当前位置:网站首页>ETCD数据库源码分析——etcdserver bootstrap初始化存储
ETCD数据库源码分析——etcdserver bootstrap初始化存储
2022-07-06 04:23:00 【肥叔菌】
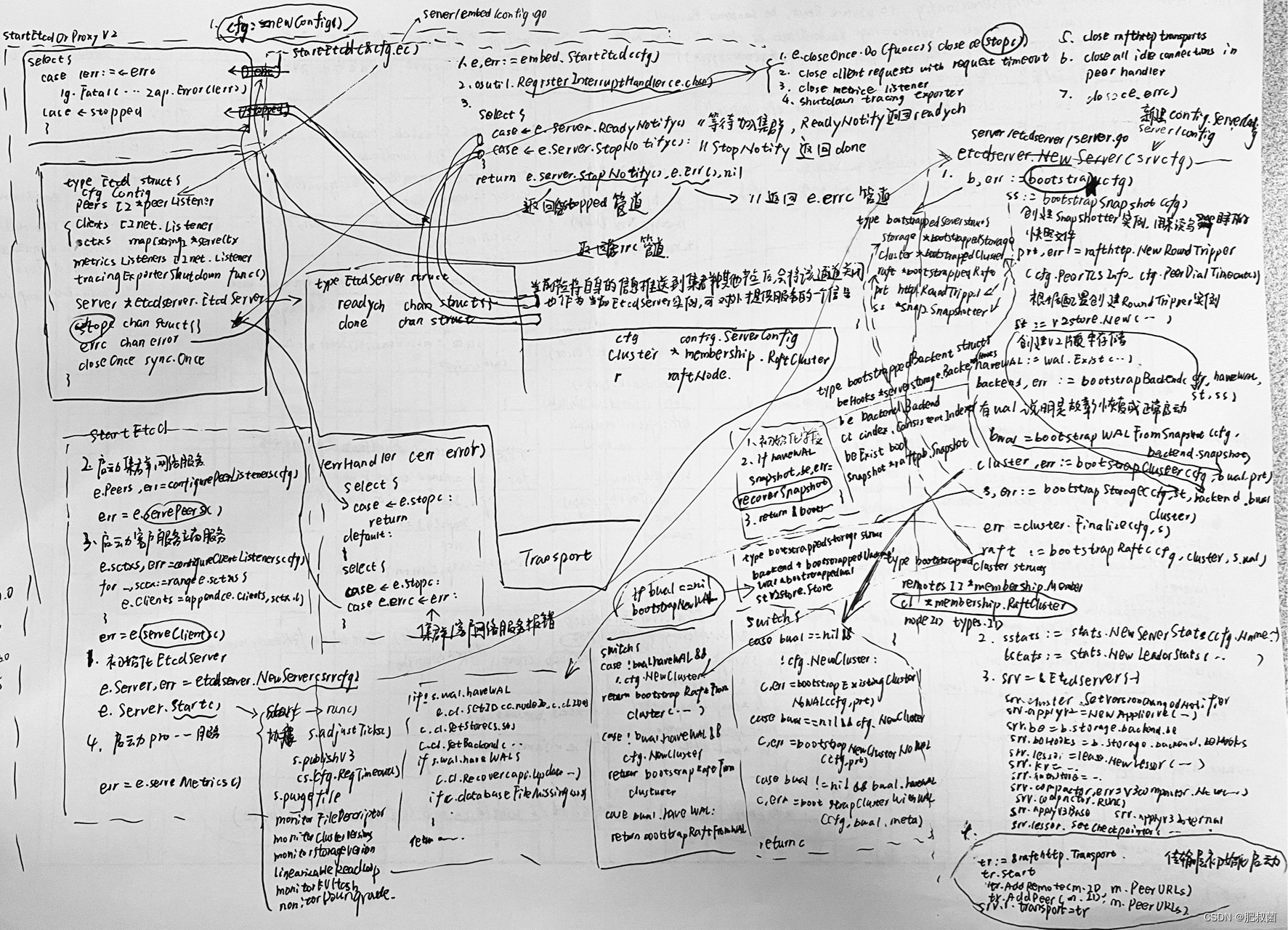
etcdserver.NewServer函数第一步就是调用bootstrap函数(定义在server/etcdserver/bootstrap.go文件中),其输入参数是config.ServerConfig,输出参数是bootstrappedServer,其主要作用是对存储Storage、集群信息Cluster和一致性模块信息Raft进行初始化和恢复。etcd 3.6.0和之前版本不同是将需要恢复的模块都集中到bootstrappedServer结构体中,以简化代码逻辑。
bootstrapSnapshot
func bootstrap(cfg config.ServerConfig) (b *bootstrappedServer, err error) {
// 每个etcd节点都会将其数据保存到"节点名称.etcd/member"目录下。这里会先检测该目录是否存在,如果不存在就创建该目录
if terr := fileutil.TouchDirAll(cfg.Logger, cfg.DataDir); terr != nil {
return nil, fmt.Errorf("cannot access data directory: %v", terr) }
if terr := fileutil.TouchDirAll(cfg.Logger, cfg.MemberDir()); terr != nil {
return nil, fmt.Errorf("cannot access member directory: %v", terr) }
// 删除tmp快照,创建snapshotter
ss := bootstrapSnapshot(cfg)
bootstrapSnapshot函数最主要的功能就是创建snapshotter。这里解释一下什么是snapshotter?随着节点的运行,会处理客户端和集群中其他节点发来的大量请求,相应的WAL日志会不断增加,会产生大量的WAL日志文件。当节点宕机之后,如果要恢复其状态,则需要从头读取全部的WAL日志文件,这样显然是不可能的。etcd为此会定期创建快照并将其保存到本地磁盘中(和redis的持久化RDB内存快照原理一致),在恢复节点状态时会先加载快照文件,使用该快照数据将节点恢复到对应的状态,之后从快照数据之后的相应位置开始读取WAL日志文件,最终将节点恢复到正确的状态。etcd将快照功能独立到snap模块中,snapshotter就是snapshot模块的核心结构体,这里首先初始化该结构体,从恢复逻辑上来看是正常的。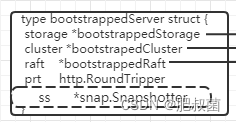
bootstrapSnapshot函数首先判定数据目录下有snap目录,然后删除带有tmp前缀的快照文件,最终调用snap包中的New函数初始化snapshotter实例。
func bootstrapSnapshot(cfg config.ServerConfig) *snap.Snapshotter {
if err := fileutil.TouchDirAll(cfg.Logger, cfg.SnapDir()); err != nil {
cfg.Logger.Fatal("failed to create snapshot directory",zap.String("path", cfg.SnapDir()),zap.Error(err), ) }
if err := fileutil.RemoveMatchFile(cfg.Logger, cfg.SnapDir(), func(fileName string) bool {
return strings.HasPrefix(fileName, "tmp") }); err != nil {
cfg.Logger.Error("failed to remove temp file(s) in snapshot directory",zap.String("path", cfg.SnapDir()),zap.Error(err),)
}
return snap.New(cfg.Logger, cfg.SnapDir()) // 创建snaoshotter实例,用来读写snap目录下的快照文件
}
根据配置创建RoundTripper实例,RoundTripper主要负责实现网络请求等功能。
prt, err := rafthttp.NewRoundTripper(cfg.PeerTLSInfo, cfg.PeerDialTimeout())
if err != nil {
return nil, err }
bootstrapBackend
创建v2版本存储和检测wal目录下是否存在WAL日志文件、snaoshotter实例都要作为bootstrapBackend函数的形参。
haveWAL := wal.Exist(cfg.WALDir()) // 检测wal目录下是否存在WAL日志文件
st := v2store.New(StoreClusterPrefix, StoreKeysPrefix) // 创建v2版本存储,这里指定了StoreClusterPrefix和StoreKeysPrefix两个只读目录,这两个常量值分别是"/0"和"/1"
backend, err := bootstrapBackend(cfg, haveWAL, st, ss)
if err != nil {
return nil, err }
首先我们需要知道这里的需要初始化的Backend其实就是Backend接口的实例,根据v3版本存储的设计,其底层的存储是可以切换的。因此这里我们就是需要初始化Backend,恢复存储。因此bootstrapBackend首先就是先判断是否存在v3存储的数据库文件。然后就是最重要的环节先加载快照文件,使用该快照数据将节点存储恢复到快照状态,这就是recoverSnapshot函数所作的事情;如果没有wal也就不需要恢复了,也就是该节点是新建立的。
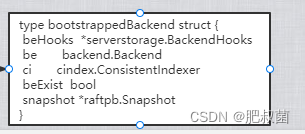
func bootstrapBackend(cfg config.ServerConfig, haveWAL bool, st v2store.Store, ss *snap.Snapshotter) (backend *bootstrappedBackend, err error) {
beExist := fileutil.Exist(cfg.BackendPath()) // 检测BoltDB数据库文件是否存在
ci := cindex.NewConsistentIndex(nil)
beHooks := serverstorage.NewBackendHooks(cfg.Logger, ci)
be := serverstorage.OpenBackend(cfg, beHooks) // 在该函数中会启动一个后台协程完成Backend实例的初始化
defer func() {
if err != nil && be != nil {
be.Close() } }()
ci.SetBackend(be)
schema.CreateMetaBucket(be.BatchTx())
if cfg.ExperimentalBootstrapDefragThresholdMegabytes != 0 {
err = maybeDefragBackend(cfg, be)
if err != nil {
return nil, err }
}
cfg.Logger.Debug("restore consistentIndex", zap.Uint64("index", ci.ConsistentIndex()))
// TODO(serathius): Implement schema setup in fresh storage
var ( snapshot *raftpb.Snapshot )
if haveWAL {
snapshot, be, err = recoverSnapshot(cfg, st, be, beExist, beHooks, ci, ss)
if err != nil {
return nil, err
}
}
if beExist {
err = schema.Validate(cfg.Logger, be.ReadTx())
if err != nil {
cfg.Logger.Error("Failed to validate schema", zap.Error(err))
return nil, err
}
}
return &bootstrappedBackend{
beHooks: beHooks, be: be, ci: ci, beExist: beExist, snapshot: snapshot, }, nil
}
我们可以看到recoverSnapshot函数需要将v2存储st和v3存储be传入函数,以及snapshotter ss用于获取磁盘上的快照文件。我们知道每次对存储打快照,相应的我们会向WAL日志中添加snapType的日志记录,因此第一步我们肯定是要先找到这中类型的日志记录,这就是ValidSnapshotEntries函数所做的工作。这里代码逻辑描述了一种情况就是存在相应的快照文件,但没有相应的快照类型的日志记录,这种情况肯定是会出现的,所以这里我们需要根据我们取得的最新的snapType类型的日志获取到磁盘上相应的快照数据。除了直接删除了快照数据,否则不会存在有snapType类型的日志而获取不到对应快照的情况。这里注意用快照数据恢复v2存储的代码是st.Recovery(snapshot.Data),使用快照恢复v3存储的代码是serverstorage.RecoverSnapshotBackend(cfg, be, *snapshot, beExist, beHooks)。v2存储的恢复其实就是加载快照文件中的JSON数据。v3存储恢复会检测前面创建的Backend实例是否可用(即包含了快照数据所包含的全部Entry记录),如果可用则继续使用该Backend实例,如果不可用则根据快照的元数据查找可用的BoltDB数据文件,并创建新的Backend实例。
func recoverSnapshot(cfg config.ServerConfig, st v2store.Store, be backend.Backend, beExist bool, beHooks *serverstorage.BackendHooks, ci cindex.ConsistentIndexer, ss *snap.Snapshotter) (*raftpb.Snapshot, backend.Backend, error) {
// Find a snapshot to start/restart a raft node ValidSnapshotEntries返回给定目录中wal日志中的所有有效快照条目。如果快照条目的raft log index小于或等于最近提交的硬状态的raft log index,则快照条目有效。
walSnaps, err := wal.ValidSnapshotEntries(cfg.Logger, cfg.WALDir())
if err != nil {
return nil, be, err }
// snapshot files can be orphaned if etcd crashes after writing them but before writing the corresponding bwal log entries 如果etcd在写入快照文件后但在写入相应的bwal日志条目之前崩溃,则快照文件可以孤立orphaned
snapshot, err := ss.LoadNewestAvailable(walSnaps)
if err != nil && err != snap.ErrNoSnapshot {
return nil, be, err }
if snapshot != nil {
if err = st.Recovery(snapshot.Data); err != nil {
cfg.Logger.Panic("failed to recover from snapshot", zap.Error(err)) } // 使用快照数据恢复v2存储
if err = serverstorage.AssertNoV2StoreContent(cfg.Logger, st, cfg.V2Deprecation); err != nil {
cfg.Logger.Error("illegal v2store content", zap.Error(err))
return nil, be, err
}
cfg.Logger.Info("recovered v2 store from snapshot",zap.Uint64("snapshot-index", snapshot.Metadata.Index),zap.String("snapshot-size", humanize.Bytes(uint64(snapshot.Size()))),)
if be, err = serverstorage.RecoverSnapshotBackend(cfg, be, *snapshot, beExist, beHooks); err != nil {
cfg.Logger.Panic("failed to recover v3 backend from snapshot", zap.Error(err)) } // 使用快照恢复v3存储
// A snapshot db may have already been recovered, and the old db should have already been closed in this case, so we should set the backend again.
ci.SetBackend(be)
s1, s2 := be.Size(), be.SizeInUse()
cfg.Logger.Info("recovered v3 backend from snapshot",zap.Int64("backend-size-bytes", s1),zap.String("backend-size", humanize.Bytes(uint64(s1))),zap.Int64("backend-size-in-use-bytes", s2),zap.String("backend-size-in-use", humanize.Bytes(uint64(s2))),)
if beExist {
// TODO: remove kvindex != 0 checking when we do not expect users to upgrade etcd from pre-3.0 release.
kvindex := ci.ConsistentIndex()
if kvindex < snapshot.Metadata.Index {
if kvindex != 0 {
return nil, be, fmt.Errorf("database file (%v index %d) does not match with snapshot (index %d)", cfg.BackendPath(), kvindex, snapshot.Metadata.Index)}
cfg.Logger.Warn("consistent index was never saved",zap.Uint64("snapshot-index", snapshot.Metadata.Index),
)
}
}
} else {
cfg.Logger.Info("No snapshot found. Recovering WAL from scratch!") // 没有快照
}
return snapshot, be, nil
}
bootstrapWALFromSnapshot
这一步最主要的功能就是初始化bootstrappedWAL,如果没有wal则不需要初始化。
var ( bwal *bootstrappedWAL )
if haveWAL {
if err = fileutil.IsDirWriteable(cfg.WALDir()); err != nil {
return nil, fmt.Errorf("cannot write to WAL directory: %v", err)}
bwal = bootstrapWALFromSnapshot(cfg, backend.snapshot)
}

openWALFromSnapshot在给定的快照处读取WAL,并返回WAL、其最新的硬状态和集群ID,以及在WAL中给定快照位置之后出现的所有条目。快照必须已事先保存到WAL,否则此调用将引起恐慌。
func bootstrapWALFromSnapshot(cfg config.ServerConfig, snapshot *raftpb.Snapshot) *bootstrappedWAL {
wal, st, ents, snap, meta := openWALFromSnapshot(cfg, snapshot)
bwal := &bootstrappedWAL{
lg: cfg.Logger, w: wal, st: st,
ents: ents, snapshot: snap, meta: meta, haveWAL: true,
}
if cfg.ForceNewCluster {
// discard the previously uncommitted entries
bwal.ents = bwal.CommitedEntries()
entries := bwal.NewConfigChangeEntries()
// force commit config change entries
bwal.AppendAndCommitEntries(entries)
cfg.Logger.Info("forcing restart member",zap.String("cluster-id", meta.clusterID.String()),zap.String("local-member-id", meta.nodeID.String()),zap.Uint64("commit-index", bwal.st.Commit),
)
} else {
cfg.Logger.Info("restarting local member",zap.String("cluster-id", meta.clusterID.String()),zap.String("local-member-id", meta.nodeID.String()),zap.Uint64("commit-index", bwal.st.Commit),
)
}
return bwal
}
func openWALFromSnapshot(cfg config.ServerConfig, snapshot *raftpb.Snapshot) (*wal.WAL, *raftpb.HardState, []raftpb.Entry, *raftpb.Snapshot, *snapshotMetadata) {
var walsnap walpb.Snapshot
if snapshot != nil {
// 从快照数据raftpb.Snapshot中提取Index(raft log index)和任期
walsnap.Index, walsnap.Term = snapshot.Metadata.Index, snapshot.Metadata.Term
}
repaired := false
for {
w, err := wal.Open(cfg.Logger, cfg.WALDir(), walsnap) // 初始化WAL实例,并从walsnap
if err != nil {
cfg.Logger.Fatal("failed to open WAL", zap.Error(err)) }
if cfg.UnsafeNoFsync {
w.SetUnsafeNoFsync() }
wmetadata, st, ents, err := w.ReadAll()
if err != nil {
w.Close()
// we can only repair ErrUnexpectedEOF and we never repair twice.
if repaired || err != io.ErrUnexpectedEOF {
cfg.Logger.Fatal("failed to read WAL, cannot be repaired", zap.Error(err))
}
if !wal.Repair(cfg.Logger, cfg.WALDir()) {
cfg.Logger.Fatal("failed to repair WAL", zap.Error(err))
} else {
cfg.Logger.Info("repaired WAL", zap.Error(err))
repaired = true
}
continue
}
var metadata etcdserverpb.Metadata
pbutil.MustUnmarshal(&metadata, wmetadata)
id := types.ID(metadata.NodeID)
cid := types.ID(metadata.ClusterID)
meta := &snapshotMetadata{
clusterID: cid, nodeID: id}
return w, &st, ents, snapshot, meta
}
}
cluster, err := bootstrapCluster(cfg, bwal, prt)
if err != nil {
backend.Close()
return nil, err
}
s, err := bootstrapStorage(cfg, st, backend, bwal, cluster)
if err != nil {
backend.Close()
return nil, err
}
err = cluster.Finalize(cfg, s)
if err != nil {
backend.Close()
return nil, err
}
raft := bootstrapRaft(cfg, cluster, s.wal)
return &bootstrappedServer{
prt: prt,
ss: ss,
storage: s,
cluster: cluster,
raft: raft,
}, nil
}
bootstrappedServer.close
func NewServer(cfg config.ServerConfig) (srv *EtcdServer, err error) {
b, err := bootstrap(cfg)
if err != nil {
return nil, err }
defer func() {
if err != nil {
b.Close() } }()
sstats := stats.NewServerStats(cfg.Name, b.cluster.cl.String())
lstats := stats.NewLeaderStats(cfg.Logger, b.cluster.nodeID.String())
heartbeat := time.Duration(cfg.TickMs) * time.Millisecond
srv = &EtcdServer{
readych: make(chan struct{
}),Cfg: cfg,lgMu: new(sync.RWMutex),
lg: cfg.Logger,errorc: make(chan error, 1),v2store: b.storage.st,
snapshotter: b.ss,r: *b.raft.newRaftNode(b.ss, b.storage.wal.w, b.cluster.cl),
memberId: b.cluster.nodeID,attributes: membership.Attributes{
Name: cfg.Name, ClientURLs: cfg.ClientURLs.StringSlice()},
cluster: b.cluster.cl,stats: sstats,lstats: lstats,
SyncTicker: time.NewTicker(500 * time.Millisecond),peerRt: b.prt,
reqIDGen: idutil.NewGenerator(uint16(b.cluster.nodeID), time.Now()),
AccessController: &AccessController{
CORS: cfg.CORS, HostWhitelist: cfg.HostWhitelist},
consistIndex: b.storage.backend.ci,
firstCommitInTerm: notify.NewNotifier(),clusterVersionChanged: notify.NewNotifier(),
}
serverID.With(prometheus.Labels{
"server_id": b.cluster.nodeID.String()}).Set(1)
srv.cluster.SetVersionChangedNotifier(srv.clusterVersionChanged)
srv.applyV2 = NewApplierV2(cfg.Logger, srv.v2store, srv.cluster)
srv.be = b.storage.backend.be
srv.beHooks = b.storage.backend.beHooks
minTTL := time.Duration((3*cfg.ElectionTicks)/2) * heartbeat
// always recover lessor before kv. When we recover the mvcc.KV it will reattach keys to its leases. If we recover mvcc.KV first, it will attach the keys to the wrong lessor before it recovers.
srv.lessor = lease.NewLessor(srv.Logger(), srv.be, srv.cluster, lease.LessorConfig{
MinLeaseTTL: int64(math.Ceil(minTTL.Seconds())),
CheckpointInterval: cfg.LeaseCheckpointInterval,
CheckpointPersist: cfg.LeaseCheckpointPersist,
ExpiredLeasesRetryInterval: srv.Cfg.ReqTimeout(),
})
tp, err := auth.NewTokenProvider(cfg.Logger, cfg.AuthToken, func(index uint64) <-chan struct{
} {
return srv.applyWait.Wait(index)}, time.Duration(cfg.TokenTTL)*time.Second, )
if err != nil {
cfg.Logger.Warn("failed to create token provider", zap.Error(err))
return nil, err
}
mvccStoreConfig := mvcc.StoreConfig{
CompactionBatchLimit: cfg.CompactionBatchLimit,CompactionSleepInterval: cfg.CompactionSleepInterval,}
srv.kv = mvcc.New(srv.Logger(), srv.be, srv.lessor, mvccStoreConfig)
srv.authStore = auth.NewAuthStore(srv.Logger(), schema.NewAuthBackend(srv.Logger(), srv.be), tp, int(cfg.BcryptCost))
newSrv := srv // since srv == nil in defer if srv is returned as nil
defer func() {
// closing backend without first closing kv can cause
// resumed compactions to fail with closed tx errors
if err != nil {
newSrv.kv.Close() }
}()
if num := cfg.AutoCompactionRetention; num != 0 {
srv.compactor, err = v3compactor.New(cfg.Logger, cfg.AutoCompactionMode, num, srv.kv, srv)
if err != nil {
return nil, err }
srv.compactor.Run()
}
if err = srv.restoreAlarms(); err != nil {
return nil, err }
srv.uberApply = srv.NewUberApplier()
if srv.Cfg.EnableLeaseCheckpoint {
// setting checkpointer enables lease checkpoint feature.
srv.lessor.SetCheckpointer(func(ctx context.Context, cp *pb.LeaseCheckpointRequest) {
srv.raftRequestOnce(ctx, pb.InternalRaftRequest{
LeaseCheckpoint: cp}) })
}
// Set the hook after EtcdServer finishes the initialization to avoid
// the hook being called during the initialization process.
srv.be.SetTxPostLockInsideApplyHook(srv.getTxPostLockInsideApplyHook())
// TODO: move transport initialization near the definition of remote
tr := &rafthttp.Transport{
Logger: cfg.Logger,TLSInfo: cfg.PeerTLSInfo,DialTimeout: cfg.PeerDialTimeout(),
ID: b.cluster.nodeID,URLs: cfg.PeerURLs,ClusterID: b.cluster.cl.ID(),Raft: srv,
Snapshotter: b.ss,ServerStats: sstats,LeaderStats: lstats,ErrorC: srv.errorc,}
if err = tr.Start(); err != nil {
return nil, err }
// add all remotes into transport
for _, m := range b.cluster.remotes {
if m.ID != b.cluster.nodeID {
tr.AddRemote(m.ID, m.PeerURLs) } }
for _, m := range b.cluster.cl.Members() {
if m.ID != b.cluster.nodeID {
tr.AddPeer(m.ID, m.PeerURLs) } }
srv.r.transport = tr
return srv, nil
}
边栏推荐
- User datagram protocol UDP
- 2327. 知道秘密的人数(递推)
- 729. My schedule I (set or dynamic open point segment tree)
- 【leetcode】22. bracket-generating
- Lambda expression learning
- How many of the 10 most common examples of istio traffic management do you know?
- One question per day (Mathematics)
- 2/12 didn't learn anything
- During pycharm debugging, the view is read only and pause the process to use the command line appear on the console input
- Leetcode32 longest valid bracket (dynamic programming difficult problem)
猜你喜欢
绑定在游戏对象上的脚本的执行顺序
Certbot failed to update certificate solution
How many of the 10 most common examples of istio traffic management do you know?
![[Zhao Yuqiang] deploy kubernetes cluster with binary package](/img/45/6777fa919386e526dbb0d2c808a7f2.jpg)
[Zhao Yuqiang] deploy kubernetes cluster with binary package
电脑钉钉怎么调整声音

【leetcode】1189. Maximum number of "balloons"

Comprehensive ability evaluation system
10個 Istio 流量管理 最常用的例子,你知道幾個?
MySql數據庫root賬戶無法遠程登陸解决辦法
Stable Huawei micro certification, stable Huawei cloud database service practice
随机推荐
. Net interprocess communication
Several important classes in unity
[tomato assistant installation]
HotSpot VM
2/13 qaq~~ greed + binary prefix sum + number theory (find the greatest common factor of multiple numbers)
Overturn your cognition? The nature of get and post requests
P3033 [usaco11nov]cow steelchase g (similar to minimum path coverage)
2328. Number of incremental paths in the grid graph (memory search)
【leetcode】1189. Maximum number of "balloons"
Unity中几个重要类
CADD课程学习(7)-- 模拟靶点和小分子相互作用 (柔性对接 AutoDock)
Fedora/REHL 安装 semanage
绑定在游戏对象上的脚本的执行顺序
Yyds dry inventory automatic lighting system based on CC2530 (ZigBee)
In depth MySQL transactions, stored procedures and triggers
Slow SQL fetching and analysis of MySQL database
Cross domain and jsonp details
Stable Huawei micro certification, stable Huawei cloud database service practice
P2022 interesting numbers (binary & digit DP)
Yyds dry goods inventory hcie security Day11: preliminary study of firewall dual machine hot standby and vgmp concepts