The following complete code can be obtained from here obtain
Stack
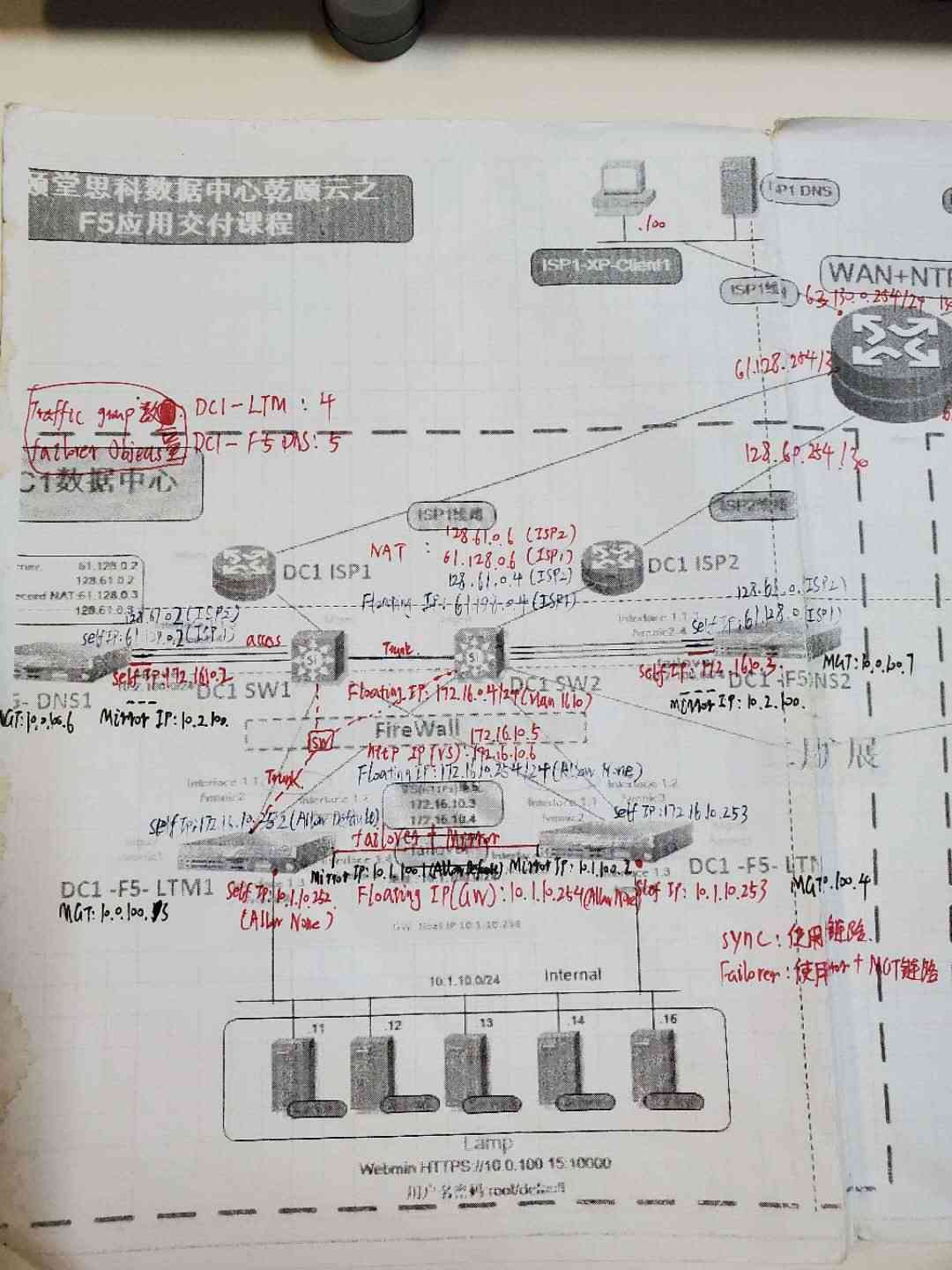
The basic concept of stack
Last in, first out 、 First in, last out is a typical stack structure . Stack can be understood as a restricted linear table , Insertion and deletion can only be done from one end
When a data set only involves inserting and deleting data at one end , And satisfy LIFO 、 Characteristics of first in and second out , Should be the first choice “ Stack ” This data structure ( Browser advances 、 Back function )
The realization of the stack
There are two main operations in a stack , Push and pull , Here, through arrays ( Order of the stack ) And the list ( Chain stack ) There are two ways to implement the stack
Order of the stack
package arrayStack
import "fmt"
type Item interface {}
type ItemStack struct {
Items []Item
N int
}
//init stack
func (stack *ItemStack) Init() *ItemStack {
stack.Items = []Item{}
return stack
}
//push stack Item
func (stack *ItemStack) Push(item Item) {
if len(stack.Items) > stack.N {
fmt.Println(" The stack is full ")
return
}
stack.Items = append(stack.Items, item)
}
//pop Item from stack
func (stack *ItemStack) Pop() Item {
if len(stack.Items) == 0 {
fmt.Println(" Stack empty ")
return nil
}
item := stack.Items[len(stack.Items) - 1]
stack.Items = stack.Items[0:len(stack.Items) - 1]
return item
}Chain stack
package linkListStack
import "fmt"
type Item interface {}
type Node struct {
Data Item
Next *Node
}
type Stack struct {
headNode *Node
}
//push Stack item
func (stack *Stack) Push(item Item) {
newNode := &Node{Data: item}
newNode.Next = stack.headNode
stack.headNode = newNode
}
//pop Item from stack
func (stack *Stack) Pop() Item {
if stack.headNode == nil {
fmt.Println(" Stack empty ")
return nil
}
item := stack.headNode.Data
stack.headNode = stack.headNode.Next
return item
}
func (stack *Stack) Traverse() {
if stack.headNode == nil {
fmt.Println(" Stack empty ")
return
}
currentNode := stack.headNode
for currentNode != nil {
fmt.Printf("%v\t", currentNode.Data)
currentNode = currentNode.Next
}
}Application scenario of stack
Call Stack
The operating system allocates an independent memory space to each thread , This memory is organized into “ Stack ” This structure , It is used to store temporary variables when calling functions . Every time a function is entered , The temporary variable will be put on the stack as a stack frame , When the called function is executed , After returning , Put the stack frame corresponding to this function out of the stacksource : The beauty of data structure and algorithm
From the execution of this code to understand the function call stack
int main() {
int a = 1;
int ret = 0;
int res = 0;
ret = add(3, 5);
res = a + ret;
printf("%d", res);
reuturn 0;
}
int add(int x, int y) {
int sum = 0;
sum = x + y;
return sum;
}main() The function is called add() function , Get calculation results , And with temporary variables a Add up , Finally print res Value . The program is in progress ,main The variables in the function will be put on the stack successively , When executed add() Function time ,add() The temporary variables in the function will also be put on the stack successively , give the result as follows :
explain : Stack in memory and data structure stack are not a concept , The stack in memory is a real physical area , The stack in a data structure is an abstract data storage structure
The application of stack in expression evaluation
An expression contains two parts , Numbers and operators . We use two stacks to implement expression evaluation , A stack is used to store numbers , A stack is used to store operators
Suppose there is such an expression
1000+5*6-6Traversing the expression from left to right , When it comes to numbers , Put the numbers in the stack where the numbers are stored ; If you encounter an operator , Remove the top element of the storage operator stack , Compare priorities
If it is higher than the top element of the operator stack , The current operator is pushed into the stack where the operator is stored ; If it is lower or the same priority than the top element of the operator stack , Take two elements from the stack where the numbers are stored , Then calculate , Put the result of the calculation into a stack of numbers . Repeat the operation above . Process diagram :
The application of stack in bracket matching
This is also a classic question , It's given a string of parentheses , Verify that it matches exactly , Such as :
{{} Mismatch
[[{()}]] matching
([{}] Mismatch This can also be solved by stack . Traversing the bracket string from left to right , An unmatched left bracket is pushed onto the stack , When the right bracket is encountered , Take a left bracket from the top of the stack , If it matches , Then continue to traverse the parentheses that follow , When the traversal is finished , The stack is empty , This indicates that the bracket string is a match , Otherwise it doesn't match . The specific implementation is as follows :
package bracketMatch
func BracketsMatch(str string) bool {
brackets := map[rune]rune{')':'(', ']':'[', '}':'['}
var stack []rune
for _, char := range str {
if char == '(' || char == '[' || char == '{' {
stack = append(stack, char)
} else if len(stack) > 0 && brackets[char] == stack[len(stack) - 1] {
stack = stack[:len(stack) - 1]
} else {
return false
}
}
return len(stack) == 0
}
queue
The basic concept of queues
FIFO is a typical queue structure , Queues can also be understood as a limited linear table , Insertion can only be done from the end of the queue , Deletion can only be done from the end of the queue . It's like queuing for tickets
There are only two basic operations of the queue , In and out of the team . The use of queues is really very extensive , Such as message queuing 、 Blocking queues 、 Circular queue, etc
Implementation of queues
There are two ways to achieve queues , The sequential queue is realized by array , Through the linked list to realize the chain queue
Two pointers are required to implement the queue , One points to the head of the queue , One points to the end of the queue
Sequential queue
package arrayQueue
import "fmt"
type Item interface {}
type Queue struct {
Queue []Item
Length int
}
func (queue *Queue) Init() {
queue.Queue = []Item{}
}
func (queue *Queue) Enqueue(data Item) {
if len(queue.Queue) > queue.Length {
fmt.Println(" The queue is full ")
return
}
queue.Queue = append(queue.Queue, data)
}
func (queue *Queue) Dequeue() Item {
if len(queue.Queue) == 0 {
fmt.Println(" The queue is empty ")
return nil
}
item := queue.Queue[0]
queue.Queue = queue.Queue[1:]
return item
}Chain queues
package linkListQueue
import "fmt"
type Item interface {}
type Node struct {
Data Item
Next *Node
}
type Queue struct {
headNode *Node
}
func (queue *Queue) Enqueue(data Item) {
node := &Node{Data: data}
if queue.headNode == nil {
queue.headNode = node
} else {
currentNode := queue.headNode
for currentNode.Next != nil {
currentNode = currentNode.Next
}
currentNode.Next = node
}
}
func (queue *Queue) Dequeue() Item {
if queue.headNode == nil {
fmt.Println(" The queue is empty ")
return nil
}
item := queue.headNode.Data
queue.headNode = queue.headNode.Next
return item
}
func (queue *Queue) Traverse() {
if queue.headNode == nil {
fmt.Println(" The queue is empty ")
return
}
currentNode := queue.headNode
for currentNode.Next != nil {
fmt.Printf("%v\t", currentNode.Data)
currentNode = currentNode.Next
}
fmt.Printf("%v\t", currentNode.Data)
}Circular queue
Why is there a circular queue ?
Look at this situation , I have a length that is 5 Queues , The queue is full at the moment . Suppose I take it out of the head of the team now 3 After elements , Want to put data in the queue again , It can't be put in , Now there's a problem , The queue has free space , But you can't put data into the queue 
One of the solutions is , Data movement . But in that case , Every time we leave the team, we say that the index of the array is deleted 0 The elements of , And move all the data behind it forward , As a result, the time complexity of the team will be changed from the original O(1) become O(n), This method is obviously not desirable 
The second way is to use a Circular queue , It's obviously a ring , This is as like as two peas . What's the specific , Everyone should be very clear , The difficulty is to judge empty and full
When the queue is empty :tail == head
When the queue is full :(tail+1)%n == headAh , Find the rules , No, just remember it , Let's take a look at how to achieve
Implementation of circular queue
package loopQueue
import "fmt"
type Item interface {}
const QueueSize = 5
type LoopQueue struct {
Items [QueueSize]Item
Head int
Tail int
}
//init
func (queue *LoopQueue) Init() {
queue.Head = 0
queue.Tail = 0
}
//enqueue
func (queue *LoopQueue) Enqueue(data Item) {
if ((queue.Tail + 1) % QueueSize) == queue.Head {
fmt.Println(" The queue is full ")
}
queue.Items[queue.Tail] = data
queue.Tail = (queue.Tail+1) % QueueSize
}
//dequeue
func (queue *LoopQueue) Dequeue() Item {
if queue.Head == queue.Tail {
fmt.Println(" The queue is empty ")
return nil
}
item := queue.Items[queue.Head]
queue.Head = (queue.Head + 1) % QueueSize
return item
}
Application scenarios of queues
Blocking queues and concurrent queues
Blocking queues
in application , The queue won't be infinite , Once the queue has a length limit , There will be a full time , When the line is full , Queuing operations will be blocked , Because there's no data to take . And when the queue is empty , Out of the team is blocked , Until there is data available in the queue
you 're right , Usually used producer - Consumer model this is it , A producer can be easily implemented through queues - Consumer model
Based on the blocking queue , You can also adjust “ producer ” and “ consumer ” The number of , To improve the efficiency of data processing
Concurrent queues
For the blocking queue above , In the case of multithreading , There will be multiple threads working on the queue at the same time , At this time, there will be thread safety problems ( If you want to understand the underlying causes , You can see my article : Process synchronization in process management )
The queue that guarantees thread safety is called concurrent queue , The easiest way is to lock in and out of the team . About locks , You can also see my series here : Thread lock series

Reference material :
- The beauty of data structure and algorithm
- Learning data structures from zero