This note still belongs to TD Category of algorithm .Multi-Step-TD-Target It's right TD Algorithm improvement .
9. Multi-Step-TD-Target
9.1 Review Sarsa & Q-Learning
- Sarsa
- Training Action value function \(Q_\pi(s,a)\);
- TD Target yes \(y_t = r_t + \gamma\cdot Q_\pi(s_{t+1},a_{t+1})\)
- Q-Learning
- Training The optimal Action value function Q-star;
- TD Target yes \(y_t = r_t +\gamma \cdot \mathop{max}\limits_{a} Q^*({s_{t+1}},a)\)
- Be careful , Of the two algorithms TD Target Of r part It's just One Reward \(r_t\)
- If you use multiple rewards , that RL The effect will be better ;Multi-Step-TD-Target Based on this consideration .
In the first chapter of reinforcement learning Basic concepts in , Just mentioned ,agent The following trajectory will be observed :
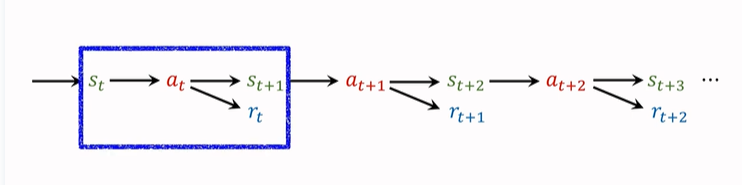
We only used one before transition To record the action 、 Reward , And update TD-Target. One transition Include \((s_t,a_t,s_{t+1},r_t)\), There is only one reward \(r_t\).( As shown in the blue box above ).
That's how it works out TD Target Namely One Step TD Target.
In fact, we can also use more than one at a time transition The reward in the game , Got TD Target Namely Multi-Step-TD-Target. As shown in the following figure, two are selected in the blue box transition, Similarly, you can choose the last two transition .
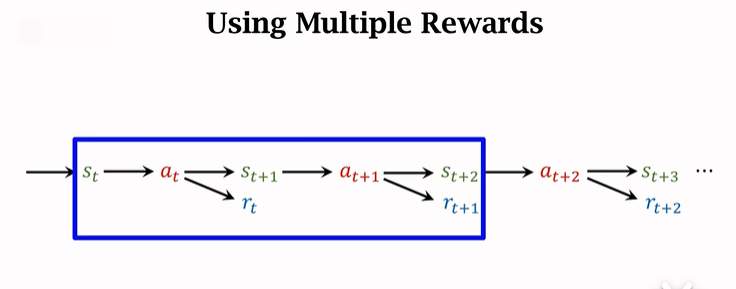
9.2 Multi step discount return
Multi-Step Return.
The discount return formula is :\(U_t=R_t+\gamma\cdot{U_{t+1}}\);
This formula establishes t Time and t+1 The moment U The relationship between , In order to get a multi-step discount return , We use this formula recursively :
\(U_t=R_t+\gamma\cdot{U_{t+1}}\\=R_t+\gamma\cdot(R_{t+1}+\gamma\cdot{U_{t+2}})\\=R_t+\gamma\cdot{R_{t+1}}+\gamma^2\cdot{U_{t+2}}\)
such , We can include Two rewards , Similarly, we can have Three rewards ...... Recursion , contain m Awards are :
\(U_t=\sum_{i=0}^{m-1}\gamma^i\cdot{R_{t+i}}+\gamma^m\cdot{U_{t+m}}\)
namely : Return \(U_t\) be equal to m Weighted sum of awards , Plus \(\gamma^m\cdot{U_{t+m}}\), The latter item is called Multi step return .
Now we have launched Multi step \(U_t\) Formula , Further, we can introduce Step by step \(y_t\) Formula , That is, expect both sides of the equation respectively , Make random variables specific :
Sarsa Of m-step TD target:
\(y_t=∑_{i=0}^{m−1}\gamma^i\cdot r_{t+i}+\gamma^m\cdot{Q_\pi}(s_{t+m},a_{t+m})\)
Be careful :m=1 when , It is the standard we are familiar with before TD Target.
Multi step TD Target The effect is better than Single step good .
Q-Learning Of m-step TD target:
\(y_t = \sum_{i=0}^{m-1}\gamma^i{r_{t+i}}+\gamma^m\cdot\mathop{max}\limits_{a} Q^*({s_{t+m}},a)\)
Again ,m=1 when , That's what happened before TD Target.
9.3 Single step And Step by step Comparison of
Single step TD Target in , Use only one reward \(r_t\);
If you use multiple steps TD Target, Will use multiple rewards :\(r_t,r_{t+1},...,r_{t+m-1}\)
Think about the second Value learning An example of a journey , If the proportion of the actual journey is higher , Don't consider “ cost ” Under the circumstances , The estimation of travel time will be more reliable .
m It's a super parameter , It needs to be adjusted manually , If adjusted properly , The effect will be much better .
x. Reference tutorial
- Video Course : Deep reinforcement learning ( whole )_ Bili, Bili _bilibili
- Video original address :https://www.youtube.com/user/wsszju
- Courseware address :https://github.com/wangshusen/DeepLearning
![The maximum number of meetings you can attend [greedy + priority queue]](/img/f3/e8e939e0393efc404cc159d7d33364.png)