当前位置:网站首页>Principle of redis cluster mode
Principle of redis cluster mode
2022-07-05 11:44:00 【We've been on the road】
One 、Redis Distributed extension Redis Cluster programme
Data will be lost during master-slave switching , Because there's only one master, You can only do single points , There is no solution to the problem of horizontal expansion . And each node holds all the data , One is that the memory occupation rate is high , In addition, if data recovery , Very slow . And the amount of data is too large IO The performance of the operation will also have an impact . So we are also right Redis The need for data fragmentation , The so-called fragmentation is to split a piece of big data into multiple pieces of small data , stay 3.0 Before , We can only build multiple redis Master slave node cluster , Split different business data into different clusters , This method requires a lot of code in the business layer to complete data fragmentation 、 Routing and so on , Resulting in high maintenance costs 、 increase 、 Removing nodes is cumbersome .Redis3.0 And then introduced Redis Cluster Cluster solution , It is used to solve the needs of distributed expansion , At the same time, it also realizes the high availability mechanism .
1.Redis Cluster framework
One Redis Cluster By multiple Redis Node structure , There is no intersection of data served by different node groups , That is, each node group corresponds to data sharding A slice of . Some nodes in the node group are primary and standby nodes , Corresponding master and slave node . The two data are consistent in quasi real time , The asynchronous active / standby replication mechanism ensures that . A node group has and has only one master node , At the same time, there can be 0 To more than one slave node , In this node group, there are only master Nodes provide some services to users , The reading service can be provided by master perhaps slave Provide .
As shown in figure, , Contains three master Nodes and three master Corresponding slave node , Generally, a group of clusters should at least 6 Only nodes can ensure complete high availability . Three of them master Will assign different slot( Represents the data partition interval ), When master Failure time ,slave Will automatically elect to become master Continue to provide services instead of the primary node .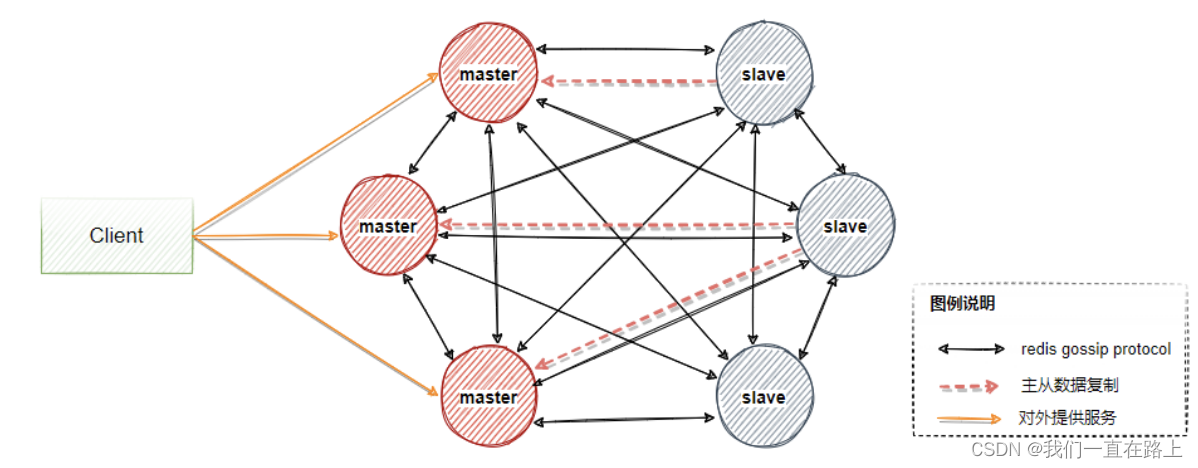
2. About gossip agreement
Throughout redis cluster Architecture , If
- New join node
- slot transfer
- The node is down
- slave The election became master
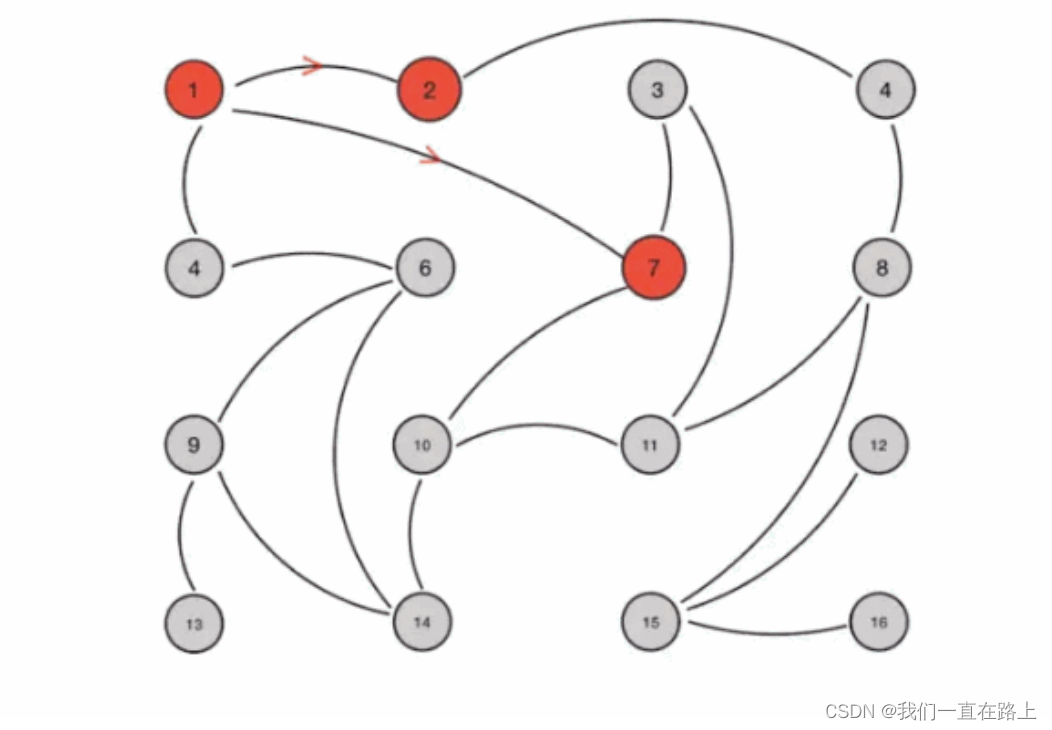
We hope that these changes will enable each node in the whole cluster to discover as soon as possible , Propagate to the whole cluster and all nodes in the cluster agree , Then each node needs to be connected with each other and carry relevant state data for propagation , The normal logic is to send messages to all nodes in the cluster by broadcasting , The point is that the data synchronization in the cluster is faster , But every message needs to be sent to all nodes , Yes CPU And bandwidth consumption is too high , So it's used here gossip agreement .Gossip protocol Also called Epidemic Protocol ( Epidemic protocol ), There are many aliases, such as :“ Rumor algorithm ”、“ Epidemic spread algorithm ” etc. . It is characterized by , In a network with a limited number of nodes , Every node will “ Random ”( Not really random , Instead, the communication node is selected according to the rules ) Communicate with some nodes , After a messy correspondence , The state of each node will be agreed within a certain period of time , As shown in the figure .
Suppose we set the following rules in advance :
- Gossip It's a periodic spread of messages , Limit the period to 1 second
- Random selection of infected nodes k Adjacency nodes (fan-out) Disseminate messages , Here is the fan-out Set to 3, At most every time 3 Node spread .
- Each time the message is spread, the node that has not been sent is selected for spreading
- The node receiving the message no longer spreads to the sending node , such as A -> B, that B When it's on the air , No longer issued A. There's a total of 16 Nodes , node 1 Is the initial infected node , adopt Gossip The process , Eventually, all nodes are infected :
3.gossip Agreement message
gossip Protocol contains multiple messages , Include ping,pong,meet,fail wait .
ping: Each node will send to other nodes frequently ping, It contains its own state and cluster metadata maintained by itself , Through each other ping Exchange metadata ;
pong: return ping and meet, Include your own status and other information , It can also be used for information broadcast and update ;
fail: One node judges another fail after , Is sent fail To other nodes , Notify other nodes , The specified node is down .
meet: Sent by a node meet To add new nodes , Add new nodes to the cluster , Then the new node will start to communicate with other nodes , You don't need to send all that's needed to form a network CLUSTER MEET command . send out CLUSTER MEET Message so that each node can reach each other, just through a known node chain . Because it's swapped in heartbeat packets gossip Information , Missing links between nodes will be built .
4.gossip Advantages and disadvantages
advantage : gossip The advantage of the protocol is that the update of metadata is scattered , Not in one place , Renewal requests will continue , There is a certain delay in updating all nodes , It reduces the pressure ; De centralization 、 Scalable 、 Fault tolerance 、 Uniform convergence 、 Simple . Because there is no guarantee that all nodes will receive messages at a certain time , But in theory, eventually all nodes will receive messages , So it's a final agreement .
shortcoming : Metadata update may delay some operations of the cluster . Delay of message , Message redundancy .
5. The data distribution
Redis Cluster in ,Sharding use slot( Slot ) The concept of , In all 16384 Slot , It's kind of like pre sharding Ideas . For each entry Redis The key/value pair , according to key To hash , Assigned here 16384 individual slot One of them . The use of hash The algorithm is also relatively simple , Namely CRC16 after 16384 modulus [crc16(key)%16384].Redis Each of the clusters node( node ) Be responsible for sharing this 16384 individual slot Part of , in other words , Every slot They all correspond to one node Responsible for handling .
Pictured 5 Shown , Suppose we are now three master nodes, which are :A, B, C Three nodes , They can be three ports on a machine , It can also be three different servers . that , Using the Hashimoto trough (hash slot) How to allocate 16384 individual slot Words , The three nodes are responsible for slot The interval is 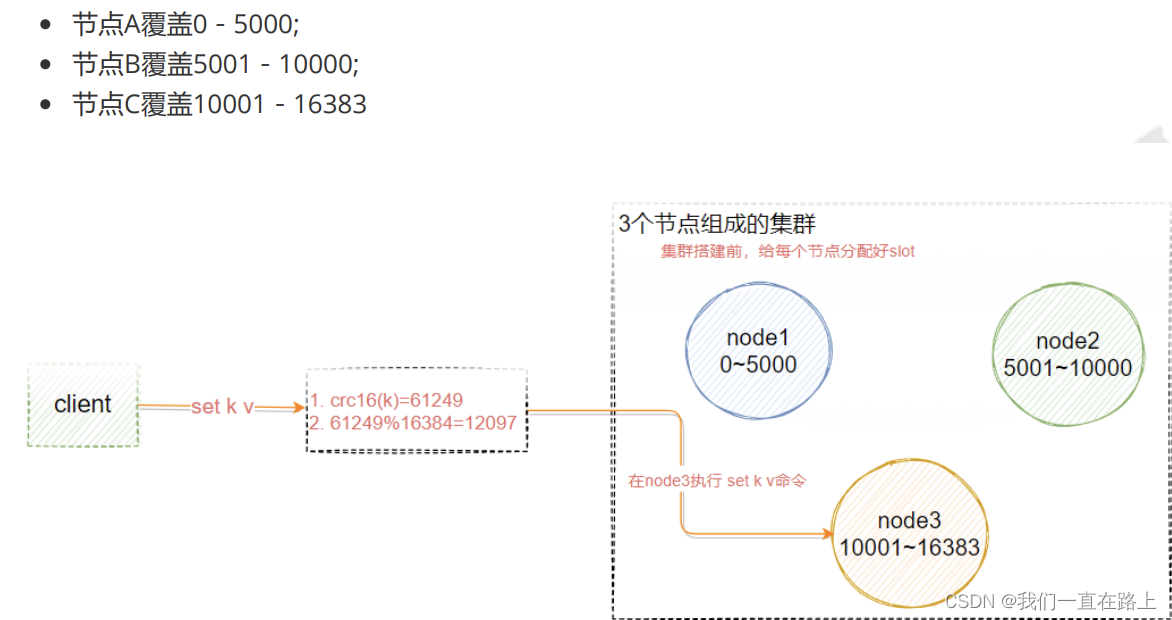
6. Client redirection
Pictured 5-6 Shown , hypothesis k This key It should be stored in node3 On , At this time, the user is node1 perhaps node2 On the call set k v Instructions , This is the time redis cluster How to deal with it ?
127.0.0.1:7291> set qs 1
(error) MOVED 13724 127.0.0.1:7293
Server return MOVED, That is to say, according to key Calculated slot Not managed by the current node , Server return MOVED Tell the client to go 7293 Port operation .
Change the port at this time , use redis-cli –p 7293 operation , Will return OK. Or use ./redis-cli -c -p port The order of . But the problem is , The client needs to connect twice to complete the operation . So most of the redis The client will maintain a copy locally slot and node Correspondence of , The current is calculated before the instruction is executed key The target node that should be stored , Then connect to the target node for data operation . stay redis The following commands are provided in the cluster to calculate the current key Which should it belong to slot
redis> cluster keyslot key1
6. High availability master-slave switching principle
If the master node does not have a slave node , So when it breaks down , The cluster will be unavailable .
Once a master The node enters FAIL state , Then the whole cluster will become FAIL state , Trigger at the same time failover Mechanism ,failover The aim is to start with slave Select a new master node from the node , So that the cluster can return to normal , This process is implemented as follows :
When slave self-discovering master Turn into FAIL In the state of , Then try to do Failover, With a view to becoming a new master. Because of the hang up 、master There may be more than one slave, So there are many slave Competition becomes master Node process , The process is as follows :
- slave self-discovering master Turn into FAIL
- Record your own clusters currentEpoch Add 1, And broadcast FAILOVER_AUTH_REQUEST Information
- Other nodes receive this message , Only master Respond to , Judge the legitimacy of the requester , And send the FAILOVER_AUTH_ACK, For each epoch Send only once ack
- Try failover Of slave collect master Back to FAILOVER_AUTH_ACK
- slave More than half received master Of ack Become new after Master ( This explains why clusters need at least three primary nodes , If there are only two , When one of them hangs up , Only one primary node can't be elected successfully )
- radio broadcast Pong Message notification to other cluster nodes .
The slave node is not in the primary node FAIL We'll try to start an election right away , It's a delay , A certain delay ensures that we wait FAIL The state propagates in the cluster ,slave If you try to vote now , Other masters Maybe not FAIL state , May refuse to vote .
Delay calculation formula : DELAY = 500ms + random(0 ~ 500ms) + SLAVE_RANK * 1000ms
SLAVE_RANK It means this slave Has gone from master The total amount of replicated data is rank.Rank The smaller the data, the newer the copied data . In this way , With the latest data slave There will be elections first
7. When is the cluster unavailable
- No master-slave backup , A node goes down
- The master and slave of a node are all down
- More than half of the primary nodes are down
Two 、codis The architecture of
Pictured 5-7 Shown , Express Codis The overall architecture diagram .
Codis Proxy: Client connected Redis Agency service , Realized Redis agreement . Except that some commands are not supported ( Unsupported command list ), Expressive and original Redis There is no difference between ( It's like Twemproxy).
For the same business cluster , You can deploy multiple codis-proxy example ; Different codis-proxy Between by codis-dashboard Ensure that the status is the same as
codis-redisgroup: Representing one redis Service cluster nodes , One RedisGroup There's one in it Master, And multiple Slave
Zookeeper:Codis rely on ZooKeeper To store data routing tables and codis-proxy Meta information of node , codis-config All orders issued will pass ZooKeeper Synced to each living codis-proxy.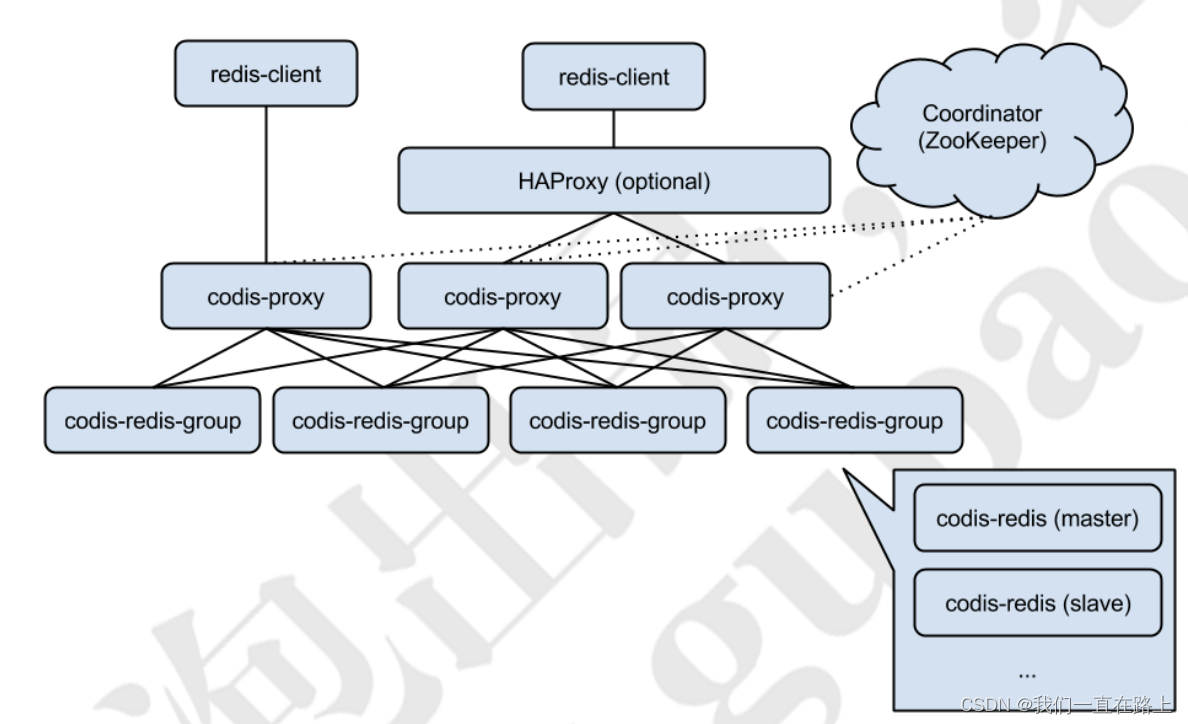
边栏推荐
- 高校毕业求职难?“百日千万”网络招聘活动解决你的难题
- MySQL 巨坑:update 更新慎用影响行数做判断!!!
- 11. (map data section) how to download and use OSM data
- 13.(地图数据篇)百度坐标(BD09)、国测局坐标(火星坐标,GCJ02)、和WGS84坐标系之间的转换
- 7 themes and 9 technology masters! Dragon Dragon lecture hall hard core live broadcast preview in July, see you tomorrow
- Sklearn model sorting
- ACID事务理论
- Dynamic SQL of ibatis
- The most comprehensive new database in the whole network, multidimensional table platform inventory note, flowus, airtable, seatable, Vig table Vika, flying Book Multidimensional table, heipayun, Zhix
- How to understand super browser? What scenarios can it be used in? What brands are there?
猜你喜欢
7.2 daily study 4
![[yolov3 loss function]](/img/79/87bcc408758403cf3993acc015381a.png)
[yolov3 loss function]
【无标题】

The most comprehensive new database in the whole network, multidimensional table platform inventory note, flowus, airtable, seatable, Vig table Vika, flying Book Multidimensional table, heipayun, Zhix

How to protect user privacy without password authentication?
![[crawler] Charles unknown error](/img/82/c36b225d0502f67cd04225f39de145.png)
[crawler] Charles unknown error
多表操作-子查询
yolov5目標檢測神經網絡——損失函數計算原理
全网最全的新型数据库、多维表格平台盘点 Notion、FlowUs、Airtable、SeaTable、维格表 Vika、飞书多维表格、黑帕云、织信 Informat、语雀
《增长黑客》阅读笔记
随机推荐
liunx禁ping 详解traceroute的不同用法
[leetcode] wild card matching
【Win11 多用户同时登录远程桌面配置方法】
MySQL statistical skills: on duplicate key update usage
redis 集群模式原理
Technology sharing | common interface protocol analysis
Sklearn model sorting
Solve the grpc connection problem. Dial succeeds with transientfailure
高校毕业求职难?“百日千万”网络招聘活动解决你的难题
Web API配置自定义路由
I used Kaitian platform to build an urban epidemic prevention policy inquiry system [Kaitian apaas battle]
Halcon 模板匹配实战代码(一)
ibatis的动态sql
Pytorch training process was interrupted
[LeetCode] Wildcard Matching 外卡匹配
Harbor image warehouse construction
Network five whip
871. Minimum Number of Refueling Stops
程序员内卷和保持行业竞争力
2048 game logic