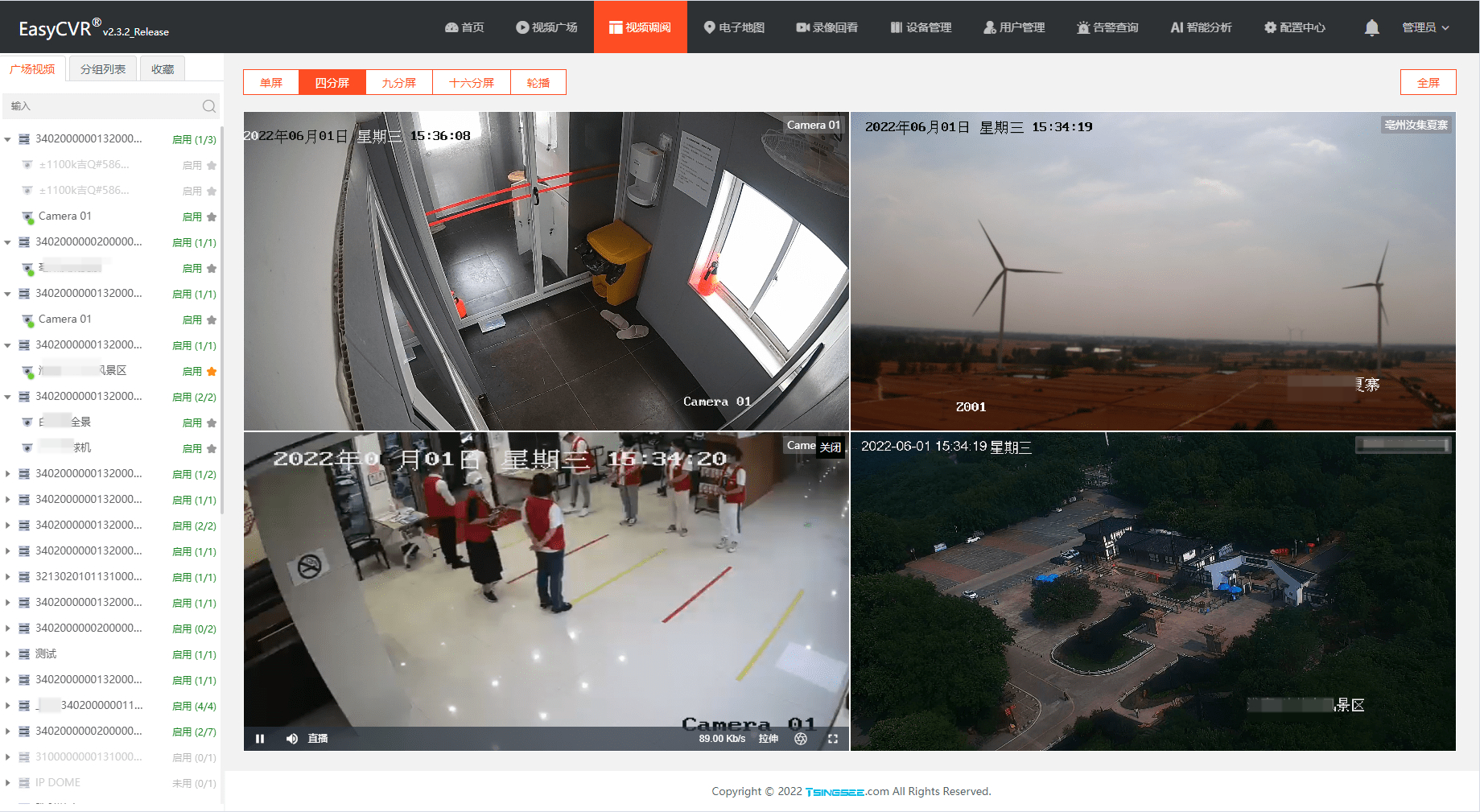
Reptile battle ( 7、 ... and ): Climbing King hero pictures
One 、 Website analysis
1、 Page analysis
We analyze the interface of King glory hero , Find out , Its data is not stored in the source code , Then it's not a static URL , We cannot obtain data by directly obtaining the source code

adopt F12 You can get a link with the same name as the page json file , A lot of garbled information is stored inside , By coding utf-8, It can be seen that , This JSON What is stored is the information of all heroes

2、 Source code analysis
that , Our homepage analysis is finished , then , We analyze the interface of individual heroes , We found that the background picture in the interface of each hero is the high-definition big picture of the hero , And you can switch pictures through the icon in the lower right corner , that , Image links must be stored in the source code of the page , Sure enough , Through translation, we found the link of the background picture , We can speculate , If you change the last number of the picture link to 2, You can change to the second skin , that , How do we get the amount of skin ?

3、 Link analysis
that , The problem is coming. , How do we enter the details interface of each hero ?
here , Let's first show some of the hero data we obtained earlier
[{'ename': 105, 'cname': ' Lian po ', 'title': ' Justice booms ', 'new_type': 0, 'hero_type': 3, 'skin_name': ' Justice booms | Hell rock soul '},
{'ename': 106, 'cname': ' Little Joe ', 'title': ' The breeze of love ', 'new_type': 0, 'hero_type': 2, 'skin_name': ' The breeze of love | The night before all saints | Swan dream | Pure white flowers marry | Colorful unicorns '},
{'ename': 107, 'cname': ' zhaoyun ', 'title': ' The sky is full of dragons ', 'new_type': 0, 'hero_type': 1, 'hero_type2': 4, 'skin_name': ' The sky is full of dragons | endure ● Burning shadow | The future era | The Royal admiral | Hip hop King | Deacon white | The heart of the engine '}]
then , Let's take a look at the link of the details page
https://pvp.qq.com/web201605/herodetail/105.shtml Lian po
https://pvp.qq.com/web201605/herodetail/106.shtml Little Joe
https://pvp.qq.com/web201605/herodetail/107.shtml zhaoyun
so , We found that , In the data ename Can help us get a link to the hero details page , meanwhile ,shin_name Skin for Heroes , But it can be seen from Lianpo that the skin of heroes is not very complete ,
that , How do we name pictures ?
From the source , We found that , There is a place to store the skin data of heroes , also , It is also corresponding to the index of hero pictures , We can also check how many skins there are according to this

that , Could it be a little simpler ?
Let's directly analyze the image links of the hero's original skin :
https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/105/105-bigskin-1.jpg # Lian po
https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/106/106-bigskin-1.jpg # Little Joe
https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/107/107-bigskin-1.jpg # zhaoyun
We found that , Only the change of hero number , The rest is unchanged
4、 Climbing process
that , Our crawling method is :
- Get all the hero data
- Get how many skins the hero has
- Send a request for the picture
Two 、 Write code
1、 obtain JSON data
import requests # The import module , Send a request , Handle JSON data
from fake_useragent import UserAgent # Random request header
headers = {
"user-agent": UserAgent().random, # Request header
"referer": "https://pvp.qq.com/web201605/herolist.shtml", # Indicate source
}
infolist = []
def get_infolist():
resp = requests.get("https://pvp.qq.com/web201605/js/herolist.json", headers=headers) # Send a request
resp.encoding = resp.apparent_encoding # Set encoding , To prevent the occurrence of random code
data = resp.json() # get data , And convert to list format
for i in data:
""" We only take the hero number and hero name """
infolist.append({
"id": i["ename"],
"name": i["cname"]
})
print(" Hero data acquisition completed !")
get_infolist()
print(infolist)
2、 Get skin quantity
import re # Using regular parsing , get data
skin_num_url = "https://pvp.qq.com/web201605/herodetail/%d.shtml"
def get_skin_num(id):
resp = requests.get(skin_num_url % id, headers=headers) # Send a request
resp.encoding = resp.apparent_encoding # Set encoding , To prevent the occurrence of random code
skin = re.search('<ul class="pic-pf-list.*?" data-imgname="(?P<skin>.*?)">', resp.text).group("skin")
# Data cleaning
lis = skin.split("|")
# print(lis)
for k, i in enumerate(lis):
try:
temp = re.search("(?P<name>.*?)&", i).group("name")
except AttributeError:
temp = i # It may not be necessary to clean the data
lis[k] = temp
# print(lis)
return lis
# get_skin_num(105)
for i in infolist:
""" Traversal data , Add skin names and skin numbers to the dictionary """
ret = get_skin_num(i["id"]) # hold id Pass in
i.update({
"skin": ret,
})
print(infolist)
3、 Download skin pictures
import os, time
skin_url = "https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{id}/{id}-bigskin-{index}.jpg"
def save_skin(dic):
""" Pass the data dictionary into , Do the rest """
if not os.path.exists(f"./ The king glorifies the skin /{dic['name']}"):
os.mkdir(f"./ The king glorifies the skin /{dic['name']}")
for i in range(len(dic["skin"])):
url_ = skin_url.format(id=dic["id"], index=i + 1)
resp = requests.get(url_, headers=headers)
file = open(f"./ The king glorifies the skin /{dic['name']}/{dic['skin'][i]}.jpg", "wb")
file.write(resp.content)
file.close()
print(dic["skin"][i], " Download complete ")
time.sleep(30)
for i in infolist:
save_skin(i)
print(f"{i['name']} Hero skin download completed ")
print(" All skin downloads are complete !")
3、 ... and 、 Master code
import requests # The import module , Send a request
import re # Using regular parsing , get data
import os, time, json # Write data to a file
from fake_useragent import UserAgent # Random request header
headers = {
"user-agent": UserAgent().random, # Request header
"referer": "https://pvp.qq.com/web201605/herolist.shtml", # Indicate source
}
skin_num_url = "https://pvp.qq.com/web201605/herodetail/%d.shtml"
skin_url = "https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{id}/{id}-bigskin-{index}.jpg"
infolist = []
def get_infolist():
global infolist
try:
with open("infolist.json", "r", encoding="utf-8") as file:
infolist = json.load(file)
if not infolist: # If there is no value in the file, it will directly report an error
raise IOError
except Exception as e:
resp = requests.get("https://pvp.qq.com/web201605/js/herolist.json", headers=headers) # Send a request
resp.encoding = resp.apparent_encoding # Set encoding , To prevent the occurrence of random code
data = resp.json() # get data , And convert to list format
for i in data:
""" We only take the hero number and hero name """
infolist.append({
"id": i["ename"],
"name": i["cname"]
})
print(" Hero data acquisition completed !")
def get_skin_num(id):
""" Get skin names and numbers """
resp = requests.get(skin_num_url % id, headers=headers) # Send a request
resp.encoding = resp.apparent_encoding # Set encoding , To prevent the occurrence of random code
skin = re.search('<ul class="pic-pf-list.*?" data-imgname="(?P<skin>.*?)">', resp.text).group("skin")
# Data cleaning
lis = skin.split("|")
# print(lis)
for k, i in enumerate(lis):
try:
temp = re.search("(?P<name>.*?)&", i).group("name")
except AttributeError:
temp = i # It may not be necessary to clean the data
lis[k] = temp
# print(lis)
return lis
def save_skin(dic):
""" Pass the data dictionary into , Do the rest """
if not os.path.exists(f"./ The king glorifies the skin /{dic['name']}"):
os.mkdir(f"./ The king glorifies the skin /{dic['name']}")
for i in range(len(dic["skin"])):
url_ = skin_url.format(id=dic["id"], index=i + 1)
resp = requests.get(url_, headers=headers)
file = open(f"./ The king glorifies the skin /{dic['name']}/{dic['skin'][i]}.jpg", "wb")
file.write(resp.content)
file.close()
print(dic["skin"][i], " Download complete ")
time.sleep(30)
def main():
get_infolist()
if not os.path.exists(f"./ The king glorifies the skin "):
""" If the folder does not exist , Create """
os.mkdir(f"./ The king glorifies the skin ")
for i in infolist:
""" Traversal data , Add skin names and skin numbers to the dictionary """
ret = get_skin_num(i["id"]) # hold id Pass in
i.update({
"skin": ret,
"is_down": False # Whether the record has been downloaded
})
# Write data to a file , You can continue to use it next time
file = open("infolist.json", "w", encoding="utf-8")
json.dump(infolist, file, indent=8, ensure_ascii=False)
file.close()
for i in infolist:
if not i["is_down"]: # If the skin is not downloaded , Then download
save_skin(i)
print(f"{i['name']} Hero skin download completed ")
else:
print(f"{i['name']} Hero skin has been downloaded ")
print(" All skin downloads are complete !")
if __name__ == "__main__":
main()
Last , Enjoy the pictures !

![[C language] advanced pointer --- do you really understand pointer?](/img/ee/79c0646d4f1bfda9543345b9da0f25.png)