当前位置:网站首页>Figure neural network makes Google maps more intelligent
Figure neural network makes Google maps more intelligent
2022-06-12 08:12:00 【Here comes the classmate】
For the field of public travel , The arrival time of vehicles is the main influencing factor , Estimated time of arrival (ETA) Accuracy has become a very practical research topic . In recent days, , British artificial intelligence company DeepMind Deep cooperation with Google Maps , Using graph neural network (Graph Neural Networks,GNN) etc. ML technology , It has greatly improved Berlin 、 Tokyo 、 Real time in big cities like Sydney ETA Accuracy rate .
Many people use Google Maps (Google Maps) Get accurate traffic forecasts and estimated arrival times (Estimated Time of Arrival,ETA), This is a very important tool , Especially when you are going through a traffic jam or need to attend an important meeting on time . For car sharing service companies and other enterprises , They can be used Google Maps The platform obtains the pick-up time information and estimates the price based on the ride time . DeepMind And Google Maps The research team cooperates , Try advanced machine learning techniques such as graph neural network , Upgrade Berlin 、 Jakarta 、 Sao Paulo 、 Sydney 、 Real time in Tokyo and Washington, D.C ETA Accuracy rate , The highest rise 50%. The following figure shows the ETA Promotion rate :
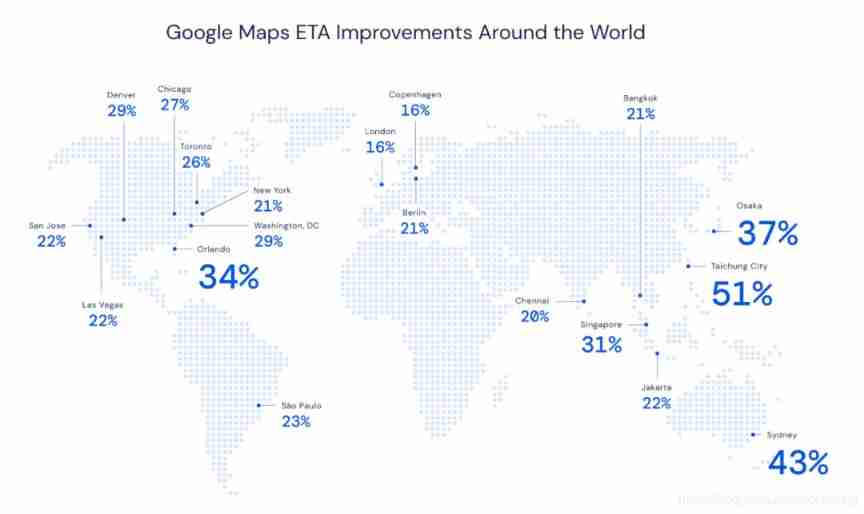
Google Maps How to predict ETA For calculation ETA,Google Maps The real-time traffic data of different road sections around the world are analyzed . These data are Google Maps It provides an accurate picture of the current traffic conditions , But it can't help the driver to predict the driving time 10 minute 、20 minute , still 50 minute . therefore , In order to accurately predict future traffic conditions ,Google Maps Use machine learning to combine real-time traffic conditions of global roads with historical traffic patterns . This process is very complicated , For many reasons . for example , There are morning and evening rush hours every day , But every day 、 The exact peak time of each month is very different . Road quality 、 The speed limit 、 Traffic accidents and other factors also increase the complexity of the traffic prediction model . DeepMind Team and Google Maps Cooperate to try to improve ETA Accuracy rate .Google Maps For more than 97% The itinerary has a precise ETA forecast ,DeepMind And Google Maps The goal of our collaboration is to minimize the remaining inaccuracies in our forecasts , For example, Taichung (Taichung) Of ETA The prediction accuracy has improved 50% many . In order to achieve this goal on a global scale ,DeepMind A general machine learning architecture is utilized —— Figure neural network (GNN), Spatiotemporal reasoning is carried out by adding relationship learning bias to the model , Then the connectivity of the real world road network is modeled . The specific steps are as follows : Divide the roads in the world into super sections (Supersegment) The team divided the road network into several adjacent sections 「 Super section 」, The super sections have great traffic flow . at present ,Google Maps The traffic forecasting system consists of the following components :
1) Route Analyzer : Have a number TB Traffic information , It can be used to build super sections ;
2) new type GNN Model : Use multiple objective functions for optimization , Be able to predict the travel time of each super section .

Google Maps Diagram of the model structure for determining the optimal route and travel time . Traffic forecasting with a new machine learning architecture Create a machine learning system for estimating travel time using super links , The biggest challenge is architecture . How to represent the variable scale sample of the link with any accuracy , So as to ensure that a single model can predict successfully ? DeepMind The team's initial proof of concept began with a straightforward approach , This method makes best use of the existing transportation system , Especially the existing road network segmentation and related real-time data pipeline. This means that the super section covers a set of sections , Each section has a specific length and corresponding speed characteristics . First , The team trained a fully connected neural network model for each super road section . The preliminary results are good , It shows that neural network has great potential in predicting travel time . however , Given the variable size of the Super Section , The team needs to train the neural network model separately for each super section . To achieve large-scale deployment , Millions of such models must be trained , This poses a huge challenge to the infrastructure . therefore , The team started working on models that could handle variable length sequences , For example, cyclic neural network (RNN). however , towards RNN Adding structures from the road network is difficult . therefore , The researchers decided to use graph neural networks . When modeling traffic conditions , How vehicles cross the road network is the focus of this study , Graph neural network can model network dynamics and information transmission . The model proposed by the team regards the local road network as a graph , Each road section corresponds to a node , Connect the two sections ( node ) The sides of are either on the same road , Or through the intersection ( Crossing ) Connect . When executing a message passing algorithm in a graph neural network , The message it transmits and its influence on the states of edges and nodes are learned by neural network . Look at it this way , Super sections are road subgraphs randomly sampled according to traffic density . therefore , Using these sampled subgraphs can train a single model , And a single model can be deployed on a large scale .

Figure neural network through generalization 「 Similarity degree (proximity)」 Concept , The learning bias imposed by convolutional neural network and cyclic neural network is extended (learning bias), And then the connection with arbitrary complexity , It can not only deal with the traffic situation in front of and behind the road , You can also deal with adjacent and intersecting roads . In graph neural network , Neighboring nodes pass messages to each other . While maintaining this structure , The researchers applied a local bias , Nodes will be easier to rely on neighboring nodes ( This requires only one messaging step ). These mechanisms enable the graph neural network to make more efficient use of the connectivity structure of the road network . Experiments show that , Extending the scope of consideration to adjacent roads that do not belong to the main road can improve the prediction ability . for example , Consider the impact of traffic congestion on the main road . By crossing multiple intersections , The model can predict the delay at the turning 、 Delay caused by merging , And the travel time of stop and go traffic conditions . The generalization ability of graph neural network in combinatorial space makes the modeling technology of this research have powerful ability . The length and complexity of each super section may vary ( From a simple two-stage path to a longer path with hundreds of nodes ), But they can all be processed using the same graph neural network model .
from Basic research to production level machine learning model In academic research , Production level machine learning systems have a huge challenge that is often overlooked , That is, the same model will have huge differences in multiple training runs . Although in many academic studies , Subtle differences in training quality can be simply used as poor Initialization is discarded , But the subtle inconsistencies of millions of users add up to have a huge impact . therefore , When the model is put into production , Figure the robustness of neural network to this change in training has become the top priority . Researchers found that , Fig. the neural network is particularly sensitive to changes in the training process , The reason for this instability is that there are great differences between the graph structures used in training . A single batch diagram can range from two node plots to 100 The larger picture above the node . However , After trial and error , Researchers have adopted a new reinforcement learning technique in a supervised setting , Solved the above problems . In the process of training machine learning system , The learning rate of the system determines its own understanding of new information 「 Plasticity 」.
Over time , Researchers often reduce the learning rate of models , This is because there is a trade-off between learning something new and forgetting the important features that have been learned , Just like the growth process of human beings from children to adults . therefore , After a pre-defined training phase , The researchers first used an exponential decay learning rate scheme to stabilize the parameters . Besides , The researchers also explored and analyzed the model integration technology that has been proved effective in previous studies , So as to observe whether the model difference in training operation can be reduced . Last , Researchers found that , The most successful solution is to use MetaGradient To dynamically adjust the learning rate during training , Thus, the system can effectively learn its own optimal learning rate plan . By automatically adjusting the learning rate during training , This model not only achieves higher quality than before , But also learned to automatically reduce the learning rate . Finally, a more stable result is achieved , The new architecture can be applied to production . Model generalization through custom loss function Although the ultimate goal of the modeling system is to reduce the error in travel estimation , But the researchers found that , Using multiple loss functions ( Appropriate weighting ) The linear combination of has greatly improved the generalization ability of the model . To be specific , The researchers use the regularization factor of the model weight 、 Global traversal time L_2 and L_1 Loss 、 And for each node in the graph Huber And negative log likelihood (negative-log likelihood, NLL) Loss , Set a multiple loss target . By combining these losses , Researchers can guide the model and avoid over fitting the training data set . Although there is no change in the quality measurement of the training process , But the improvements that occur in training are more directly translated into setting aside (held-out) In test sets and end-to-end experiments . at present , Researchers are exploring , Under the guidance of reducing the travel estimation error ,MetaGradient Whether the technique can also be used to change the composition of the multi-component loss function in the training process . This research is supported by previous successes in reinforcement learning MetaGradient Inspired by the , And early experiments also showed good results .
边栏推荐
- Debug debugging cmake code under clion, including debugging process under ROS environment
- Map the world according to the data of each country (take the global epidemic as an example)
- Mathematical knowledge - matrix - matrix / vector derivation
- vm虛擬機中使用NAT模式特別說明
- "Three.js" auxiliary coordinate axis
- (p36-p39) right value and right value reference, role and use of right value reference, derivation of undetermined reference type, and transfer of right value reference
- OpenMP task 原理與實例
- FPGA implementation of right and left flipping of 720p image
- Compiling principle on computer -- functional drawing language (I)
- Clarify the division of IPv4 addresses
猜你喜欢

Record the treading pit of grain Mall (I)

FPGA to flip video up and down (SRAM is61wv102416bll)

MATLAB image processing - cosine noise removal in image (with code)

Convolutional neural network CNN based cat dog battle picture classification (tf2.1 py3.6)

(P27-P32)可调用对象、可调用对象包装器、可调用对象绑定器

超全MES系统知识普及,必读此文
![Easyexcel exports excel tables to the browser, and exports excel through postman test [introductory case]](/img/ca/0e2bd54a842a393231ec6db5ab02c2.png)
Easyexcel exports excel tables to the browser, and exports excel through postman test [introductory case]

(P25-P26)基于非范围的for循环、基于范围的for循环需要注意的3个细节

Pytorch profiler with tensorboard.

Map the world according to the data of each country (take the global epidemic as an example)
随机推荐
APS软件有哪些排程规则?有何异常处理方案?
Cmake can't find the solution of sophus
Record the treading pit of grain Mall (I)
离散 第一章
(P14)overrid关键字的使用
目前MES应用很多,为什么APS排程系统很少,原因何在?
visual studio2019的asp.net项目添加日志功能
Principle and example of OpenMP task
Summary of 3D point cloud construction plane method
Leetcode notes: Weekly contest 280
vm虛擬機中使用NAT模式特別說明
企业上线MES软件的费用真的很贵?
Literature reading: raise a child in large language model: rewards effective and generalizable fine tuning
Discrete chapter I
MATLAB image processing - Otsu threshold segmentation (with code)
JSP technology
企业为什么要实施MES?具体操作流程有哪些?
Leetcode notes: Weekly contest 275
2.2 linked list - Design linked list (leetcode 707)
In depth learning, the parameter quantity (param) in the network is calculated. The appendix contains links to floating point computations (flops).