当前位置:网站首页>encoderMapReduce 随手记
encoderMapReduce 随手记
2022-07-06 09:15:00 【@小蜗牛】
目录
1、MapReduce定义
将这些数据切分成三块,然后分别计算处理这些数据(Map),
处理完毕之后发送到一台机器上进行合并(merge),
再计算合并之后的数据,归纳(reduce)并输出。
Java 中包含3个函数:
map分割数据集
reduce处理数据
job对象来运行MapReduce作业,
2、MapReduce统计两个文本文件中,每个单词出现的次数
首先我们在当前目录下创建两个文件:
创建file01输入内容:
Hello World Bye World
创建file02输入内容:
Hello Hadoop Goodbye Hadoop
将文件上传到HDFS的/usr/input/目录下:
不要忘了启动DFS:
start-dfs.sh
public class WordCount {
//Mapper类
/*因为文件默认带有行数,LongWritable是用来接受文件中的行数, 第一个Text是用来接受文件中的内容, 第二个Text是用来输出给Reduce类的key, IntWritable是用来输出给Reduce类的value*/
public static class TokenizerMapper
extends Mapper<LongWritable, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
//创建配置对象
Configuration conf = new Configuration();
//创建job对象
Job job = new Job(conf, "word count");
//设置运行job的类
job.setJarByClass(WordCount.class);
//设置Mapper的类
job.setMapperClass(TokenizerMapper.class);
//设置Reduce的类
job.setReducerClass(IntSumReducer.class);
//设置输出的key value格式
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置输入路径
String inputfile = "/usr/input";
//设置输出路径
String outputFile = "/usr/output";
//执行输入
FileInputFormat.addInputPath(job, new Path(inputfile));
//执行输出
FileOutputFormat.setOutputPath(job, new Path(outputFile));
//是否运行成功,true输出0,false输出1
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
hadoop的MapReduce与hdfs中一定要先启动start-dfs.sh
3、用MapReduce计算班级每个学生的最好成绩
import java.io.IOException;
import java.util.StringTokenizer;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
/********** Begin **********/
public static class TokenizerMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
private int maxValue = 0;
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString(),"\n");
while (itr.hasMoreTokens()) {
String[] str = itr.nextToken().split(" ");
String name = str[0];
one.set(Integer.parseInt(str[1]));
word.set(name);
context.write(word,one);
}
//context.write(word,one);
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
**int maxAge = 0;
int age = 0;
for (IntWritable intWritable : values) {
maxAge = Math.max(maxAge, intWritable.get());
}
result.set(maxAge);**
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
String inputfile = "/user/test/input";
String outputFile = "/user/test/output/";
FileInputFormat.addInputPath(job, new Path(inputfile));
FileOutputFormat.setOutputPath(job, new Path(outputFile));
job.waitForCompletion(true);
/********** End **********/
}
}
4、 MapReduce 文件内容合并去重
import java.io.IOException;
import java.util.*;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class Merge {
/** * @param args * 对A,B两个文件进行合并,并剔除其中重复的内容,得到一个新的输出文件C */
//在这重载map函数,直接将输入中的value复制到输出数据的key上 注意在map方法中要抛出异常:throws IOException,InterruptedException
/********** Begin **********/
public static class Map extends Mapper<LongWritable, Text, Text, Text >
{
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
String str = value.toString();
String[] data = str.split(" ");
Text t1= new Text(data[0]);
Text t2 = new Text(data[1]);
context.write(t1,t2);
}
}
/********** End **********/
//在这重载reduce函数,直接将输入中的key复制到输出数据的key上 注意在reduce方法上要抛出异常:throws IOException,InterruptedException
/********** Begin **********/
public static class Reduce extends Reducer<Text, Text, Text, Text>
{
protected void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
List<String> list = new ArrayList<>();
for (Text text : values) {
String str = text.toString();
if(!list.contains(str)){
list.add(str);
}
}
Collections.sort(list);
for (String text : list) {
context.write(key, new Text(text));
}
}
/********** End **********/
}
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
Job job = new Job(conf, "word count");
job.setJarByClass(Merge.class);
job.setMapperClass(Map.class);
job.setCombinerClass(Reduce.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
String inputPath = "/user/tmp/input/"; //在这里设置输入路径
String outputPath = "/user/tmp/output/"; //在这里设置输出路径
FileInputFormat.addInputPath(job, new Path(inputPath));
FileOutputFormat.setOutputPath(job, new Path(outputPath));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
边栏推荐
- [download app for free]ineukernel OCR image data recognition and acquisition principle and product application
- About string immutability
- 快来走进JVM吧
- Request object and response object analysis
- Machine learning -- census data analysis
- Double to int precision loss
- [CDH] modify the default port 7180 of cloudera manager in cdh/cdp environment
- [CDH] cdh5.16 configuring the setting of yarn task centralized allocation does not take effect
- [number theory] divisor
- Nanny level problem setting tutorial
猜你喜欢
Why can't I use the @test annotation after introducing JUnit
Reading BMP file with C language
Cookie setting three-day secret free login (run tutorial)
Vs2019 use wizard to generate an MFC Application
Mtcnn face detection

QT creator create button
![[CDH] cdh5.16 configuring the setting of yarn task centralized allocation does not take effect](/img/e7/a0d4fc58429a0fd8c447891c848024.png)
[CDH] cdh5.16 configuring the setting of yarn task centralized allocation does not take effect
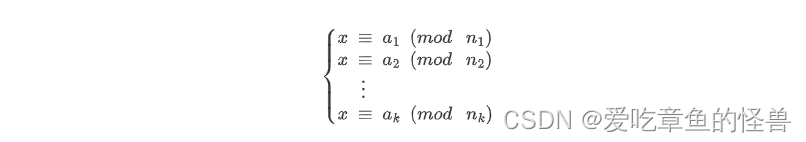
AcWing 1298. Solution to Cao Chong's pig raising problem
Unable to call numpy in pycharm, with an error modulenotfounderror: no module named 'numpy‘

{一周总结}带你走进js知识的海洋
随机推荐
Word排版(小计)
Deoldify project problem - omp:error 15:initializing libiomp5md dll,but found libiomp5md. dll already initialized.
Install mongdb tutorial and redis tutorial under Windows
第4阶段 Mysql数据库
数数字游戏
MTCNN人脸检测
QT creator uses Valgrind code analysis tool
牛客Novice月赛40
Solution of deleting path variable by mistake
nodejs 详解
Dotnet replaces asp Net core's underlying communication is the IPC Library of named pipes
库函数--(持续更新)
Database advanced learning notes -- SQL statement
【kerberos】深入理解kerberos票据生命周期
解决安装Failed building wheel for pillow
Pytorch基础
误删Path变量解决
{one week summary} take you into the ocean of JS knowledge
Test objects involved in safety test
Why can't STM32 download the program