当前位置:网站首页>Tools used for Yolo object recognition and data generation
Tools used for Yolo object recognition and data generation
2022-07-02 09:38:00 【Ignorant dream fireworks】
YOLO Object recognition , Tools used to generate data
1 remove_spaces( Remove the space in the file name , take “ ” Replace with “_”)
Before running :
import os
import string
def listdir(path, list_name):
for file in os.listdir(path):
file_path = os.path.join(path, file)
if os.path.isdir(file_path):
listdir(file_path, list_name)
elif os.path.splitext(file_path)[1] == '.xml' or os.path.splitext(file_path)[1] == '.jpg':
list_name.append(file_path)
if (1):
# 1. Read xml file
file_path = "C:/31/darknet-master/build/darknet/x64/data/voc/VOC2020/JPEGImages"
list_name = []
listdir(file_path, list_name)
# print(list_name)
size = 0
str_ = ""
for file_name in list_name:
# print(tree)
# 2. Attribute changes
# A. Find the parent node
str_ = ((file_name).replace(' ','_'))
os.rename(file_name, str_)
size+=1
print( file_name + " " + str(size) +' succeful! ')
After operation :
2 change_xml ( modify xml Chinese and path errors in the file )
The following error occurred while generating the dataset :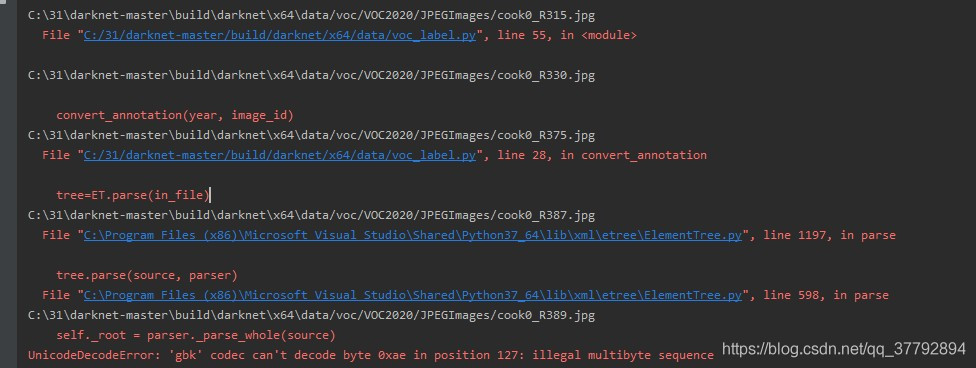
Before running :
from xml.etree.ElementTree import ElementTree, Element
def read_xml(in_path):
''''' Read and parse xml file
in_path: xml route
return: ElementTree'''
tree = ElementTree()
tree.parse(in_path)
return tree
def write_xml(tree, out_path):
''''' take xml The document says
tree: xml Trees
out_path: Write the path '''
tree.write(out_path, encoding="utf-8", xml_declaration=True)
def if_match(node, kv_map):
''''' Judge whether a node contains all the passed in parameter attributes
node: node
kv_map: Attribute and attribute value map'''
for key in kv_map:
if node.get(key) != kv_map.get(key):
return False
return True
# ---------------search -----
def find_nodes(tree, path):
''''' Find all nodes matching a path
tree: xml Trees
path: Node path '''
return tree.findall(path)
def get_node_by_keyvalue(nodelist, kv_map):
''''' Locate the matching node according to the attribute and attribute value , Return to node
nodelist: The node list
kv_map: Match attribute and attribute value map'''
result_nodes = []
for node in nodelist:
if if_match(node, kv_map):
result_nodes.append(node)
return result_nodes
# ---------------change -----
def change_node_properties(nodelist, kv_map, is_delete=False):
''''' modify / increase / Delete Attributes and attribute values of nodes
nodelist: The node list
kv_map: Property and property value map'''
for node in nodelist:
for key in kv_map:
if is_delete:
if key in node.attrib:
del node.attrib[key]
else:
node.set(key, kv_map.get(key))
def change_node_text(nodelist, text, is_add=False, is_delete=False):
''''' change / increase / Delete the text of a node
nodelist: The node list
text : Updated text '''
for node in nodelist:
if is_add:
node.text += text
elif is_delete:
node.text = ""
else:
node.text = text
def create_node(tag, property_map, content):
''''' Create a new node
tag: Node labels
property_map: Property and property value map
content: The text content in the node closure label
return New node '''
element = Element(tag, property_map)
element.text = content
return element
def add_child_node(nodelist, element):
''''' Add child nodes to a node
nodelist: The node list
element: Child node '''
for node in nodelist:
node.append(element)
def del_node_by_tagkeyvalue(nodelist, tag, kv_map):
''''' Locate a node through the attribute and attribute value , And delete it
nodelist: List of parent nodes
tag: Child node label
kv_map: Attribute and attribute value list '''
for parent_node in nodelist:
children = parent_node.getchildren()
for child in children:
if child.tag == tag and if_match(child, kv_map):
parent_node.remove(child)
import os
import string
def listdir(path, list_name):
for file in os.listdir(path):
file_path = os.path.join(path, file)
if os.path.isdir(file_path):
listdir(file_path, list_name)
elif os.path.splitext(file_path)[1] == '.xml':
list_name.append(file_path)
if (1):
# 1. Read xml file
file_path = "C:/Users/zhumengbo/Desktop/new/original"
list_name = []
listdir(file_path, list_name)
# print(list_name)
size = 0
str_ = ""
for strPath in list_name:
tree = read_xml(strPath)
# print(tree)
# 2. Attribute changes
# A. Find the parent node
nodes = find_nodes(tree, "path")
str_ = ((strPath).replace('\\','/'))
change_node_text(nodes, str_)
write_xml(tree, str_)
size+=1
print( str_ + " " + str(size) +' succeful! ')
Change file name : take New folder modify by fruit_plates, The program automatically modifies the original path according to the current new folder name
After operation :
3 Get rid of the excess jpg and xml file
In the data set ,jpg Document and xml You need to be in pairs
import os
import string
def listdir(path, list_name, format):
for file in os.listdir(path):
file_path = os.path.join(path, file)
if os.path.isdir(file_path):
listdir(file_path, list_name)
elif os.path.splitext(file_path)[1] == format:
list_name.append(os.path.splitext(file_path)[0].split('\\')[-1])
def aligning(path):
list_xml_name = []
list_jpg_name = []
listdir(path, list_xml_name, '.xml')
listdir(path, list_jpg_name, '.jpg')
# Remove redundant xml file
for file_name_xml in list_xml_name:
is_exit = 0
for file_name_jpg in list_jpg_name:
if file_name_xml == file_name_jpg:
is_exit = 1
break
if is_exit == 0:
current_file_path = path + '/' + file_name_xml + '.xml'
if os.path.exists(current_file_path): # If the file exists
# Delete file , Two methods can be used .
os.remove(current_file_path)
# Remove redundant jpg file
for file_name_jpg in list_jpg_name:
is_exit = 0
for file_name_xml in list_xml_name:
if file_name_jpg == file_name_xml:
is_exit = 1
break
if is_exit == 0:
current_file_path = path + '/' + file_name_jpg + '.xml'
if os.path.exists(current_file_path): # If the file exists
# Delete file , Two methods can be used .
os.remove(current_file_path)
if (1):
# 1. Read xml file
aligning('C:/Users//Desktop/img/label20201009/label/yellow_belt/yellow_belt2_xml')
边栏推荐
- MySQL multi column in operation
- How to choose between efficiency and correctness of these three implementation methods of distributed locks?
- Insight into cloud native | microservices and microservice architecture
- ClassFile - Attributes - Code
- Micro service practice | introduction and practice of zuul, a micro service gateway
- 记录下对游戏主机配置的个人理解与心得
- 自定义Redis连接池
- Read 30 minutes before going to bed every day_ day3_ Files
- C语言之判断直角三角形
- Solutions to Chinese garbled code in CMD window
猜你喜欢

JDBC回顾

Idea view bytecode configuration
Bold prediction: it will become the core player of 5g
![[go practical basis] gin efficient artifact, how to bind parameters to structures](/img/c4/44b3bda826bd20757cc5afcc5d26a9.png)
[go practical basis] gin efficient artifact, how to bind parameters to structures

Beats (filebeat, metricbeat), kibana, logstack tutorial of elastic stack

在SQL注入中,为什么union联合查询,id必须等于0
Redis installation and deployment (windows/linux)

The channel cannot be viewed when the queue manager is running
Chrome browser tag management plug-in – onetab

一次聊天勾起的回忆
随机推荐
What are the differences between TP5 and laravel
Statistical learning methods - Chapter 5, decision tree model and learning (Part 1)
Methods of classfile
2837xd 代码生成——补充(3)
Navicat 远程连接Mysql报错1045 - Access denied for user ‘root‘@‘222.173.220.236‘ (using password: YES)
Pool de connexion redis personnalisé
Chrome browser tag management plug-in – onetab
并网逆变器PI控制(并网模式)
图像识别-数据标注
微服务实战|声明式服务调用OpenFeign实践
Ora-12514 problem solving method
From concept to method, the statistical learning method -- Chapter 3, k-nearest neighbor method
ZK configuration center -- configuration and use of config Toolkit
cmake的命令-官方文档
Actual combat of microservices | discovery and invocation of original ecosystem implementation services
互联网API接口幂等设计
每天睡觉前30分钟阅读_day3_Files
Amq6126 problem solving ideas
Read 30 minutes before going to bed every day_ day4_ Files
Microservice practice | load balancing component and source code analysis