当前位置:网站首页>Redis highly available slice cluster
Redis highly available slice cluster
2022-07-05 12:18:00 【Xujunsheng】
Redis Highly available slice cluster
Preface
【 It's the Spring Festival , I wish you all a new year , Good health , prosperous .】
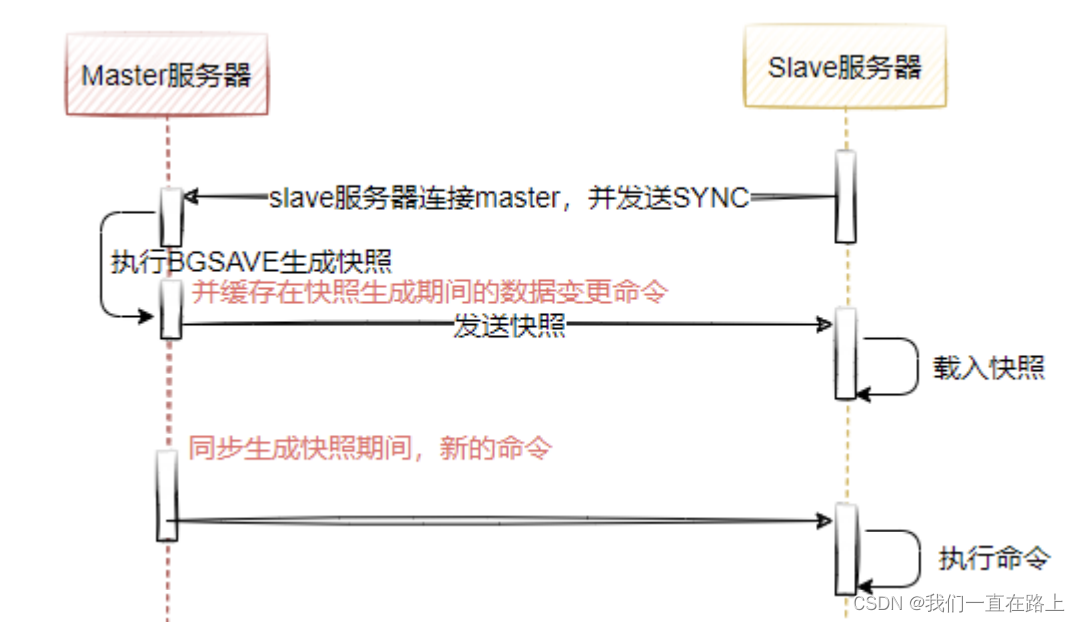
In the previous article, we analyzed several Redis High availability solutions . Include :「 A master-slave mode 」、「 Sentinel mechanism 」 as well as 「 The sentry cluster 」.
- 「 A master-slave mode 」 With read-write separation , Share the reading pressure 、 The data backup , Advantages such as providing multiple copies .
- 「 Sentinel mechanism 」 After the master node fails, it can automatically promote the slave node to the master node , Service availability can be restored without manual intervention .
- 「 The sentry cluster 」 Solve single point of failure and single sentinel generation 「 Miscalculation 」 problem .
Redis From the simplest stand-alone version , After data persistence 、 Master slave multiple copies 、 The sentry cluster , Through such optimization , Whether it's performance or stability , It's getting higher and higher .
But as time goes on , The business volume of the company has witnessed explosive growth , The architecture model at this time , Can we still afford such a large amount of traffic ?
For example, there is such a demand : Use Redis preservation 5000 ten thousand Key value pairs , Each key value pair is about 512B, In order to rapidly deploy and provide services , We use virtual machine to run Redis example , that , How to select the memory capacity of the virtual machine ?
By calculation , The memory space occupied by these key value pairs is about 25GB(5000 ten thousand *512B).
The first plan I came up with was : Choose one 32GB In memory virtual machine deployment Redis. because 32GB Memory can hold all data , And there are 7GB, It can ensure the normal operation of the system .
meanwhile , Also used RDB Persistent data , In order to ensure that Redis After instance failure , And from RDB Restore data .
however , In the process of using, you will find ,Redis The response can be very slow at times . adopt INFO command see Redis Of latest_fork_usec Index value ( Represents the last time fork Time consuming ), It was found that the index value was particularly high .
This one Redis It has something to do with the persistence mechanism of .
In the use of RDB When persisting ,Redis Meeting fork Sub process to complete ,fork Operation time and Redis The amount of data is positively correlated , and fork The main thread will be blocked during execution . More data ,fork The longer the main thread is blocked by the operation .
therefore , In the use of RDB Yes 25GB When data is persisted , Large amount of data , The child processes running in the background are fork The main thread was blocked during creation , This leads to Redis Slow response .
Obviously, this plan is not feasible , We have to find other solutions .
How to save more data ?
In order to save a lot of data , We generally have two methods :「 Vertical expansion 」 and 「 Horizontal scaling 」:
- Vertical expansion : Upgrade single Redis Instance resource allocation , Including increasing memory capacity 、 Increase disk capacity 、 Use a higher configuration of CPU;
- Horizontal scaling : Horizontal increase current Redis Number of instances .
First ,「 Vertical expansion 」 Are the benefits of , It's easy to implement 、 direct . however , This solution also faces two potential problems .
- The first question is , When using RDB When data is persisted , If the amount of data increases , The amount of memory needed will also increase , The main thread
forkChild processes may block . - The second question is : Vertical expansion will be limited by hardware and cost . It's easy to understand , After all , Remove memory from 32GB Extended to 64GB It's easy , however , To expand to 1TB, It will face the limitation of hardware capacity and cost .
And 「 Vertical expansion 」 comparison ,「 Horizontal scaling 」 It is a scheme with better scalability . This is because , To save more data , If we adopt this plan , Just add Redis Just the number of instances , Don't worry about the hardware and cost limitations of a single instance .
Redis Clustering is based on 「 Horizontal scaling 」 Realized , By starting multiple Redis Instances form a cluster , And then according to certain rules , Divide the received data into multiple copies , Each copy is saved with an instance .
Redis colony
Redis Cluster is a distributed database solution , Cluster adoption Fragmentation (sharding, It can also be called section ) To share data , It also provides replication and failover capabilities .
Back in the scene we just had , If you put 25GB The data are divided equally into 5 Share ( Of course , You can't even it ), Use 5 An instance to save , Each instance only needs to be saved 5GB data . As shown in the figure below :
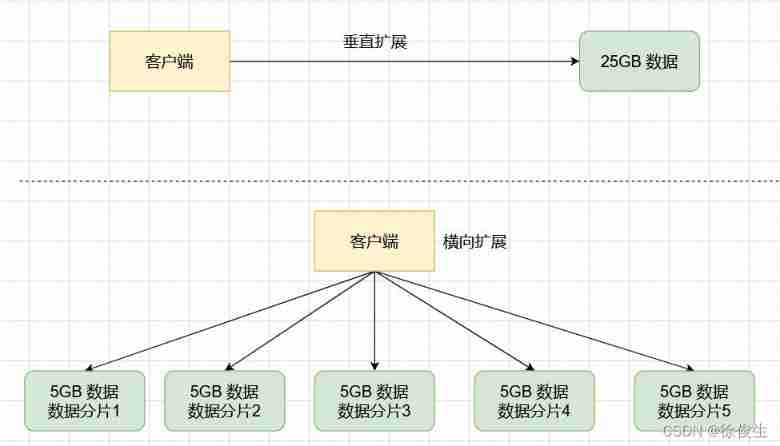
that , In a slice cluster , The example is 5GB The data generated RDB when , The amount of data is much smaller ,fork A child process will not block the main thread for a long time .
After saving data slices with multiple instances , We can keep it 25GB data , Again, avoid fork The response of a child process blocking the main thread suddenly slows down .
In practical application Redis when , With the expansion of the business , Saving large amounts of data is often unavoidable . and Redis colony , Is a very good solution .
Now we begin to study how to build a Redis colony ?
build Redis colony
One Redis A cluster usually consists of multiple nodes , At the beginning , Each node is independent of each other , There is no association between nodes . Build a working cluster , We have to Connect the independent nodes get up , Constitute a Cluster with multiple nodes .
We can go through CLUSTER MEET command , Connect the nodes :
CLUSTER MEET <ip> <port>
- ip: Nodes to be added to the cluster ip
- port: Nodes to be added to the cluster port
Command specification : By going to a node A send out CLUSTER MEET command , The node that can receive the command A Put another node B Add to node A In the cluster .
It's a little abstract , Here's an example .
Suppose there are now three independent nodes 127.0.0.1:7001、 127.0.0.1:7002、 127.0.0.1:7003.
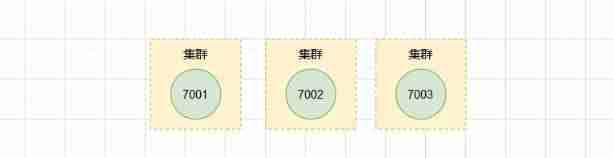
We first use the client to connect to the node 7001:
$ redis-cli -c -p 7001
And then to the node 7001 dispatch orders , The nodes 7002 Add to 7001 In the cluster :
127.0.0.1:7001> CLUSTER MEET 127.0.0.1 7002
alike , We ask 7003 dispatch orders , Also added to the 7001 and 7002 The cluster .
127.0.0.1:7001> CLUSTER MEET 127.0.0.1 7003
adopt
CLUSTER NODESThe command can view the node information in the cluster .
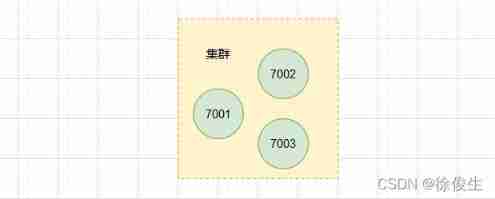
Now the cluster contains 7001、 7002 and 7003 Three nodes . however , When using a single instance , Where does the data exist , Where does the client access , It's all very clear . however , Slice clustering inevitably involves Distributed management of multiple instances .
To use slice clusters , We need to solve two major problems :
- After slicing the data , How to distribute among multiple instances ?
- How can the client determine which instance of the data it wants to access ?
Next , We'll solve it one by one .
The corresponding distribution relationship between data slice and instance
In a slice cluster , Data needs to be distributed across different instances , that , How do data and instances correspond ?
This is related to the following Redis Cluster The plan is about . however , We need to figure out the slice clusters and Redis Cluster The connection and difference between .
stay Redis 3.0 Before , The official does not provide a specific scheme for slicing clusters . from 3.0 Start , The official offer is called
Redis ClusterThe plan , For slicing clusters .
actually , Slice clustering is a general mechanism for storing large amounts of data , This mechanism can have different implementation schemes . Redis Cluster The corresponding rules of data and instances are specified in the scheme .
say concretely , Redis Cluster The scheme adopts Hash slot (Hash Slot), To handle the mapping between data and instances .
Hash slot and Redis Instance mapping
stay Redis Cluster In the plan , A slice cluster has 16384 Hash slot (2^14), These hash slots are similar to data partitions , Each key value pair will be based on its key, Is mapped to a hash slot .
What we analyzed above , adopt CLUSTER MEET The order will 7001、7002、7003 Three nodes are connected to the same cluster , But this cluster is currently in Offline status Of , Because the three nodes in the cluster are not assigned any slots .
that , How these hash slots are mapped to specific Redis On the instance ?
We can use CLUSTER MEET Command to manually establish a connection between instances , Forming clusters , Reuse CLUSTER ADDSLOTS command , Specify the number of hash slots on each instance .
CLUSTER ADDSLOTS <slot> [slot ...]
Redis5.0 Provide
CLUSTER CREATECommand create cluster , Use this command ,Redis These slots are automatically evenly distributed on cluster instances .
for instance , We pass the following order , to 7001、7002、7003 The three nodes are assigned slots .
Put the groove 0 ~ Slot 5000 Assign to to 7001 :
127.0.0.1:7001> CLUSTER ADDSLOTS 0 1 2 3 4 ... 5000
Put the groove 5001 ~ Slot 10000 Assign to to 7002 :
127.0.0.1:7002> CLUSTER ADDSLOTS 5001 5002 5003 5004 ... 10000
Put the groove 10001~ Slot 16383 Assign to to 7003 :
127.0.0.1:7003> CLUSTER ADDSLOTS 10001 10002 10003 10004 ... 16383
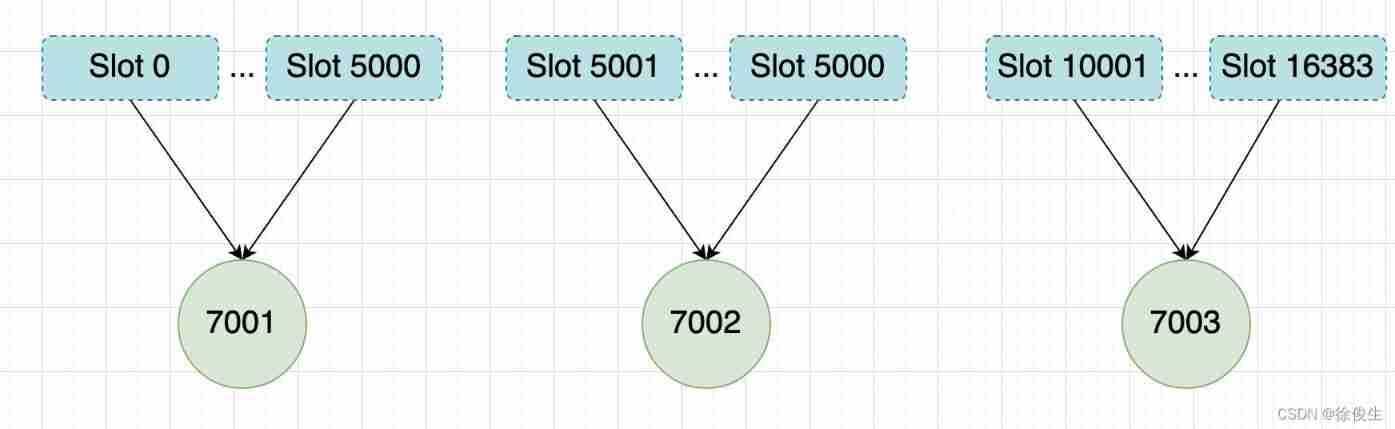
When three CLUSTER ADDSLOTS After all the commands are executed , In the database 16384 Slots have been assigned to corresponding nodes , At this time, the cluster goes online .
Through hash slot , The slice cluster realizes the data to the hash slot 、 Allocation of hash slots to instances .
however , Even if the instance has the mapping information of the hash slot , How does the client know which instance the data to be accessed is on ?
How the client locates the data ?
Generally speaking , After the connection between the client and the cluster instance is established , The instance will send the hash slot allocation information to the client . however , When the cluster was just created , Each instance only knows which hash slots it has been assigned , Do not know the hash slot information owned by other instances .
that , How can a client access any instance , You can get all the hash slot information ?
Redis Instance will send its own hash slot information to other instances connected to it , To complete the hash slot allocation information diffusion . When instances are interconnected , Each instance has the mapping relationship of all hash slots .
After the client receives the hash slot information , The hash slot information Cache locally . When a client requests a key value pair , We will first calculate the corresponding Hashi groove of the bond , Then you can send the request to the corresponding instance .
When a client requests a key value pair from a node , The node receiving the command calculates which slot the database key to process belongs to , And check that the slot is assigned to yourself :
- If the slot where the key is located is just assigned to the current node , Then the node will directly execute this command ;
- If it is not assigned to the current node , Then the node will return one to the client
MOVEDerror , And then redirect (redirect) To the right node , And send the command to be executed before again .
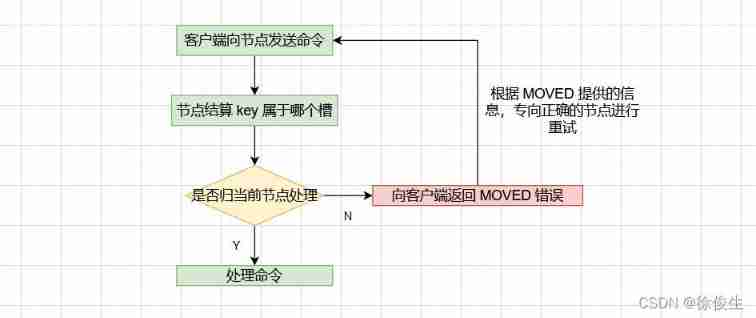
Calculate which slot the key belongs to
Nodes are defined by the following algorithm key Which slot does it belong to :
crc16(key,keylen) & 0x3FFF;
- crc16: Used to calculate key Of CRC-16 The checksum
- 0x3FFF: The conversion 10 Into the system is 16383
- & 0x3FFF: Used to calculate a value between 0~16383 An integer between as key Slot number of .
adopt
CLUSTER KEYSLOT <KEY>Commands can be viewed key Which slot does it belong to .
Determine whether the slot is handled by the current node
When the node calculates key Of Slot i after , The node will judge Slot i Have you been assigned yourself . So how to judge ?
Each node will maintain one 「slots Array 」, The node passed the check slots[i] , Judge Slot i Whether you are responsible for :
- if
slots[i]If the corresponding node is the current node , It means thatSlot iThe current node is responsible for , The node can execute commands sent by the client ; - if
slots[i]The corresponding node is not the current node , Nodes will be based onslots[i]The node pointed to returns to the clientMOVEDerror , Guide the client to the correct node .
MOVED error
Format :
MOVED <slot> <ip>:<port>
- slot: The slot where the key is located
- ip: Responsible for processing the tank slot Node ip
- port: Responsible for processing the tank slot Node port
such as :MOVED 10086 127.0.0.1:7002, Express , The hash slot where the key value pair requested by the client is located 10086, It's actually in 127.0.0.1:7002 In this case .
By returning MOVED command , It is equivalent to telling the client the information of the new instance where the Hashi slot is located .
thus , The client can communicate directly with 7002 Connect , And send the operation request .
meanwhile , The client also updates the local cache , Connect the slot with Redis The instance correspondence is updated correctly .
cluster-mode
redis-cliThe client is receivingMOVEDWhen it's wrong , It doesn't print outMOVEDerror , But according toMOVEDError automatically redirects the node , And print out the steering information , So we can't see the return of the nodeMOVEDFALSE . While using stand-alone moderedis-cliThe client can printMOVEDerror .
Actually ,Redis Tell the client to redirect access to the new instance in two ways :MOVED and ASK . Let's analyze ASK How to use the redirect command .
The shard
In the cluster , The corresponding relationship between examples and Hashi trough is not invariable , There are two of the most common changes :
- In the cluster , Instances are added or deleted ,Redis Need to reallocate the Hashi trough ;
- For load balancing ,Redis The hash slot needs to be redistributed across all instances .
Re sectioning can be done online , in other words , In the process of repartition , Clusters do not need to be offline .
for instance , above-mentioned , We formed 7001、7002、7003 Three node cluster , We can add a new node to this cluster 127.0.0.1:7004.
$ redis-cli -c -p 7001
127.0.0.1:7001> CLUSTER MEET 127.0.0.1 7004
OK
Then by re slicing , Assign the original to the node 7003 The groove of 15001 ~ Slot 16383 Instead assign to 7004.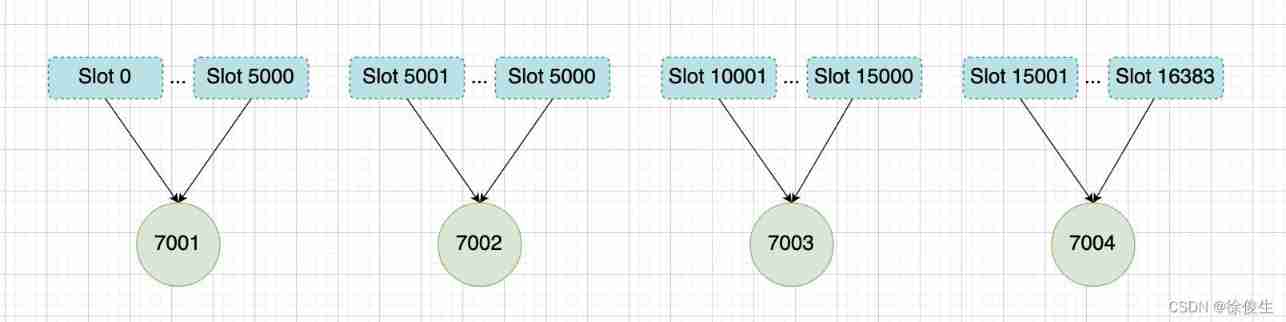
During the re segmentation , In the process of migrating slots from the source node to the target node , There may be such a situation : If there is more data in a slot , Partial migration to new instance , There's still a part that hasn't been relocated ?
In the case of partial completion of this migration , The client will receive a ASK Error message .
ASK error
If the client sends a command related to the database key to the target node , And the key to be processed by this command just belongs to the migrated slot :
- The source node will first find the specified key in its own database , If you find it , Direct command execution ;
- contrary , If the source node is not found , Then this key may have been migrated to the target node , The source node will send a
ASKerror , Direct the client to the target node , And send the command to be executed before again .
It seems a little complicated , Let's take an example to explain .
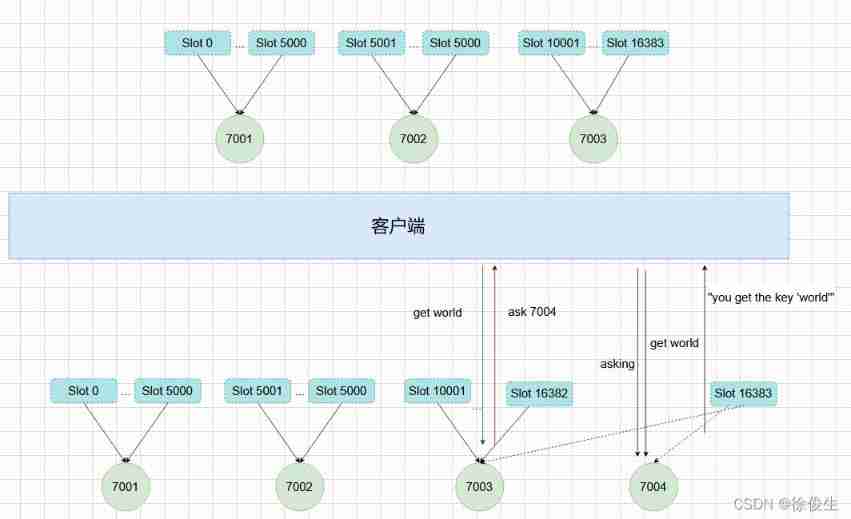
As shown in the figure above , node 7003 I'm going to 7004 transfer Slot 16383, This slot contains hello and world, Middle key hello Stay at the node 7003, and world Has moved to 7004.
We go to the node 7003 Send about hello The order of This command will be executed directly :
127.0.0.1:7003> GET "hello"
"you get the key 'hello'"
If we go to the node 7003 send out world Then the client will be redirected to 7004:
127.0.0.1:7003> GET "world"
-> (error) ASK 16383 127.0.0.1:7004
The client is receiving ASK After the mistake , Send one first ASKING command , And then send GET "world" command .
ASKINGThe command is used to open theASKINGidentification , After opening, you can execute the command .
ASK and MOVED The difference between
ASK Mistakes and MOVED Errors will cause client redirection , The difference is :
- MOVED The error indicates that the responsibility of the slot has been transferred from one node to another : Receive information about
Slot iOfMOVEDAfter the mistake , Every time the client encounters aboutSlot iCommand when requested , You can send command requests directly toMOVEDWrong node , Because this node is currently in chargeSlot iThe node of . - and ASK It's just one of the processes of two nodes migrating slots Temporary measures : Receive information about
Slot iOfASKAfter the mistake , The client will only ask about... In the next command requestSlot iThe command request is sent toASKWrong node , however , If the client requests againSlot iData in , It will still Be responsible for the originalSlot iThe node of sends a request .
That means ,ASK The purpose of the command is to enable the client to send a request to the new instance , And the hash slot allocation information cached by the client will not be updated . Not like MOVED Order that , Changes the local cache , Let all subsequent commands be sent to the new instance .
We now know Redis Implementation principle of cluster . Now let's analyze ,Redis How can a cluster achieve high availability ?
Replication and failover
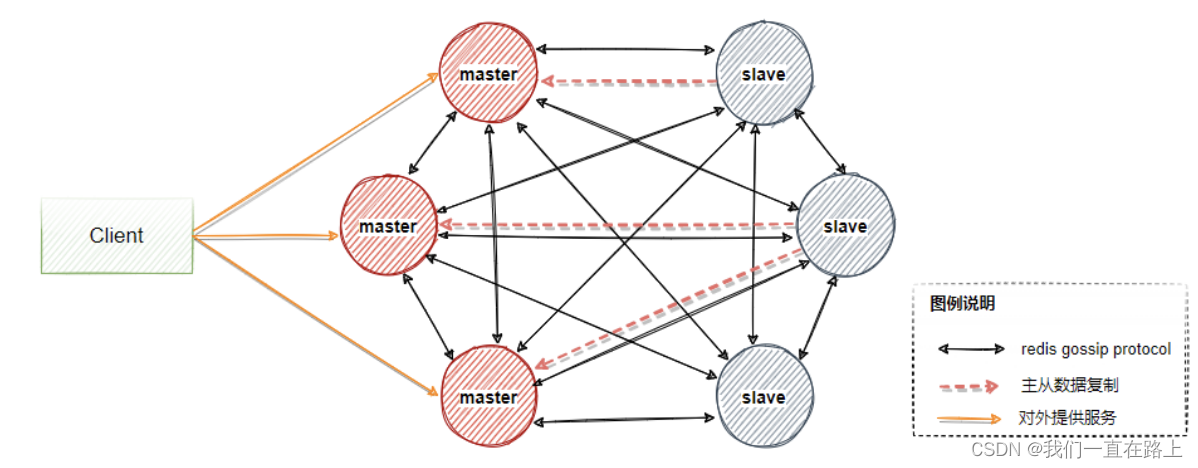
Redis The nodes in the cluster are also divided into master nodes and slave nodes .
- The master node is used for the processing slot
- The slave node is used to replicate the master node , If the copied master node goes offline , It can continue to provide services instead of the master node .
for instance , To contain 7001 ~ 7004 A cluster of four master nodes , You can add two nodes :7005、7006. And set these two nodes to 7001 The slave node .
Set the slave node command :
CLUSTER REPLICATE <node_id>
Pictured :
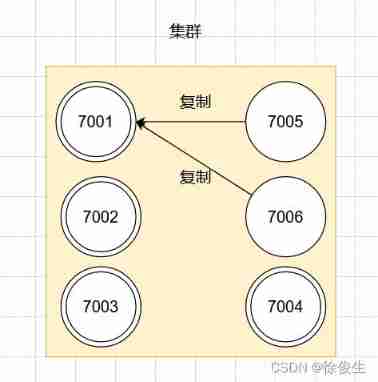
If at this time , Master node 7001 Offline , Then the remaining main nodes that work normally in the cluster will be 7001 Select one of the two slave nodes as the new master node .
for example , node 7005 To be selected , So the node 7001 The slot responsible for processing will be handed over to the node 7005 Handle . And node 7006 The new master node will be copied instead 7005. If the follow-up 7001 Back online , Then it will become 7005 The slave node . As shown in the figure below :
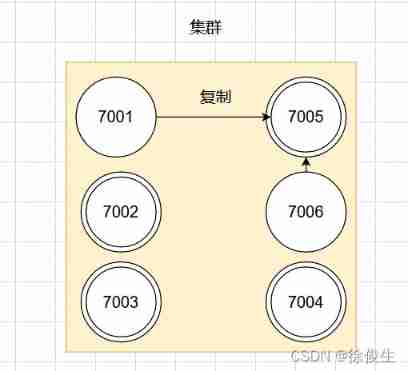
Fault detection
Each node in the cluster will send messages to other nodes regularly PING news , To check whether the other party is online . If the party receiving the message does not return within the specified time PONG news , that The party receiving the message will be marked as 「 Suspected offline 」.
Each node in the cluster will exchange the status information of each node by sending messages to each other .
Three states of nodes :
- Online status
- Suspected offline status PFAIL
- Offline status FAIL
If a node thinks that a node has lost its connection, it does not mean that all nodes think it has lost its connection . In a cluster , More than half of the master nodes responsible for processing slots have confirmed that a master node is offline , The cluster thinks that the node needs to switch between master and slave .
Redis The cluster node adopts Gossip Protocol to broadcast their own state and their own cognitive changes of the whole cluster . For example, a node finds that a node is disconnected (PFail), It will broadcast this message to the entire cluster , Other nodes can also receive this information .
We all know , Sentinel mechanism can be monitored 、 Switch the main library automatically 、 Inform the client to realize automatic fail over . that Redis Cluster How to realize automatic failover ?
Fail over
When a slave node finds that it is replicating, the master node enters 「 Offline 」 In the state of , The slave node will start to fail over the offline master node .
Execution steps of failover :
- In all slave nodes of the replication offline master node , Select a slave node
- The selected slave node performs
SLAVEOF no onecommand , Become the master node - The new master node will cancel all slot assignments to the offline master node , Assign all these slots to yourself
- The new master node broadcasts a message to the cluster
PONGnews , Let other nodes in the cluster know , This node has changed from a slave node to a master node , And has taken over the slot that the original master node is responsible for - The new master node starts to receive commands and requests related to processing slots , Failover complete .
Elector
This method of choosing the master is very similar to that of the sentry , Both are based on Raft Algorithm The leading algorithm of . The process is as follows :
- The era of cluster configuration is an auto increment counter , The initial value is 0;
- When a node in the cluster starts a failover operation , Cluster configuration era plus 1;
- For each configuration era , Every primary node in the cluster responsible for processing slots has a chance to vote , The first slave node that requests a vote from the master node will get the vote of the master node ;
- When the slave node finds its replicated master node, it enters 「 Offline 」 In the state of , Will broadcast a message to the cluster , Request to receive this message , And the master node with voting rights votes for itself ;
- If a primary node has voting rights , And have not voted for other slave nodes , Then the master node will return a message to the slave node that requires voting , Indicates that the slave node is supported to become a new master node ;
- Each slave node participating in the election will calculate how much support it has received from the master node ;
- If there is N Primary nodes with voting rights , When a support ticket is received from a node
Greater than or equal to N/2 + 1when , The slave node will be selected as the new master node ; - If not enough votes are collected from the node in a configuration era , Then the cluster will enter a new era of configuration , And choose the master again .
news
The nodes in the cluster communicate by sending and receiving messages , We call the node that sends the message the sender , The person who receives the message is called the receiver .
There are five kinds of messages sent by nodes :
- MEET news
- PING news
- PONG news
- FAIL news
- PUBLISH news
Each node in the cluster passes through Gossip The protocol exchanges state information of different nodes , Gossip By MEET、PING、PONG Three kinds of messages .
Every time the sender sends MEET、PING、PONG When the news , Will randomly select two nodes from their known node list ( It can be a master node or a slave node ) Send it to the receiver .
Received by recipient MEET、PING、PONG When the news , Different processing is carried out according to whether they know these two nodes :
- If the selected node does not exist, it receives a list of known nodes , Description is the first contact , The receiver will select the node according to ip Communicate with the port number ;
- If it already exists , Explain that the communication has been completed before , Then the information of the original selected node will be updated .
Okay , About Redis That's all for cluster related . See you next time .
边栏推荐
- Want to ask, how to choose a securities firm? Is it safe to open an account online?
- 1 plug-in to handle advertisements in web pages
- Matlab imoverlay function (burn binary mask into two-dimensional image)
- Linux Installation and deployment lamp (apache+mysql+php)
- Codeworks 5 questions per day (1700 average) - day 5
- Video networkstate property
- 想问问,如何选择券商?在线开户是很安全么?
- POJ-2499 Binary Tree
- ABAP table lookup program
- 什么是数字化存在?数字化转型要先从数字化存在开始
猜你喜欢
Linux Installation and deployment lamp (apache+mysql+php)

Matlab superpixels function (2D super pixel over segmentation of image)
Learn memory management of JVM 01 - first memory
Reinforcement learning - learning notes 3 | strategic learning
Principle of redis cluster mode

Matlab label2idx function (convert the label matrix into a cell array with linear index)
The survey shows that traditional data security tools cannot resist blackmail software attacks in 60% of cases
Pytorch MLP

什么是数字化存在?数字化转型要先从数字化存在开始
Redis master-slave mode

随机推荐
Matlab label2idx function (convert the label matrix into a cell array with linear index)
Matlab boundarymask function (find the boundary of the divided area)
Basic operations of MySQL data table, addition, deletion and modification & DML
Multi table operation - Auto Association query
MySQL transaction
Thoughts and suggestions on the construction of intelligent management and control system platform for safe production in petrochemical enterprises
MySQL storage engine
Instance + source code = see through 128 traps
Two minutes will take you to quickly master the project structure, resources, dependencies and localization of flutter
Linux Installation and deployment lamp (apache+mysql+php)
byte2String、string2Byte
想问问,如何选择券商?在线开户是很安全么?
The survey shows that traditional data security tools cannot resist blackmail software attacks in 60% of cases
Learn memory management of JVM 01 - first memory
Learn JVM garbage collection 02 - a brief introduction to the reference and recycling method area
Learn the garbage collector of JVM -- a brief introduction to Shenandoah collector
【ijkplayer】when i compile file “compile-ffmpeg.sh“ ,it show error “No such file or directory“.
[cloud native | kubernetes] actual battle of ingress case (13)
Learning JVM garbage collection 06 - memory set and card table (hotspot)
MySQL view