当前位置:网站首页>Learning notes of millet mall, day 5: ES full text search
Learning notes of millet mall, day 5: ES full text search
2020-11-09 16:11:00 【There is a little ALFY】
Grain mall learning notes , Fifth day :ES Full text search
One 、 Basic concepts
notes :ES7 and 8 I don't support type 了
1、Index Indexes
amount to MySQL Medium Database
2、Type type (ES8 I don't support it in the future )
amount to MySQL Medium table
3、Document file (JSON Format )
amount to MySQL Data in
Inverted index :
Forward index :
When users search for keywords on the home page “ Huawei mobile phones ” when , Suppose there are only positive indexes (forward index), Then you need to scan all the documents in the index library ,
Find all the keywords that contain “ Huawei mobile phones ” Documents , Then according to the scoring model to score , After ranking, it will be presented to users . Because of the documents in search engines on the Internet
The number is astronomical , This kind of index structure can not meet the requirement of real-time return of ranking results .
Inverted index :
An inverted index consists of a list of all non repeating words in a document , For each of these words , There is a list of documents that contain it . We first split each document into separate words ,
Create a sort list of all non repeating entries , Then list which document each entry appears in .
obtain Inverted index The structure is as follows :
| key word | file ID |
|---|---|
| key word 1 | file 1, file 2 |
| key word 2 | file 2, file 7 |
From the keyword of the word , Find the document .
Two 、Docker install ES
1、 Download the image file
docker pull elasticsearch:7.4.2
docker pull kibana:7.4.2 ## Visually retrieve data
2、 install
## Now create a local hang on path
mkdir -p /opt/software/mydata/elasticsearch/config
mkdir -p /opt/software/mydata/elasticsearch/data
mkdir -p /opt/software/mydata/elasticsearch/plugins
## Set read and write permissions
chmod -R 777 /opt/software/mydata/elasticsearch/
## The configuration file : The remote access
echo "http.host:0.0.0.0" >> /opt/software/mydata/elasticsearch/config/elasticsearch.yml
## install ES
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms64m -Xms128m" \
-v /opt/software/mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /opt/software/mydata/elasticsearch/data:/usr/share/elasticsearch/data \
-v /opt/software/mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.4.2
## Check the log
docker logs elasticsearch
## install Kibana
docker run --name kibana -p 5601:5601 \
-e ELASTICSEARCH_HOSTS=http://182.92.191.49:9200 \
-d kibana:7.4.2
verification
visit :http:// Your server IP:9200 es
http:// Your server IP:5601 kibana
If it's Alibaba's server , Let go of the security group rules first 9200 5601
9200 As Http agreement , It is mainly used for external communication
9300 As Tcp agreement ,jar Between is through tcp Protocol communication ,ES Through the 9300 To communicate
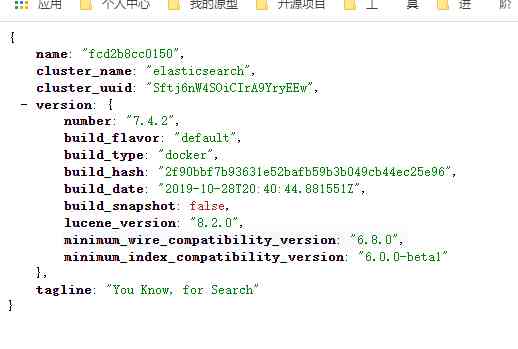
3、 ... and 、 Preliminary search
3.1、_cat
| command | effect |
|---|---|
| GET /_cat/nodes | View all nodes |
| GET /_cat/health | see ES health |
| GET /_cat/master | see ES Master node |
| GET /_cat/indices | View all indexes :show databases |
3.2、 The new data :put/post
##put and post Can be added and modified
##post You can take ID It's also possible to do without ID, For the first time , Second revision
##put Must bring ID, Otherwise, the report will be wrong , The same is true for the first time , Second table modification .[ Because you have to bring ID, All are generally used to make modifications ]
## grammar
POST http://IP:9200/index/type/id id Take it or not
{
name: "lee"
}
PUT http://IP:9200/index/type/id id Must bring
{
name: "lee"
}
3.3、 Query data :GET& Optimism lock
## grammar
GET http://IP:9200/customer/external/1
result :
{
"_index": "customer", ## Indexes
"_type": "external", ## type
"_id": "1", ##doc Of ID
"_version": 5, ## Version number , Add number of changes
"_seq_no": 5, ## Concurrency control fields , Every update will +1, Used to make optimism lock
"_primary_term": 1, ## ditto , The main partition is redistributed , If you restart , It will change , Used to make optimism lock
"found": true, ##true It means that we have found
"_source": {
"name": "ren"
}
}
## Optimism lock : To prevent concurrent changes
## We can do the following operations when modifying :
PUT http://IP:9200/customer/external/1?_seq_no=5&_primary_term=1
{
"name":"ren"
}
3.4、 Update data :PUT/POST
## Covering the update : Delete the original data first , Add new
POST http://IP:9200/customer/external/1
{
"name":"lee",
"gender":"male",
"age":20
}
PUT http://IP:9200/customer/external/1
{
"name":"ren",
"gender":"male"
}
## Partial update : Only modify the listed fields
POST http://IP:9200/customer/external/1/_update
{
"doc":{
"name":"lee_ren",
}
}
3.5、 Delete data and index :DELETE
## Delete data
DELETE http://IP:9200/customer/external/1
## Delete index ( Not deleted type)
DELETE http://IP:9200/customer
3.6、 Bulk import data :bulk
Be careful : Independent operation , No transaction
########## grammar :action Express POST PUT DELETE
{ action: { metadata }}
{ request body }
{ action: { metadata }}
{ request body }
######### Batch add
http://IP:9200/_bulk
{"create":{"_index":"haoke","_type":"user","_id":"aaa"}}
{"id":1001,"name":"name1","age":20,"sex":" male "}
{"create":{"_index":"haoke","_type":"user","_id":"bbb"}}
{"id":1002,"name":"name2","age":21,"sex":" Woman "}
{"create":{"_index":"haoke","_type":"user","_id":"ccc"}}
{"id":1003,"name":"name3","age":22,"sex":" Woman "}
perhaps :
{"index":{"_index":"haoke","_type":"user","_id":"aaa"}}
{"id":1001,"name":"name1","age":20,"sex":" male "}
{"index":{"_index":"haoke","_type":"user","_id":"bbb"}}
{"id":1002,"name":"name2","age":21,"sex":" Woman "}
{"index":{"_index":"haoke","_type":"user","_id":"ccc"}}
{"id":1003,"name":"name3","age":22,"sex":" Woman "}
######### Batch deletion
POST http://IP:9200/_bulk
{"delete":{"_index":"haoke","_type":"user","_id":"aaa"}}
{"delete":{"_index":"haoke","_type":"user","_id":"bbb"}}
{"delete":{"_index":"haoke","_type":"user","_id":"ccc"}}
######## Bulk changes
POST http://IP:9200/_bulk
request body:
{"index":{"_index":"haoke","_type":"user","_id":"aaa"}}
{"id":1001,"name":"name111","age":20,"sex":" male "}
{"index":{"_index":"haoke","_type":"user","_id":"bbb"}}
{"id":1002,"name":"name222","age":21,"sex":" Woman "}
{"index":{"_index":"haoke","_type":"user","_id":"ccc"}}
{"id":1003,"name":"name333","age":22,"sex":" Woman "}
######### Batch partial modification
POST http://IP:9200/_bulk
request body:
{"update":{"_index":"haoke","_type":"user","_id":"aaa"}}
{"doc":{"name":"name111a"}}
{"update":{"_index":"haoke","_type":"user","_id":"bbb"}}
{"doc":{"name":"name222b"}}
{"update":{"_index":"haoke","_type":"user","_id":"ccc"}}
{"doc":{"name":"name333c"}}
elasticsearch Own batch Test data :
https://download.elastic.co/demos/kibana/gettingstarted/8.x/accounts.zip
Four 、 Search Advanced
The first way to search :
## Put all the request parameters , Put it in URI In the path
GET http://IP:9200/bank/_search?q=*&sort=account_number:asc
[q=* Query all ,sort Indicates that the sort field is account_number Ascending , Default from by 0 size by 10]
The second way to search :Query DSL
## Put all the request parameters , Put it in body The body of the
GET http://IP:9200/bank/_search
{
"query": {
"match_all": {}
},
"sort": {
"account_number": "asc"
}
}
[query Represents a query match_all Query all ,sort Indicates sort , Default from by 0 size by 10]
4.1、Query DSL Basic grammar
GET http://IP:9200/bank/_search
{
"query": {
"match_all": {}
},
"sort": {
"account_number": "asc"
}
"from": 0,
"size": 5,
"_source": ["account_number","balance"]
}
[query Represents a query match_all Query all ,sort Indicates sort ,from It means to start from the data ]
[size Represents the number of query records ,_source Represents the field to be returned ]
4.2、Query DSL:match
##match Exactly match ,
## Not String Type field amount to == Number
##String Type field amount to like,( After the participle == Exactly match )
GET http://IP:9200/bank/_search
{
"query": {
"match": {
"address": "mill"
}
}
}
##match add keyword, It's an exact match address Must be 990 Mill Road, Case should also be distinguished
## Be careful macth+keyword Same as match_phrase The difference between :
##macth+keyword It must be as like as two peas == ,match_phrase It can be included like, It is case insensitive
GET http://IP:9200/bank/_search
{
"query": {
"match": {
"address.keyword": "990 Mill Road"
}
}
}
4.3、Query DSL:match_phrase
##match_phrase phrase match ,
##match Will "mill road" Divide it into two words "mill" and "road" Match ,
##match_phrase Will be "mill road" Match as a complete word ( Case write and The extra space in the middle does not affect the query results )
GET http://IP:9200/bank/_search
{
"query": {
"match_phrase": {
"address": "mill road"
}
}
}
4.4、Query DSL:multi_match
##multi_match Multi field matching
## amount to username == "aa" or nickname == "aa"
GET http://IP:9200/bank/_search
{
"query": {
"multi_match": {
"query":"mill movico",
"fields":["address","city"]
}
}
}
##es Will mill and movico participle , The result is similar to address == mill or address == movico or city == mill or city == movico
4.5、Query DSL:bool
##bool Composite query
##bool Combine several queries , They are and The relationship between
##must It must be satisfied ,must_not It must be unsatisfied ,should It can be satisfied or not satisfied , But when it is satisfied, the ranking will be higher
##must and should It will improve the relevant score score,must_not It doesn't affect the score (filter It doesn't affect the score )
GET /bank/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"address":"mill"
}
},
{
"match": {
"gender": "m"
}
}
],
"must_not": [
{
"match": {
"age": "28"
}
}
],
"should": [
{
"match": {
"city": "blackgum"
}
}
]
}
}
}
4.6、Query DSL:filter
##filter Result filtering
##filter similar must, But it doesn't affect the score score result
##must and should Will affect the relevant results score, but filter Can't
##range similar between
GET /bank/_search
{
"query": {
"bool": {
"filter": {
"range": {
"age": {
"gte": 10,
"lte": 30
}
}
}
}
}
}
4.7、Query DSL:term
##term Equate to match, but term Can only be used for precise non text Text format search ( No word segmentation )
##match Can be done text After the participle of
## Appointment : Not text Field use term,text Field use match
## Note, for example :city:"hebei" yes String It can be used term lookup
##address:"hebei handan" yes text Need to use match lookup
GET /bank/_search
{
"query": {
"term": {
"address": "mill"
}
}
}
5、 ... and 、 polymerization :aggregations
## polymerization : Grouping and extracting data from data
## Be similar to SQL Medium group by\count\avg etc.
## Aggregation type term avg Average min Minimum max Maximum sum comprehensive
## Be careful : Aggregate use of text and string forms keyword polymerization
## grammar :
"aggs": {
"aggs name Aggregate name ": {
"aggs type Aggregation type ": {
"field": " Aggregated fields ",
"size": " How many results do you want "
},
.... Sub aggregation
},
... Other aggregations
}
##eg
##1、 Search for address Contained in the mill The age distribution of all, as well as the average age and average salary
##[size:0 Show search data 0 strip , That is, search results are not displayed ]
## Other aggregations
GET /bank/_search
{
"query": {
"match": {
"address": "mill"
}
},
"aggs": {
"ageAggs": {
"terms": {
"field": "age",
"size": 10
}
},
"ageAvgAggs":{
"avg": {
"field": "age"
}
},
"balanceAvgAggs":{
"avg": {
"field": "balance"
}
}
},
"size":0
}
##2、 Aggregate according to age , And investigate the average salary of each age group
## Sub aggregation
GET /bank/_search
{
"query": {
"match_all": {}
},
"aggs": {
"ageAggs": {
"terms": {
"field": "age",
"size": 10
},
"aggs": {
"balanceAvg": {
"avg": {
"field": "balance"
}
}
}
}
},
"size": 0
}
##3、 Investigate all age distributions , And the average salary in these age groups and M The average salary of a man and F Women's average salary
##[gender It's in the form of text , It's not possible to aggregate , use gender.keyword polymerization ]
GET /bank/_search
{
"query": {
"match_all": {}
},
"aggs": {
"ageAggs": {
"terms": {
"field": "age",
"size": 10
},
"aggs": {
"ageBalanceAvg": {
"avg": {
"field": "balance"
}
},
"genderAggs": {
"terms": {
"field": "gender.keyword"
},
"aggs": {
"genderBalanceAvg": {
"avg": {
"field": "balance"
}
}
}
}
}
}
},
"size": 0
}
6、 ... and 、 mapping :Mapping
## mapping :mapping similar SQL The data type of the field defined in
##1、 View the map
GET /bank/_mapping
##2、 Create mapping
PUT /myindex
{
"mappings": {
"properties": {
"name":{"type": "text"},
"age":{"type": "integer"},
"email":{"type": "keyword"},
"birthday":{"type": "date"}
}
}
}
##3、 Existing mapping On , Add a new mapping field
PUT /myindex/_mapping
{
"properties":{
"employee_id":{"type":"long"}
}
}
##4、 modify : Existing fields of existing maps cannot be modified , Only new fields can be added
## If you have to think about Modify the existing mapping , You need to recreate the mapping mapping, And then migrate the data
## Such as : There is bank The index is with type Of , Now we create a new map and remove bank
## Create a new mapping
PUT /newbank
{
"mappings": {
"properties": {
"account_number": {
"type": "long"
},
"address": {
"type": "text"
},
"age": {
"type": "integer"
},
"balance": {
"type": "long"
},
"city": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"email": {
"type": "keyword"
},
"employer": {
"type": "text"
},
"firstname": {
"type": "text"
},
"gender": {
"type": "keyword"
},
"lastname": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"state": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
## Data migration : Original bank Data from to newbank in
## Data migration
POST _reindex
{
"source": {
"index": "bank",
"type": "account"
},
"dest": {
"index": "newbank"
}
}
## Notice that it's ES The old version has type Type of data migration , The new version of the data does not carry type, The transfer grammar is as follows :
POST _reindex
{
"source": {
"index": "bank"
},
"dest": {
"index": "newbank"
}
}
7、 ... and 、 participle
7.1、 participle
One tokenizer( Word segmentation is ) Receive a character stream , Divide it into separate tokens( Morpheme , It's usually a separate word ), Then the output tokens flow .
## Word segmentation is
POST _analyze
{
"analyzer": "standard",
"text": "Besides traveling and volunteering, something else that’s great for when you don’t give a hoot is to read."
}
7.2、IK Word segmentation is
Download address GitHub medcl/elasticsearch-analysis-ik
## install IK Word segmentation is : Download to elasticsearch Under the plugins Under the table of contents
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.4.2/elasticsearch-analysis-ik-7.4.2.zip
## decompression
unzip elasticsearch-analysis-ik-7.4.2.zip
## Modify the permissions
chmod -R 777 ik/
## Check that it's installed
docker exec -it fcd2b /bin/bash
cd bin
elasticsearch-plugin list
## restart es
docker restart fcd2
test :
## Chinese word segmentation
POST _analyze
{
"analyzer": "ik_smart",
"text": " I'm from Hebei, China "
}
## Chinese word segmentation
POST _analyze
{
"analyzer": "ik_max_word",
"text": " I'm from Hebei, China "
}
7.3、 Custom extended Thesaurus
7.3.1、Docker install Nginx
## download nginx
docker pull nginx:1.10
## Startup and operation
docker run -p 80:80 --name nginx -d nginx:1.10
## Copy docker In the container nginx Configuration file to local
cd /opt/software/mydata/
mkdir nginx
cd nginx
mkdir html
mkdir logs
docker container cp nginx:/etc/nginx .
## Install the new nginx
docker run -p 80:80 --name nginx \
-v /opt/software/mydata/nginx/html:/usr/share/nginx/html \
-v /opt/software/mydata/nginx/logs:/var/log/nginx \
-v /opt/software/mydata/nginx/conf:/etc/nginx \
-d nginx:1.10
test :
## stay /opt/software/mydata/nginx/html Create index.html
## Content :
<h1>welcome to nginx</h1>
## Browser access
http://IP:80/
7.3.2、 Expand Thesaurus
Create a Thesaurus
## stay /opt/software/mydata/nginx/html Next create a file :es/fenci.txt
## Content :
Giobilo
Xu Jinglei
## Browser access :
http://IP/es/fenci.txt
es Related Thesaurus
## To configure es plugins Under the table of contents IK Word segmentation is conf The configuration file under the directory IKAnalyzer.cfg.xml
<!-- Users can configure the remote extended dictionary here -->
<entry key="remote_ext_dict">http:// Yours IP/es/fenci.txt</entry>
## restart es
docker restart
## test
POST _analyze
{
"analyzer": "ik_smart",
"text": " I don't know your highness gioppello "
}
版权声明
本文为[There is a little ALFY]所创,转载请带上原文链接,感谢
边栏推荐
- 明年起旧版本安卓设备将无法浏览大约30%的网页
- 高质量的缺陷分析:让自己少写 bug
- . net report builder stimulsoft Reports.Net Release the latest version of v2020.5!
- EMQ X 在中国建设银行物联网平台中的应用EMQ X 在中国建设银行物联网平台中的应用
- International top journal radiology published the latest joint results of Huawei cloud, AI assisted detection of cerebral aneurysms
- 函数计算进阶-IP查询工具开发
- 5分钟GET我使用Github 5 年总结的这些骚操作!
- On agile development concept and iterative development scheme
- 高质量的缺陷分析:让自己少写 bug
- Do you think it's easy to learn programming? In fact, it's hard! Do you think it's hard to learn programming? In fact, it's very simple!
猜你喜欢
电商/直播速看!双11跑赢李佳琦就看这款单品了!

5 minutes get I use GitHub's five-year summary of these complaints!
Equivalent judgment between floating point numbers
谈谈敏捷开发概念和迭代开发方案
How to download and install autocad2020 in Chinese
Mobile security reinforcement helps app achieve comprehensive and effective security protection
A certification and authorization solution based on. Net core - hulutong 1.0 open source

乘风破浪的技术大咖再次集结 | 腾讯云TVP持续航行中

Rongyun has completed several hundred million RMB round D financing, and will continue to build global cloud communication capability
Flink的安装和测试
随机推荐
cad教程 cad2016安装教程
International top journal radiology published the latest joint results of Huawei cloud, AI assisted detection of cerebral aneurysms
I do digital transformation in traditional industries (1)
缓存的数据一致性
用微信表情翻译表白,程序员的小浪漫,赶紧Get起来!
低功耗蓝牙单芯片为物联网助力
Why is your money transferred? This article tells you the answer
如何使用Camtasia制作动态动画场景?
拉线式位移传感器在边坡裂缝中的作用
高德全链路压测——语料智能化演进之路
详解Git
从一次需求改良漫谈php文件分片上传
5分钟GET我使用Github 5 年总结的这些骚操作!
Gesture switch background, let live with goods more immersive
设置背景图片的两种方式,并解决手机端背景图片高度自适应问题
Mobile security reinforcement helps app achieve comprehensive and effective security protection
【云小课】版本管理发展史之Git+——代码托管
手势切换背景,让直播带货更加身临其境
谷粒商城学习笔记,第五天:ES全文检索
Ultra simple integration of Huawei system integrity testing, complete equipment security protection