当前位置:网站首页>UCORE lab8 file system experiment report
UCORE lab8 file system experiment report
2022-07-06 15:06:00 【Wuhu hanjinlun】
The experiment purpose
- Understand the implementation of basic file system calls ;
- Learn about an index node based organization Simple FS Design and implementation of file system ;
- Understand the file system abstraction layer -VFS Design and implementation ;
Experimental content
Experiment 7 completed the synchronization and mutual exclusion experiment in the kernel . This experiment involves file system , Understand through analysis ucore The overall architecture design of the file system , Improve the operation of reading and writing files , Re implement the file system based execution program mechanism ( Namely rewrite do_execve), Thus, the functions of executing files stored on disk and reading and writing files can be completed .
practice
practice 0: Fill in the existing experiment
This experiment relies on experiments 1/2/3/4/5/6/7. Please take your experiment 1/2/3/4/5/6/7 Fill in the code in this experiment. There are “LAB1”/“LAB2”/“LAB3”/“LAB4”/“LAB5”/“LAB6” /“LAB7” The corresponding part of the notes . And ensure that the compilation passes . Be careful : In order to execute correctly lab8 Test application for , It may be necessary to test the completed experiments 1/2/3/4/5/6/7 Code for further improvements .
Use meld The software will lab7 and lab8 Compare folders , The following files need to be copied :
- proc.c
- default_pmm.c
- pmm.c
- swap_fifo.c
- vmm.c
- trap.c
- sche.c
- monitor.c
- check_sync.c
- kdebug.c
Other documents need not be modified , It can be used directly
practice 1: Complete the implementation of file reading operation ( Need to code )
First, understand the processing flow of opening files , Then refer to the subsequent process analysis of file reading and writing operation in this experiment , Written in sfs_inode.c in sfs_io_nolock Read the implementation code of the data in the file .
Please give the design and implementation in the experimental report ”UNIX Of PIPE Mechanism “ Outline design scheme , Encourage to give detailed design scheme
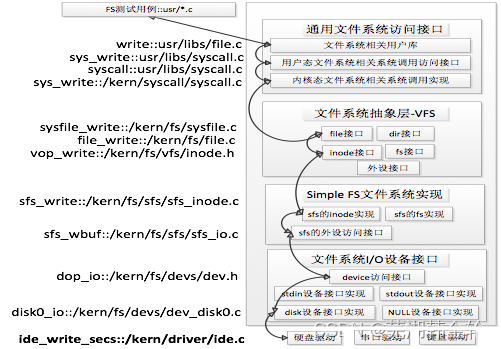
ucore File system architecture for
ucore Imitated UNIX File system design ,ucore The file system architecture of is mainly composed of four parts :
- Common file system access interface layer : This layer provides a standard access interface from user space to file system . This layer of access interface allows applications to obtain through a simple interface ucore Kernel file system services .
- File system abstraction layer : Provide a consistent interface up to the rest of the kernel ( File system related system call implementation module and other kernel function modules ) visit . Provide the same abstract function pointer list and data structure to shield the implementation details of different file systems .
- Simple FS File system layer : An example of a simple file system based on index . Up through various concrete functions to achieve the corresponding abstract functions proposed by the file system Abstract Layer . Downward access to peripheral interfaces
- Peripheral interface layer : Offer up device The access interface shields different hardware details . Downward implementation of interfaces for accessing various specific device drivers , such as disk Device interface / Serial port device interface / Keyboard device interface .
ucore Overall structure of file system :
Important data structures
file File structure :
struct file {
enum {
FD_NONE, FD_INIT, FD_OPENED, FD_CLOSED,
} status; // Access the execution status of the file
bool readable; // Is the file readable
bool writable; // Is the document writable
int fd; // The file in filemap Index value in
off_t pos; // Access the current location of the file
struct inode *node; // The memory corresponding to this file inode The pointer
atomic_t open_count; // Number of times this file was opened
};
inode:inode data structure , It is an index node located in memory , Put the specific inode information of different file systems ( It's not even an inode ) Put it all together , It avoids the process from directly accessing the specific file system
struct inode {
union {
// Different file systems are specific inode The information of union Domain
struct device __device_info; // Device file system memory inode Information
struct sfs_inode __sfs_inode_info; //SFS File system memory inode Information
} in_info;
enum {
inode_type_device_info = 0x1234,
inode_type_sfs_inode_info,
} in_type; // this inode File system type
atomic_t ref_count; // this inode Reference count of
atomic_t open_count; // Open this inode Number of corresponding files
struct fs *in_fs; // Abstract file system , Contains function pointers to access the file system
const struct inode_ops *in_ops; // In the abstract inode operation , Include access inode Function pointer of
};
Process flow of opening file
First assume that the file that the user process needs to open already exists on the hard disk . With user/sfs_filetest1.c For example , First, the user process will call in main The following statements in the function :
int fd1 = safe_open("/test/testfile", O_RDWR | O_TRUNC);
If ucore This file can be found normally , A file descriptor representing the file will be returned fd1, So in the next process of reading and writing files , Just use it directly fd1 Just represent .
The specific process
(1) Processing flow of general file access interface layer
First, the user will call safe_open() function , Then call the following functions in turn : open->sys_open->syscall, This causes the system call to enter the kernel state . When it comes to kernel mode , By interrupt processing routine , Will be called to sys_open Kernel functions , And call sysfile_open Kernel functions . Here we are. , You need to put the string in user space ”/test/testfile” String copied to kernel space path in , And enter the processing flow of the file system abstraction layer to complete the further operation of opening files .
(2) Processing flow of file system abstraction layer
Assign a free file Data structure variables file In the processing of file system abstraction layer ( An array of open files for the current process current->fs_struct->filemap[] A free element in ), At this point, it's only to assign one to the current user process file Variables of data structure , The corresponding file index node has not been found . Further call vfs_open Function to find path The corresponding file indicated is based on inode data-structured VFS The index node node. And then call vop_open Function to open a file . Then return layer by layer , By executing statements file->node=node;, Just put the current process current->fs_struct->filemap[fd]( namely file The indicated variable ) Member variables of node The pointer points to the index node representing the file node. Now back to fd. Finally, complete the operation of opening the file .
(3)SFS Processing flow of file system layer
In the second step ,vop_lookup The function is called sfs_lookup function .
The following analysis sfs_lookup function :
static int sfs_lookup(struct inode *node, char *path, struct inode **node_store) {
struct sfs_fs *sfs = fsop_info(vop_fs(node), sfs);
assert(*path != '\0' && *path != '/'); // With “/” For the separator , Decompose one by one from left to right path Get the corresponding of each subdirectory and the final file inode node .
vop_ref_inc(node);
struct sfs_inode *sin = vop_info(node, sfs_inode);
if (sin->din->type != SFS_TYPE_DIR) {
vop_ref_dec(node);
return -E_NOTDIR;
}
struct inode *subnode;
int ret = sfs_lookup_once(sfs, sin, path, &subnode, NULL); // Loop further calls sfs_lookup_once Looking to “test” Files in subdirectories “testfile1” The corresponding inode node .
vop_ref_dec(node);
if (ret != 0) {
return ret;
}
*node_store = subnode; // When it cannot be decomposed path after , It means finding the corresponding inode node , You can return smoothly .
return 0;
}
sfs_lookup The function starts with “/” For the separator , Decompose one by one from left to right path Get the corresponding of each subdirectory and the final file inode node . Then the loop calls further sfs_lookup_once Looking to “test” Files in subdirectories “testfile1” The corresponding inode node . Finally, when it cannot be decomposed path after , It means finding the corresponding inode node , You can return smoothly .
complete sfs_io_nolock function
sfs_io_nolock Function is mainly used to read a piece of data from disk into memory or write a piece of data from memory to disk .
This function performs a series of edge checks , Check whether the access is out of bounds 、 Is it legal . After that, I will read / Write operations are unified using function pointers , Unified into operations for the whole block . Then complete the reading that does not fall on the whole data block / Write operations , And reading and writing on the whole data block . Here is the code for this function ( Including supplementary code , There will be more detailed notes )
static int
sfs_io_nolock(struct sfs_fs *sfs, struct sfs_inode *sin, void *buf, off_t offset, size_t *alenp, bool write)
{
// Create a disk index node to point to the memory index node to access the file
struct sfs_disk_inode *din = sin->din;
assert(din->type != SFS_TYPE_DIR);
// Determine the end position of the read
off_t endpos = offset + *alenp, blkoff;
*alenp = 0;
// Carry out a series of edges , Avoid illegal access
if (offset < 0 || offset >= SFS_MAX_FILE_SIZE || offset > endpos) {
return -E_INVAL;
}
if (offset == endpos) {
return 0;
}
if (endpos > SFS_MAX_FILE_SIZE) {
endpos = SFS_MAX_FILE_SIZE;
}
if (!write) {
if (offset >= din->size) {
return 0;
}
if (endpos > din->size) {
endpos = din->size;
}
}
int (*sfs_buf_op)(struct sfs_fs *sfs, void *buf, size_t len, uint32_t blkno, off_t offset);
int (*sfs_block_op)(struct sfs_fs *sfs, void *buf, uint32_t blkno, uint32_t nblks);
// Determine whether it is a read operation or a write operation , And determine the corresponding system function
if (write) {
sfs_buf_op = sfs_wbuf, sfs_block_op = sfs_wblock;
}
else {
sfs_buf_op = sfs_rbuf, sfs_block_op = sfs_rblock;
}
//
int ret = 0;
size_t size, alen = 0;
uint32_t ino;
uint32_t blkno = offset / SFS_BLKSIZE; // The NO. of Rd/Wr begin block
uint32_t nblks = endpos / SFS_BLKSIZE - blkno; // The size of Rd/Wr blocks
//-------------------------- The supplementary part ----------------------------------------------
// Judge whether the first block in the data block of the area to be operated is completely covered ,
// If not , You need to call a function that reads or writes a non whole block of data to complete the corresponding operation
if ((blkoff = offset % SFS_BLKSIZE) != 0) {
// The offset of the operation in the first data block
blkoff = offset % SFS_BLKSIZE;
// Length of data in the first data block
size = (nblks != 0) ? (SFS_BLKSIZE - blkoff) : (endpos - offset);
// Get the number of these data blocks corresponding to the data blocks on the disk
if ((ret = sfs_bmap_load_nolock(sfs, sin, blkno, &ino)) != 0) {
goto out;
}
// Read or write data blocks
if ((ret = sfs_buf_op(sfs, buf, size, ino, blkoff)) != 0) {
goto out;
}
// The length of data that has been read and written
alen += size;
if (nblks == 0) {
goto out;
}
buf += size, blkno++; nblks--;
}
Read the data in the middle part , Divide it into size size The block , Then operate one by one , Until completion
size = SFS_BLKSIZE;
while (nblks != 0)
{
if ((ret = sfs_bmap_load_nolock(sfs, sin, blkno, &ino)) != 0) {
goto out;
}
// Read or write data blocks
if ((ret = sfs_block_op(sfs, buf, ino, 1)) != 0) {
goto out;
}
// Update the corresponding variable
alen += size, buf += size, blkno++, nblks--;
}
// The last page , Misalignment may occur :
if ((size = endpos % SFS_BLKSIZE) != 0)
{
// Get the number of the data block corresponding to the data block on the disk
if ((ret = sfs_bmap_load_nolock(sfs, sin, blkno, &ino)) != 0) {
goto out;
}
// Perform non block read or write operations
if ((ret = sfs_buf_op(sfs, buf, size, ino, 0)) != 0) {
goto out;
}
alen += size;
}
out:
*alenp = alen;
if (offset + alen > sin->din->size) {
sin->din->size = offset + alen;
sin->dirty = 1;
}
return ret;
}
In general, it is divided into three parts to read the file , Each time through sfs_bmap_load_nolock Function to get the file index number , And then call sfs_buf_op perhaps sfs_block_op Complete the actual file reading and writing operation .
Question answering
- Please give the design and implementation in the experimental report ”UNIX Of PIPE Mechanism “ Outline design scheme , Encourage to give detailed design scheme
Pipes can be used for communication between processes with kinship , A pipeline is a buffer managed by the kernel , It's equivalent to a note we put in memory . One end of the pipe is connected to the output of a process . This process will put information into the pipeline . Connect the other end of the input pipeline , This process takes out the information put into the pipeline . A buffer does not need to be large , It is designed as a ring data structure , So that the pipe can be recycled . When there is no information in the pipeline , The process reading from the pipeline will wait , Until the process at the other end puts information . When the pipeline is full of information , The process trying to put information will wait , Until the process at the other end takes out the information . When both processes end , The pipe also disappears automatically .
stay Linux in , The implementation of pipeline does not use special data structure , But with the help of the file system file The structure and VFS The index node of inode. By putting two file The structure points to the same temporary VFS The index node , And this VFS The index node points to a physical page .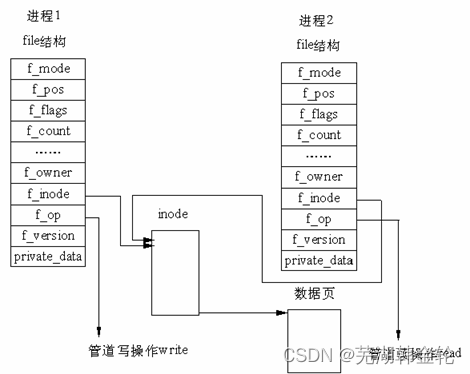
Pipelines can be seen as a managed by the kernel buffer , One end is connected to process A Output , End connection process B The input of . process A Will put information into the pipeline , And the process B Will take out the information put into the pipeline . When there is no information in the pipeline , process B Meeting wait for , Until the process A Put information . When the pipeline is full of information , process A Will wait for , Until the process B Take out the information . When both processes are over , The pipe also disappears automatically . The pipeline is based on fork Mechanism to establish , So that two processes can connect to the same PIPE On .
Based on this , We can imitate UNIX, To design a PIPE Mechanism .
- First, we need to reserve a certain area on the disk for PIPE The mechanism buffer , Or create a file as PIPE Mechanism Services
- When initializing system files PIPE also initialization And create the corresponding inode
- In memory for PIPE Leave an area , In order to complete the cache efficiently
- When two processes want to establish a pipeline , Then it can be on the process control block of these two processes New variable To record this property of the process
- When one of the processes wants to process the data Write In operation , Information through the process control block , You can put it first For temporary files PIPE Make changes
- When a process needs to process data read In operation , This can be done through the information of the process control block For temporary files PIPE The read
- Add some related system calls to support the above operations
thus ,PIPE The general framework of has been completed .
practice 2: Complete the implementation of the execution program mechanism based on the file system ( Need to code )
rewrite proc.c Medium load_icode Functions and other related functions , Implement file system based execution program mechanism . perform :make qemu. If you can see sh User program execution interface , Basically succeeded . If in sh The user interface can execute ”ls”,”hello” Wait for others to be placed sfs Other executors in the file system , It can be considered that this experiment is basically successful .
Please give the design and Implementation Based on ”UNIX Hard link and soft link mechanism “ Outline design scheme , Encourage to give detailed design scheme
alloc_proc
stay proc.c in , According to the comments, we need to initialize fs Process control structure in , That is to say alloc_proc We need to make some changes in the function , add a sentence proc->filesp = NULL; To complete initialization .
static struct proc_struct *
alloc_proc(void) {
struct proc_struct *proc = kmalloc(sizeof(struct proc_struct));
if (proc != NULL) {
// Lab7 Content
// ...
//LAB8:EXERCISE2 YOUR CODE HINT:need add some code to init fs in proc_struct, ...
// LAB8 Add one filesp Initialization of the pointer
proc->filesp = NULL;
}
return proc;
}
load_icode
load_icode The main task of the function is to create a user environment for the user process to run normally . The basic flow :
- call mm_create Function to apply for the memory management data structure of the process mm Required memory space , Also on mm To initialize ;
- call setup_pgdir To apply for a page size memory space required for a page directory table , And describe ucore Kernel page table of kernel virtual space mapping (boot_pgdir To refer to ) Copy the contents of this new directory table , Finally let mm->pgdir Point to the table of contents on this page , This is the new page directory table of the process , And can correctly map the kernel virtual space ;
- Load the files in the disk into memory , This... Is resolved according to the starting position of the application execution code ELF Format execution program , And according to ELF The format of the execution program describes the various paragraphs ( Code segment 、 Data segment 、BSS Duan et al ) The starting position and size of the corresponding vma structure , And put vma Insert into mm In structure , Thus, it shows the legal user state virtual address space of user process ;
- Call to allocate physical memory space according to the size of each segment of the executing program , The virtual address is determined according to the starting position of each segment of the execution program , And establish the mapping relationship between physical address and virtual address in the page table , Then copy the contents of each segment of the execution program to the corresponding kernel virtual address
- You need to set the user stack for the user process , And handle the parameters passed in the user stack
- First clear the interrupt frame of the process , Then reset the interrupt frame of the process , Make the interrupt return instruction “iret” after , To be able to make CPU Go to the user state privilege level , And return to the user state memory space , Code snippets using user mode 、 Segments and stacks , And can jump to the first instruction execution of the user process , And ensure that the interrupt can be responded to in the user state ;
It can be roughly divided into the following parts :
Load the file into memory and execute , According to the notes, there are seven steps :
- Create a memory manager
- Create a page directory
- Load the file into memory segment by segment , Here, you should pay attention to setting the mapping between virtual address and physical address
- Establish the corresponding virtual memory mapping table
- Establish and initialize the user stack
- Handle the parameters passed in from the user stack
- The last key step is to set the interrupt frame of the user process
The complete code is as follows :
// Read the executable file from the disk , And loaded into memory , Complete the initialization of memory space
static int load_icode(int fd, int argc, char **kargv)
{
// Determine whether the memory management of the current process has been released , We need to require that the current memory manager is empty
if (current->mm != NULL)
{
panic("load_icode: current->mm must be empty.\n");
}
int ret = -E_NO_MEM;
//1. call mm_create Function to apply for the memory management data structure of the process mm Required memory space , Also on mm To initialize
struct mm_struct *mm;
if ((mm = mm_create()) == NULL) {
goto bad_mm;
}
//2. Apply for space for new directory items and complete the setting of directory items
if (setup_pgdir(mm) != 0) {
goto bad_pgdir_cleanup_mm;
}
// Create page table
struct Page *page;
//3. Load program from file from disk to memory
struct elfhdr __elf, *elf = &__elf;
//3.1 call load_icode_read Function read ELF file
if ((ret = load_icode_read(fd, elf, sizeof(struct elfhdr), 0)) != 0)
{
goto bad_elf_cleanup_pgdir;
}
// Judge whether this file is legal
if (elf->e_magic != ELF_MAGIC) {
ret = -E_INVAL_ELF;
goto bad_elf_cleanup_pgdir;
}
struct proghdr __ph, *ph = &__ph;
uint32_t i;
uint32_t vm_flags, perm;
//e_phnum Represents the number of program segment entry addresses
for (i = 0; i < elf->e_phnum; ++i)
{
//3.2 Loop through the header of each segment of the program
if ((ret = load_icode_read(fd, ph, sizeof(struct proghdr), elf->e_phoff + sizeof(struct proghdr) * i)) != 0)
{
goto bad_elf_cleanup_pgdir;
}
if (ph->p_type != ELF_PT_LOAD) {
continue ;
}
if (ph->p_filesz > ph->p_memsz) {
ret = -E_INVAL_ELF;
goto bad_cleanup_mmap;
}
if (ph->p_filesz == 0) {
continue ;
}
//3.3 Establish corresponding VMA
vm_flags = 0, perm = PTE_U; // Establish the mapping between virtual address and physical address
// according to ELF Information in the file , Set the permissions of each section
if (ph->p_flags & ELF_PF_X) vm_flags |= VM_EXEC;
if (ph->p_flags & ELF_PF_W) vm_flags |= VM_WRITE;
if (ph->p_flags & ELF_PF_R) vm_flags |= VM_READ;
if (vm_flags & VM_WRITE) perm |= PTE_W;
// The virtual memory address is set to legal
if ((ret = mm_map(mm, ph->p_va, ph->p_memsz, vm_flags, NULL)) != 0) {
goto bad_cleanup_mmap;
}
//3.4 Allocate pages for data segments, code segments, etc
off_t offset = ph->p_offset;
size_t off, size;
// Calculate the starting address of data segment and code segment
uintptr_t start = ph->p_va, end, la = ROUNDDOWN(start, PGSIZE);
ret = -E_NO_MEM;
// Calculate the end address of data segment and code segment
end = ph->p_va + ph->p_filesz;
while (start < end)
{
// by TEXT/DATA Allocate physical memory space page by page
if ((page = pgdir_alloc_page(mm->pgdir, la, perm)) == NULL)
{
goto bad_cleanup_mmap;
}
off = start - la, size = PGSIZE - off, la += PGSIZE;
if (end < la) {
size -= la - end;
}
// Put... On the disk TEXT/DATA The segment is read into the allocated memory space
// Each read size The size of the block , Until you finish reading
if ((ret = load_icode_read(fd, page2kva(page) + off, size, offset)) != 0)
{
goto bad_cleanup_mmap;
}
start += size, offset += size;
}
//3.5 by BBS Section distribution page
// Calculation BBS End address of
end = ph->p_va + ph->p_memsz;
if (start < la) {
if (start == end) {
continue ;
}
off = start + PGSIZE - la, size = PGSIZE - off;
if (end < la)
{
size -= la - end;
}
memset(page2kva(page) + off, 0, size);
start += size;
assert((end < la && start == end) || (end >= la && start == la));
}
// If you don't give BSS Segment allocate enough pages , Further allocation
while (start < end) {
if ((page = pgdir_alloc_page(mm->pgdir, la, perm)) == NULL) {
goto bad_cleanup_mmap;
}
off = start - la, size = PGSIZE - off, la += PGSIZE;
if (end < la) {
size -= la - end;
}
// Reset and initialize the allocated space
memset(page2kva(page) + off, 0, size);
start += size;
}
}
sysfile_close(fd);// Close file , End of loader
// 4. Set user stack
vm_flags = VM_READ | VM_WRITE | VM_STACK; // Set the permissions of the user stack
// Set the virtual memory area where the user stack is located to legal
if ((ret = mm_map(mm, USTACKTOP - USTACKSIZE, USTACKSIZE, vm_flags, NULL)) != 0) {
goto bad_cleanup_mmap;
}
assert(pgdir_alloc_page(mm->pgdir, USTACKTOP-PGSIZE , PTE_USER) != NULL);
assert(pgdir_alloc_page(mm->pgdir, USTACKTOP-2*PGSIZE , PTE_USER) != NULL);
assert(pgdir_alloc_page(mm->pgdir, USTACKTOP-3*PGSIZE , PTE_USER) != NULL);
assert(pgdir_alloc_page(mm->pgdir, USTACKTOP-4*PGSIZE , PTE_USER) != NULL);
// Set the mm、cr3 etc.
mm_count_inc(mm);
current->mm = mm;
current->cr3 = PADDR(mm->pgdir);
lcr3(PADDR(mm->pgdir));
// Set for user space trapeframe
uint32_t argv_size=0, i;
// Determine how much space the parameters passed to the application should occupy
uint32_t total_len = 0;
for (i = 0; i < argc; ++i)
{
total_len += strnlen(kargv[i], EXEC_MAX_ARG_LEN) + 1;
// +1 Represents the end of a string '\0'
}
// User stack top minus the total length of all parameters , And 4 Byte alignment find the position of the stack where the string parameters are actually stored
char *arg_str = (USTACKTOP - total_len) & 0xfffffffc;
// Store pointers to string parameters
int32_t *arg_ptr = (int32_t *)arg_str - argc;
// According to the space that the parameter needs to occupy on the stack , The position of the top of the stack after passing the parameter
int32_t *stacktop = arg_ptr - 1;
*stacktop = argc;
for (i = 0; i < argc; ++i)
{
uint32_t arg_len = strnlen(kargv[i], EXEC_MAX_ARG_LEN);
strncpy(arg_str, kargv[i], arg_len);
*arg_ptr = arg_str;
arg_str += arg_len + 1;
++arg_ptr;
}
//6. Set the interrupt frame of the process
// Set up tf Setting of corresponding variables , Include :tf_cs、tf_ds tf_es、tf_ss tf_esp, tf_eip, tf_eflags
struct trapframe *tf = current->tf;
memset(tf, 0, sizeof(struct trapframe));
tf->tf_cs = USER_CS;
tf->tf_ds = tf->tf_es = tf->tf_ss = USER_DS;
tf->tf_esp = stacktop;
tf->tf_eip = elf->e_entry;
tf->tf_eflags |= FL_IF;
ret = 0;
out:
return ret;
// Some wrong handling
bad_cleanup_mmap:
exit_mmap(mm);
bad_elf_cleanup_pgdir:
put_pgdir(mm);
bad_pgdir_cleanup_mm:
mm_destroy(mm);
bad_mm:
goto out;
}
function make qemu:
Input ls and hello:

function make grade Check your grades :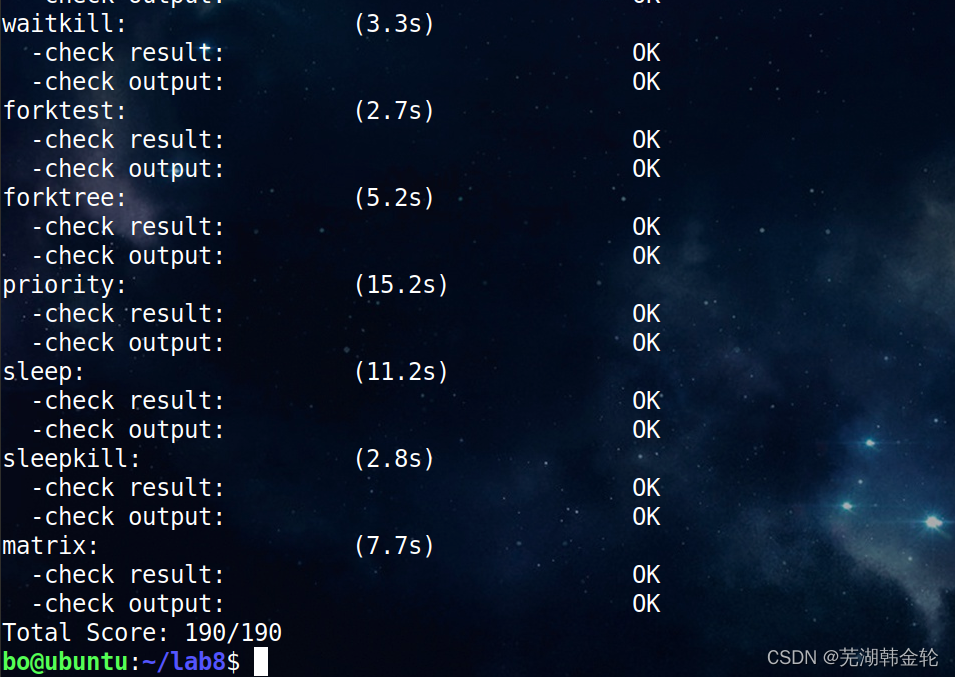
Question answering
- Please give the design and Implementation Based on ”UNIX Hard link and soft link mechanism “ Outline design scheme , Encourage to give detailed design scheme
Hard links : It's a copy of the document , At the same time, establish the connection between the two
Soft link : Symbolic connection
The main features of hard links and soft links :
Because hard links have the same inode Only files with different file names , Therefore, hard links have the following features :
- The documents have the same inode And data block;
- Only existing files can be created ;
- Can't cross file system for hard link creation ;
- Cannot create directory , Only files can be created ;
- Deleting a hard link file does not affect others having the same inode Document No
The creation and use of soft links do not have many restrictions similar to hard links :
- Soft links have their own file properties and permissions ;
- You can create soft links to nonexistent files or directories ;
- Soft links can cross file systems ;
- Soft links can create files or directories ;
- When creating a soft link , Link count i_nlink Will not increase ;
- Deleting a soft link does not affect the file being pointed to , But if the original file pointed to is deleted , The related soft links are called dead links ( namely dangling
link, If the directed path file is recreated , Dead links can be restored to normal soft links ).
Saved on disk inode There is a nlinks Variable is used to represent the linked count of the current file , Therefore, it supports the implementation of hard link and soft link mechanisms ;
- Create a hard link link when , by
new_pathCreate the corresponding file, And put it inode Point to old_path The correspondinginode,inodeReference count of plus 1. - Create a soft connection link when , Create a new file (inode Different ), And put
old_pathThe contents of the file are stored in the contents of the file , When saving this file on diskdisk_inodeThe type isSFS_TYPE_LINK, Perfect this typeinodeThe operation of . - Delete a soft link B When , Put it directly on the disk
inodeJust delete it ; But delete a hard link B When , Except that it needs to be deleted B Ofinodeoutside , Also need to B Files pointed to A The linked count of is subtracted 1, If it's down to 0, You need to A Delete the ; - The way of asking hard links is consistent with accessing soft links ;
Congratulations on your efforts , It's done ucore OS lab1-lab8!
边栏推荐
- Practical cases, hand-in-hand teaching you to build e-commerce user portraits | with code
- Réponses aux devoirs du csapp 7 8 9
- 王爽汇编语言学习详细笔记一:基础知识
- 数字电路基础(三)编码器和译码器
- Using flask_ Whooshalchemyplus Jieba realizes global search of flask
- Investment operation steps
- Wang Shuang's detailed notes on assembly language learning I: basic knowledge
- 数字电路基础(四) 数据分配器、数据选择器和数值比较器
- Zhejiang University Edition "C language programming experiment and exercise guide (3rd Edition)" topic set
- High concurrency programming series: 6 steps of JVM performance tuning and detailed explanation of key tuning parameters
猜你喜欢

Capitalize the title of leetcode simple question
Login the system in the background, connect the database with JDBC, and do small case exercises
“Hello IC World”

Quaternion -- basic concepts (Reprint)
ucore lab1 系统软件启动过程 实验报告
![[Ogg III] daily operation and maintenance: clean up archive logs, register Ogg process services, and regularly back up databases](/img/31/875b08d752ecd914f4e727e561adbd.jpg)
[Ogg III] daily operation and maintenance: clean up archive logs, register Ogg process services, and regularly back up databases

Fundamentals of digital circuits (III) encoder and decoder
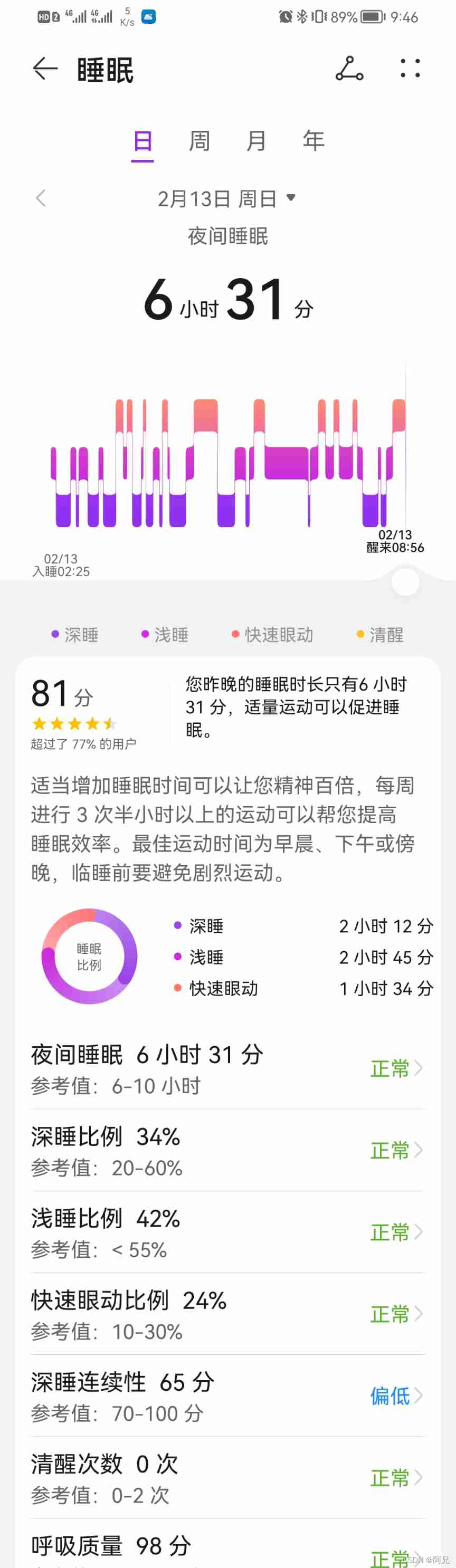
Sleep quality today 81 points
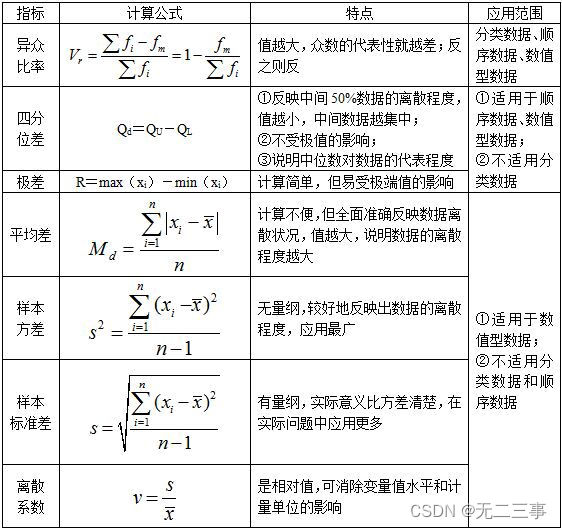
Statistics 8th Edition Jia Junping Chapter 4 Summary and after class exercise answers
CSAPP homework answers chapter 789
随机推荐
Summary of thread implementation
The four connection methods of JDBC are directly coded
Maximum nesting depth of parentheses in leetcode simple questions
Cadence physical library lef file syntax learning [continuous update]
Public key box
ucore lab8 文件系统 实验报告
[oiclass] maximum formula
5分钟掌握机器学习鸢尾花逻辑回归分类
[pointer] use the insertion sorting method to arrange n numbers from small to large
Pointer -- eliminate all numbers in the string
Fundamentals of digital circuits (II) logic algebra
【指针】八进制转换为十进制
How to learn automated testing in 2022? This article tells you
四元数---基本概念(转载)
ByteDance ten years of experience, old bird, took more than half a year to sort out the software test interview questions
“Hello IC World”
Global and Chinese market of goat milk powder 2022-2028: Research Report on technology, participants, trends, market size and share
STC-B学习板蜂鸣器播放音乐2.0
Vysor uses WiFi wireless connection for screen projection_ Operate the mobile phone on the computer_ Wireless debugging -- uniapp native development 008
Expanded polystyrene (EPS) global and Chinese markets 2022-2028: technology, participants, trends, market size and share Research Report