当前位置:网站首页>特征生成
特征生成
2022-07-07 20:57:00 【全栈程序员站长】
大家好,又见面了,我是全栈君。
特征准则
区分性:不同类别模式在特征空间可分
不变性:同一类别模式在特征空间的变化(变化、形变、噪声) 选取区分性高、且同意一定不变性的特征
特征生成的一些方法 1 时域、频域、视频联合 相关系数、FFT、DCT、Wavelet、Gabor 2 统计、结构、混合 直方图、属性-关系图 3 底层、中层、高层 颜色、梯度(Robert、Prewitt、Sobel、差分+平滑、HOG)、纹理(类Harr、LBP)、形状、语义 4 模型 ARMA、LPC
三个实例
A SIFT 1 建立高斯金字塔 做差生成DOG(LOG)的近似 2 求取极值点,并依据导数求取优化极值点 3 依据Hessian矩阵(能够自相关函数)去掉边缘和不稳定的点 4 进行梯度描写叙述
详细步骤參考《图像局部不变性特征与描写叙述》及 http://underthehood.blog.51cto.com/2531780/658350 带有SIFT凝视的代码,请參考
B Bag of Words 1 聚类-构建词典 2 映射到词典,然后SVM等其它分类器进行训练分类就可以
详细点有 1 Feature extraction 2 Codebook generation 3 Coding(Hard or Soft) 4 Polling(Average or Max) 5 Classify
“ 如今Computer Vision中的Bag of words来表示图像的特征描写叙述也是非常流行的。
大体思想是这种,如果有5类图像。每一类中有10幅图像。这样首先对每一幅图像划分成patch(能够是刚性切割也能够是像SIFT基于关键点检測的),这样。每个图像就由非常多个patch表示,每个patch用一个特征向量来表示,咱就如果用Sift表示的,一幅图像可能会有成百上千个patch,每个patch特征向量的维数128。
接下来就要进行构建Bag of words模型了,如果Dictionary词典的Size为100,即有100个词。那么咱们能够用K-means算法对全部的patch进行聚类,k=100,我们知道,等k-means收敛时。我们也得到了每个cluster最后的质心。那么这100个质心(维数128)就是词典里德100个词了,词典构建完成。
词典构建完了怎么用呢?是这种,先初始化一个100个bin的初始值为0的直方图h。每一幅图像不是有非常多patch么?我们就再次计算这些patch和和每个质心的距离,看看每个patch离哪一个质心近期,那么直方图h中相相应的bin就加1,然后计算完这幅图像全部的patches之后,就得到了一个bin=100的直方图。然后进行归一化。用这个100维德向量来表示这幅图像。
对全部图像计算完毕之后。就能够进行分类聚类训练预測之类的了。 “
C 图像显著性 1 多尺度对照 2 中心周围直方图 3 颜色空间分布
发布者:全栈程序员栈长,转载请注明出处:https://javaforall.cn/116276.html原文链接:https://javaforall.cn
边栏推荐
- UVA 11080 – Place the Guards(二分图判定)
- 写一下跳表
- Details of C language integer and floating-point data storage in memory (including details of original code, inverse code, complement, size end storage, etc.)
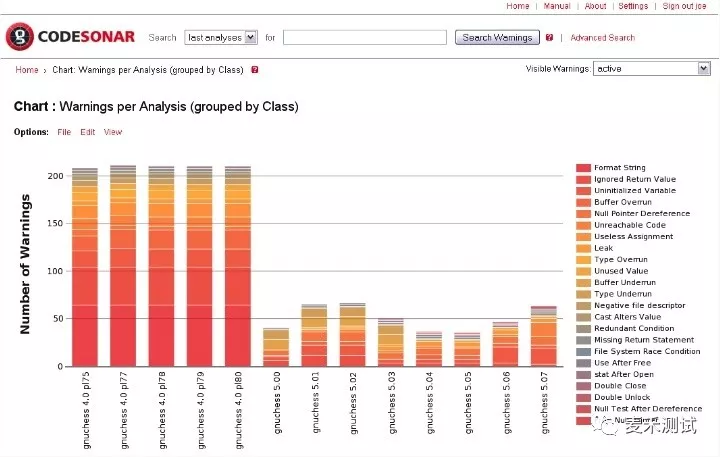
- CodeSonar如何帮助无人机查找软件缺陷?
- OneSpin 360 DV新版发布,刷新FPGA形式化验证功能体验
- Implement secondary index with Gaussian redis
- Cantata9.0 | 全 新 功 能
- 目标:不排斥 yaml 语法。争取快速上手
- The latest version of codesonar has improved functional security and supports Misra, c++ parsing and visualization
- 写了个 Markdown 命令行小工具,希望能提高园友们发文的效率!
猜你喜欢
智能软件分析平台Embold
C language helps you understand pointers from multiple perspectives (1. Character pointers 2. Array pointers and pointer arrays, array parameter passing and pointer parameter passing 3. Function point
复杂因子计算优化案例:深度不平衡、买卖压力指标、波动率计算

测量楼的高度

Onespin | solve the problems of hardware Trojan horse and security trust in IC Design
CodeSonar通过创新型静态分析增强软件可靠性

I wrote a markdown command line gadget, hoping to improve the efficiency of sending documents by garden friends!

如何满足医疗设备对安全性和保密性的双重需求?

CodeSonar网络研讨会

万字总结数据存储,三大知识点
随机推荐
Is it safe to open a stock account at present? Can I open an account online directly.
MinGW MinGW-w64 TDM-GCC等工具链之间的差别与联系「建议收藏」
AADL inspector fault tree safety analysis module
Jetty:配置连接器[通俗易懂]
HDU4876ZCC loves cards(多校题)
C语言多角度帮助你深入理解指针(1. 字符指针2. 数组指针和 指针数组 、数组传参和指针传参3. 函数指针4. 函数指针数组5. 指向函数指针数组的指针6. 回调函数)
【奖励公示】第22期 2022年6月奖励名单公示:社区明星评选 | 新人奖 | 博客同步 | 推荐奖
想杀死某个端口进程,但在服务列表中却找不到,可以之间通过命令行找到这个进程并杀死该进程,减少重启电脑和找到问题根源。
Implement secondary index with Gaussian redis
现在网上开户安全么?想知道我现在在南宁,到哪里开户比较好?
CodeSonar如何帮助无人机查找软件缺陷?
How to choose financial products? Novice doesn't know anything
Small guide for rapid formation of manipulator (11): standard nomenclature of coordinate system
上海交大最新《标签高效深度分割》研究进展综述,全面阐述无监督、粗监督、不完全监督和噪声监督的深度分割方法
openGl超级宝典学习笔记 (1)第一个三角形「建议收藏」
[paper reading] maps: Multi-Agent Reinforcement Learning Based Portfolio Management System
论文解读(ValidUtil)《Rethinking the Setting of Semi-supervised Learning on Graphs》
凌云出海记 | 赛盒&华为云:共助跨境电商行业可持续发展
Klocwork 代码静态分析工具
Can Huatai Securities achieve Commission in case of any accident? Is it safe to open an account