当前位置:网站首页>Lab 8 file system
Lab 8 file system
2022-07-06 15:19:00 【Hu Da jinshengyu】
Lab 8 file system
The experiment purpose
By completing this experiment , I hope to achieve the following goals
- Understand the implementation of basic file system calls ;
- Learn about an index node based organization Simple FS Design and implementation of file system ;
- Understand the file system abstraction layer -VFS Design and implementation ;
Experimental content
Experiment 7 completed the synchronization and mutual exclusion experiment in the kernel . This experiment involves file system , Understand through analysis ucore The overall architecture design of the file system , Improve the operation of reading and writing files , Re implement the file system based execution program mechanism ( Namely rewrite do_execve), Thus, the functions of executing files stored on disk and reading and writing files can be completed .
practice
Requirements for experimental report :
- be based on markdown Format to complete , Text based
- Fill in the report required in each basic exercise
- After finishing the experiment , Please analyze ucore_lab Reference answers provided in , Please explain the difference between your implementation and the reference answer in the experiment report
- List the knowledge points you think are important in this experiment , And corresponding OS Knowledge points in principle , And briefly explain your meaning of the two , Relationship , Understanding of differences and other aspects ( It may also appear that the knowledge points in the experiment have no corresponding principle knowledge points )
- List what you think OS Principle is very important , But there is no corresponding knowledge point in the experiment
practice 0: Fill in the existing experiment
This experiment relies on experiments 1/2/3/4/5/6/7. Please take your experiment 1/2/3/4/5/6/7 Fill in the code in this experiment. There are “LAB1”/“LAB2”/“LAB3”/“LAB4”/“LAB5”/“LAB6”
/“LAB7” The corresponding part of the notes . And ensure that the compilation passes . Be careful : In order to execute correctly lab8 Test application for , It may be necessary to test the completed experiments 1/2/3/4/5/6/7 Code for further improvements .
Use meld The software will lab7 and lab8 Compare folders :
The following files need to be copied :
- proc.c
- default_pmm.c
- pmm.c
- swap_fifo.c
- vmm.c
- trap.c
- sche.c
- monitor.c
- check_sync.c
- kdebug.c
Other documents need not be modified , It can be used directly .
practice 1: Complete the implementation of file reading operation ( Need to code )
First, understand the processing flow of opening files , Then refer to the subsequent process analysis of file reading and writing operation in this experiment , Written in sfs_inode.c in sfs_io_nolock Read the implementation code of the data in the file .
Please give the design and implementation in the experimental report ”UNIX Of PIPE Mechanism “ Outline design scheme , Encourage to give detailed design scheme
UNIX file system
UNIX Four abstract concepts of file system are proposed : file (file)、 Catalog items (dentry)、 The index node (inode) And mounting points (mount point):
- file :UNIX The contents of the file can be understood as an ordered byte buffer, All files have a file name that is easy for the application to recognize call ( Also known as file pathname ). Typical file operations include reading 、 Write 、 Create and delete .
- Catalog items : The directory entry is not a directory ( Also known as file path ), It's part of the directory . stay UNIX The Chinese catalogue is regarded as a special Fixed file , The directory entry is part of the file path . For example, a file path name is “/test/testfile”, Then the included directory Items for : root directory “/”, Catalog “test” And documents “testfile”, These three are all directory entries . generally speaking , Directory entries contain directory entries Name ( Filename or directory name ) And the index node of the directory entry ( See the following description ) Location .
- The index node :UNIX The relevant metadata information of the file ( Such as access control permission 、 size 、 The owner 、 Creation time 、 Within data Let's wait for information ) Stored in a separate data structure , This structure is called an index node .
- Mounting points : stay UNIX in , The file system is installed in a specific file path location , This position is the installation point . be-all Installed file systems appear in the system as leaves in the root file system tree .
The above abstract concepts form UNIX Logical data structure of file system , And we need to design and implement a specific file system architecture The above information is mapped and stored on disk media , Thus, the disk layout of the specific file system ( That is, the physical organization of data on disk ) On Embody the above abstract concepts . For example, file metadata information is stored on the index node in the disk block . When the file is loaded into memory , The kernel needs to use index points in disk blocks to construct index nodes in memory .
ucore file system
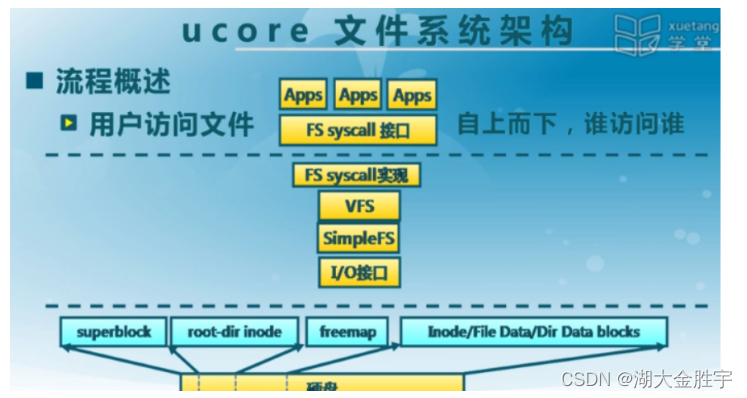
ucore Imitated UNIX File system design ,ucore The file system architecture of is mainly composed of four parts :
- Common file system access interface layer : This layer provides a standard access interface from user space to file system . This layer of access interface allows applications to obtain through a simple interface ucore Kernel file system services .
- File system abstraction layer : Provide a consistent interface up to the rest of the kernel ( File system related system call implementation module and other kernel function modules ) visit . Provide the same abstract function pointer list and data structure to shield the implementation details of different file systems .
- Simple FS File system layer : An example of a simple file system based on index . Up through various concrete functions to achieve the corresponding abstract functions proposed by the file system Abstract Layer . Downward access to peripheral interfaces
- Peripheral interface layer : Offer up device The access interface shields different hardware details . Downward implementation of interfaces for accessing various specific device drivers , such as disk Device interface / Serial port device interface / Keyboard device interface .
Compared with the above levels, we will briefly introduce the file system access processing process , Deepen the overall understanding of the file system .
Suppose the application operates on files ( open / establish / Delete / Reading and writing ), First of all, we need to provide The access interface provided by user space enters the file system , Then the file system abstraction layer forwards the access request to a specific file system system ( such as SFS file system ), Specific file system (Simple FS File system layer ) Convert the access request of the application to the disk Upper block Processing requests for , And through the peripheral interface layer to the disk drive routine to complete the specific disk operation . Write files in combination with user mode function write The whole execution process of , We can see clearly ucore Hierarchy and dependencies of file system architecture
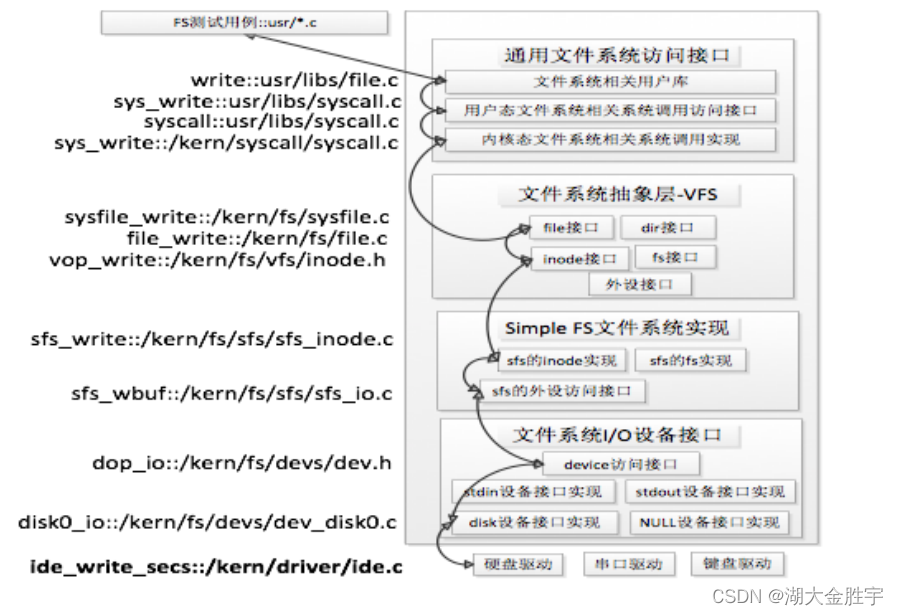
ucore Overall structure of file system
from ucore From different perspectives of the operating system ,ucore The file system architecture in contains four main types of data structures , They are :
- Superblock (SuperBlock), It mainly describes the global information of a specific file system from the global point of view of the file system . Its function range Circumference is the whole OS Space .
- The index node (inode): It mainly describes the various attributes and data of the file system from the perspective of a single file Set up . Its scope of action is the whole OS Space .
- Catalog items (dentry): It mainly describes a specific directory item in the file path from the perspective of the file path of the file system ( notes : A series of catalog items form a catalog / File path ). Its scope of action is the whole OS Space . about SFS for ,inode( have Body as struct sfs_disk_inode) Corresponding to the specific object on the physical disk ,dentry( Specific for struct sfs_disk_entry) Is a memory entity , Among them ino The member points to the corresponding inode number, Another member is file name( file name ).
- file (file), It mainly describes the file identification that a process needs to know when accessing files from the perspective of a process , File read and write The location of , Information such as document quotation . Its scope of action is a specific process .
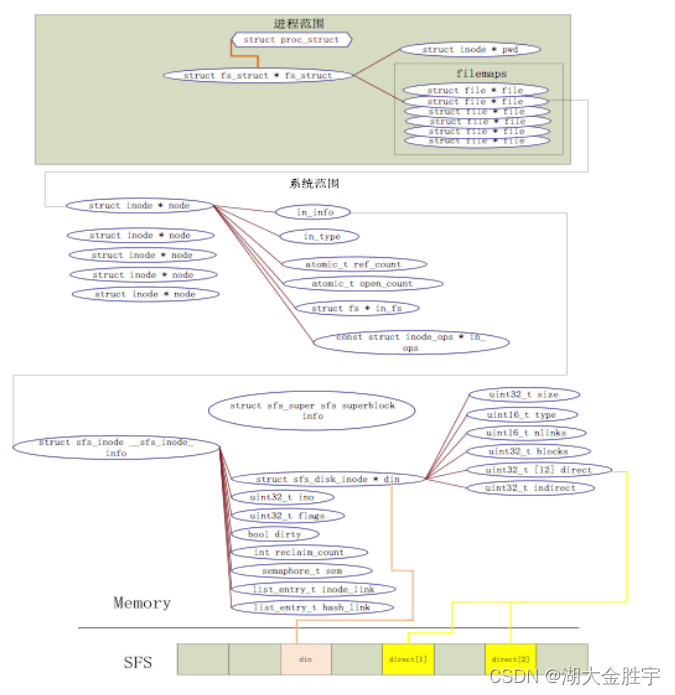
Important data structures
file File structure :
struct file {
enum {
FD_NONE, FD_INIT, FD_OPENED, FD_CLOSED,
} status; // Access the execution status of the file
bool readable; // Is the file readable
bool writable; // Is the document writable
int fd; // The file in filemap Index value in
off_t pos; // Access the current location of the file
struct inode *node; // The memory corresponding to this file inode The pointer
atomic_t open_count; // Number of times this file was opened
};
inode:inode data structure , It is an index node located in memory , Put the specific inode information of different file systems ( It's not even an inode ) Put it all together , It avoids the process from directly accessing the specific file system .
struct inode {
union {
// Different file systems are specific inode The information of union Domain
struct device __device_info; // Device file system memory inode Information
struct sfs_inode __sfs_inode_info; //SFS File system memory inode Information
} in_info;
enum {
inode_type_device_info = 0x1234,
inode_type_sfs_inode_info,
} in_type; // this inode File system type
atomic_t ref_count; // this inode Reference count of
atomic_t open_count; // Open this inode Number of corresponding files
struct fs *in_fs; // Abstract file system , Contains function pointers to access the file system
const struct inode_ops *in_ops; // In the abstract inode operation , Include access inode Function pointer of
};
Process flow of opening file
First assume that the file that the user process needs to open already exists on the hard disk . With user/sfs_filetest1.c For example , First, the user process will call in main The following statements in the function :
int fd1 = safe_open("/test/testfile", O_RDWR | O_TRUNC);
If ucore This file can be found normally , A file descriptor representing the file will be returned fd1, So in the next process of reading and writing files , Just use it directly fd1 Just represent .
Universal file system access interface
- In terms of file operation , The most basic correlation function is open、close、read、write. Before reading and writing a file , First of all use open The system calls to open it .
- open The first parameter of specifies the pathname of the file , Absolute pathnames can be used ; The second parameter specifies how to open , Can be set up by O_RDONLY、O_WRONLY\O_RDWR, Read only 、 Just write 、 Can read but write .
- After opening a file , You can use the file descriptor it returns fd Perform relevant operations on the file . After using a file after , And use it close The system call turns it off , The parameter is the file descriptor fd. So its file descriptor can be empty Come on , For other documents .
- The system call to read and write file contents is read and write.read The system call has three parameters : A file description specifying the operation operator , A specified storage address for reading data , The last one specifies how many bytes to read . stay C The method of calling the system call in the program is as follows :
count = read(filehandle, buffer, nbytes);
The system call will return the number of bytes actually read to count Variable . Under normal circumstances, this value is similar to nbytes equal , But sometimes it can be It will be smaller . for example , I hit the end of the file when reading the file , Thus ending this read operation in advance .
- If it is due to invalid parameters or wrong disk access , This makes the system call impossible , be count Be set to -1. and write The parameters of the function are exactly the same .
- For a catalog , The most common operation is to jump to a directory , The corresponding user library function here is chdir. Then you need to read The contents of the directory , That is, list the file or directory name in the directory , This is similar to reading files in processing , That is, it needs to pass the opendir Letter Count open directory , adopt readdir To get the file information in the directory , After reading, you need to pass closedir Function to close the directory . from In ucore Regard the directory as a special file , therefore opendir and closedir In fact, it is to call the file related open and close function . Only readdir You need to call a special system call to get the contents of the directory sys_getdirentry. And here There is no operation of writing directory . Adding content to a directory is actually creating files in this directory , You need to use the function to create the file .
SFS Processing flow of file system layer
In the second step ,vop_lookup The function is called sfs_lookup function .
The following analysis sfs_lookup function :
static int sfs_lookup(struct inode *node, char *path, struct inode **node_store) {
struct sfs_fs *sfs = fsop_info(vop_fs(node), sfs);
assert(*path != '\0' && *path != '/'); // With “/” For the separator , Decompose one by one from left to right path Get the corresponding of each subdirectory and the final file inode node .
vop_ref_inc(node);
struct sfs_inode *sin = vop_info(node, sfs_inode);
if (sin->din->type != SFS_TYPE_DIR) {
vop_ref_dec(node);
return -E_NOTDIR;
}
struct inode *subnode;
int ret = sfs_lookup_once(sfs, sin, path, &subnode, NULL); // Loop further calls sfs_lookup_once Looking to “test” Files in subdirectories “testfile1” The corresponding inode node .
vop_ref_dec(node);
if (ret != 0) {
return ret;
}
*node_store = subnode; // When it cannot be decomposed path after , It means finding the corresponding inode node , You can return smoothly .
return 0;
}
sfs_lookup The function starts with “/” For the separator , Decompose one by one from left to right path Get the corresponding of each subdirectory and the final file inode node . Then the loop calls further sfs_lookup_once Looking to “test” Files in subdirectories “testfile1” The corresponding inode node . Finally, when it cannot be decomposed path after , It means finding the corresponding inode node , You can return smoothly .
complete sfs_io_nolock function
sfs_io_nolock Function is mainly used to read a piece of data from disk into memory or write a piece of data from memory to disk .
This function performs a series of edge checks , Check whether the access is out of bounds 、 Is it legal . After that, I will read / Write operations are unified using function pointers , Unified into operations for the whole block . Then complete the reading that does not fall on the whole data block / Write operations , And reading and writing on the whole data block . Here is the code for this function ( Including supplementary code , There will be more detailed notes )
static int
sfs_io_nolock(struct sfs_fs *sfs, struct sfs_inode *sin, void *buf, off_t offset, size_t *alenp, bool write)
{
// Create a disk index node to point to the memory index node to access the file
struct sfs_disk_inode *din = sin->din;
assert(din->type != SFS_TYPE_DIR);
// Determine the end position of the read
off_t endpos = offset + *alenp, blkoff;
*alenp = 0;
// Carry out a series of edges , Avoid illegal access
if (offset < 0 || offset >= SFS_MAX_FILE_SIZE || offset > endpos) {
return -E_INVAL;
}
if (offset == endpos) {
return 0;
}
if (endpos > SFS_MAX_FILE_SIZE) {
endpos = SFS_MAX_FILE_SIZE;
}
if (!write) {
if (offset >= din->size) {
return 0;
}
if (endpos > din->size) {
endpos = din->size;
}
}
int (*sfs_buf_op)(struct sfs_fs *sfs, void *buf, size_t len, uint32_t blkno, off_t offset);
int (*sfs_block_op)(struct sfs_fs *sfs, void *buf, uint32_t blkno, uint32_t nblks);
// Determine whether it is a read operation or a write operation , And determine the corresponding system function
if (write) {
sfs_buf_op = sfs_wbuf, sfs_block_op = sfs_wblock;
}
else {
sfs_buf_op = sfs_rbuf, sfs_block_op = sfs_rblock;
}
//
int ret = 0;
size_t size, alen = 0;
uint32_t ino;
uint32_t blkno = offset / SFS_BLKSIZE; // The NO. of Rd/Wr begin block
uint32_t nblks = endpos / SFS_BLKSIZE - blkno; // The size of Rd/Wr blocks
//-------------------------- The supplementary part ----------------------------------------------
// Judge whether the first block in the data block of the area to be operated is completely covered ,
// If not , You need to call a function that reads or writes a non whole block of data to complete the corresponding operation
if ((blkoff = offset % SFS_BLKSIZE) != 0) {
// The offset of the operation in the first data block
blkoff = offset % SFS_BLKSIZE;
// Length of data in the first data block
size = (nblks != 0) ? (SFS_BLKSIZE - blkoff) : (endpos - offset);
// Get the number of these data blocks corresponding to the data blocks on the disk
if ((ret = sfs_bmap_load_nolock(sfs, sin, blkno, &ino)) != 0) {
goto out;
}
// Read or write data blocks
if ((ret = sfs_buf_op(sfs, buf, size, ino, blkoff)) != 0) {
goto out;
}
// The length of data that has been read and written
alen += size;
if (nblks == 0) {
goto out;
}
buf += size, blkno++; nblks--;
}
Read the data in the middle part , Divide it into size size The block , Then operate one by one , Until completion
size = SFS_BLKSIZE;
while (nblks != 0)
{
if ((ret = sfs_bmap_load_nolock(sfs, sin, blkno, &ino)) != 0) {
goto out;
}
// Read or write data blocks
if ((ret = sfs_block_op(sfs, buf, ino, 1)) != 0) {
goto out;
}
// Update the corresponding variable
alen += size, buf += size, blkno++, nblks--;
}
// The last page , Misalignment may occur :
if ((size = endpos % SFS_BLKSIZE) != 0)
{
// Get the number of the data block corresponding to the data block on the disk
if ((ret = sfs_bmap_load_nolock(sfs, sin, blkno, &ino)) != 0) {
goto out;
}
// Perform non block read or write operations
if ((ret = sfs_buf_op(sfs, buf, size, ino, 0)) != 0) {
goto out;
}
alen += size;
}
out:
*alenp = alen;
if (offset + alen > sin->din->size) {
sin->din->size = offset + alen;
sin->dirty = 1;
}
return ret;
}
In general, it is divided into three parts to read the file , Each time through sfs_bmap_load_nolock Function to get the file index number , And then call sfs_buf_op perhaps sfs_block_op Complete the actual file reading and writing operation .
Question answering
- Please give the design and implementation in the experimental report ”UNIX Of PIPE Mechanism “ Outline design scheme , Encourage to give detailed design scheme
Pipes can be used for communication between processes with kinship , A pipeline is a buffer managed by the kernel , It's equivalent to a note we put in memory . One end of the pipe is connected to the output of a process . This process will put information into the pipeline . Connect the other end of the input pipeline , This process takes out the information put into the pipeline . A buffer does not need to be large , It is designed as a ring data structure , So that the pipe can be recycled . When there is no information in the pipeline , The process reading from the pipeline will wait , Until the process at the other end puts information . When the pipeline is full of information , The process trying to put information will wait , Until the process at the other end takes out the information . When both processes end , The pipe also disappears automatically .
stay Linux in , The implementation of pipeline does not use special data structure , But with the help of the file system file The structure and VFS The index node of inode. By putting two file The structure points to the same temporary VFS The index node , And this VFS The index node points to a physical page .
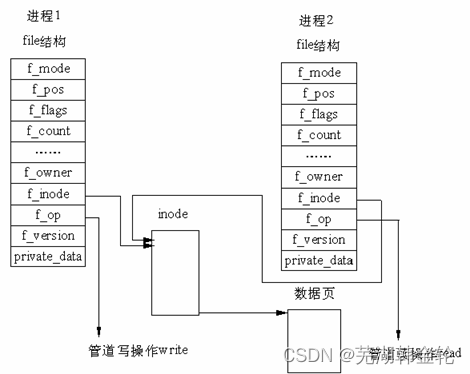
stay Linux in , Pipeline is a very frequently used communication mechanism . essentially , A pipe is also a file , But it is also similar to general literature Pieces are different , Pipeline can overcome two problems of using files for communication , Specific performance: :
- Limit the size of the pipe . actually , A pipe is a fixed size buffer . stay Linux in , The size of the buffer is 1 page , namely 4K byte , So that its size does not grow as unchecked as a file . Using a single fixed buffer can also cause problems , For example The pipeline may become full when writing , When that happens , The subsequent of the pipeline write() Calls will be blocked by default , Wait for some data Read , So as to make enough space for write() Call write .
- The read process may also work faster than the write process . When all current process data has been read , The pipe becomes empty . When this happens when , A subsequent read() Calls will be blocked by default , Wait for some data to be written , That's settled read() Call the return file The end question .
Realization
A pipeline can be seen as a buffer managed by the kernel , One end connects to the process A Output , The other end connects to the process B The input of . process A Meeting Put information into the pipeline , And the process B Will take out the information put into the pipeline . When there is no information in the pipeline , process B Will wait for , Until the process A Put information . When the pipeline is full of information , process A Will wait for , Until the process B Take out the information . When both processes are over , The pipe also disappears automatically . The pipeline is based on fork Mechanism to establish , So that two processes can connect to the same PIPE On
Based on this , We can imitate UNIX, To design a PIPE Mechanism :
- Reserve a certain area on the disk for PIPE Buffer of mechanism , Or create a file as PIPE Mechanism Services
- When initializing system files PIPE Also initialize and create the corresponding inode In memory for PIPE Leave an area , In order to complete the cache efficiently
- When two processes want to establish a pipeline , Then you can add variables to the process control block of these two processes to record this attribute of the process
- When one of the processes wants to write data , Information through the process control block , You can set it to the temporary file first PIPE Make changes
- When a user needs to read data , You can complete the processing of temporary files through the information of the process control block PIPE The read
- Add some related system calls to support the above operations
A pipeline can be seen as a buffer managed by the kernel , One end connects to the process A Output , The other end connects to the process B The input of . process A Will put information into the pipeline , And the process B Will take out the information put into the pipeline . When there is no information in the pipeline , process B Will wait for , Until the process A Put information . When the pipeline is full of information , process A Will wait for , Until the process B Take out the information . When both processes are over , The pipe also disappears automatically . The pipeline is based on fork Mechanism to establish , So that two processes can connect to the same PIPE On .
Based on this , We can imitate UNIX, To design a PIPE Mechanism .
- First, we need to reserve a certain area on the disk for PIPE Buffer of mechanism , Or create a file as PIPE Mechanism Services
- When initializing system files PIPE Also initialize and create the corresponding inode
- In memory for PIPE Leave an area , In order to complete the cache efficiently
- When two processes want to establish a pipeline , Then you can add variables to the process control block of these two processes to record this attribute of the process
- When one of the processes wants to write data , Information through the process control block , You can set it to the temporary file first PIPE Make changes
- When a user needs to read data , You can complete the processing of temporary files through the information of the process control block PIPE The read
- Add some related system calls to support the above operations
thus ,PIPE The general framework of has been completed .
practice 2: Complete the implementation of the execution program mechanism based on the file system ( Need to code )
rewrite proc.c Medium load_icode Functions and other related functions , Implement file system based execution program mechanism . perform :make qemu. If you can see sh User program execution interface , Basically succeeded . If in sh The user interface can execute ”ls”,”hello” Wait for others to be placed sfs Other executors in the file system , It can be considered that this experiment is basically successful .
Please give the design and Implementation Based on ”UNIX Hard link and soft link mechanism “ Outline design scheme , Encourage to give detailed design scheme
modify alloc_proc
stay proc.c in , According to the comments, we need to initialize fs Process control structure in , That is to say alloc_proc In the function, we need to do a Modify the , add a sentence proc->filesp = NULL; To complete initialization .
static struct proc_struct *
alloc_proc(void) {
struct proc_struct *proc = kmalloc(sizeof(struct proc_struct));
if (proc != NULL) {
// Lab7 Content
// ...
//LAB8:EXERCISE2 YOUR CODE HINT:need add some code to init fs in proc_struct, ...
// LAB8 Add one filesp Initialization of the pointer
proc->filesp = NULL;
}
return proc;
}
Why should we do this , Because we said before , A file needs to be in VFS In order to be executed .
Realization load_icode function
load_icode The main task of the function is to create a user environment for the user process to run normally . The basic flow :
- call mm_create Function to apply for the memory management data structure of the process mm Required memory space , Also on mm To initialize ;
- call setup_pgdir To apply for a page size memory space required for a page directory table , And describe ucore Kernel page table of kernel virtual space mapping (boot_pgdir To refer to ) Copy the contents of this new directory table , Finally let mm->pgdir Point to the table of contents on this page , This is the new page directory table of the process , And can correctly map the kernel virtual space ;
- Load the files in the disk into memory , This... Is resolved according to the starting position of the application execution code ELF Format execution program , And according to ELF The format of the execution program describes the various paragraphs ( Code segment 、 Data segment 、BSS Duan et al ) The starting position and size of the corresponding vma structure , And put vma Insert into mm In structure , Thus, it shows the legal user state virtual address space of user process ;
- Call to allocate physical memory space according to the size of each segment of the executing program , The virtual address is determined according to the starting position of each segment of the execution program , And establish the mapping relationship between physical address and virtual address in the page table , Then copy the contents of each segment of the execution program to the corresponding kernel virtual address
- You need to set the user stack for the user process , And handle the parameters passed in the user stack
- First clear the interrupt frame of the process , Then reset the interrupt frame of the process , Make the interrupt return instruction “iret” after , To be able to make CPU Go to the user state privilege level , And return to the user state memory space , Code snippets using user mode 、 Segments and stacks , And can jump to the first instruction execution of the user process , And ensure that the interrupt can be responded to in the user state ;
It can be roughly divided into the following parts :
Load the file into memory and execute , According to the notes, there are seven steps :
- Create a memory manager
- Create a page directory
- Load the file into memory segment by segment , Here, you should pay attention to setting the mapping between virtual address and physical address
- Establish the corresponding virtual memory mapping table
- Establish and initialize the user stack
- Handle the parameters passed in from the user stack
- The last key step is to set the interrupt frame of the user process
The complete code is as follows :
// Read the executable file from the disk , And loaded into memory , Complete the initialization of memory space
static int load_icode(int fd, int argc, char **kargv)
{
// Determine whether the memory management of the current process has been released , We need to require that the current memory manager is empty
if (current->mm != NULL)
{
panic("load_icode: current->mm must be empty.\n");
}
int ret = -E_NO_MEM;
//1. call mm_create Function to apply for the memory management data structure of the process mm Required memory space , Also on mm To initialize
struct mm_struct *mm;
if ((mm = mm_create()) == NULL) {
goto bad_mm;
}
//2. Apply for space for new directory items and complete the setting of directory items
if (setup_pgdir(mm) != 0) {
goto bad_pgdir_cleanup_mm;
}
// Create page table
struct Page *page;
//3. Load program from file from disk to memory
struct elfhdr __elf, *elf = &__elf;
//3.1 call load_icode_read Function read ELF file
if ((ret = load_icode_read(fd, elf, sizeof(struct elfhdr), 0)) != 0)
{
goto bad_elf_cleanup_pgdir;
}
// Judge whether this file is legal
if (elf->e_magic != ELF_MAGIC) {
ret = -E_INVAL_ELF;
goto bad_elf_cleanup_pgdir;
}
struct proghdr __ph, *ph = &__ph;
uint32_t i;
uint32_t vm_flags, perm;
//e_phnum Represents the number of program segment entry addresses
for (i = 0; i < elf->e_phnum; ++i)
{
//3.2 Loop through the header of each segment of the program
if ((ret = load_icode_read(fd, ph, sizeof(struct proghdr), elf->e_phoff + sizeof(struct proghdr) * i)) != 0)
{
goto bad_elf_cleanup_pgdir;
}
if (ph->p_type != ELF_PT_LOAD) {
continue ;
}
if (ph->p_filesz > ph->p_memsz) {
ret = -E_INVAL_ELF;
goto bad_cleanup_mmap;
}
if (ph->p_filesz == 0) {
continue ;
}
//3.3 Establish corresponding VMA
vm_flags = 0, perm = PTE_U; // Establish the mapping between virtual address and physical address
// according to ELF Information in the file , Set the permissions of each section
if (ph->p_flags & ELF_PF_X) vm_flags |= VM_EXEC;
if (ph->p_flags & ELF_PF_W) vm_flags |= VM_WRITE;
if (ph->p_flags & ELF_PF_R) vm_flags |= VM_READ;
if (vm_flags & VM_WRITE) perm |= PTE_W;
// The virtual memory address is set to legal
if ((ret = mm_map(mm, ph->p_va, ph->p_memsz, vm_flags, NULL)) != 0) {
goto bad_cleanup_mmap;
}
//3.4 Allocate pages for data segments, code segments, etc
off_t offset = ph->p_offset;
size_t off, size;
// Calculate the starting address of data segment and code segment
uintptr_t start = ph->p_va, end, la = ROUNDDOWN(start, PGSIZE);
ret = -E_NO_MEM;
// Calculate the end address of data segment and code segment
end = ph->p_va + ph->p_filesz;
while (start < end)
{
// by TEXT/DATA Allocate physical memory space page by page
if ((page = pgdir_alloc_page(mm->pgdir, la, perm)) == NULL)
{
goto bad_cleanup_mmap;
}
off = start - la, size = PGSIZE - off, la += PGSIZE;
if (end < la) {
size -= la - end;
}
// Put... On the disk TEXT/DATA The segment is read into the allocated memory space
// Each read size The size of the block , Until you finish reading
if ((ret = load_icode_read(fd, page2kva(page) + off, size, offset)) != 0)
{
goto bad_cleanup_mmap;
}
start += size, offset += size;
}
//3.5 by BBS Section distribution page
// Calculation BBS End address of
end = ph->p_va + ph->p_memsz;
if (start < la) {
if (start == end) {
continue ;
}
off = start + PGSIZE - la, size = PGSIZE - off;
if (end < la)
{
size -= la - end;
}
memset(page2kva(page) + off, 0, size);
start += size;
assert((end < la && start == end) || (end >= la && start == la));
}
// If you don't give BSS Segment allocate enough pages , Further allocation
while (start < end) {
if ((page = pgdir_alloc_page(mm->pgdir, la, perm)) == NULL) {
goto bad_cleanup_mmap;
}
off = start - la, size = PGSIZE - off, la += PGSIZE;
if (end < la) {
size -= la - end;
}
// Reset and initialize the allocated space
memset(page2kva(page) + off, 0, size);
start += size;
}
}
sysfile_close(fd);// Close file , End of loader
// 4. Set user stack
vm_flags = VM_READ | VM_WRITE | VM_STACK; // Set the permissions of the user stack
// Set the virtual memory area where the user stack is located to legal
if ((ret = mm_map(mm, USTACKTOP - USTACKSIZE, USTACKSIZE, vm_flags, NULL)) != 0) {
goto bad_cleanup_mmap;
}
assert(pgdir_alloc_page(mm->pgdir, USTACKTOP-PGSIZE , PTE_USER) != NULL);
assert(pgdir_alloc_page(mm->pgdir, USTACKTOP-2*PGSIZE , PTE_USER) != NULL);
assert(pgdir_alloc_page(mm->pgdir, USTACKTOP-3*PGSIZE , PTE_USER) != NULL);
assert(pgdir_alloc_page(mm->pgdir, USTACKTOP-4*PGSIZE , PTE_USER) != NULL);
// Set the mm、cr3 etc.
mm_count_inc(mm);
current->mm = mm;
current->cr3 = PADDR(mm->pgdir);
lcr3(PADDR(mm->pgdir));
// Set for user space trapeframe
uint32_t argv_size=0, i;
// Determine how much space the parameters passed to the application should occupy
uint32_t total_len = 0;
for (i = 0; i < argc; ++i)
{
total_len += strnlen(kargv[i], EXEC_MAX_ARG_LEN) + 1;
// +1 Represents the end of a string '\0'
}
// User stack top minus the total length of all parameters , And 4 Byte alignment find the position of the stack where the string parameters are actually stored
char *arg_str = (USTACKTOP - total_len) & 0xfffffffc;
// Store pointers to string parameters
int32_t *arg_ptr = (int32_t *)arg_str - argc;
// According to the space that the parameter needs to occupy on the stack , The position of the top of the stack after passing the parameter
int32_t *stacktop = arg_ptr - 1;
*stacktop = argc;
for (i = 0; i < argc; ++i)
{
uint32_t arg_len = strnlen(kargv[i], EXEC_MAX_ARG_LEN);
strncpy(arg_str, kargv[i], arg_len);
*arg_ptr = arg_str;
arg_str += arg_len + 1;
++arg_ptr;
}
//6. Set the interrupt frame of the process
// Set up tf Setting of corresponding variables , Include :tf_cs、tf_ds tf_es、tf_ss tf_esp, tf_eip, tf_eflags
struct trapframe *tf = current->tf;
memset(tf, 0, sizeof(struct trapframe));
tf->tf_cs = USER_CS;
tf->tf_ds = tf->tf_es = tf->tf_ss = USER_DS;
tf->tf_esp = stacktop;
tf->tf_eip = elf->e_entry;
tf->tf_eflags |= FL_IF;
ret = 0;
out:
return ret;
// Some wrong handling
bad_cleanup_mmap:
exit_mmap(mm);
bad_elf_cleanup_pgdir:
put_pgdir(mm);
bad_pgdir_cleanup_mm:
mm_destroy(mm);
bad_mm:
goto out;
}
Running results :
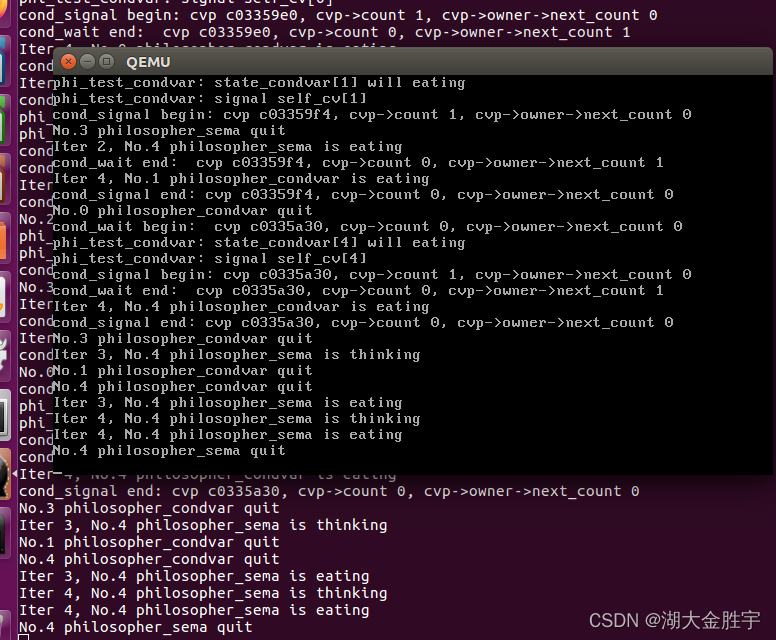
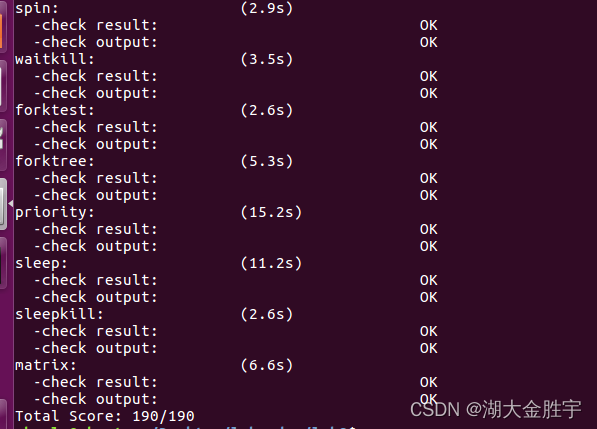
Input ls and hello:
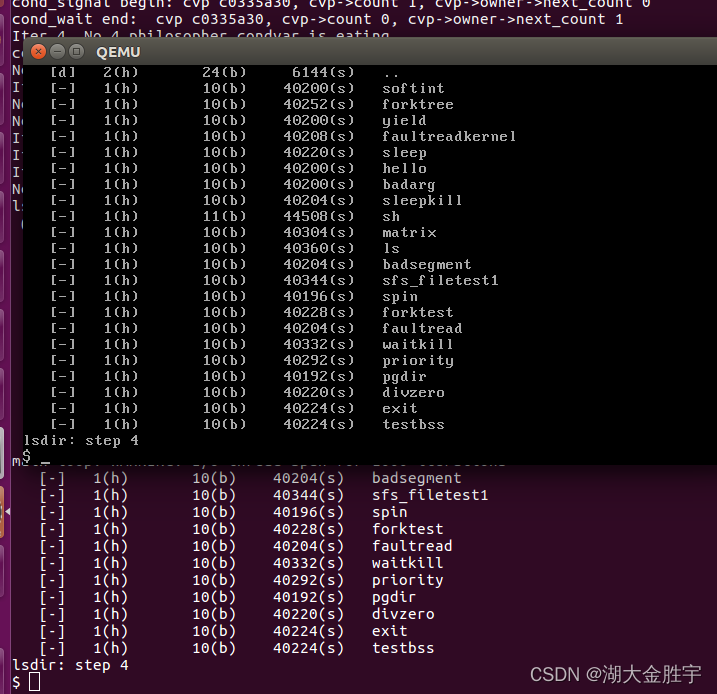
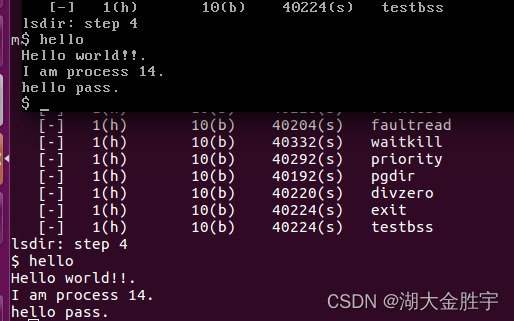
function make grade Check your grades :
Question answering
Please give the design and Implementation Based on ”UNIX Hard link and soft link mechanism “ The outline design of case , Encourage to give detailed design scheme ;
1. Soft link and hard link
Link is actually a way of file sharing , yes POSIX The concept of , Linked files are supported in mainstream file systems .
Links can be simply understood as Windows Shortcuts common in ( or OS X Double in ),Linux It is often used to solve a Some library version problems , It is also common to link files with a deeper directory hierarchy to a more accessible Directory . In these uses , We usually use soft links ( Also known as symbolic links )
Hard links : It's no different from ordinary documents , inode All points to the block of the same file in the hard disk
- Hard links , In the form of a copy of a document . But it doesn't take up the actual space .
- Hard links to directories are not allowed .
- Hard links can only be created in the same file system .
- Deleting one of the hard link files does not affect the others to have the same inode Document No .
Soft link : Save the absolute path of the file it represents , It's another kind of document , There are separate blocks on the hard disk , Replace when accessing Own path .
- Soft links are the form of paths that hold another file .
- Soft links can Cross file system , Hard links cannot .
- Soft link can link to a file name that does not exist , Hard links must have source files .
- Soft links can link directories .
2. Realize the idea
On disk inode There is a nlinks Variable is used to represent the linked count of the current file , Therefore, it supports the implementation of hard links And soft link mechanism ;
- If you create a file on disk A The soft links B, It will be B Create as a normal file inode, And then TYPE Domain Set to link , Then use one of the remaining domains , Point to A Of inode Location , Then use an extra bit to mark Is the current link a soft link or a hard link ;
- When accessing files B(read,write Wait for system call ), Determine if the B It's a link , Is actually going to be right B Point to the text Pieces of A( I already know A Of inode Location ) To operate ;
- When deleting a soft link B When , Put it directly on the disk inode Just delete it ;
- If the file on the disk A Create a hard link B, After the soft link method is used B after , Also need to A Add 1;
- The way of accessing hard links is consistent with that of accessing soft links ;
- When deleting a hard link B When , Except that it needs to be deleted B Of inode outside , Also need to B Files pointed to A Linked by Count minus 1, If it's down to 0, You need to A Delete the ;
Comparison and analysis
The implementation of this experiment is similar to the answer
Important knowledge points in this experiment , And corresponding OS Knowledge points in principle
- The Conduit
- Virtual file system framework
- File descriptor
- Catalog
- inode、 Open files and other structures
- inode cache
- Simple file system
- ucore Specific file system architecture
There is no corresponding :
- Other interprocess communication mechanisms , For example, signals 、 Message queuing and shared memory
- RAID
- Disk scheduling algorithm
- Disk caching
- I/O
Summary of the experiment
Through this experiment , I am familiar with the implementation of basic file system calls , Learned about an index node based organization Simple FS Design and implementation of file system , Understand the file system abstraction layer -VFS Design and implementation , What impresses me is the pipeline And the realization of soft link and hard link .
system call ), Determine if the B It's a link , Is actually going to be right B Point to the text Pieces of A( I already know A Of inode Location ) To operate ;
- When deleting a soft link B When , Put it directly on the disk inode Just delete it ;
- If the file on the disk A Create a hard link B, After the soft link method is used B after , Also need to A Add 1;
- The way of accessing hard links is consistent with that of accessing soft links ;
- When deleting a hard link B When , Except that it needs to be deleted B Of inode outside , Also need to B Files pointed to A Linked by Count minus 1, If it's down to 0, You need to A Delete the ;
Comparison and analysis
The implementation of this experiment is similar to the answer
Important knowledge points in this experiment , And corresponding OS Knowledge points in principle
- The Conduit
- Virtual file system framework
- File descriptor
- Catalog
- inode、 Open files and other structures
- inode cache
- Simple file system
- ucore Specific file system architecture
There is no corresponding :
- Other interprocess communication mechanisms , For example, signals 、 Message queuing and shared memory
- RAID
- Disk scheduling algorithm
- Disk caching
- I/O
Summary of the experiment
Through this experiment , I am familiar with the implementation of basic file system calls , Learned about an index node based organization Simple FS Design and implementation of file system , Understand the file system abstraction layer -VFS Design and implementation , What impresses me is the pipeline And the realization of soft link and hard link .
Last , Thank teachers and teaching assistants for their time , Thank you for your answer .
边栏推荐
- Sleep quality today 81 points
- Soft exam information system project manager_ Project set project portfolio management --- Senior Information System Project Manager of soft exam 025
- Global and Chinese markets of PIM analyzers 2022-2028: Research Report on technology, participants, trends, market size and share
- 软件测试行业的未来趋势及规划
- Automated testing problems you must understand, boutique summary
- 安全测试入门介绍
- Threads et pools de threads
- Want to learn how to get started and learn software testing? I'll give you a good chat today
- [oiclass] maximum formula
- ArrayList set
猜你喜欢

Stc-b learning board buzzer plays music
Réponses aux devoirs du csapp 7 8 9
安全测试入门介绍
Introduction to safety testing

接口测试面试题及参考答案,轻松拿捏面试官
UCORE lab8 file system experiment report
Stc-b learning board buzzer plays music 2.0

Brief introduction to libevent

Maximum nesting depth of parentheses in leetcode simple questions
Knowledge that you need to know when changing to software testing

随机推荐
Eigen User Guide (Introduction)
ucore lab5用户进程管理 实验报告
Description of Vos storage space, bandwidth occupation and PPS requirements
STC-B学习板蜂鸣器播放音乐2.0
Mysql database (II) DML data operation statements and basic DQL statements
Opencv recognition of face in image
Expanded polystyrene (EPS) global and Chinese markets 2022-2028: technology, participants, trends, market size and share Research Report
Heap, stack, queue
想跳槽?面试软件测试需要掌握的7个技能你知道吗
软件测试Bug报告怎么写?
[pytorch] simple use of interpolate
C language do while loop classic Level 2 questions
Introduction to variable parameters
Example 071 simulates a vending machine, designs a program of the vending machine, runs the program, prompts the user, enters the options to be selected, and prompts the selected content after the use
CSAPP Shell Lab 实验报告
Automated testing problems you must understand, boutique summary
Pedestrian re identification (Reid) - data set description market-1501
Interface test interview questions and reference answers, easy to grasp the interviewer
CSAPP家庭作業答案7 8 9章
[HCIA continuous update] advanced features of routing