当前位置:网站首页>MySQL optimization notes
MySQL optimization notes
2022-07-06 16:57:00 【Xiaoxiamo】
Indexes
Index Overview
MySQL The official definition of index is : Indexes (index) Help MySQL Data structure for efficient data acquisition ( Orderly ). Out of data , The database system also maintains a data structure that satisfies a specific search algorithm , These data structures are referenced in some way ( Point to ) data , In this way, advanced search algorithms can be implemented on these data structures , This data structure is the index . As shown in the figure below :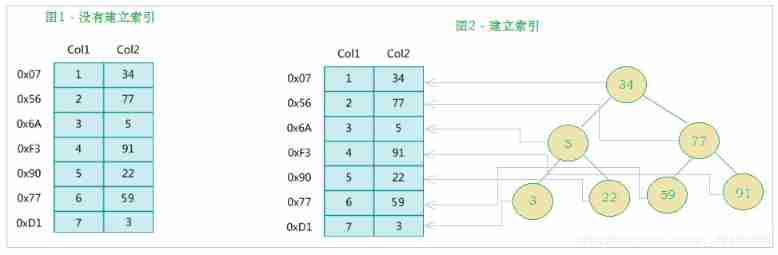
On the left is the data table , There are two columns and seven records , On the far left is the physical address of the data record ( Note that logically adjacent records are not physically adjacent to each other on disk ). In order to speed up Col2 Lookup , You can maintain a binary search tree as shown on the right , Each node contains an index key value and a pointer to the physical address of the corresponding data record , In this way, we can use binary search to get the corresponding data quickly .
Generally speaking, the index itself is very large , It's impossible to store everything in memory , So indexes are often stored on disk as index files . Index is the most commonly used tool in database to improve performance .
Index strengths and weaknesses
advantage
1) It's like a catalog index of books , Improve the efficiency of data retrieval , Reduce the IO cost .
2) Sort data through index columns , Reduce the cost of sorting data , Reduce CPU Consumption of .
Inferiority
1) The index is actually a table , The table holds the primary key and index fields , And point to the record of the entity class , So index columns also need to occupy space .
2) Although indexing greatly improves query efficiency , At the same time, it also reduces the speed of updating tables , Such as on the table INSERT、UPDATE、DELETE. Because when updating tables ,MySQL Not only to save data , Also save the fields in the index file that have index columns added every time it is updated , Will adjust the index information after the key value changes due to the update .
Index structure
The index is in MySQL In the storage engine layer , Not at the server level . So the indexes of each storage engine are not necessarily the same , Not all storage engines support all index types .MySQL The following are currently available 4 Species index :
- BTREE Indexes : The most common type of index , Most indexes support B Tree index .
- HASH Indexes : Only Memory Engine support , The use scenario is simple .
- R-tree Indexes ( Spatial index ): The spatial index is MyISAM A special index type of the engine , Mainly used for geospatial data types , Usually used less , No special introduction .
- Full-text ( Full-text index ) : Full text index is also MyISAM A special index type of , Mainly used for full-text indexing ,InnoDB from Mysql5.6 Full text indexing is now supported .
MyISAM、InnoDB、Memory Three storage engines support various index types
| Indexes | InnoDB engine | MyISAM engine | Memory engine |
|---|---|---|---|
| BTREE Indexes | Support | Support | Support |
| HASH Indexes | I won't support it | I won't support it | Support |
| R-tree Indexes | I won't support it | Support | I won't support it |
| Full-text | 5.6 Support for | Support | I won't support it |
What we usually call index , If not specified , All refer to B+ Trees ( Multiple search trees , It doesn't have to be a binary ) Index of structural organization . Where the clustered index 、 Composite index 、 Prefix index 、 The only index defaults to B+tree Indexes , Collectively referred to as index .
BTREE structure
BTree It's also called multiple balanced search tree , One m Forked BTree Characteristics are as follows :
- Each node in the tree contains at most m A child .
- Except root node and leaf node , Each node has at least [ceil(m/2)] A child .
- If the root node is not a leaf node , There are at least two children .
- All the leaf nodes are on the same layer .
- Each non leaf node is composed of n individual key And n+1 Pointer composition , among [ceil(m/2)-1] <= n <= m-1
B+TREE structure
B+Tree by BTree Variants ,B+Tree And BTree The difference is :
1). n fork B+Tree Up to n individual key, and BTree Up to n-1 individual key.
2). B+Tree The leaf node in the key Information , In accordance with the key In order of size .
3). All non leaf nodes can be regarded as key The index part of .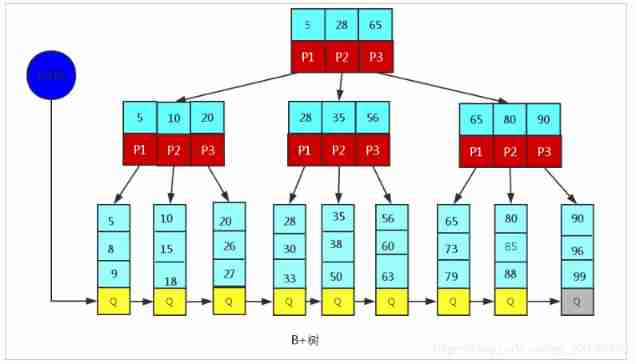
because B+Tree Only leaf nodes are saved key Information , Query any key All from root Go to the leaves . therefore B+Tree The query efficiency is more stable .
MySQL Medium B+Tree
MySql Index data structure for classic B+Tree optimized . In the original B+Tree On the basis of , Add a pointer to the linked list of adjacent leaf nodes , So we have a sequence pointer B+Tree, Improve the performance of interval access .
MySQL Medium B+Tree Index structure diagram :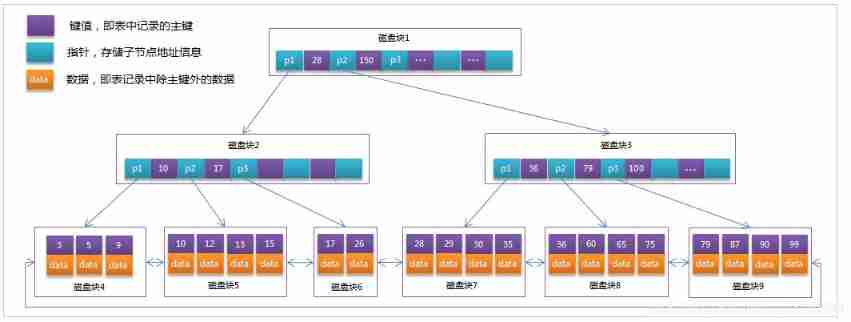
Index classification
1) Single value index : That is, an index contains only a single column , A table can have multiple single-column indexes
2) unique index : The value of the index column must be unique , But you can have an empty value
3) Composite index : That is, an index contains multiple columns
Index Syntax
When the index creates the table , You can create at the same time , You can also add new indexes at any time .
Create index
grammar :
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name
[USING index_type]
ON tbl_name(index_col_name,...)
Look at the index
grammar :
show index from table_name;
Delete index
grammar :
DROP INDEX index_name ON tbl_name;
ALTER command
1). alter table tb_name add primary key(column_list);
This statement adds a primary key , This means that the index value must be unique , And cannot be NULL
2). alter table tb_name add unique index_name(column_list);
The value of the index created by this statement must be unique ( except NULL Outside ,NULL There may be many times )
3). alter table tb_name add index index_name(column_list);
Add a normal index , Index values can appear multiple times .
4). alter table tb_name add fulltext index_name(column_list);
The statement specifies that the index is FULLTEXT, For full-text indexing
Index design principles
Index design can follow some existing principles , When creating an index, try to conform to these principles , It is easy to improve the efficiency of the index , More efficient use of indexes .
The query frequency is high , And a table with a large amount of data is indexed .
Selection of index fields , The best candidate column should be from where Clause is extracted from the condition of clause , If where There are more combinations in clauses , Then choose the most commonly used 、 The combination of the best filtering Columns .
Use unique index , The more distinguishable , The more efficient the index is .
Index can effectively improve the efficiency of query data , But the number of indexes is not the better , More indexes , The cost of maintaining the index naturally goes up . For inserting 、 to update 、 Delete etc. DML For tables that operate more frequently , Too many indexes , It's going to introduce quite a high maintenance cost , Reduce DML Efficiency of operation , Increase the time consumption of the corresponding operation . In addition, if there are too many indexes ,MySQL It's also a choice problem , Although you'll still find a usable index in the end , But it certainly raises the cost of choice .
Use short index , After the index is created, it is also stored on the hard disk , Therefore, the index access is improved I/O efficiency , It can also improve the overall access efficiency . If the total length of the fields that make up the index is short , Then more index values can be stored in a given size of memory block , Correspondingly, it can effectively improve MySQL Access to the index I/O efficiency .
Use the leftmost prefix ,N A composite index of columns , So it's equivalent to creating N An index , If you query where Clause uses the first few fields that make up the index , So this query SQL We can use composite index to improve query efficiency .
Create composite index : CREATE INDEX idx_name_email_status ON tb_seller(NAME,email,STATUS); Equivalent to Yes name Create index ; Yes name , email Created index ; Yes name , email, status Created index ;
View
View overview
View (View) It's a virtual existence table . The view does not actually exist in the database , Row and column data comes from tables used in queries that define views , And it's dynamically generated when using views . Generally speaking , The view is just a line SELECT The result set returned after the statement is executed . So when we create views , The main job is to create this SQL On the query statement .
The advantages of a view over a regular table include the following .
- Simple : Users of views do not need to care about the structure of the corresponding tables 、 Association and screening criteria , It is already the result set of filtered composite conditions for users .
- Security : Users of views can only access the result set they are allowed to query , Permission management of a table cannot be limited to a row or a column , But it can be realized simply by view .
- Data independence : Once the structure of the view is determined , It can shield the influence of table structure change on users , Adding columns to the source table has no effect on the view ; Source table change column name , Can be solved by modifying the view , No impact on visitors .
Create or modify views
The syntax for creating a view is :
CREATE [OR REPLACE] [ALGORITHM = {
UNDEFINED | MERGE | TEMPTABLE}]
VIEW view_name [(column_list)]
AS select_statement
[WITH [CASCADED | LOCAL] CHECK OPTION]
Modify the syntax of the view to :
ALTER [ALGORITHM = {
UNDEFINED | MERGE | TEMPTABLE}]
VIEW view_name [(column_list)]
AS select_statement
[WITH [CASCADED | LOCAL] CHECK OPTION]
Options :
WITH [CASCADED | LOCAL] CHECK OPTION Decide whether to allow the data to be updated so that the record no longer meets the view conditions .
LOCAL : You can update as long as you meet the conditions of this view .
CASCADED : All the conditions for all views for that view must be met to update . The default value is .
View view
from MySQL 5.1 Version start , Use SHOW TABLES The command not only displays the name of the table , The name of the view is also displayed , There is no way to display views separately SHOW VIEWS command .
Again , In the use of SHOW TABLE STATUS When ordered , It can not only display the information of the table , At the same time, it can also display the information of the view . 
If you need to query the definition of a view , have access to SHOW CREATE VIEW Command to view :
Delete view
grammar :
DROP VIEW [IF EXISTS] view_name [, view_name] ...[RESTRICT | CASCADE]
Stored procedures and functions
Overview of stored procedures and functions
Stored procedures and functions are , A segment that has been compiled in advance and stored in a database SQL Collection of statements , Calling stored procedures and functions can simplify a lot of work for application developers , Reduce data transfer between database and application server , It's good for improving the efficiency of data processing .
The difference between a stored procedure and a function is that the function must have a return value , And stored procedures don't have .
function : Is a process with a return value ;
The process : Is a function with no return value ;
Create stored procedure
CREATE PROCEDURE procedure_name ([proc_parameter[,...]])
begin
-- SQL sentence
end ;
Knowledge tips
DELIMITER
This keyword is used to declare SQL Statement separator , tell MySQL Interpreter , Whether the order has ended ,mysql Whether it can be carried out . By default ,delimiter It's a semicolon ;. In the command line client , If there's a line of command that ends with a semicolon , So when you return ,mysql The command will be executed .
Calling stored procedure
call procedure_name() ;
View stored procedures
-- Inquire about db_name All stored procedures in the database
select name from mysql.proc where db='db_name';
-- Query the status information of the stored procedure
show procedure status;
-- Query the definition of a stored procedure
show create procedure test.pro_test1 \G;
Delete stored procedure
DROP PROCEDURE [IF EXISTS] sp_name ;
grammar
Stored procedures are programmable , It means that variables can be used , expression , Control structure , To complete more complex functions .
Variable
DECLARE
adopt DECLARE You can define a local variable , This variable can only be used in BEGIN…END In block .
DECLARE var_name[,...] type [DEFAULT value]
- SET
Direct assignment uses SET, You can assign constants or expressions , The specific syntax is as follows :
SET var_name = expr [, var_name = expr] ...
It can also be done through select … into Method for assignment operation :
DELIMITER $
CREATE PROCEDURE pro_test5()
BEGIN
declare countnum int;
select count(*) into countnum from city;
select countnum;
END$
DELIMITER ;
if conditional
Grammatical structure :
if search_condition then statement_list
[elseif search_condition then statement_list] ...
[else statement_list]
end if;
Pass parameters
Grammar format :
create procedure procedure_name([in/out/inout] Parameter name Parameter type )
...
IN : This parameter can be used as input , That is, you need the caller to pass in a value , Default
OUT: This parameter is used as the output , That is, the parameter can be used as the return value
INOUT: It can be used as an input parameter , It can also be used as an output parameter
Little knowledge
@description : This variable should be preceded by the name of the variable “@” Symbol , It's called the user session variable , On behalf of the whole conversation, he is useful , This is similar to a global variable .
@@global.sort_buffer_size : This adds... To the variable “@@” Symbol , be called System variables
case structure
Grammatical structure :
Mode one :
CASE case_value
WHEN when_value THEN statement_list
[WHEN when_value THEN statement_list] ...
[ELSE statement_list]
END CASE;
Mode two :
CASE
WHEN search_condition THEN statement_list
[WHEN search_condition THEN statement_list] ...
[ELSE statement_list]
END CASE;
while loop
Grammatical structure :
while search_condition do
statement_list
end while;
repeat structure
Conditional loop control statements , Exit the loop when the conditions are met .while Only when the conditions are met ,repeat If you meet the conditions, you exit the cycle .
Grammatical structure :
REPEAT
statement_list
UNTIL search_condition
END REPEAT;
loop sentence
LOOP Implement a simple loop , The conditions for exiting the loop need to be defined with other statements , You can usually use LEAVE Statements for , The specific syntax is as follows :
[begin_label:] LOOP
statement_list
END LOOP [end_label]
If not statement_list Add the statement to exit the loop , that LOOP Statements can be used to implement simple dead loops .
leave sentence
Used to exit from annotated process constructs , Usually and BEGIN … END Or loop together . Here is a use LOOP and LEAVE Simple example of , Exit loop :
delimiter $
CREATE PROCEDURE pro_test11(n int)
BEGIN
declare total int default 0;
ins: LOOP
IF n <= 0 then
leave ins;
END IF;
set total = total + n;
set n = n - 1;
END LOOP ins;
select total;
END$
delimiter ;
The cursor / cursor
Cursors are data types used to store query result sets , In stored procedures and functions, you can use cursors to cycle through the result set . The use of cursors includes the declaration of cursors 、OPEN、FETCH and CLOSE, The grammar is as follows .
Declaration cursor :
DECLARE cursor_name CURSOR FOR select_statement ;
OPEN cursor :
OPEN cursor_name ;
FETCH cursor :
FETCH cursor_name INTO var_name [, var_name] ...
CLOSE cursor :
CLOSE cursor_name ;
Storage function
Grammatical structure :
CREATE FUNCTION function_name([param type ... ])
RETURNS type
BEGIN
...
END;
trigger
Introduce
Triggers are database objects related to tables , Referring to insert/update/delete Before or after , Trigger and execute the... Defined in the trigger SQL Statement set . This feature of trigger can help to ensure the integrity of data in database , logging , Data verification and other operations .
Use the alias OLD and NEW To refer to the changed record content in the trigger , This is similar to other databases . Now triggers only support row level triggering , Statement level triggering is not supported .
| Trigger Type | NEW and OLD Use |
|---|---|
| INSERT Type trigger | NEW Indicates the data to be added or added |
| UPDATE Type trigger | OLD Represents the data before modification , NEW Represents the data that will be or has been modified |
| DELETE Type trigger | OLD Data that will be or has been deleted |
Create trigger
Grammatical structure :
create trigger trigger_name
before/after insert/update/delete
on tbl_name
[ for each row ] -- Line level triggers
begin
trigger_stmt ;
end;
Delete trigger
Grammatical structure :
drop trigger [schema_name.]trigger_name
If not specified schema_name, The default is the current database .
Check triggers
Can be executed by SHOW TRIGGERS Command to view the status of the trigger 、 Grammar and other information .
Grammatical structure :
show triggers ;
Mysql Architecture Overview
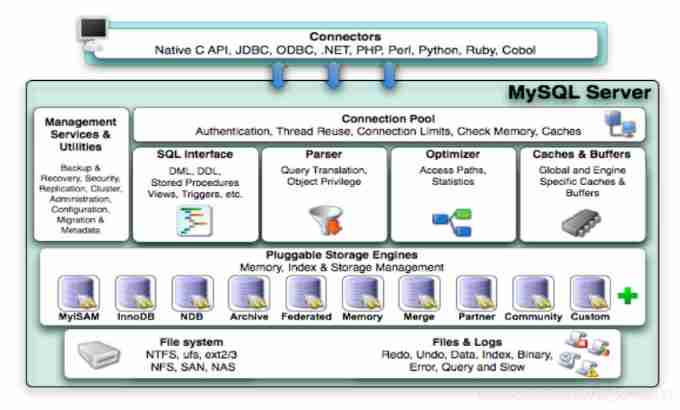
Whole MySQL Server It consists of
- Connection Pool : Connection pool components
- Management Services & Utilities : Manage service and tool components
- SQL Interface : SQL Interface component
- Parser : Query analyzer component
- Optimizer : Optimizer components
- Caches & Buffers : Buffer pool components
- Pluggable Storage Engines : Storage engine
- File System : file system
1) adjoining course
At the top are some clients and link services , Contains the local sock Communication and most are client based / The implementation of server-side tools is similar to TCP/IP Communication for . Mainly completes some similar to the connection processing 、 Authorized certification 、 And related safety programs . The concept of thread pool is introduced in this layer , Provide threads for clients accessing through authentication security . Also on this layer, we can implement the system based on SSL Security links for . The server will also verify the operation permissions it has for each client of secure access .
2) Service layer
The second layer architecture mainly completes most of the core service functions , Such as SQL Interface , And complete the cache query ,SQL Analysis and optimization of , Execution of some built-in functions . All the cross storage engine functions are also implemented in this layer , Such as The process 、 Functions, etc . On this floor , The server parses the query and creates the corresponding internal parse tree , And it completes the corresponding optimization, such as determining the query order of the table , Whether to use index, etc , Finally, the corresponding execution operation is generated . If it is select sentence , The server also queries the internal cache , If the cache space is large enough , In this way, it can improve the performance of the system in the environment of solving a large number of read operations .
3) Engine layer
Storage engine layer , The storage engine is really responsible for MySQL The storage and extraction of data in , Server pass API Communicating with the storage engine . Different storage engines have different functions , So that we can according to our own needs , To choose the right storage engine .
4) Storage layer
Data storage layer , Mainly store the data on the file system , And complete the interaction with the storage engine .
Compared with other databases ,MySQL It's a little different , Its architecture can be applied in many different scenarios and play a good role . Mainly in the storage engine , Plug in storage engine architecture , Separate query processing from other system tasks and data storage and extraction . This architecture can choose the right storage engine according to the needs of the business and the actual needs .
Storage engine
Storage engine overview
Unlike most databases , MySQL There's a storage engine concept in , We can choose the best storage engine for different storage requirements .
The storage engine is to store data , Index , Update query data and so on . The storage engine is table based , Not library based . So a storage engine can also be called a table type .
Oracle,SqlServer There is only one storage engine for databases .MySQL Provides plug-in storage engine architecture . therefore MySQL There are multiple storage engines , You can use the engine as needed , Or write a storage engine .
MySQL5.0 Supported storage engines include : InnoDB 、MyISAM 、BDB、MEMORY、MERGE、EXAMPLE、NDB Cluster、ARCHIVE、CSV、BLACKHOLE、FEDERATED etc. , among InnoDB and BDB Provide transaction safety watch , Other storage engines are non transactional security tables .
You can specify show engines , To query the storage engine supported by the current database :
If you do not specify a storage engine when creating a new table , Then the system will use the default storage engine ,MySQL5.5 The previous default storage engine was MyISAM,5.5 Then it's changed to InnoDB.
see Mysql Database default storage engine , Instructions :
show variables like '%storage_engine%' ;

Various storage engine features
Here are some common storage engines , And compare the differences between the storage engines , As shown in the following table :
| characteristic | InnoDB | MyISAM | MEMORY | MERGE | NDB |
|---|---|---|---|---|---|
| Storage limits | 64TB | Yes | Yes | No, | Yes |
| Transaction security | Support | ||||
| Locking mechanism | Row lock ( Suitable for high concurrency ) | Table locks | Table locks | Table locks | Row lock |
| B Tree index | Support | Support | Support | Support | Support |
| Hash index | Support | ||||
| Full-text index | Support (5.6 After the version ) | Support | |||
| Cluster index | Support | ||||
| Data index | Support | Support | Support | ||
| The index buffer | Support | Support | Support | Support | Support |
| Data can be compressed | Support | ||||
| Space use | high | low | N/A | low | low |
| Memory usage | high | low | secondary | low | high |
| Batch insertion speed | low | high | high | high | high |
| Support foreign keys | Support |
Next, we will focus on the two longest used storage engines : InnoDB、MyISAM , The other two MEMORY、MERGE , Understanding can .
InnoDB
InnoDB The storage engine is Mysql The default storage engine for .InnoDB The storage engine provides with commit 、 Roll back 、 Crash resilience transaction security . But contrast MyISAM Storage engine for ,InnoDB The processing efficiency of writing is poor , And it will take up more disk space to keep data and index .
InnoDB Storage engine is different from other storage engines :
Transaction control
create table goods_innodb(
id int NOT NULL AUTO_INCREMENT,
name varchar(20) NOT NULL,
primary key(id)
)ENGINE=innodb DEFAULT CHARSET=utf8;
start transaction;
insert into goods_innodb(id,name)values(null,'Meta20');
commit;

test , Found in InnoDB There are transactions in ;
Foreign key constraints
MySQL The only storage engine that supports foreign keys is InnoDB , When creating a foreign key , The parent table is required to have a corresponding index , When creating a foreign key, the child table , The corresponding index will also be created automatically .
In the following two tables , country_innodb It's the father's watch , country_id Index for primary key ,city_innodb A watch is a subtable ,country_id The field is foreign key , Corresponding to country_innodb Primary Key country_id .
create table country_innodb(
country_id int NOT NULL AUTO_INCREMENT,
country_name varchar(100) NOT NULL,
primary key(country_id)
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
create table city_innodb(
city_id int NOT NULL AUTO_INCREMENT,
city_name varchar(50) NOT NULL,
country_id int NOT NULL,
primary key(city_id),
key idx_fk_country_id(country_id),
CONSTRAINT `fk_city_country` FOREIGN KEY(country_id) REFERENCES country_innodb(country_id) ON DELETE RESTRICT ON UPDATE CASCADE
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into country_innodb values(null,'China'),(null,'America'),(null,'Japan');
insert into city_innodb values(null,'Xian',1),(null,'NewYork',2),(null,'BeiJing',1);
When the index is created , Can be specified in delete 、 When updating the parent table , The corresponding operation on the sub table , Include RESTRICT、CASCADE、SET NULL and NO ACTION.
RESTRICT and NO ACTION identical , It is limited to the case that the sub table has associated records , The parent table cannot be updated ;
CASCADE Indicates that when the parent table is updated or deleted , Update or delete the record corresponding to the sub table ;
SET NULL When the parent table is updated or deleted , The corresponding fields of the sub table are SET NULL .
For the two tables created above , The foreign key specification of the child table is ON DELETE RESTRICT ON UPDATE CASCADE The way of , When deleting records in the main table , If the sub table has corresponding records , Delete is not allowed , When the main table is updating records , If the sub table has corresponding records , Then the sub table is updated .
The data in the table is shown in the figure below :
Foreign key information can be viewed in the following two ways :
show create table city_innodb ;

Delete country_id by 1 Of country data :
delete from country_innodb where country_id = 1;

Update main table country Table fields country_id :
update country_innodb set country_id = 100 where country_id = 1;

After the update , The data information of the sub table is :
storage
InnoDB There are two ways to store tables and indexes :
①. Use shared table space to store , The table structure of the table created in this way is saved in .frm In file , Data and indexes are stored in innodb_data_home_dir and innodb_data_file_path In the defined tablespace , It can be multiple files .
②. Using multi table space storage , The table structure of the table created in this way still exists .frm In file , But the data and index of each table are stored separately in .ibd in .
MyISAM
MyISAM Unsupported transaction 、 Foreign keys are also not supported , The advantage is the speed of access , There is no requirement for the integrity of the transaction or to SELECT、INSERT Basically, all major applications can use this engine to create tables . There are two more important features :
Unsupported transaction
create table goods_myisam(
id int NOT NULL AUTO_INCREMENT,
name varchar(20) NOT NULL,
primary key(id)
)ENGINE=myisam DEFAULT CHARSET=utf8;
File storage
Every MyISAM Stored on disk as 3 File , The file name is the same as the table name , But the extended names are :
.frm ( Storage table definition );
.MYD(MYData , Store the data );
.MYI(MYIndex , Storage index );
MEMORY
Memory The storage engine stores the table data in memory . Every MEMORY The table actually corresponds to a disk file , The format is .frm , Only the structure of the table is stored in this file , And its data files , It's all stored in memory , This is conducive to the rapid processing of data , Improve the efficiency of the whole watch .MEMORY Table access of type is very fast , Because his data is stored in memory , And by default HASH Indexes , But once the service is shut down , The data in the table will be lost .
MERGE
MERGE The storage engine is a set of MyISAM Combination of tables , these MyISAM Tables must be exactly the same structure ,MERGE The table itself does not store data , Yes MERGE Types of tables can be queried 、 to update 、 Delete operation , These operations are actually internal MyISAM Table .
about MERGE Insert operation of type table , It's through INSERT_METHOD Clause defines the inserted table , There can be 3 Different values , Use FIRST or LAST Value so that the insert operation is applied to the first or last table accordingly , Do not define this clause or define it as NO, That means you can't do this MERGE Tables perform insert operations .
It can be done to MERGE table DROP operation , But this operation just deletes MERGE The definition of the table , It has no effect on the internal table .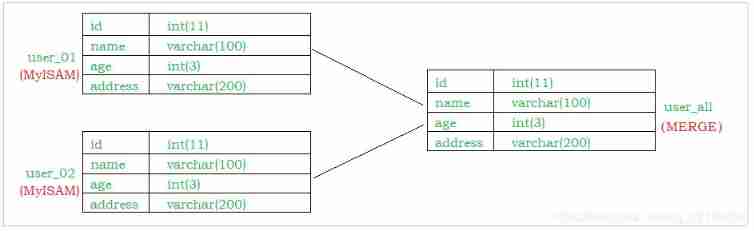
Choice of storage engine
When choosing a storage engine , The appropriate storage engine should be selected according to the characteristics of the application system . For complex applications , You can also select a variety of storage engines to combine according to the actual situation . Here are some common storage engine usage environments .
- InnoDB : yes Mysql The default storage engine for , For transactional applications , Support foreign keys . If the application has higher requirements for transaction integrity , Data consistency is required under concurrent conditions , Data operation except insert and query , It also contains a lot of updates 、 Delete operation , that InnoDB The storage engine is a better choice .InnoDB The storage engine can effectively reduce the lock caused by deletion and update , It also ensures the complete commit and rollback of the transaction , For similar billing system or financial system and other data accuracy requirements of the system ,InnoDB Is the most appropriate choice .
- MyISAM : If the application is based on read operation and insert operation , There are very few update and delete operations , And the integrity of the transaction 、 Concurrency requirements are not very high , So it's very appropriate to choose this storage engine .
- MEMORY: Save all data in RAM in , In the need for fast location records and other similar data environment , Can provide access to a few blocks .MEMORY The drawback is that there is a limit on the size of the table , Too large tables cannot be cached in memory , The second is to ensure that the data in the table can be recovered , After the abnormal termination of the database, the data in the table can be recovered .MEMORY Tables are usually used to update small tables that are less frequent , To quickly get access to results .
- MERGE: Used to equate a series of MyISAM Tables are logically combined , And refer to them as an object .MERGE The advantage of the table is that it can break through to single MyISAM Table size limit , And by distributing different tables on multiple disks , Can effectively improve MERGE Table access efficiency . It's important for storage such as data warehousing VLDB The environment is perfect .
Optimize SQL step
In the process of application development , Due to the small amount of data in the initial stage , Developers write SQL We should pay more attention to the realization of function when we make a statement , But when the application system goes online , With the rapid growth of production data , quite a lot SQL Statements begin to show performance problems , The impact on production is also growing , At this point, these problems SQL Statement becomes the bottleneck of the whole system performance , So we have to optimize them , This chapter will introduce in detail in MySQL Medium optimization SQL Method of statement .
When faced with a person who has SQL Performance issues with the database , Where should we start to make a systematic analysis , Enables the problem to be located as soon as possible SQL And solve the problem as soon as possible .
see SQL Frequency of execution
MySQL After successful client connection , adopt show [session|global] status Command can provide server status information .show [session|global] status You can add parameters as needed “session” perhaps “global” To display session level ( Current connection ) And global level ( Since the database was last started ) The statistics of . If you don't write , The default usage parameter is “session”.
The following command shows the current session The values of all statistical parameters in :
show status like 'Com_______';

show status like 'Innodb_rows_%';

Com_xxx Represent each xxx Number of statement executions , We are usually concerned with the following statistical parameters .
| Parameters | meaning |
|---|---|
| Com_select | perform select Number of operations , A query only adds up to 1. |
| Com_insert | perform INSERT Number of operations , For batch inserted INSERT operation , Only add up once . |
| Com_update | perform UPDATE Number of operations . |
| Com_delete | perform DELETE Number of operations . |
| Innodb_rows_read | select The number of rows returned by the query . |
| Innodb_rows_inserted | perform INSERT The number of rows inserted by the operation . |
| Innodb_rows_updated | perform UPDATE Number of rows updated by operation . |
| Innodb_rows_deleted | perform DELETE The number of rows deleted by the operation . |
| Connections | Trying to connect MySQL The number of servers . |
| Uptime | Server working hours . |
| Slow_queries | The number of slow queries . |
Com_*** : These parameters are accumulated for all table operations of the storage engine .
Innodb_*** : These parameters are only for InnoDB Storage engine , The algorithm of accumulation is slightly different .
Positioning inefficient execution SQL
There are two ways to locate the less efficient SQL sentence .
- Slow query log : Slow query logs to locate those that are less efficient SQL sentence , use –log-slow-queries[=file_name] When the option starts ,mysqld Write a containing all execution times over long_query_time Of a second SQL Statement log file . For details, please refer to chapter 26 The related parts of log management in Chapter 2 .
- show processlist : The slow query log is not recorded until after the end of the query , So when the application reflects the problem of execution efficiency, the query of slow query log cannot locate the problem , have access to show processlist Command to view the current MySQL Thread in progress , Including the state of the thread 、 Lock the watch, etc , Can view... In real time SQL Implementation of , At the same time, some lock table operations are optimized .

1) id Column , The user login mysql when , System assigned "connection_id", You can use functions connection_id() see
2) user Column , Show current user . If not root, This command only displays the scope of user authority sql sentence
3) host Column , Show from which ip On which port of , It can be used to track users who have problem statements
4) db Column , Shows which database the process is currently connected to
5) command Column , Displays the command executed by the current connection , Generally, the value is sleep (sleep), Inquire about (query), Connect (connect) etc.
6) time Column , Shows the duration of this state , The unit is seconds
7) state Column , Shows the... Using the current connection sql The state of the statement , A very important column .state Describes a state in the execution of a statement . One sql sentence , Take the query as an example , May need to go through copying to tmp table、sorting result、sending data Wait for the status to complete
8) info Column , Show this sql sentence , It is an important basis to judge the problem statement
explain Analysis execution plan
Through the above steps to find out the inefficient SQL After the statement , Can pass EXPLAIN perhaps DESC Command acquisition MySQL How to execute SELECT Statement information , Included in SELECT How tables are joined and the order in which they are joined during statement execution .
Inquire about SQL Statement execution plan :
explain select * from tb_item where id = 1;

| Field | meaning |
|---|---|
| id | select The serial number of the query , It's a set of numbers , Represents execution in query select Clause or the order of the operation table . |
| select_type | Express SELECT The type of , Common values are SIMPLE( A simple watch , That is, no table join or subquery is used )、PRIMARY( Main query , That is, the outer query )、UNION(UNION The second or subsequent query statement in )、SUBQUERY( First in subquery SELECT) etc. |
| table | Output result set table |
| type | Indicates the connection type of the table , The connection types with good to poor performance are ( system —> const -----> eq_ref ------> ref -------> ref_or_null----> index_merge —> index_subquery -----> range -----> index ------> all ) |
| possible_keys | When representing a query , Possible indexes |
| key | Indicates the index actually used |
| key_len | Length of index field |
| rows | Number of scan lines |
| extra | Description and description of the implementation |
explain And id
id The fields are select The serial number of the query , It's a set of numbers , Represents execution in query select Clause or the order of the operation table .id There are three situations :
1) id The same means that the order in which tables are loaded is from top to bottom .
explain select * from t_role r, t_user u, user_role ur where r.id = ur.role_id and u.id = ur.user_id ;

2) id Different id The bigger the value is. , The higher the priority , The first to be executed .
EXPLAIN SELECT * FROM t_role WHERE id = (SELECT role_id FROM user_role WHERE user_id = (SELECT id FROM t_user WHERE username = 'stu1'))

3) id It's the same , There are different , At the same time .id The same can be thought of as a group , From top to bottom ; In all groups ,id The greater the value of , The higher the priority , Execute first .
EXPLAIN SELECT * FROM t_role r , (SELECT * FROM user_role ur WHERE ur.`user_id` = '2') a WHERE r.id = a.role_id ;

explain And select_type
Express SELECT The type of , Common values , As shown in the following table :
| select_type | meaning |
|---|---|
| SIMPLE | ordinary select Inquire about , The query does not contain subqueries or UNION |
| PRIMARY | If the query contains any complex subqueries , The outermost query is marked with this identifier |
| SUBQUERY | stay SELECT or WHERE The list contains subqueries |
| DERIVED | stay FROM Subqueries included in the list , Marked as DERIVED( derivative ) MYSQL These subqueries will be executed recursively , Put the results in the provisional table |
| UNION | If the second SELECT Appear in the UNION after , Then it is marked with UNION ; if UNION Included in FROM Clause , Outer layer SELECT Will be marked as : DERIVED |
| UNION RESULT | from UNION Table to get the result SELECT |
explain And table
Show which table this row of data is about
explain And type
type It shows the type of access , Is a more important indicator , It can be taken as :
| type | meaning |
|---|---|
| NULL | MySQL Don't access any tables , Indexes , Direct return |
| system | There is only one line in the table ( It's equal to the system table ), This is a const Special case of type , In general, it will not appear |
| const | Indicates that it is found through index once ,const For comparison primary key perhaps unique Indexes . Because only one line of data is matched , So soon . For example, place the primary key in where In the list ,MySQL The query can be converted to a constant light .const At will “ Primary key ” or “ only ” All parts of the index are compared with constant values |
| eq_ref | similar ref, The difference is that you use a unique index , Use primary key Association query , There is only one record found by association . Common in primary key or unique index scan |
| ref | Non unique index scan , Returns all rows that match a single value . In essence, it is also an index access , Returns all rows that match a single value ( Multiple ) |
| range | Retrieve only rows returned for a given , Use an index to select rows . where After that between , < , > , in Wait for the operation . |
| index | index And ALL The difference is index Type just traverses the index tree , Often than ALL fast , ALL It's traversing data files . |
| all | Will traverse the entire table to find the matching rows |
The result is from the best to the worst :
NULL > system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
system > const > eq_ref > ref > range > index > ALL
Generally speaking , We need to make sure that the query is at least range Level , It's best to achieve ref .
explain And key
possible_keys : Show the indexes that may be applied to this table , One or more .
key : Actual index used , If NULL, No index is used .
key_len : Represents the number of bytes used in the index , This value is the maximum possible length of the index field , It's not the actual length , Without losing accuracy , The shorter the length, the better .
explain And rows
Number of scan lines .
explain And extra
Other additional execution plan information , Show in this column .
| extra | meaning |
|---|---|
| using filesort | explain mysql Will use an external index to sort the data , Instead of reading in the order of the indexes in the table , be called “ File sorting ”, Low efficiency . |
| using temporary | Temporary tables are used to save intermediate results ,MySQL Use temporary tables when sorting query results . Common in order by and group by; Low efficiency |
| using index | It means corresponding select The operation uses an override index , Avoid accessing table data rows , Good efficiency . |
show profile analysis SQL
Mysql from 5.0.37 The version began to add right show profiles and show profile Statement support .show profiles Be able to do SQL Optimization helps us understand where the time is spent .
adopt have_profiling Parameters , Be able to see the present MySQL Do you support profile:
Default profiling Is turned off , Can pass set Statements in Session Level on profiling:
set profiling=1; // Turn on profiling switch ;
adopt profile, We can understand more clearly SQL The process of execution .
First , We can perform a series of operations , As shown in the figure below :
show databases;
use db01;
show tables;
select * from tb_item where id < 5;
select count(*) from tb_item;
After executing the above order , Re execution show profiles Instructions , Check it out. SQL Statement execution time :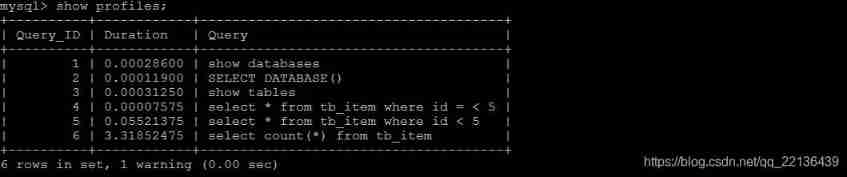
adopt show profile for query query_id You can see the SQL The state and time consumed by each thread during execution :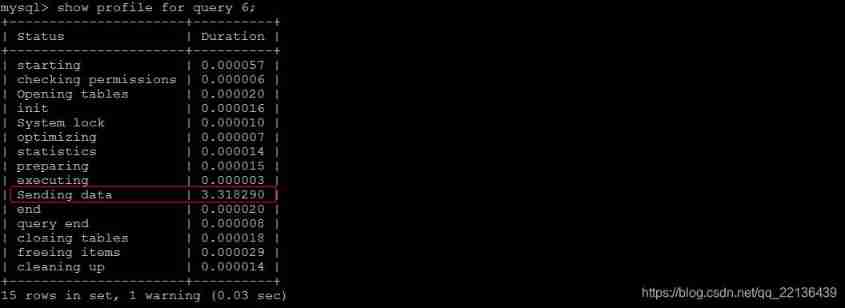
TIP :
Sending data State means MySQL The thread starts to access the data row and returns the result to the client , Instead of just returning a client . Because in Sending data State, ,MySQL Threads often need to do a lot of disk read operations , Therefore, it is often the most time-consuming state in the whole query .
After getting the most time consuming thread state ,MySQL Support further choice all、cpu、block io 、context switch、page faults And other detail type classes MySQL Spend too much time on what resources to use . for example , Select View CPU Time consuming :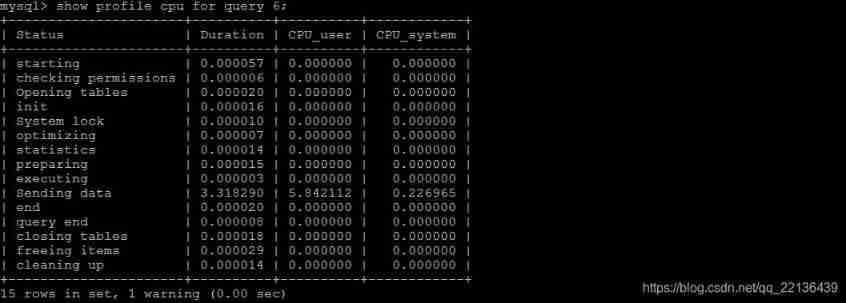
| Field | meaning |
|---|---|
| Status | sql The state of statement execution |
| Duration | sql The time of each step in the execution process |
| CPU_user | The current user has cpu |
| CPU_system | System owned cpu |
trace Analyze optimizer execution plan
MySQL5.6 Provide for the right to SQL Keep track of trace, adopt trace File to learn more about why the optimizer chose A plan , Instead of choosing B plan .
open trace , Format as JSON, And set up trace Maximum available memory size , Avoid that the default memory is too small to be fully displayed during parsing .
SET optimizer_trace="enabled=on",end_markers_in_json=on;
set optimizer_trace_max_mem_size=1000000;
perform SQL sentence :
select * from tb_item where id < 4;
Last , Check information_schema.optimizer_trace We can know MySQL How to execute SQL Of :
select * from information_schema.optimizer_trace\G;
Use of index
Avoid index invalidation
1). Full match , Specify specific values for all columns in the index . In this case , The index works , High execution efficiency .
2). The leftmost prefix rule , If you index multiple columns , Follow the leftmost prefix rule . It means that the query starts from the top left of the index , And don't skip columns in the index .
3). Range query right column , Index cannot be used .
4). Do not operate on index columns , Otherwise, the index will be invalidated .
5). String without single quotes , Cause index invalidation .
6). Try to use overlay index , avoid select *, Try to use overlay index ( Queries that only access the index ( Index column contains query column completely )), Reduce select * . If the query column , Out of index columns , It also reduces performance .
TIP :
using index : When using overlay index, it will appear
using where: In the case of search using index , You need to go back to the table to query the required data
using index condition: Search uses index , But you need to return the table to query the data
using index ; using where: Search uses index , But all the data needed can be found in the index column , So you don't need to go back to the table to query the data
7). use or The conditions of separation , If or The columns in the previous condition are indexed , And there's no index in the next column , Then the indexes involved will not be used .
Example ,name Fields are index columns , and createtime It's not an index column , In the middle is or Connection is not indexed :
8). With % At the beginning Like Fuzzy query , Index failure . If it's just tail blur matching , The index will not fail . If it's a fuzzy head match , Index failure .
9). If MySQL Evaluation uses indexes more slowly than full tables , Index is not used .
10). is NULL , is NOT NULL Sometimes Index failure . for example NULL too many values ,is NULL Don't go to the index when
11). in Go to the index , not in Index failure .
12). Single column index and composite index .
Try to use composite indexes , Use less single column indexes .
Create composite index
create index idx_name_sta_address on tb_seller(name, status, address);
It's like creating three indexes :
name
name + status
name + status + address
Create a single column index
create index idx_seller_name on tb_seller(name);
create index idx_seller_status on tb_seller(status);
create index idx_seller_address on tb_seller(address);
The database will choose an optimal index ( The most recognizable index ) To use , Not all indexes will be used .
Check index usage
show status like 'Handler_read%';
show global status like 'Handler_read%';

Handler_read_first: The number of times the first item in the index has been read . If it's higher , Indicates that the server is performing a large number of full index scans ( The lower the value, the better ).
Handler_read_key: If the index is working , This value represents the number of times a row has been read by the index value , If the value is lower , Indicates that the performance improvement of index is not high , Because indexes are not often used ( The higher the value, the better ).
Handler_read_next : Number of requests to read next line in key order . If you use range constraints or if you perform index scans to query index columns , The value increases .
Handler_read_prev: Number of requests to read the previous line in key order . This reading method is mainly used to optimize ORDER BY ... DESC.
Handler_read_rnd : The number of requests to read a line according to a fixed location . If you are executing a large number of queries and need to sort the results, the value is high . You may be using a lot of needs MySQL Scan the entire table for queries or your connection is not properly keyed . This is a higher value , It means that the operation efficiency is low , An index should be established to remedy .
Handler_read_rnd_next: Number of requests to read the next line in the data file . If you're doing a lot of scanning , The value is higher . Usually it means that your table index is not correct or the query written does not use the index .
SQL Optimize
Mass insert data
about InnoDB Type of watch , There are several ways to improve the efficiency of import :
1) Insert primary key in order
because InnoDB Tables of type are saved in the order of primary keys , So the imported data is arranged in the order of primary key , It can effectively improve the efficiency of importing data . If InnoDB Table has no primary key , Then the system will automatically create an internal column as the primary key by default , So if you can create a primary key for a table , Will be able to take advantage of this , To improve the efficiency of importing data .
2) Turn off uniqueness check
Execute... Before importing data SET UNIQUE_CHECKS=0, Turn off uniqueness check , Execute... After import SET UNIQUE_CHECKS=1, Restore uniqueness check , Can improve the efficiency of import .
3) Commit transactions manually
If the app uses auto submit , It is recommended to execute before importing SET AUTOCOMMIT=0, Turn off auto submit , After the import, execute SET AUTOCOMMIT=1, Turn on auto submit , It can also improve the efficiency of import .
Optimize insert sentence
When it comes to data insert During operation , The following optimization schemes can be considered .
If you need to insert many rows of data into a table at the same time , You should try to use more than one value table insert sentence , This way will greatly reduce the connection between the client and the database 、 Turn off consumption, etc . Make the efficiency ratio separate from the single execution insert Fast sentence .
Example , The original way is :
insert into tb_test values(1,'Tom'); insert into tb_test values(2,'Cat'); insert into tb_test values(3,'Jerry');The optimized scheme is :
insert into tb_test values(1,'Tom'),(2,'Cat'),(3,'Jerry');Data insertion in transactions .
start transaction; insert into tb_test values(1,'Tom'); insert into tb_test values(2,'Cat'); insert into tb_test values(3,'Jerry'); commit;Data is inserted in order
insert into tb_test values(4,'Tim'); insert into tb_test values(1,'Tom'); insert into tb_test values(3,'Jerry'); insert into tb_test values(5,'Rose'); insert into tb_test values(2,'Cat');After optimization
insert into tb_test values(1,'Tom'); insert into tb_test values(2,'Cat'); insert into tb_test values(3,'Jerry'); insert into tb_test values(4,'Tim'); insert into tb_test values(5,'Rose');
Optimize order by sentence
Two ways of sorting
1). The first is to sort the returned data , That is to say filesort Sort , All sorts that do not return sorting results directly through index are called FileSort Sort .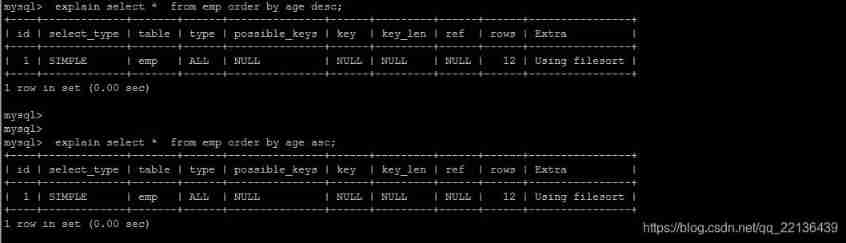
2). The second way is to return ordered data directly through ordered index scanning , This is the case using index, No need for extra sorting , High operating efficiency .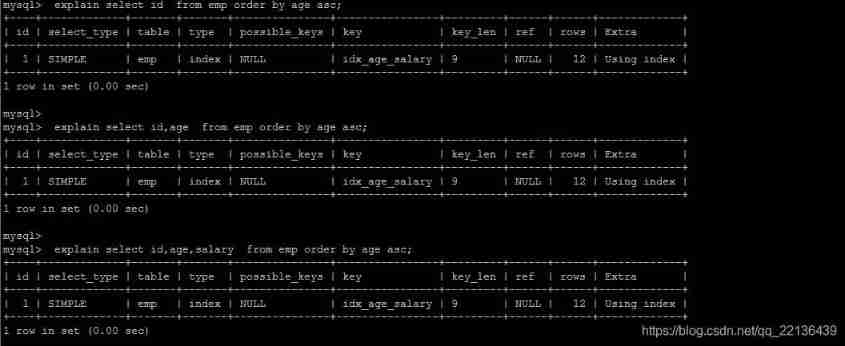
Multi field sorting 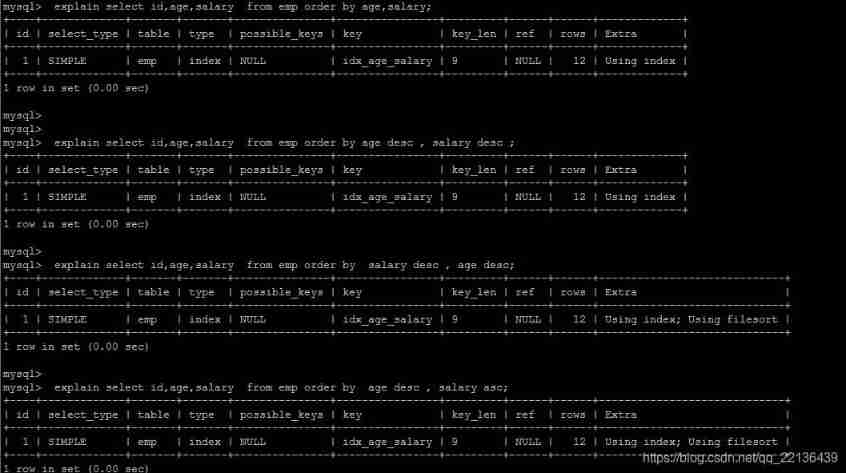
I understand MySQL Sort by , The goal of optimization is clear : Try to minimize the extra ordering , Return ordered data directly through index .where Conditions and Order by Use the same index , also Order By In the same order as the index , also Order by The fields of are all in ascending order , Or in descending order . Otherwise, extra operation is necessary , And then there will be FileSort.
Filesort The optimization of the
By creating the appropriate index , Can reduce the Filesort Appearance , But in some cases , Conditionality cannot allow Filesort disappear , Then we need to speed up Filesort The sorting operation of . about Filesort , MySQL There are two sort algorithms :
1) Two scan algorithm :MySQL4.1 Before , Use this method to sort . First, take out the sorting field and row pointer information according to the conditions , Then in the sorting area sort buffer Middle order , If sort buffer Not enough , On the temporary watch temporary table The sorting result is stored in . After sorting , Then read the record according to the row pointer back to the table , This operation may result in a large number of random I/O operation .
2) One scan algorithm : Take out all the fields that meet the conditions at once , Then in the sorting area sort buffer After sorting, output the result set directly . When sorting, memory overhead is large , But the efficiency of sorting is higher than that of twice scanning algorithm .
MySQL By comparing system variables max_length_for_sort_data The size and Query The total size of the field taken out by the statement , To determine the sort algorithm , If max_length_for_sort_data Bigger , Then use the second optimized algorithm ; Otherwise use the first .
Can be improved properly sort_buffer_size and max_length_for_sort_data System variables , To increase the size of the sorting area , Improve the efficiency of sorting .
Optimize group by sentence
because GROUP BY In fact, the sorting operation will also be carried out , And with the ORDER BY comparison ,GROUP BY It's mainly about the grouping operation after sorting . Of course , If some other aggregate functions are used when grouping , So we need to calculate some aggregate functions . therefore , stay GROUP BY During the implementation of , And ORDER BY You can also use the index .
If the query contains group by But users want to avoid the consumption of sorting results , Then you can execute order by null No sorting . as follows :
drop index idx_emp_age_salary on emp;
explain select age,count(*) from emp group by age;

After optimization
explain select age,count(*) from emp group by age order by null;

As can be seen from the above example , first SQL The statement needs to be "filesort", And the second one. SQL because order by null There is no need for “filesort”, As mentioned above Filesort It's very time consuming .
Create index :
create index idx_emp_age_salary on emp(age,salary);

Optimize nested queries
Mysql4.1 After the version , Start supporting SQL Subquery of . This technology can be used SELECT Statement to create a single column query result , Then use this result as a filter in another query . Using subquery can complete many logical steps at once SQL operation , At the same time, transaction or table lock can be avoided , And it's easy to write . however , In some cases , Subqueries can be joined more efficiently (JOIN) replace .
Example , Find all user information with roles :
explain select * from t_user where id in (select user_id from user_role );
The execution plan is :
After optimization :
explain select * from t_user u , user_role ur where u.id = ur.user_id;

Connect (Join) The reason why queries are more efficient , Because MySQL There is no need to create a temporary table in memory to complete this logically two-step query .
Optimize OR Conditions
To contain OR Query clause for , If you want to use indexes , be OR Each condition column between must use an index , And you can't use composite indexes ; If there is no index , You should consider adding indexes .
obtain emp All indexes in the table :
Example :
explain select * from emp where id = 1 or age = 30;
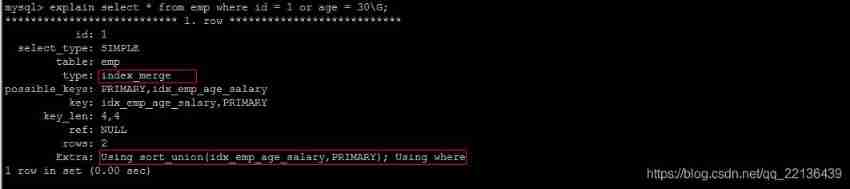
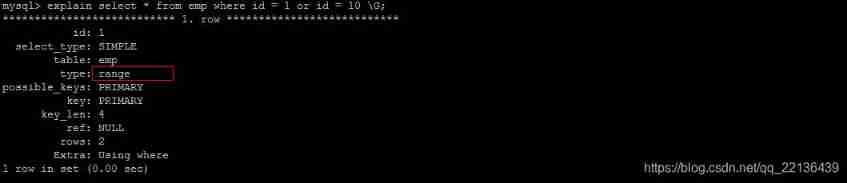
It is recommended to use union Replace or :
Let's compare the important indicators , The main difference was found to be type and ref These two
type It shows the type of access , Is a more important indicator , The result value is from good to bad :
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
UNION Of the statement type The value is ref,OR Of the statement type The value is range, You can see that this is a very clear gap
UNION Of the statement ref The value is const,OR Of the statement type The value is null,const Represents a constant value reference , Very fast
The difference between the two shows that UNION Is better than OR .
Optimize paging queries
General paging query , Better performance can be achieved by creating indexes . A common and very troublesome problem is limit 2000000,10 , At this time need MySQL Before ordering 2000010 Record , Just go back to 2000000 - 2000010 The record of , Other records discarded , The cost of query sorting is very high .
Optimization idea 1
Complete sort paging operation on Index , Finally, according to the primary key Association, return to the original table to query other column contents .
Optimization idea II
This scheme is applicable to tables with self increasing primary key , You can put Limit The query is converted to a query in a certain location .
Use SQL Tips
SQL Tips , Is an important means to optimize the database , Simply speaking , Is in the SQL Add some human prompts in the statement to optimize the operation .
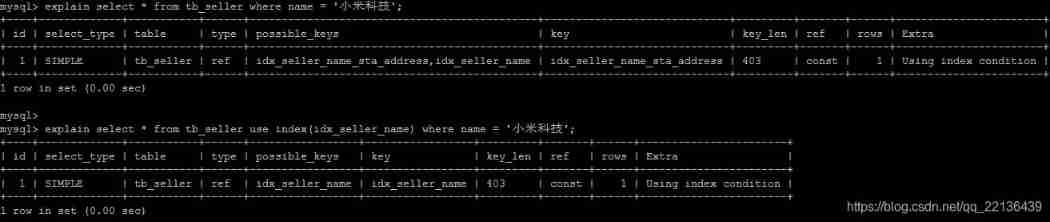
USE INDEX
After the table name in the query statement , add to use index To provide hope MySQL To refer to the index list , You can make MySQL No longer consider other available indexes .
create index idx_seller_name on tb_seller(name);
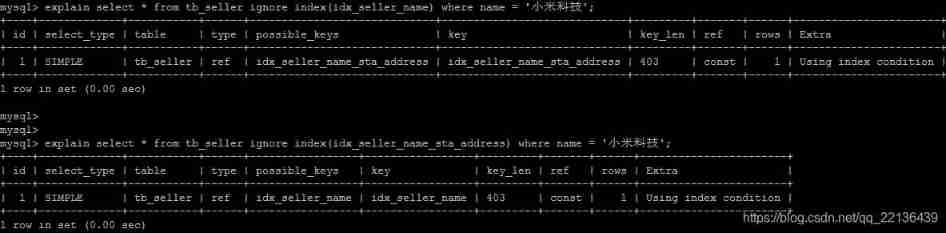
IGNORE INDEX
If the user just wants to let MySQL Ignore one or more indexes , You can use ignore index As hint .
explain select * from tb_seller ignore index(idx_seller_name) where name = ' Xiaomi Tech ';
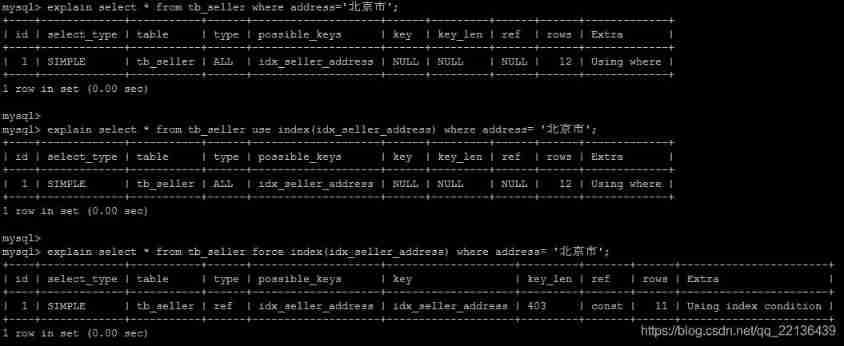
FORCE INDEX
Is mandatory MySQL Use a specific index , It can be used in query force index As hint .
create index idx_seller_address on tb_seller(address);
Application optimization
Previous content , We introduced many database optimization measures . But in the actual production environment , Due to the performance limitations of the database itself , It is necessary to optimize the application of the foreground , To reduce the pressure of database access .
Use connection pool
For accessing databases , The cost of establishing a connection is more expensive , Because we often create closed connections , It's more resource consuming , We need to establish Database connection pool , To improve access performance .
Reduce to MySQL The interview of
Avoid duplicate retrieval of data
When writing application code , Need to be able to clarify the access logic to the database . Able to get results in one connection , You don't have to connect twice , This can greatly reduce unnecessary repeated requests to the database .
such as , Need to get books id and name Field , Then query as follows :
select id , name from tb_book;
after , In business logic, it is necessary to obtain the book status information , Then query as follows :
select id , status from tb_book;
such , You need to submit two requests to the database , The database has to do two queries . Actually, you can use one SQL Statement to get the desired result .
select id, name , status from tb_book;
increase cache layer
In the application , We can increase the cache layer in the application to reduce the burden of the database . There are many kinds of cache layers , There are also many ways to implement , As long as it can reduce the burden of the database and meet the application requirements .
Therefore, part of the data can be extracted from the database and stored in the application side in the form of text , Or use a framework (Mybatis, Hibernate) First level cache provided / Second level cache , Or use redis Database to cache data .
Load balancing
Load balancing is a very common optimization method in application , Its mechanism is to use some kind of equalization algorithm , Distribute the fixed load to different servers , To reduce the load of a single server , Achieve the optimized effect .
utilize MySQL Copy split query
adopt MySQL Master-slave replication of , Read and write separation , Make add, delete, and change the primary node , Query operation goes from node , Thus, the reading and writing pressure of a single server can be reduced .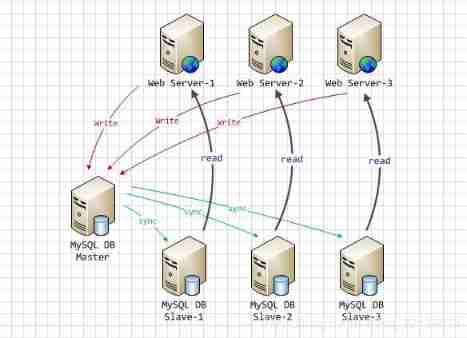
Adopt distributed database architecture
Distributed database architecture is suitable for large data volume 、 High load , It has good expansibility and high availability . By distributing data between multiple servers , Load balancing among multiple servers can be realized , Improve access efficiency .
Mysql Query cache optimization in
summary
Turn on Mysql The query cache , When performing exactly the same SQL At the time of statement , The server will read the results directly from the cache , When the data is modified , The previous cache will fail , Tables with frequent changes are not suitable for query caching .
Operation process
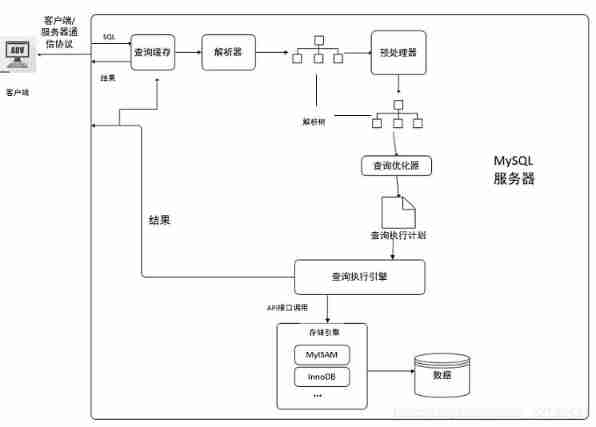
- The client sends a query to the server ;
- The server first checks the query cache , If the cache is hit , Then immediately return the result stored in the cache . Otherwise move on to the next stage ;
- On the server side SQL analysis 、 Preprocessing , Then the optimizer generates the corresponding execution plan ;
- MySQL According to the execution plan generated by the optimizer , To invoke the storage engine API To execute the query ;
- Returns the result to the client .
Query cache configuration
View the current MySQL Does the database support query caching :
SHOW VARIABLES LIKE 'have_query_cache';

2. View the current MySQL Whether query caching is enabled :
SHOW VARIABLES LIKE 'query_cache_type';

3. Check the usage size of query cache :
SHOW VARIABLES LIKE 'query_cache_size';

4. View the status variables of the query cache :
SHOW STATUS LIKE 'Qcache%';

The meaning of each variable is as follows :
| Parameters | meaning |
|---|---|
| Qcache_free_blocks | Query the number of available memory blocks in the cache |
| Qcache_free_memory | The amount of memory available in the query cache |
| Qcache_hits | Query Cache Hits |
| Qcache_inserts | Number of queries added to the query cache |
| Qcache_lowmen_prunes | The number of queries deleted from the query cache due to insufficient memory |
| Qcache_not_cached | The number of non cached queries ( because query_cache_type Set and cannot be cached or not cached ) |
| Qcache_queries_in_cache | Number of queries registered in the query cache |
| Qcache_total_blocks | Total number of blocks in Query Cache |
Turn on query cache
MySQL The query cache of is turned off by default , Parameters need to be configured manually query_cache_type , To open the query cache .query_cache_type There are three values of this parameter :
| value | meaning |
|---|---|
| OFF or 0 | Query caching is off |
| ON or 1 | Query cache function on ,SELECT If the result meets the caching conditions, it will be cached , otherwise , No caching , Explicitly specify SQL_NO_CACHE, No caching |
| DEMAND or 2 | The query cache function is on demand , Explicitly specify SQL_CACHE Of SELECT Statements are cached ; Others are not cached |
stay /usr/my.cnf Configuration in progress , Add the following configuration :
Once configured , Restart the service to take effect ;
You can then execute... On the command line SQL Statement to verify , It takes a lot of time to execute SQL sentence , Then do it a few more times , Check the execution time of the next few times ; Get the number of cache hits by viewing the query cache , To determine whether to go to query cache .
The query cache SELECT Options
Can be in SELECT Statement specifies two options related to query caching :
SQL_CACHE : If the query results are cacheable , also query_cache_type The value of the system variable is ON or DEMAND , Then cache the query results .
SQL_NO_CACHE : The server does not use query caching . It does not check the query cache , Also does not check whether the results are cached , Also do not cache query results .
Example :
SELECT SQL_CACHE id, name FROM customer;
SELECT SQL_NO_CACHE id, name FROM customer;
Query cache failure
1) SQL In case of Inconsistent Statements , To hit the query cache , Of the query SQL Statements must be consistent .
SQL1 : select count(*) from tb_item;
SQL2 : Select count(*) from tb_item;
2) When there is some uncertainty in the query statement , Will not cache . Such as : now() , current_date() , curdate() , curtime() , rand() , uuid() , user() , database() .
SQL1 : select * from tb_item where updatetime < now() limit 1;
SQL2 : select user();
SQL3 : select database();
3) Do not use any table query statements .
select 'A';
4) Inquire about mysql, information_schema or performance_schema When tables in the database , Does not walk query cache .
select * from information_schema.engines;
5) Functions in storage , Queries executed within the body of a trigger or event .
6) If the table changes , All cached queries that use this table will become invalid and be removed from the cache . This includes the use of MERGE Queries mapped to tables that have changed tables . A table can be used by many types of statements , If changed INSERT, UPDATE, DELETE, TRUNCATE TABLE, ALTER TABLE, DROP TABLE, or DROP DATABASE .
Mysql Memory management and optimization
Memory optimization principles
1) Allocate as much memory as possible to MySQL Do the cache , But reserve enough memory for the operating system and other programs .
2) MyISAM The data file reading of the storage engine depends on the operating system itself IO cache , therefore , If there is MyISAM surface , We need to reserve more memory for the operating system IO cache .
3) Sorting area 、 Caches such as connection areas are allocated to each database session (session) A dedicated , The default value should be set according to the maximum number of connections , If the setting is too large , Not only waste resources , And when the concurrent connection is high, the physical memory will be exhausted .
MyISAM Memory optimization
myisam Storage engine use key_buffer Cache index blocks , Speed up myisam Reading and writing speed of index . about myisam Data block of table ,mysql There is no special caching mechanism , Completely dependent on the operating system IO cache .
key_buffer_size
key_buffer_size decision MyISAM Size of index block cache , Directly affect MyISAM Table access efficiency . Can be in MySQL Parameter file key_buffer_size Value , For the average MyISAM database , Suggest at least general 1/4 Available memory is allocated to key_buffer_size.
stay /usr/my.cnf Do the following configuration in :
key_buffer_size=512M
read_buffer_size
If frequent sequential scanning is needed myisam surface , By increasing read_buffer_size Value to improve performance . But it should be noted that read_buffer_size Is each session Exclusive , If the default setting is too large , Memory is wasted .
read_rnd_buffer_size
For those that need to be sorted myisam Table in the query , If with order by Clause sql, Add... Appropriately read_rnd_buffer_size Value , Can improve this kind of sql performance . But it should be noted that read_rnd_buffer_size Is each session Exclusive , If the default setting is too large , Memory is wasted .
InnoDB Memory optimization
innodb Use a block of memory to do IO Buffer pool , The cache pool is not just for caching innodb The index block of , And it's also used to cache innodb A block of data .
innodb_buffer_pool_size
This variable determines innodb Maximum cache size to store engine table data and index data . Under the condition that the operating system and other programs have enough memory available ,innodb_buffer_pool_size The greater the value of , The higher the cache hit rate , visit InnoDB The disk required by the table I/O The less , The higher the performance .
innodb_buffer_pool_size=512M
innodb_log_buffer_size
To determine the innodb Size of redo log cache , For large transactions that can generate a large number of update records , increase innodb_log_buffer_size Size , You can avoid innodb Perform unnecessary log writes to disk before the transaction is committed .
innodb_log_buffer_size=10M
Mysql Concurrent parameter adjustment
In terms of implementation ,MySQL Server It's a multithreaded structure , Including background thread and customer service thread . Multithreading can make effective use of server resources , Improve the concurrent performance of database . stay Mysql in , The main parameters that control concurrent connections and threads include max_connections、back_log、thread_cache_size、table_open_cahce.
max_connections
use max_connections Control allows connection to MySQL The maximum number of databases , The default value is 151. If the state variable connection_errors_max_connections Not zero , And it keeps growing , It means that there are continuous connection requests failed due to the maximum number of database connections , It is possible to consider increasing max_connections Value .
Mysql Maximum number of connections supported , It depends on many factors , Include the quality of the thread library for a given operating system platform 、 Memory size 、 Load per connection 、CPU Processing speed of , Expected response time, etc . stay Linux Under the platform , Good performance server , Support 500-1000 A connection is not difficult , You need to evaluate settings based on server performance .
back_log
back_log Parameter control MySQL monitor TCP The size of the backlog request stack set at port . If MySql The number of connections reached max_connections when , New requests will be stored in the stack , To wait for a connection to release resources , The number of stacks is back_log, If the number of waiting connections exceeds back_log, Will not be granted connection resources , Will be an error .5.6.6 Before version, the default value was 50 , Later versions default to 50 + (max_connections / 5), But not more than 900.
If you need a database to handle a large number of connection requests in a short time , You can consider increasing it appropriately back_log Value .
table_open_cache
This parameter is used to control all SQL Statement execution thread can open the number of table cache , And in the execution SQL When the sentence is , every last SQL The thread of execution must at least be open 1 Table cache . The value of this parameter should be based on the maximum number of connections set max_connections And the maximum number of tables involved in the execution of the associated query for each connection :
max_connections x N ;
thread_cache_size
In order to speed up the connection to the database ,MySQL A certain number of customer service threads will be cached for reuse , Through parameters thread_cache_size Controllable MySQL Number of cached customer service threads .
innodb_lock_wait_timeout
This parameter is used to set InnoDB Transaction waiting time for row lock , The default value is 50ms , It can be set dynamically as required . For business systems that need quick feedback , The waiting time of row lock can be reduced , To avoid long-term transaction suspension ; For batch processors running in the background , You can increase the waiting time of the row lock , To avoid large rollback operations .
Mysql The lock problem
Lock overview
A lock is a mechanism by which a computer coordinates multiple processes or threads to access a resource concurrently ( Avoid fighting ).
In the database , In addition to traditional computing resources ( Such as CPU、RAM、I/O etc. ) Beyond contention , Data is also a resource that is Shared by many users . How to ensure the consistency of data concurrent access 、 Validity is a problem that all databases must solve , Lock conflicts are also an important factor affecting the performance of concurrent database access . From this perspective , Locks are especially important for databases , It's more complicated .
Lock classification
From the granularity of data operations :
1) Table locks : In operation , Will lock the entire table .
2) Row lock : In operation , Will lock the current action line .
From the type of data operation :
1) Read the lock ( Shared lock ): For the same data , Multiple read operations can be performed simultaneously without affecting each other .
2) Write lock ( Exclusive lock ): Before the current operation is completed , It blocks other write and read locks .
Mysql lock
Relative to other databases ,MySQL The locking mechanism is relatively simple , The most notable feature is that different storage engines support different locking mechanisms . The following table lists the support of each storage engine for locks :
| Storage engine | Table lock | Row-level locks | Page lock |
|---|---|---|---|
| MyISAM | Support | I won't support it | I won't support it |
| InnoDB | Support | Support | I won't support it |
| MEMORY | Support | I won't support it | I won't support it |
| BDB | Support | I won't support it | Support |
MySQL this 3 The characteristics of seed locks can be summarized as follows :
| Lock type | characteristic |
|---|---|
| Table lock | deviation MyISAM Storage engine , Low overhead , Locked fast ; A deadlock will not occur ; Large locking size , The highest probability of lock collisions , Lowest degree of concurrency . |
| Row-level locks | deviation InnoDB Storage engine , Spending big , Lock the slow ; A deadlock occurs ; Locking granularity minimum , The lowest probability of lock collisions , The highest degree of concurrency . |
| Page lock | Cost and lock time are between table lock and row lock ; A deadlock occurs ; Lock granularity is between table lock and row lock , The concurrency is average . |
It can be seen from the above characteristics that , It's hard to generalize which lock is better , Only on the characteristics of specific applications, which lock is more suitable ! Only from the point of view of lock : Table-level locking is better suited for query-oriented locking , Only a small number of applications update data by index criteria , Such as Web application ; Row level lock is more suitable for a large number of concurrent updates of different data according to index conditions , At the same time, it has the application of parallel query , Like some online transactions (OLTP) System .
MyISAM Table locks
MyISAM The storage engine only supports table locks , This is also MySQL The only lock type supported in the first few versions .
How to lock the watch
MyISAM In the execution of the query statement (SELECT) front , Will automatically lock all tables involved , Is performing an update operation (UPDATE、DELETE、INSERT etc. ) front , Will automatically lock the tables involved , This process does not require user intervention , therefore , Users generally don't need to use LOCK TABLE Order to MyISAM The watch is explicitly locked .
Show table lock Syntax :
Add read lock : lock table table_name read;
Add write lock : lock table table_name write;
Read lock case
Prepare the environment
create database demo_03 default charset=utf8mb4;
use demo_03;
CREATE TABLE `tb_book` (
`id` INT(11) auto_increment,
`name` VARCHAR(50) DEFAULT NULL,
`publish_time` DATE DEFAULT NULL,
`status` CHAR(1) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=myisam DEFAULT CHARSET=utf8 ;
INSERT INTO tb_book (id, name, publish_time, status) VALUES(NULL,'java Programming idea ','2088-08-01','1');
INSERT INTO tb_book (id, name, publish_time, status) VALUES(NULL,'solr Programming idea ','2088-08-08','0');
CREATE TABLE `tb_user` (
`id` INT(11) auto_increment,
`name` VARCHAR(50) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=myisam DEFAULT CHARSET=utf8 ;
INSERT INTO tb_user (id, name) VALUES(NULL,' linghu chong ');
INSERT INTO tb_user (id, name) VALUES(NULL,' Tian boguang ');
client One :
1) get tb_book The reading lock of the watch
lock table tb_book read;
2) Perform query operation
select * from tb_book;

It can be executed normally , Find out the data .
client Two :
3) Perform query operation
select * from tb_book;

client One :
4) Query an unlocked table
select name from tb_seller;

client Two :
5) Query an unlocked table
select name from tb_seller;

You can query the unlocked table normally ;
client One :
6) Perform the insert operation
insert into tb_book values(null,'Mysql senior ','2088-01-01','1');

Execution insert , Direct error , Due to the current tb_book What you get is Read the lock , Cannot perform update operation .
client Two :
7) Perform the insert operation
insert into tb_book values(null,'Mysql senior ','2088-01-01','1');

When releasing the lock command in client one unlock tables after , In client 2 inesrt sentence , Execute now ;
Write lock cases
client One :
1) get tb_book The writing lock of the watch
lock table tb_book write ;
2) Perform query operation
select * from tb_book ;

Query operation executed successfully ;
3) Perform an update operation
update tb_book set name = 'java Programming idea ( The second edition )' where id = 1;

Update operation executed successfully ;
client Two :
4) Perform query operation
select * from tb_book ;

When releasing the lock command in client one unlock tables after , In client 2 select sentence , Execute now ;
Conclusion
The lock modes are compatible with each other as shown in the table :
As can be seen from the above table :
1) Yes MyISAM Read operation of table , Does not block other users' read requests for the same table , But it blocks write requests to the same table ;
2) Yes MyISAM Write operation of table , Will block other users to read and write to the same table ;
In short , It's just that reading locks block writing , But it doesn't block reading . And write lock , It will block reading , Will block writing again .
Besides ,MyISAM Read and write lock scheduling is write first , This is also MyISAM The reason why it's not suitable to be a storage engine for write based tables . Because after writing the lock , No other thread can do anything , A large number of updates will make it difficult for queries to get locks , And cause permanent obstruction .
Check lock contention
show open tables;
In_user : The number of times the table is currently being queried . If the number is zero , The watch is open , But it's not being used at the moment .
Name_locked: Whether the table name is locked . Name locking is used to cancel or rename a table .
show status like 'Table_locks%';

Table_locks_immediate : It refers to the number of times table level locks can be obtained immediately , Every time you get a lock immediately , It's worth adding 1.
Table_locks_waited : It refers to the number of times to wait for a table level lock that cannot be acquired immediately , Every time I wait , It's worth plus 1, The high value indicates that there is a serious table level lock contention .
InnoDB Row lock
Introduction to line lock
Line lock features : deviation InnoDB Storage engine , Spending big , Lock the slow ; A deadlock occurs ; Locking granularity minimum , The lowest probability of lock collisions , The highest degree of concurrency .
InnoDB And MyISAM There are two big differences : One is to support affairs ; Two is Row level lock is used .
Background knowledge
Affairs and ACID attribute
The business is made up of a group of SQL A logical processing unit made up of statements .
The transaction has the following 4 A feature , Short for business ACID attribute .
| ACID attribute | meaning |
|---|---|
| Atomicity (Atomicity) | A transaction is an atomic unit of operation , Its modification of data , All or nothing , All or nothing . |
| Uniformity (Consistent) | At the beginning and end of the transaction , Data must be consistent . |
| Isolation, (Isolation) | The database system provides a certain isolation mechanism , Ensure that transactions are not affected by external concurrent operations “ Independent ” Operation in environment . |
| persistence (Durable) | After the transaction completes , The modification of the data is permanent . |
Problems caused by concurrent transaction processing
| problem | meaning |
|---|---|
| Lost update (Lost Update) | When two or more transactions select the same row , The original transaction modifies the value , It will be overwritten by the value modified by subsequent transactions . |
| Dirty reading (Dirty Reads) | When a transaction is accessing data , And the data has been modified , This modification has not yet been committed to the database , At this time , Another transaction also accesses this data , And then I used this data . |
| It can't be read repeatedly (Non-Repeatable Reads) | A time after a transaction reads some data , Read the previously read data again , But it was found that it was inconsistent with the data read out before . |
| Fantasy reading (Phantom Reads) | A transaction re reads the previously queried data according to the same query criteria , However, it is found that other transactions have inserted new data satisfying their query criteria . |
Transaction isolation level
In order to solve the problem of transaction concurrency mentioned above , The database provides a transaction isolation mechanism to solve this problem . The more strict the transaction isolation of the database , The less side effects , But the more it costs , Because transaction isolation is essentially the use of transactions to a certain extent “ Serialization ” Conduct , This is obviously related to “ Concurrent ” Is contradictory .
The isolation level of the database is 4 individual , From low to high Read uncommitted、Read committed、Repeatable read、Serializable, These four levels can solve dirty writing one by one 、 Dirty reading 、 It can't be read repeatedly 、 These questions of unreal reading .
| Isolation level | Lost update | Dirty reading | It can't be read repeatedly | Fantasy reading |
|---|---|---|---|---|
| Read uncommitted | × | √ | √ | √ |
| Read committed | × | × | √ | √ |
| Repeatable read( Default ) | × | × | × | √ |
| Serializable | × | × | × | × |
remarks : √ Represents the possibility of , × Means there won't be .
Mysql The default isolation level of the database is Repeatable read , View by :
show variables like 'tx_isolation';

InnoDB The row lock mode of
InnoDB Two types of row locks are implemented .
- Shared lock (S): Also known as read lock , abbreviation S lock , Shared lock is that multiple transactions can share a lock for the same data , All have access to data , But it can only be read but not modified .
- Exclusive lock (X): Also known as write lock , abbreviation X lock , Exclusive locks are not allowed to coexist with other locks , For example, a transaction acquires an exclusive lock of a data row , Other transactions can no longer acquire other locks of the row , Including shared lock and exclusive lock , But the transaction of acquiring exclusive lock can read and modify data on line .
about UPDATE、DELETE and INSERT sentence ,InnoDB An exclusive lock will be automatically added to the involved data set (X);
For ordinary SELECT sentence ,InnoDB No locks ;
You can add shared lock or exclusive lock to the recordset through the following statement .
Shared lock (S):SELECT * FROM table_name WHERE ... LOCK IN SHARE MODE
Exclusive lock (X) :SELECT * FROM table_name WHERE ... FOR UPDATE
Case preparation
create table test_innodb_lock(
id int(11),
name varchar(16),
sex varchar(1)
)engine = innodb default charset=utf8;
insert into test_innodb_lock values(1,'100','1');
insert into test_innodb_lock values(3,'3','1');
insert into test_innodb_lock values(4,'400','0');
insert into test_innodb_lock values(5,'500','1');
insert into test_innodb_lock values(6,'600','0');
insert into test_innodb_lock values(7,'700','0');
insert into test_innodb_lock values(8,'800','1');
insert into test_innodb_lock values(9,'900','1');
insert into test_innodb_lock values(1,'200','0');
create index idx_test_innodb_lock_id on test_innodb_lock(id);
create index idx_test_innodb_lock_name on test_innodb_lock(name);
Line lock basic demonstration
| Session-1 | Session-2 |
|---|---|
 Turn off auto submit Turn off auto submit | Turn off auto submit |
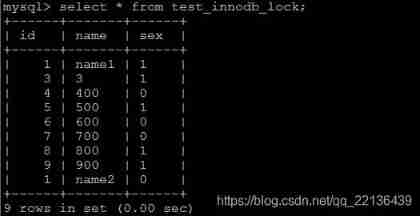 All data can be queried normally All data can be queried normally | All data can be queried normally |
 Inquire about id by 3 The data of ; Inquire about id by 3 The data of ; | obtain id by 3 The data of ; |
 to update id by 3 The data of , But don't submit ; to update id by 3 The data of , But don't submit ; |  to update id by 3 The data of , In a waiting state to update id by 3 The data of , In a waiting state |
 adopt commit, Commit transaction adopt commit, Commit transaction |  unblocked , The update is running normally unblocked , The update is running normally |
| above , It's all the same row of data , Next , Demonstrate data from different peers : | |
 to update id by 3 data , Get the row lock normally , Perform the update ; to update id by 3 data , Get the row lock normally , Perform the update ; |  Because of and Session-1 The operation is not on the same line , Get the current row lock , Perform the update ; Because of and Session-1 The operation is not on the same line , Get the current row lock , Perform the update ; |
No index row lock upgraded to table lock
If you don't retrieve data by index criteria , that InnoDB Lock all records in the table , The actual effect is the same as the watch lock .
View the index of the current table : show index from test_innodb_lock ;
| Session-1 | Session-2 |
|---|---|
 Turn off automatic commit of transactions Turn off automatic commit of transactions | Turn off automatic commit of transactions |
 Execute UPDATE statement Execute UPDATE statement |  Execute UPDATE statement , But it's blocked Execute UPDATE statement , But it's blocked |
 Commit transaction Commit transaction |  unblocked , Update executed successfully unblocked , Update executed successfully |
 Perform commit operation Perform commit operation |
because On update , name The field was originally varchar type , We use it as an array type , There is a type conversion , Index failure , Finally, row lock becomes table lock ;
Gap lock hazard
When we use range conditions , Instead of using equal conditions to retrieve data , And request sharing or exclusive lock ,InnoDB Lock the existing data that meets the conditions ; For records where the key value is in the condition range but does not exist , be called “ The gap (GAP)” , InnoDB It's also about this “ The gap ” Lock , This locking mechanism is called Clearance lock (Next-Key lock ) .
Example :
| Session-1 | Session-2 |
|---|---|
 Turn off automatic transaction commit Turn off automatic transaction commit | Turn off automatic transaction commit |
 according to id Range update data according to id Range update data | |
 Insert id by 2 The record of , In a blocked state Insert id by 2 The record of , In a blocked state | |
 Commit transaction ; Commit transaction ; | |
 unblocked , Perform the insert operation unblocked , Perform the insert operation | |
| Commit transaction : |
InnoDB Row lock contention
show status like 'innodb_row_lock%';

Innodb_row_lock_current_waits: The number of currently waiting locks
Innodb_row_lock_time: The total length of time from system startup to lock up
Innodb_row_lock_time_avg: The average time spent waiting
Innodb_row_lock_time_max: The longest waiting time from system startup to now
Innodb_row_lock_waits: The total number of times the system has been waiting since it was started
When the number of waits is high , And every time the waiting time is not small , We need to analyze why there are so many waits in the system , Then according to the results of the analysis to develop optimization plan .
summary
InnoDB The storage engine implements row level locking , Although in the implementation of locking mechanism, the performance loss may be higher than that of table locking , But in terms of the overall concurrent processing capacity, it is far more due to MyISAM The watch is locked . When the system concurrency is high ,InnoDB The overall performance and MyISAM There will be obvious advantages in comparison .
however ,InnoDB The row level lock also has its weak side , When we don't use it properly , May let InnoDB The overall performance of MyISAM high , Even worse .
Optimization Suggestions :
- As far as possible, all data retrieval can be completed through index , Avoid upgrading non indexed row locks to table locks .
- Design index reasonably , Try to narrow down the range of locks
- Minimize index conditions , And index range , Avoid gap locks
- Try to control the transaction size , Reduce the amount of locked resources and the length of time
- Use low level transaction isolation as much as possible ( But it needs to be met at the business level )
Commonly used SQL skill
SQL Execution order
Writing order
SELECT DISTINCT
<select list>
FROM
<left_table> <join_type>
JOIN
<right_table> ON <join_condition>
WHERE
<where_condition>
GROUP BY
<group_by_list>
HAVING
<having_condition>
ORDER BY
<order_by_condition>
LIMIT
<limit_params>
Execution order
FROM <left_table>
ON <join_condition>
<join_type> JOIN <right_table>
WHERE <where_condition>
GROUP BY <group_by_list>
HAVING <having_condition>
SELECT DISTINCT <select list>
ORDER BY <order_by_condition>
LIMIT <limit_params>
Regular expressions use
Regular expressions (Regular Expression) It refers to a single string used to describe or match a series of strings conforming to a certain syntax rule .
| Symbol | meaning |
|---|---|
| ^ | Match at the beginning of a string |
| $ | Match at the end of the string |
| . | Match any single character , Include line breaks |
| […] | Match any character in parentheses |
| [^…] | Can't match any characters in parentheses |
| a* | Match zero or more a( Including empty strings ) |
| a+ | Match one or more a( It doesn't include empty strings ) |
| a? | Match zero or one a |
| a1|a2 | matching a1 or a2 |
| a(m) | matching m individual a |
| a(m,) | Match at least m individual a |
| a(m,n) | matching m individual a To n individual a |
| a(,n) | matching 0 To n individual a |
| (…) | Make pattern elements into a single element |
select * from emp where name regexp '^T';
select * from emp where name regexp '2$';
select * from emp where name regexp '[uvw]';
MySQL Common functions
Number function
| The name of the function | do use |
|---|---|
| ABS | Find the absolute value |
| SQRT | Find the quadratic root |
| MOD | Mod |
| CEIL and CEILING | The two functions have the same function , All return the minimum integer no less than the parameter , That is, round up |
| FLOOR | Rounding down , The return value is converted to a BIGINT |
| RAND | Generate a 0~1 Random number between , The input integer parameter is , Used to generate repeat sequences |
| ROUND | Round the parameters passed |
| SIGN | Returns the symbol of the parameter |
| POW and POWER | The functions of the two functions are the same , Are the result values of the power of the passed parameters |
| SIN | Find the sine |
| ASIN | Find the inverse sine , And functions SIN They're inverse functions to each other |
| COS | Find the cosine |
| ACOS | Find the inverse cosine , And functions COS They're inverse functions to each other |
| TAN | Find tangent |
| ATAN | Find the arctangent , And functions TAN They're inverse functions to each other |
| COT | Find the cotangent value |
String function
| The name of the function | do use |
|---|---|
| LENGTH | Evaluate string length function , Returns the byte length of the string |
| CONCAT | Merge string functions , The return result is the string generated by the connection parameter , Parameters can make one or more |
| INSERT | Replace string functions |
| LOWER | Convert the letters in the string to lowercase |
| UPPER | Convert the letters in the string to uppercase |
| LEFT | Take the string from the left side of the word , Returns several characters to the left of the string |
| RIGHT | Take the string from the right word , Returns several characters to the right of the string |
| TRIM | Delete the spaces on the left and right of the string |
| REPLACE | String replacement function , Return the new string after replacement |
| SUBSTRING | Intercepting string , Returns a character change of a specified length starting at a specified location |
| REVERSE | String inversion ( The reverse ) function , Returns the string in reverse order to the original string |
Date function
| The name of the function | do use |
|---|---|
| CURDATE and CURRENT_DATE | The two functions work the same , Returns the date value of the current system |
| CURTIME and CURRENT_TIME | The two functions work the same , Returns the time value of the current system |
| NOW and SYSDATE | The two functions work the same , Returns the date and time values of the current system |
| MONTH | Get the month in the specified date |
| MONTHNAME | Get the English name of the month in the specified date |
| DAYNAME | Get the English name of the day of the week corresponding to the specified date |
| DAYOFWEEK | Gets the index location value of the week corresponding to the specified date |
| WEEK | Get the specified date is the week of the year , Whether the return value range is 0〜52 or 1〜53 |
| DAYOFYEAR | The date of acquisition is the day of the year , The return value range is 1~366 |
| DAYOFMONTH | Get the specified date is the day of the month , The return value range is 1~31 |
| YEAR | Get year , The return value range is 1970〜2069 |
| TIME_TO_SEC | Convert the time parameter to seconds |
| SEC_TO_TIME | Convert seconds to time , And TIME_TO_SEC They're inverse functions to each other |
| DATE_ADD and ADDDATE | The two functions have the same function , All add the specified time interval to the date |
| DATE_SUB and SUBDATE | The two functions have the same function , It's all subtracting the specified time interval from the date |
| ADDTIME | Time addition operation , Add the specified time... To the original time |
| SUBTIME | Time subtraction , Subtract the specified time from the original time |
| DATEDIFF | Get the interval between two dates , Returns the parameter 1 Subtract the parameter 2 Value |
| DATE_FORMAT | Format the specified date , Returns the value of the specified format according to the parameter |
| WEEKDAY | Get the corresponding working day index of the specified date in a week |
Aggregate functions
| The name of the function | effect |
|---|---|
| MAX | Query the maximum value of the specified column |
| MIN | Query the minimum value of the specified column |
| COUNT | Count the number of rows in the query result |
| SUM | Sum up , Returns the sum of the specified columns |
| AVG | averaging , Returns the average of the specified column data |
MySql Common tools in
mysql
The mysql Don't mean mysql service , But to mysql Client tools .
grammar :
mysql [options] [database]
Connection options
Parameters :
-u, --user=name Specify user name
-p, --password[=name] Specified password
-h, --host=name Specify the server IP Or domain name
-P, --port=# Specify the connection port
Example :
mysql -h 127.0.0.1 -P 3306 -u root -p
mysql -h127.0.0.1 -P3306 -uroot -p2143
Execution Options
-e, --execute=name perform SQL Statement and exit
This option is available in Mysql Client execution SQL sentence , Instead of connecting to MySQL The database then executes , For some batch scripts , This is especially convenient .
Example :
mysql -uroot -p2143 db01 -e "select * from tb_book";
mysqladmin
mysqladmin Is a client program that performs administrative operations . It can be used to check the configuration and current state of the server 、 Create and delete databases, etc .
Can pass : mysqladmin --help Command to view help documents 
Example :
mysqladmin -uroot -p2143 create 'test01';
mysqladmin -uroot -p2143 drop 'test01';
mysqladmin -uroot -p2143 version;
mysqlbinlog
Because the binary log file generated by the server is saved in binary format , So if you want to check the text format of these texts , Will be used to mysqlbinlog Log management tools .
grammar :
mysqlbinlog [options] log-files1 log-files2 ...
Options :
-d, --database=name : Specify database name , Only the specified database related operations are listed .
-o, --offset=# : Ignore the previous in the log n Line command .
-r,--result-file=name : Output the output text format log to the specified file .
-s, --short-form : Show simple format , Omit some information .
--start-datatime=date1 --stop-datetime=date2 : All logs within the specified date interval .
--start-position=pos1 --stop-position=pos2 : All logs within the specified location interval .
mysqldump
mysqldump Client tools are used to back up databases or migrate data between different databases . The backup includes creating tables , And insert the SQL sentence .
grammar :
mysqldump [options] db_name [tables]
mysqldump [options] --database/-B db1 [db2 db3...]
mysqldump [options] --all-databases/-A
Connection options
Parameters :
-u, --user=name Specify user name
-p, --password[=name] Specified password
-h, --host=name Specify the server IP Or domain name
-P, --port=# Specify the connection port
Output content options
Parameters :
--add-drop-database Add... Before each database creation statement Drop database sentence
--add-drop-table Add... Before each table creation statement Drop table sentence , Default on ; Don't open (--skip-add-drop-table)
-n, --no-create-db Do not include database creation statements
-t, --no-create-info Create statement without data table
-d --no-data No data
-T, --tab=name Automatically generate two files : One .sql file , Statement to create a table structure ;
One .txt file , Data files , amount to select into outfile
Example :
mysqldump -uroot -p2143 db01 tb_book --add-drop-database --add-drop-table > a
mysqldump -uroot -p2143 -T /tmp test city
mysqlimport/source
mysqlimport Is the client data import tool , Used to import mysqldump Add -T The text file exported after the parameter .
grammar :
mysqlimport [options] db_name textfile1 [textfile2...]
Example :
mysqlimport -uroot -p2143 test /tmp/city.txt
If you need to import sql file , have access to mysql Medium source Instructions :
source /root/tb_book.sql
mysqlshow
mysqlshow Client object finder , Used to quickly find which databases exist 、 Tables in the database 、 A column or index in a table .
grammar :
mysqlshow [options] [db_name [table_name [col_name]]]
Parameters :
--count Display statistics of databases and tables ( database , surface You can not specify )
-i Display the status information of the specified database or table
Example :
# Query the number of tables in each database and the number of records in the table
mysqlshow -uroot -p2143 --count
# Inquire about test The fields in each table in the library , And the number of lines
mysqlshow -uroot -p2143 test --count
# Inquire about test In the library book Details of the table
mysqlshow -uroot -p2143 test book --count
Mysql journal
In any database , There are all kinds of logs , It records all aspects of database work , To help the database administrator track all kinds of events that have happened in the database .MySQL No exception , stay MySQL in , Yes 4 Different kinds of logs , They are error logs 、 Binary log (BINLOG journal )、 Query log and slow query log , These logs record the trace of database in different aspects .
Error log
The error log is MySQL One of the most important logs in , It records when mysqld When starting and stopping , As well as information about any serious errors in the running process of the server . When there is any failure of the database that results in the failure of normal use , You can check this log first .
The log is on by default , The default storage directory is mysql Data directory for (var/lib/mysql), The default log file name is hostname.err(hostname It's the host name ).
View log location instructions :
show variables like 'log_error%';

Check the log content :
tail -f /var/lib/mysql/xaxh-server.err

Binary log
summary
Binary log (BINLOG) It records all the DDL( Data definition language ) Statement and DML( Data manipulation language ) sentence , But it does not include data query statements . This log plays an extremely important role in data recovery in case of disaster ,MySQL Master-slave replication of , Through this binlog Realized .
Binary log , It is not enabled by default , Need to MySQL In the configuration file of , And configuration MySQL Format of log .
Profile location : /usr/my.cnf
Log storage location : When the configuration , File name given but no path specified , Log default write Mysql Data directory for .
# Configuration on binlog journal , The file prefix of the log is mysqlbin -----> The generated file name is as follows : mysqlbin.000001,mysqlbin.000002
log_bin=mysqlbin
# Configure binary log format
binlog_format=STATEMENT
Log format
STATEMENT
The log format is recorded in the log file SQL sentence (statement), Every one of the items that modify the data SQL Will be recorded in the log file , adopt Mysql Provided mysqlbinlog Tools , You can see the text of each statement clearly . When master and slave copy , Slave Library (slave) Will resolve the log to the original text , And execute it again from the library .
ROW
The log format records the data changes of each line in the log file , Instead of recording SQL sentence . such as , perform SQL sentence : update tb_book set status=‘1’ , If it is STATEMENT Log format , A line will be recorded in the log SQL file ; If it is ROW, Because it's updating the whole table , That is to say, every line of record will change ,ROW The data changes of each line will be recorded in the format log .
MIXED
This is the present time. MySQL Default log format , It's a mixture of STATEMENT and ROW Two formats . By default STATEMENT, But in some special cases ROW To record .MIXED The format can make the best of the advantages of the two modes , And avoid their shortcomings .
Log reading
Because logs are stored in binary form , Can't read directly , Need to use mysqlbinlog Tools to view , The grammar is as follows :
mysqlbinlog log-file;
see STATEMENT Format log
Execute insert statement :
insert into tb_book values(null,'Lucene','2088-05-01','0');
view log file :
mysqlbin.index : This file is a log index file , The filename of the log ;
mysqlbing.000001 : Log files
Check the log content :
mysqlbinlog mysqlbing.000001;
see ROW Format log
To configure :
# Configuration on binlog journal , The file prefix of the log is mysqlbin -----> The generated file name is as follows : mysqlbin.000001,mysqlbin.000002
log_bin=mysqlbin
# Configure binary log format
binlog_format=ROW
insert data :
insert into tb_book values(null,'SpringCloud actual combat ','2088-05-05','0');
If the log format is ROW , Check the data directly , I don't understand ; Can be in mysqlbinlog Add parameters after -vv
mysqlbinlog -vv mysqlbin.000002
Log delete
For busy systems , Due to the large amount of logs generated every day , If these logs are not clear for a long time , It will take up a lot of disk space . Next we will explain several common ways to delete logs :
Mode one
adopt Reset Master Command to delete all binlog journal , After deleting , Log number , Will be taken from xxxx.000001 restart .
Before query , First query the log file :

Execute the delete log instruction :
Reset Master
After performing , view log file :
Mode two
Execution instruction purge master logs to 'mysqlbin.******', The command will delete ****** All logs before numbering .
Mode three
Execution instruction purge master logs before 'yyyy-mm-dd hh24:mi:ss', This command will delete the log as “yyyy-mm-dd hh24:mi:ss” All logs generated before .
Mode 4
Set parameters --expire_logs_days=# , The meaning of this parameter is to set the expiration days of logs , After the specified number of days, the log will be automatically deleted , This will help to reduce DBA The workload of managing logs .
The configuration is as follows :
Query log
The query log records all the operation statements of the client , Binary log does not contain query data SQL sentence .
By default , The query log is not opened . If you need to open the query log , You can set the following configuration :
# This option is used to open the query log , Optional value : 0 perhaps 1 ; 0 On behalf of closed , 1 Representative opens
general_log=1
# Set the file name of the log , If not specified , The default filename is host_name.log
general_log_file=file_name
stay mysql Configuration file for /usr/my.cnf The following is configured in :
Once configured , Do the following in the database :
select * from tb_book;
select * from tb_book where id = 1;
update tb_book set name = 'lucene Getting started ' where id = 5;
select * from tb_book where id < 8;
After execution , Let's query the log file again :
Slow query log
The slow query log records that all execution times exceed the parameters long_query_time Set the value and the number of scan records is not less than min_examined_row_limit All of SQL Statement log .long_query_time The default is 10 second , The minimum is 0, The precision can reach microseconds .
File location and format
Slow query log is off by default . Slow query log can be controlled by two parameters :
# This parameter is used to control whether the slow query log is turned on , Value for : 1 and 0 , 1 Representative opens , 0 On behalf of closed
slow_query_log=1
# This parameter is used to specify the file name of the slow query log
slow_query_log_file=slow_query.log
# This option is used to configure the query time limit , Beyond this time will be considered value slow query , Will need to log , Default 10s
long_query_time=10
Log reading
And error logs 、 The query log is the same , The format of slow query log records is also plain text , Can be read directly .
1) Inquire about long_query_time Value .
2) Perform query operation
select id, title,price,num ,status from tb_item where id = 1;

Because the execution time of this statement is very short , by 0s , So it will not be recorded in the slow query log .
select * from tb_item where title like '% Alcatel (OT-927) carbon black Unicom 3G mobile phone Double card double waiting 165454%' ;

The SQL sentence , The execution time is 26.77s , exceed 10s , So it will be recorded in the slow query log file .
3) View slow query log file
Directly through cat Command to query the log file :
If slow query log content is a lot , Look directly at the file , More trouble , At this time, we can use mysql Self contained mysqldumpslow Tools , To classify and summarize the slow query logs .
Mysql Copy
Copy Overview
Replication refers to the main database DDL and DML The operation is passed to the database server through binary log , Then re execute the logs on the slave database ( It's also called redoing ), In this way, the data of the slave database and the master database can be synchronized .
MySQL One master database can be copied to multiple slave databases at the same time , The slave library can also be used as the master library of other slave servers , Achieve Chain replication .
The principle of replication
MySQL The principle of master-slave replication is as follows .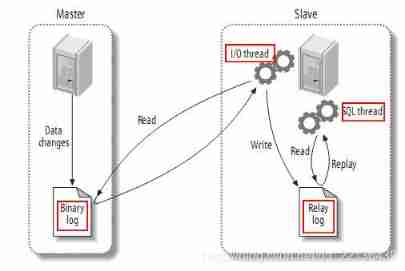
From the top , Replication is divided into three steps :
- Master When the main database commits the transaction , Will change data as time Events Record in binary log file Binlog in .
- The main library pushes binary log files Binlog Log events in to relay logs from the library Relay Log .
- slave Redo events in relay log , Will change the data that reflects itself .
Replication advantages
MySQL The of replication mainly includes the following three aspects :
- There's something wrong with the main database , You can quickly switch to providing services from the library .
- You can perform query operations on the slave database , Update from main library , Read and write separation , Reduce the access pressure of the main library .
- You can perform a backup from the library , To avoid affecting the service of the primary database during backup .
边栏推荐
- Cmake Express
- 汇编课后作业
- The "advertising maniacs" in this group of programmers turned Tiktok advertisements into ar games
- Continue and break jump out of multiple loops
- ByteDance new programmer's growth secret: those glittering treasures mentors
- 面试集锦库
- Soft music -js find the number of times that character appears in the string - Feng Hao's blog
- ~72 horizontal and vertical alignment of text
- string. How to choose h and string and CString
- Shell_ 03_ environment variable
猜你喜欢
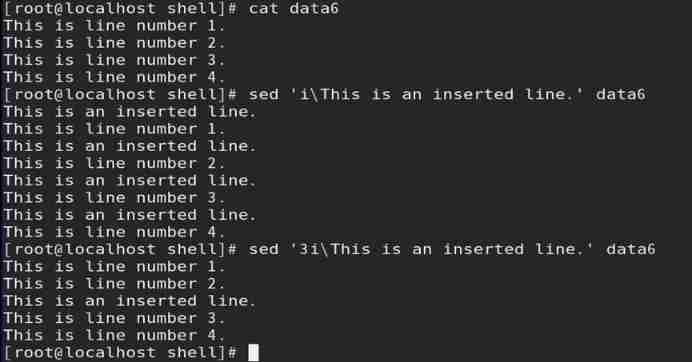
Shell_ 02_ Text three swordsman
LeetCode 1560. The sector with the most passes on the circular track
The QT program compiled on CentOS lacks a MySQL driven solution
Fdog series (V): use QT to imitate QQ to realize login interface to main interface, function chapter.
koa中间件

LeetCode 1584. Minimum cost of connecting all points

7-4 harmonic average
Solr word segmentation analysis
Gridhome, a static site generator that novices must know
Alibaba cloud server builds SVN version Library
随机推荐
Cmake error: could not create named generator visual studio 16 2019 solution
Shell_ 02_ Text three swordsman
Introduction to microservices
I'm "fixing movies" in ByteDance
Error: case label `15 'not within a switch statement
汇编语言段定义
Description of project structure configuration of idea
面试集锦库
LeetCode 1641. Count the number of Lexicographic vowel strings
DS18B20数字温度计系统设计
J'ai traversé le chemin le plus fou, le circuit cérébral d'un programmeur de saut d'octets
谢邀,人在工区,刚交代码,在下字节跳动实习生
Cmake Express
Saw local status change event StatusChangeEvent [timestamp=1644048792587, current=DOWN, previous=UP]
Eureka single machine construction
字节跳动2022校招研发提前批宣讲会,同学们最关心的10个问题
7-8 likes (need to continue to improve)
LeetCode1556. Thousand separated number
Record the error reason
LeetCode 1561. The maximum number of coins you can get