , That is, when someone CPU When a write to the core occurs , Broadcast the event to other core needs ;
- The second is the serialization of things , This is very important , Only this is guaranteed , Second, it can guarantee that our data is truly consistent , The results of our program running on different cores are the same ;
Based on bus sniffer mechanism MESI agreement , Just satisfy the above two points , Therefore, it is a protocol to guarantee cache consistency .
MESI agreement , It has been modified 、 Monopoly 、 share 、 A combination of abbreviations for these four states has been implemented . Whole MSI A change of state , It's based on local sources CPU The core request , Or from something else CPU Requests from the core are transmitted through the bus , Thus a flowing state machine is formed . in addition , For in 「 The modified 」 perhaps 「 Monopoly 」 State of Cache Line, Modifying and updating its data does not need to be broadcast to other CPU The core .
边栏推荐
猜你喜欢
Differences between MySQL storage engine MyISAM and InnoDB
![Scripy tutorial classic practice [New Concept English]](/img/bc/f1ef8b6de6bfb6afcdfb0d45541c72.png)
Scripy tutorial classic practice [New Concept English]

About how appium closes apps (resolved)

单片机原理期末复习笔记

日本政企员工喝醉丢失46万信息U盘,公开道歉又透露密码规则
Sed of three swordsmen in text processing
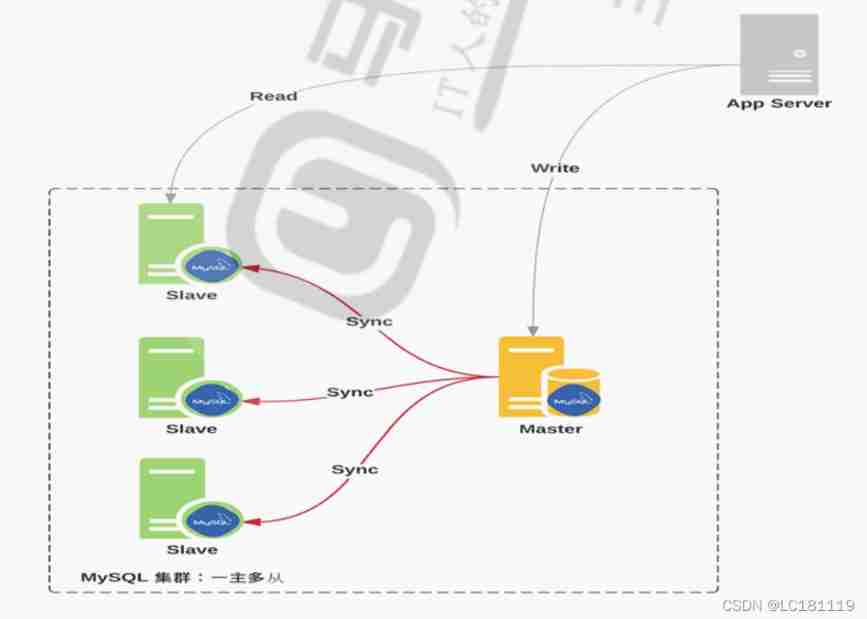
MySQL master-slave replication
Vscode编辑器ESP32头文件波浪线不跳转彻底解决
Final review notes of single chip microcomputer principle
单片机学习笔记之点亮led 灯
随机推荐
MongoDB优化的几点原则
存储过程的介绍与基本使用
[dark horse morning post] Huawei refutes rumors about "military master" Chen Chunhua; Hengchi 5 has a pre-sale price of 179000 yuan; Jay Chou's new album MV has played more than 100 million in 3 hours
ESP32构解工程添加组件
记一次 .NET 某新能源系统 线程疯涨 分析
PHP - laravel cache
如何让electorn打开的新窗口在window任务栏上面
【学习笔记】线段树选做
分布式事务解决方案
[etc.] what are the security objectives and implementation methods that cloud computing security expansion requires to focus on?
【学习笔记】zkw 线段树
About the problem of APP flash back after appium starts the app - (solved)
简单好用的代码规范
Ogre入门尝鲜
Clion mingw64 Chinese garbled code
Digital IC Design SPI
PCAP学习笔记二:pcap4j源码笔记
Write it down once Net a new energy system thread surge analysis
QQ的药,腾讯的票
OSI 七层模型