当前位置:网站首页>[figure neural network] GNN from entry to mastery
[figure neural network] GNN from entry to mastery
2022-07-05 12:26:00 【Nat_ Jst】
List of articles
1.Graph Basic introduction
1.1 The representation of the figure
What is a graph? ?
Graph is a data structure composed of nodes and edges .
The representation of the figure ?
Undirected graph ( The edge between two nodes has no direction )
Directed graph ( The edge between two nodes has direction )
How to represent a picture ?
Use adjacency matrix : If two nodes in a matrix have edges, it is 1, Boundless is 0

The nature of graphs : degree (degree)
The degree of an undirected graph : Number of node edges
The degree of a digraph : Divided into degrees ( The number of edges that this node points to other nodes )、 The degree of ( The number of edges of other nodes pointing to this node )
1.2 Characteristics of Graphs
• Subgraphs Subgraph
Part of the larger picture , All nodes and edges in the subgraph and the relationship between nodes and edges are part of the larger graph .
• Connection diagram Connected Graph
For an undirected graph , If any node i Can reach the node through some edges j , It is called a connected graph
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-4GPxxkQx-1643032621958)(C:\Users\hp\AppData\Roaming\Typora\typora-user-images\1643009357413.png)]](/img/86/190a24acf802b08afd3840850307f0.jpg)
Directed graph The connectivity of :
Strongly connected graph : Given a digraph G=(VE), And give the graph G Any two nodes in u and v, If the node u And nodes v Reach each other , That is, there is at least one path that can be determined by nodes u Start , To the node v End , At the same time, there is at least one path that can be determined by nodes v Start , To the node u End , Then it is called the digraph G It's a strongly connected graph .
If a connected graph : If at least one pair of nodes is not unidirectionally connected , But after removing the direction of edges, it is a connected graph from the perspective of undirected graph , be D It is called weakly connected graph .
• Connected component Connected Component
Connected component : Undirected graph G One of the most important sub maps of Dalian is called G A connected component of ( Or connected branches ).
A connected graph has only one connected component , It is itself .
A disconnected graph has many connected components .
• Shortest path Shortest Path
The shortest path connecting two nodes in the graph .
• Figure diameter Diameter
The maximum value of the shortest path between two nodes in the graph .
1.3 Centrality graph . Centrality
• Centrality Degree Centrality
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-wlNTQ5ib-1643032621960)(C:\Users\hp\AppData\Roaming\Typora\typora-user-images\1643025129366.png)]](/img/71/86d5084aa87c34d36621cb31269b63.jpg)
N d e g r e e N_{degree} Ndegree : node N Degree , n n n : Total number of nodes
• Centrality of eigenvectors Eigenvector Centrality
Find the eigenvalue and eigenvector of the adjacency matrix of the graph , The eigenvector corresponding to the largest eigenvalue is the centrality of the eigenvector of this node .
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-acdYoqpD-1643032621961)(C:\Users\hp\AppData\Roaming\Typora\typora-user-images\1643026659366.png)]](/img/a1/6fee1cfdfe38eb1f3a7a4daaa9235f.jpg)
among A A A Is the adjacency matrix , There are five eigenvalues , among 2.4811943 Is the highest value , The corresponding eigenvector is the content of the small red box , multiply -1 Have no effect on the result , So the centrality of the eigenvector is the following value , among 1 Node and 5 The value of the node is the largest , Express 1 Node and 5 The degree of node is the largest . among 4 Node ratio 2、3 The reason why the centrality of node eigenvectors is large is 4 The degree of two nodes connected by nodes is large .
I don't know whether I consider the node degree of itself or the adjacent node degree . It shows the position of the node in the figure .
• Intermediary centrality Betweenness Centrality
If the other two nodes in the figure want to reach the shortest path, the number of times they pass through a node is intermediary centrality .
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-EcRiOhqM-1643032621962)(C:\Users\hp\AppData\Roaming\Typora\typora-user-images\1643027209731.png)]](/img/b4/c438828a5ce7c3f231c3a6456bb119.jpg)
When calculating the intermediary centrality of Cao Cao in the first formula , The content in the first bracket in the numerator indicates the number of shortest paths from Cai Wenji to other nodes ,0: The shortest path from caiwenji to Zhen Ji is 1, The number of passes through Cao Cao node is 0,1: The shortest path from caiwenji to Sima Yi and Xia Houdun is 3, The number of passes through Cao Cao node is 1,0.5: The shortest path from caiwenji to Dianwei is 2, There are two ways , So for 0.5.
• Connection centrality Closeness Centrality
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-k0UNpTji-1643032621989)(C:\Users\hp\AppData\Roaming\Typora\typora-user-images\1643029587438.png)]](/img/8f/894693c50837d1d55b003daa65fa26.jpg)
1.4 Page sorting algorithm
• PageRank
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-WNuHZzCv-1643032621996)(C:\Users\hp\AppData\Roaming\Typora\typora-user-images\1643032455298.png)]](/img/8e/62fc8b99c5df3020e779f2c4ffe60b.jpg)
PageRank Google's web page sorting algorithm .
The side PageRank The value is equal to the PageRank Value divided by the number of edges pointing to other nodes .
Node PageRank The value is equal to all points to the edge of the node PageRank Sum of values .
Damping coefficient : Last node PageRank What is the probability that the value will not be transmitted to the next node .
• HITS
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-kvX9DrBv-1643032622005)(C:\Users\hp\AppData\Roaming\Typora\typora-user-images\1643032505063.png)]](/img/eb/8ddd46b1cf69d4d4fa3107634e3e3b.jpg)
Node Hub The value is equal to that of the node pointed to by this node authority It's worth it and .( Out )
Node authority The value of is equal to the node pointing to this node Hub It's worth it and .( Enter into )

2.Graph Embedding

To represent each node in the diagram, you may use n Dimension length one-hot Coding vector ,n Is the number of nodes .
one-hot shortcoming :
1. If there are many nodes , The length of the vector is relatively large .
2. The information of the node in the graph is lost .
Network embedding The point in the network is represented by a low dimensional vector , And these vectors should reflect some characteristics of the original network , For example, if the structure of two points in the original network is similar , Then the vector represented by these two points should also be similar .
graph embedding(GE) = graph representation embedding(GRE) = network embedding(NE) = network presentation embedding(NPE)
Graph embedding The role of : The characteristic length of nodes is simplified , The information of nodes on the graph is preserved .
Graph embedding Algorithm :
2.1 DeepWalk
【 Paper notes 】DeepWalk
A method of network embedding is called DeepWalk, its Input It's a picture or a network , Output Is the vector representation of vertices in the network .DeepWalk By truncating random walks (truncated random walk) Learn a social expression of network (social representation), We can also get better results when there are few vertices in the network . And this method also has the advantage of scalability , Be able to adapt to the changes of the network .
Representation of network nodes (node representation) Is the use of word embedding ( The word vector ) My thoughts . The basic processing element of word embedding is word , The processing element corresponding to the representation of the network node is the network node ; Word embedding is the analysis of word sequences in a sentence , Then the sequence of nodes in the representation of network nodes is random walk .
The so-called random walk (random walk), It is to choose a random path repeatedly on the network , Finally, it forms a path through the network . Start at a specific endpoint , Each step of the walk randomly selects one of the edges connected to the current node , Move along the selected edge to the next vertex , Repeat the process over and over again . The green part shown in the figure below is a random walk .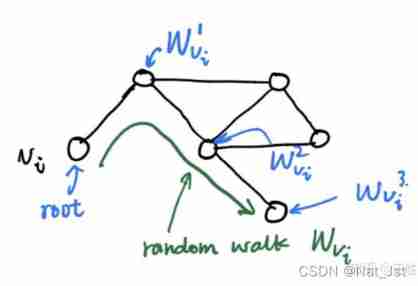
On the symbolic interpretation of random walk : With v i v_i vi A random walk path generated for the root node ( green ) by W v i W_{v_i} Wvi , Where the point on the path ( Blue ) They are marked as W v i 1 , W v i 2 , W v i 3 . . . W^1_{v_i},W^2_{v_i},W^3_{v_i}... Wvi1,Wvi2,Wvi3... …, Cut off random walk (truncated random walk) It's actually a random walk with a fixed length .
Using random walk has two benefits :
Parallelization , Random walk is local , For a large network , You can start a certain length of random walk at different vertices at the same time , Multiple random walks are performed simultaneously , It can reduce the sampling time .
adaptive , It can adapt to the local changes of the network . The evolution of networks is usually the change of local points and edges , Such changes will only affect some random walk paths , Therefore, in the process of network evolution, it is not necessary to recalculate the random walk of the whole network every time .
Algorithm
Whole DeepWalk The algorithm consists of two parts , One part is the generation of random walk , The other part is the update of parameters .
Among them the first 2 The next step is to build Hierarchical Softmax, The first 3 Step 1: do... For each node γ Random walk , The first 4 Step 1: disrupt the nodes in the network , The first 5 Step 1: take each node as the root node to generate a node with a length of t The random walk of , The first 7 Step based on the generated random walk using skip-gram The model uses gradient method to update the parameters .
The details of parameter update are as follows :
2.2 LINE
DeepWalk On an undirected graph ,LINE In a directed graph, you can use .
Title of thesis :LINE: Large-scale Information Network Embedding
This paper is also about network embedding , The main feature of the article is :
- Suitable for networks of any size , Whether directed graph, undirected graph or weighted graph .
- The objective function proposed in this paper (objective function) At the same time, the local and global characteristics of the network are considered .
- An edge sampling algorithm is proposed , It can be solved very well SGD The efficiency of .( I didn't understand this part , So I didn't write it out , Those who are interested can go to see the original )
- The network representation method proposed in this paper is very efficient , You can learn the representation of a million level vertex network on a single node within an hour .
The two vertices of the following two cases are reduced to similar vertices :
- If there is a strongly connected edge between two vertices ( Heavily weighted edges ), Then these two vertices are similar . The vertices in the graph 6 And 7 This is the similarity .
- If two vertices share many of the same neighbor vertices , Then these two vertices are similar . The vertices in the graph 5 and 6 Although not directly connected , But they are also connected to the vertex 1234, So the summit 5 and 6 It's similar .
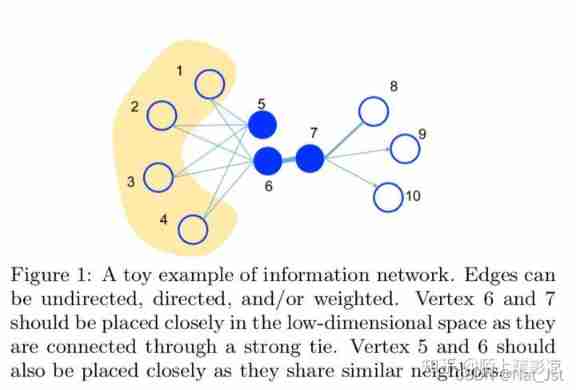
These two similarities are described as 1 Order similarity and 2 Order similarity .1 Order similarity holds that the greater the edge weight of two vertices , The more similar the two vertices are .2 Order similarity holds that two vertices have more common neighbors , The more similar the two vertices are .
In related work diss The effect of a wave of traditional methods , Some methods use the idea of matrix decomposition , The characteristic matrix of the graph ( Laplace matrix 、 Adjacency matrix ) Do feature decomposition , However, these methods require a lot of calculation , And the effect also has limitations . The last paper is also mentioned DeepWalk, Combine this article with Deepwalk Made a comparison .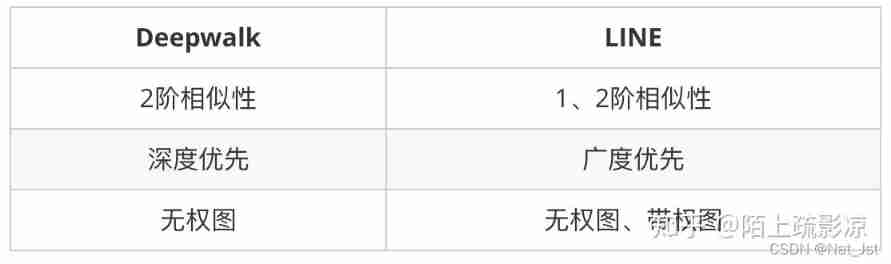



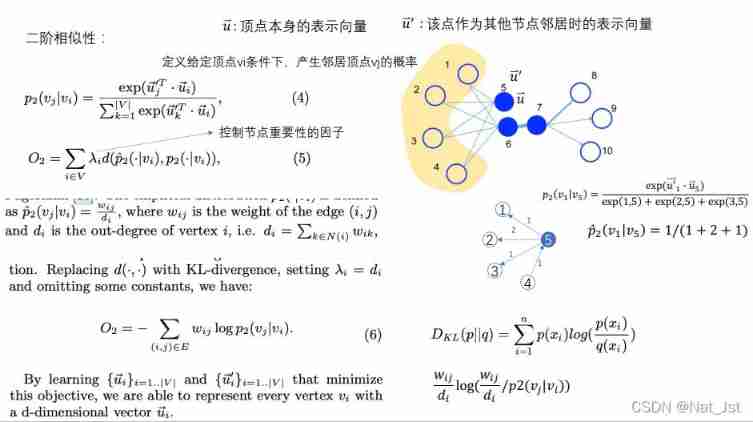


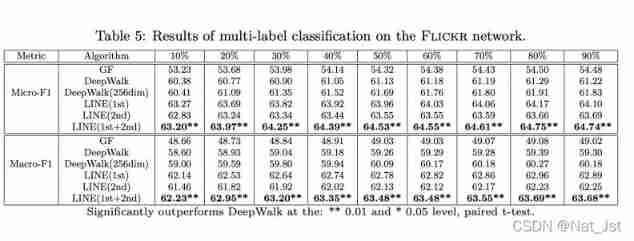
2.3 node2vec
Title of thesis :node2vec: Scalable Feature Learning for Networks
node2vec Our thoughts are the same as DeepWalk equally : Generate random walks , Random walk sampling results ( node , Context ) The combination of , Then we use the method of processing word vector to model such a combination, and get the representation of network nodes . However, some innovations have been made in the process of generating random walks .
First of all, it introduces several tasks of complex network , One is Classification of network nodes , Popular point is to cluster the nodes in the network , We are concerned about which nodes have similar properties , Just put them in the same category . The other is Link prediction , It's about predicting which vertices in the network are potentially related .
One structural feature is that many nodes gather together , There are more connections inside than outside , We call it community . Another feature of the network is that the two nodes are far away , There are similar features in the connection of edges . For example, below , u , s 1 , s 2 , s 3 . s 4 u,s_{1},s_2,s_3.s_4 u,s1,s2,s3.s4 It belongs to a community , and u , s 6 u,s_6 u,s6 They have similar characteristics in structure .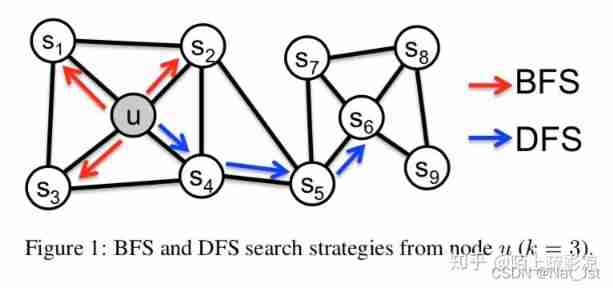
Then the goal of the network representation learning algorithm to be designed must meet these two points :
- Nodes in the same community represent similar .– Homogeneity homophily
- Nodes with similar structural characteristics represent similar .– Structural equivalence structural equivalence
Speaking of random walk sampling , In this paper, we analyze the walk patterns of two kinds of graphs , Depth first swim (Depth-first Sampling,DFS) And breadth first (Breadth-first Sampling,BFS), In the previous figure, two kinds of swimming paths are also drawn , Have studied graph theory or data structure, and have a good understanding . The walk path is the random walk obtained after sampling .
The task of complex network processing is actually inseparable from two characteristics , As mentioned before : One is homogeneity , It is the community mentioned before . One is structural similarity , It is worth noting that , Two points with similar structure may not be connected , It can be two nodes far apart .
BFS Tend to swim around the initial node , It can reflect the microscopic characteristics of a node's neighbors ; and DFS Generally, it will run farther and farther away from the initial node , It can reflect the macro characteristics of a node neighbor .
After so much preparation, it's finally time for the work of this article , Can we improve DeepWalk The way of random walk in , Make it comprehensive DFS and BFS The characteristics of ? Therefore, this paper introduces two parameters to control the way of random walk generation .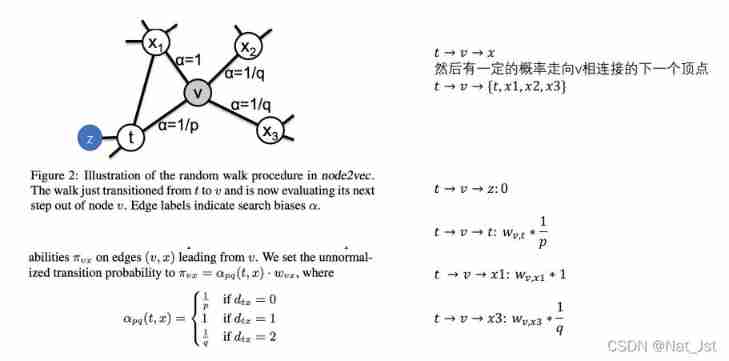
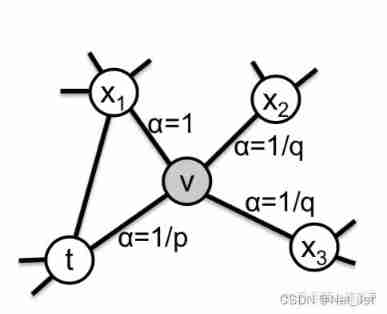
Above picture , For a random walk , If you have sampled ( t , v ) (t,v) (t,v), That is, now stay at the node v On , So the next node to sample x Which is ? The author defines a probability distribution , That is, the transition probability of a node to its different neighbors :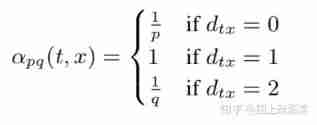
 
Let's take a look at the algorithm provided in the paper line by line :
First, let's look at the parameters of the algorithm , chart G、 Represents the vector dimension d、 Number of walks generated by each node r, Walk length l, The window length of the context k, And as mentioned before p、q Parameters .
according to p、q And the previous formula to calculate the transition probability from a node to its neighbors .
Add this transition probability to the graph G To form G’.
walks Used to store random walks , Initialize to null first .
Outer loop r Times indicates that each node is to be generated as the initial node r A random walk .
Then for each node in the graph .
Generate a random walk walk.
take walk Add to walks Kept in .
And then use SGD The method of walks Training .
The first 6 One step walk The generation method of is as follows :Set the initial node u Add in .
walk The length of is l, So recycle and add l-1 Nodes .
The current node is set to walk The last added node .
Find all neighbor nodes of the current node .
Select a neighbor according to the transition probability sampling s.
Add this neighbor to walk in .
Experiments
The following figure shows some experimental results and visualization effects :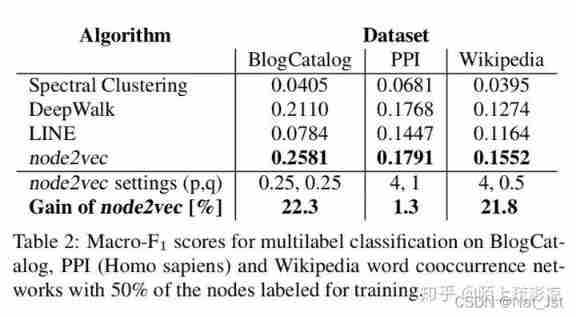

边栏推荐
- ABAP table lookup program
- 报错ModuleNotFoundError: No module named ‘cv2.aruco‘
- What is digital existence? Digital transformation starts with digital existence
- Implementing Yang Hui triangle with cyclic queue C language
- 信息服务器怎么恢复,服务器数据恢复怎么弄[通俗易懂]
- Multi table operation - Auto Association query
- [hdu 2096] Xiaoming a+b
- GPS data format conversion [easy to understand]
- Two minutes will take you to quickly master the project structure, resources, dependencies and localization of flutter
- What is the difference between canvas and SVG?
猜你喜欢

Matlab superpixels function (2D super pixel over segmentation of image)
The survey shows that traditional data security tools cannot resist blackmail software attacks in 60% of cases
Wireless WiFi learning 8-channel transmitting remote control module

7月华清学习-1

Implementing Yang Hui triangle with cyclic queue C language
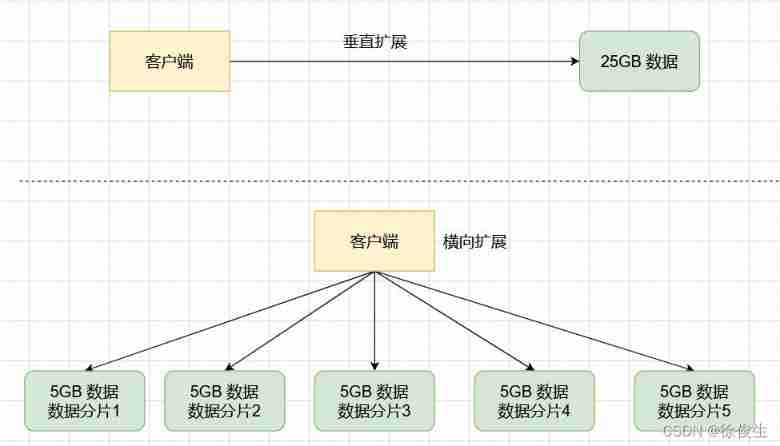
Redis highly available slice cluster
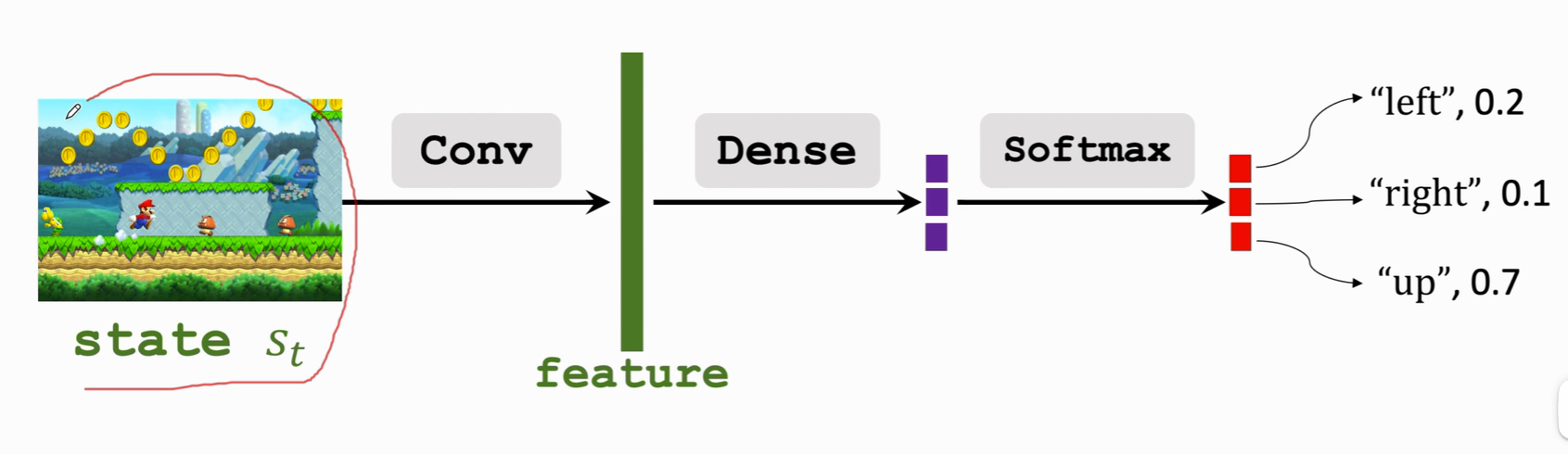
Reinforcement learning - learning notes 3 | strategic learning
调查显示传统数据安全工具在60%情况下无法抵御勒索软件攻击

互联网公司实习岗位选择与简易版职业发展规划
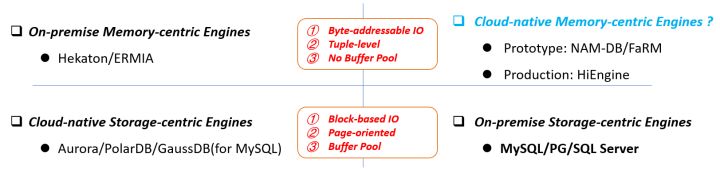
Hiengine: comparable to the local cloud native memory database engine

随机推荐
Swift - add navigation bar
Uniapp + unicloud + Unipay realize wechat applet payment function
mysql拆分字符串做条件查询
Array cyclic shift problem
How to recover the information server and how to recover the server data [easy to understand]
你做自动化测试为什么总是失败?
Matlab imoverlay function (burn binary mask into two-dimensional image)
Matlab boundarymask function (find the boundary of the divided area)
16 channel water lamp experiment based on Proteus (assembly language)
调查显示传统数据安全工具在60%情况下无法抵御勒索软件攻击
ZABBIX ODBC database monitoring
Design of music box based on assembly language
Get data from the database when using JMeter for database assertion
Ecplise development environment configuration and simple web project construction
MySQL function
一类恒等式的应用(范德蒙德卷积与超几何函数)
Application of a class of identities (vandermond convolution and hypergeometric functions)
ACID事务理论
Matlab superpixels function (2D super pixel over segmentation of image)
The evolution of mobile cross platform technology