当前位置:网站首页>Tâche 6: regroupement DBSCAN
Tâche 6: regroupement DBSCAN
2022-07-03 01:34:00 【Zstar - _】
Exigences
Réalisation de la programmationDBSCANRegroupement des données suivantes
Acquisition de données:https://download.csdn.net/download/qq1198768105/85865302
Bibliothèque de guides et paramètres globaux
from scipy.io import loadmat
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import DBSCAN
from sklearn import datasets
import pandas as pd
plt.rcParams['font.sans-serif'] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
DBSCAN Description des paramètres de regroupement
eps:ϵ-Seuil de distance pour le voisinage,Distance de l'échantillon supérieure àϵLe point d'échantillonnage n'est pasϵ-Dans le quartier,La valeur par défaut est0.5.
min_samples:Nombre minimum de points formant une zone de haute densité.Le quartier des mots en tant que point central(C'est - à - dire qu'il est centré,epsEst un cercle de rayon, Y compris les points sur le cercle ) Nombre minimal d'échantillons dans ( Y compris le point lui - même ).
Siy=-1, Est le point d'exception
Parce queDBSCAN Catégorie générée incertaine , Ainsi, une fonction est définie pour filtrer les paramètres les plus appropriés qui correspondent à la catégorie spécifiée .
Le critère approprié est le nombre minimum de points anormaux
def search_best_parameter(N_clusters, X):
min_outliners = 999
best_eps = 0
best_min_samples = 0
# Itérer différemmentepsValeur
for eps in np.arange(0.001, 1, 0.05):
# Itérer différemmentmin_samplesValeur
for min_samples in range(2, 10):
dbscan = DBSCAN(eps=eps, min_samples=min_samples)
# Ajustement du modèle
y = dbscan.fit_predict(X)
# Compter le nombre de grappes sous chaque combinaison de paramètres(-1Indique un point d'exception)
if len(np.argwhere(y == -1)) == 0:
n_clusters = len(np.unique(y))
else:
n_clusters = len(np.unique(y)) - 1
# Nombre de points d'exception
outliners = len([i for i in y if i == -1])
if outliners < min_outliners and n_clusters == N_clusters:
min_outliners = outliners
best_eps = eps
best_min_samples = min_samples
return best_eps, best_min_samples
# Importer des données
colors = ['green', 'red', 'blue']
smile = loadmat('data-Regroupement de la densité/smile.mat')
smileDonnées
X = smile['smile']
eps, min_samples = search_best_parameter(3, X)
dbscan = DBSCAN(eps=eps, min_samples=min_samples)
y = dbscan.fit_predict(X)
# Visualisation des résultats du regroupement
plt.figure(figsize=(20, 15))
plt.subplot(2, 2, 1)
for i in range(len(smile['smile'])):
plt.scatter(smile['smile'][i][0], smile['smile'][i][1],
color=colors[int(smile['smile'][i][2])])
plt.title("Données brutes")
plt.subplot(2, 2, 2)
for i in range(len(y)):
plt.scatter(smile['smile'][i][0], smile['smile'][i][1], color=colors[y[i]])
plt.title(" Données après regroupement ")
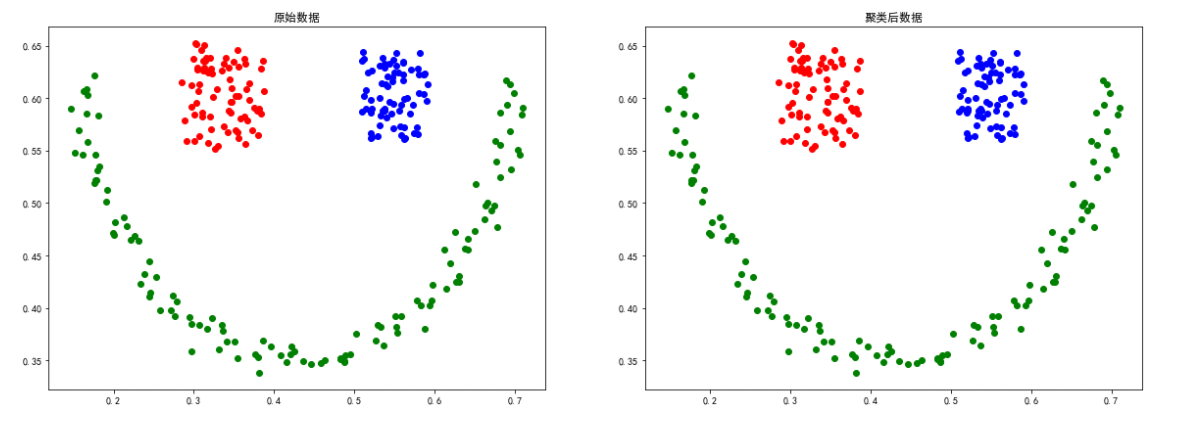
sizes5Données
# Importer des données
colors = ['blue', 'green', 'red', 'black', 'yellow']
sizes5 = loadmat('data-Regroupement de la densité/sizes5.mat')
X = sizes5['sizes5']
eps, min_samples = search_best_parameter(4, X)
dbscan = DBSCAN(eps=eps, min_samples=min_samples)
y = dbscan.fit_predict(X)
# Visualisation des résultats du regroupement
plt.figure(figsize=(20, 15))
plt.subplot(2, 2, 1)
for i in range(len(sizes5['sizes5'])):
plt.scatter(sizes5['sizes5'][i][0], sizes5['sizes5']
[i][1], color=colors[int(sizes5['sizes5'][i][2])])
plt.title("Données brutes")
plt.subplot(2, 2, 2)
for i in range(len(y)):
if y[i] != -1:
plt.scatter(sizes5['sizes5'][i][0], sizes5['sizes5']
[i][1], color=colors[y[i]])
plt.title(" Données après regroupement ")
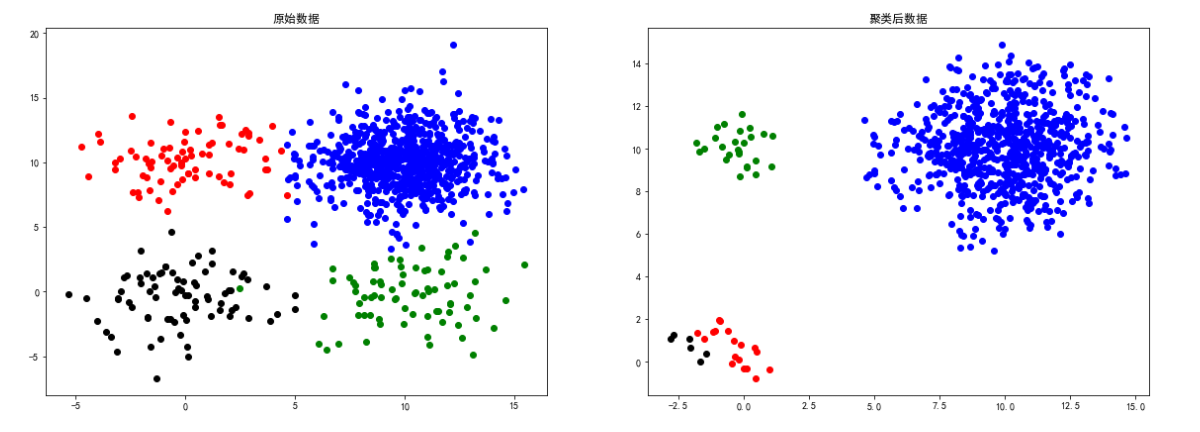
square1Données
# Importer des données
colors = ['green', 'red', 'blue', 'black']
square1 = loadmat('data-Regroupement de la densité/square1.mat')
X = square1['square1']
eps, min_samples = search_best_parameter(4, X)
dbscan = DBSCAN(eps=eps, min_samples=min_samples)
y = dbscan.fit_predict(X)
# Visualisation des résultats du regroupement
plt.figure(figsize=(20, 15))
plt.subplot(2, 2, 1)
for i in range(len(square1['square1'])):
plt.scatter(square1['square1'][i][0], square1['square1']
[i][1], color=colors[int(square1['square1'][i][2])])
plt.title("Données brutes")
plt.subplot(2, 2, 2)
for i in range(len(y)):
plt.scatter(square1['square1'][i][0], square1['square1']
[i][1], color=colors[y[i]])
plt.title(" Données après regroupement ")

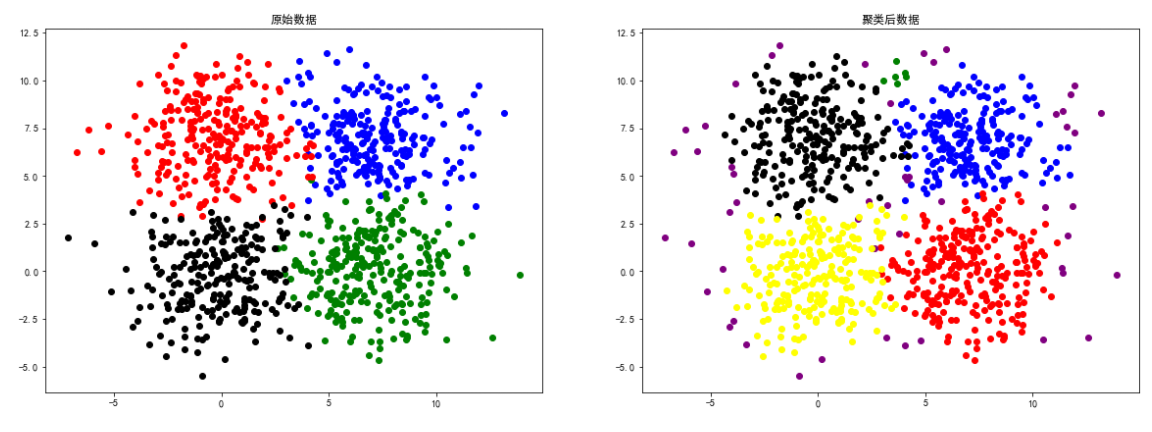
square4Données
# Importer des données
colors = ['blue', 'green', 'red', 'black',
'yellow', 'brown', 'orange', 'purple']
square4 = loadmat('data-Regroupement de la densité/square4.mat')
X = square4['b']
eps, min_samples = search_best_parameter(5, X)
dbscan = DBSCAN(eps=eps, min_samples=min_samples)
y = dbscan.fit_predict(X)
# Visualisation des résultats du regroupement
plt.figure(figsize=(20, 15))
plt.subplot(2, 2, 1)
for i in range(len(square4['b'])):
plt.scatter(square4['b'][i][0], square4['b']
[i][1], color=colors[int(square4['b'][i][2])])
plt.title("Données brutes")
plt.subplot(2, 2, 2)
for i in range(len(y)):
plt.scatter(square4['b'][i][0], square4['b']
[i][1], color=colors[y[i]])
plt.title(" Données après regroupement ")
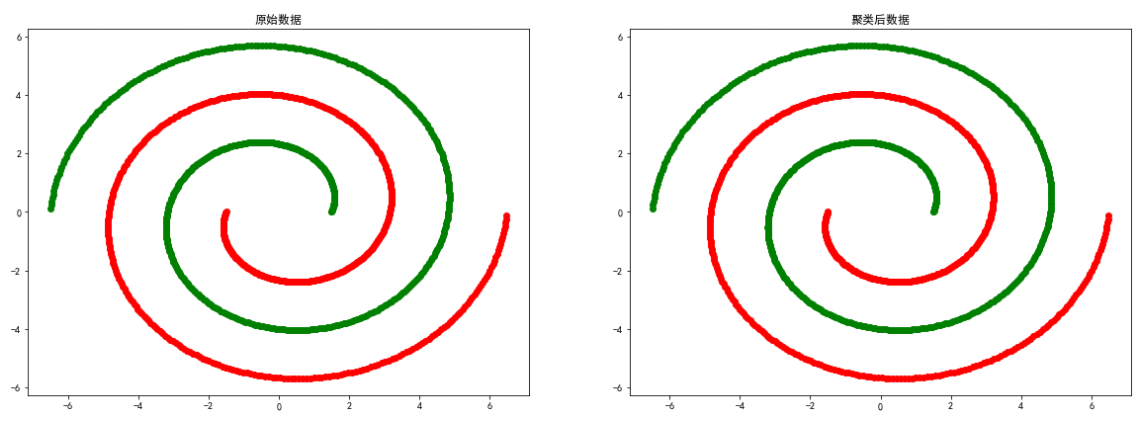
spiralDonnées
# Importer des données
colors = ['green', 'red']
spiral = loadmat('data-Regroupement de la densité/spiral.mat')
X = spiral['spiral']
eps, min_samples = search_best_parameter(2, X)
dbscan = DBSCAN(eps=eps, min_samples=min_samples)
y = dbscan.fit_predict(X)
# Visualisation des résultats du regroupement
plt.figure(figsize=(20, 15))
plt.subplot(2, 2, 1)
for i in range(len(spiral['spiral'])):
plt.scatter(spiral['spiral'][i][0], spiral['spiral']
[i][1], color=colors[int(spiral['spiral'][i][2])])
plt.title("Données brutes")
plt.subplot(2, 2, 2)
for i in range(len(y)):
plt.scatter(spiral['spiral'][i][0], spiral['spiral']
[i][1], color=colors[y[i]])
plt.title(" Données après regroupement ")
moonDonnées
# Importer des données
colors = ['green', 'red']
moon = loadmat('data-Regroupement de la densité/moon.mat')
X = moon['a']
eps, min_samples = search_best_parameter(2, X)
dbscan = DBSCAN(eps=eps, min_samples=min_samples)
y = dbscan.fit_predict(X)
# Visualisation des résultats du regroupement
plt.figure(figsize=(20, 15))
plt.subplot(2, 2, 1)
for i in range(len(moon['a'])):
plt.scatter(moon['a'][i][0], moon['a']
[i][1], color=colors[int(moon['a'][i][2])])
plt.title("Données brutes")
plt.subplot(2, 2, 2)
for i in range(len(y)):
plt.scatter(moon['a'][i][0], moon['a']
[i][1], color=colors[y[i]])
plt.title(" Données après regroupement ")

longDonnées
# Importer des données
colors = ['green', 'red']
long = loadmat('data-Regroupement de la densité/long.mat')
X = long['long1']
eps, min_samples = search_best_parameter(2, X)
dbscan = DBSCAN(eps=eps, min_samples=min_samples)
y = dbscan.fit_predict(X)
# Visualisation des résultats du regroupement
plt.figure(figsize=(20, 15))
plt.subplot(2, 2, 1)
for i in range(len(long['long1'])):
plt.scatter(long['long1'][i][0], long['long1']
[i][1], color=colors[int(long['long1'][i][2])])
plt.title("Données brutes")
plt.subplot(2, 2, 2)
for i in range(len(y)):
plt.scatter(long['long1'][i][0], long['long1']
[i][1], color=colors[y[i]])
plt.title(" Données après regroupement ")

2d4cDonnées
# Importer des données
colors = ['green', 'red', 'blue', 'black']
d4c = loadmat('data-Regroupement de la densité/2d4c.mat')
X = d4c['a']
eps, min_samples = search_best_parameter(4, X)
dbscan = DBSCAN(eps=eps, min_samples=min_samples)
y = dbscan.fit_predict(X)
# Visualisation des résultats du regroupement
plt.figure(figsize=(20, 15))
plt.subplot(2, 2, 1)
for i in range(len(d4c['a'])):
plt.scatter(d4c['a'][i][0], d4c['a']
[i][1], color=colors[int(d4c['a'][i][2])])
plt.title("Données brutes")
plt.subplot(2, 2, 2)
for i in range(len(y)):
plt.scatter(d4c['a'][i][0], d4c['a']
[i][1], color=colors[y[i]])
plt.title(" Données après regroupement ")

Résumé
Les expériences ci - dessus prouvent que DBSCAN La méthode de regroupement dépend du degré d'association à l'emplacement des points de données ,Poursmile、spiral L'effet de regroupement des données de distribution égale est meilleur .
边栏推荐
- dotConnect for PostgreSQL数据提供程序
- Vim 9.0正式发布!新版脚本执行速度最高提升100倍
- leetcode 6103 — 从树中删除边的最小分数
- Mathematical Knowledge: Steps - Nim Games - Game Theory
- CF1617B Madoka and the Elegant Gift、CF1654C Alice and the Cake、 CF1696C Fishingprince Plays With Arr
- 什么是调。调的故事
- 软考信息系统项目管理师_历年真题_2019下半年错题集_上午综合知识题---软考高级之信息系统项目管理师053
- How is the mask effect achieved in the LPL ban/pick selection stage?
- [fh-gfsk] fh-gfsk signal analysis and blind demodulation research
- 按键精灵打怪学习-自动回城路线的判断
猜你喜欢

Arduino DY-SV17F自动语音播报
串口抓包/截断工具的安装及使用详解

How is the mask effect achieved in the LPL ban/pick selection stage?

【面试题】1369- 什么时候不能使用箭头函数?

力扣 204. 计数质数
![[QT] encapsulation of custom controls](/img/33/aa2ef625d1e51e945571c116a1f1a9.png)
[QT] encapsulation of custom controls

MySQL foundation 04 MySQL architecture
![[technology development-23]: application of DSP in future converged networks](/img/2e/f39543a18a8f58b1d341ce72cc4427.png)
[technology development-23]: application of DSP in future converged networks
![[androd] module dependency replacement of gradle's usage skills](/img/5f/968db696932f155a8c4a45f67135ac.png)
[androd] module dependency replacement of gradle's usage skills

Androd Gradle 对其使用模块依赖的替换
随机推荐
[Cao gongzatan] after working in goose factory for a year in 2021, some of my insights
Common English Vocabulary
【数据挖掘】任务4:20Newsgroups聚类
数学知识:Nim游戏—博弈论
LeetCode 987. Vertical order transverse of a binary tree - Binary Tree Series Question 7
C#应用程序界面开发基础——窗体控制(3)——文件类控件
看完这篇 教你玩转渗透测试靶机Vulnhub——DriftingBlues-9
Basic remote connection tool xshell
Thinkphp+redis realizes simple lottery
QTableWidget懒加载剩内存,不卡!
对非ts/js文件模块进行类型扩充
Mathematical knowledge: Nim game game theory
Arduino dy-sv17f automatic voice broadcast
Steps to obtain SSL certificate private key private key file
leetcode 2097 — 合法重新排列数对
Key wizard hit strange learning - automatic path finding back to hit strange points
Leetcode 2097 - Legal rearrangement of pairs
【第29天】给定一个整数,请你求出它的因子数
Expérience de recherche d'emploi d'un programmeur difficile
Soft exam information system project manager_ Real topic over the years_ Wrong question set in the second half of 2019_ Morning comprehensive knowledge question - Senior Information System Project Man