当前位置:网站首页>Dynamic ReLU:微软推出提点神器,可能是最好的ReLU改进 | ECCV 2020
Dynamic ReLU:微软推出提点神器,可能是最好的ReLU改进 | ECCV 2020
2020-11-08 21:03:00 【晓飞的算法工程笔记】
> 论文提出了动态ReLU,能够根据输入动态地调整对应的分段激活函数,与ReLU及其变种对比,仅需额外的少量计算即可带来大幅的性能提升,能无缝嵌入到当前的主流模型中
来源:晓飞的算法工程笔记 公众号
论文: Dynamic ReLU

Introduction
ReLU是深度学习中很重要的里程碑,简单但强大,能够极大地提升神经网络的性能。目前也有很多ReLU的改进版,比如Leaky ReLU和 PReLU,而这些改进版和原版的最终参数都是固定的。所以论文自然而然地想到,如果能够根据输入特征来调整ReLU的参数可能会更好。

基于上面的想法,论文提出了动态ReLU(DY-ReLU)。如图2所示,DY-ReLU是一个分段函数$f_{\theta{(x)}}(x)$,参数由超函数$\theta{(x)}$根据输入$x$得到。超函数$\theta(x)$综合输入的各维度上下文来自适应激活函数$f_{\theta{(x)}}(x)$,能够在带来少量额外计算的情况下,显著地提高网络的表达能力。另外,论文提供了三种形态的DY-ReLU,在空间位置和维度上有不同的共享机制。不同形态的DY-ReLU适用于不同的任务,论文也通过实验验证,DY-ReLU在关键点识别和图像分类上均有不错的提升。
Definition and Implementation of Dynamic ReLU
Definition
定义原版的ReLU为$y=max{x, 0}$,$x$为输入向量,对于输入的$c$维特征$x_c$,激活值计算为$y_c=max{x_c, 0}$。ReLU可统一表示为分段线性函数$y_c=max_k{a^k_c x_c+b^k_c}$,论文基于这个分段函数扩展出动态ReLU,基于所有的输入$x={x_c}$自适应$a^k_c$,$b^k_c$:
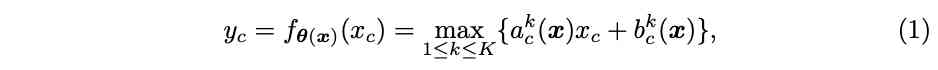
因子$(a^k_c, b^k_c)$为超函数$\theta(x)$的输出:

$K$为函数数量,$C$为维度数,激活参数$(a^k_c, b^k_c)$不仅与$x_c$相关,也与$x_{j\ne c}$相关。
Implementation of hyper function $\theta(x)$
论文采用类似与SE模块的轻量级网络进行超函数的实现,对于大小为$C\times H\times W$的输入$x$,首先使用全局平均池化进行压缩,然后使用两个全连接层(中间包含ReLU)进行处理,最后接一个归一化层将结果约束在-1和1之间,归一化层使用$2\sigma(x) - 1$,$\sigma$为Sigmoid函数。子网共输出$2KC$个元素,分别对应$a^{1:K}{1:C}$和$b^{1:K}{1:C}$的残差,最终的输出为初始值和残差之和:

$\alpha^k$和$\beta^k$为$a^k_c$和$b^k_c$的初始值,$\lambda_a$和$\lambda_b$是用来控制残差大小的标量。对于$K=2$的情况,默认参数为$\alpha^1=1$,$\alpha^2=\beta^1=\beta^2=0$,即为原版ReLU,标量默认为$\lambda_a=1.0$,$\lambda_b=0.5$。
Relation to Prior Work
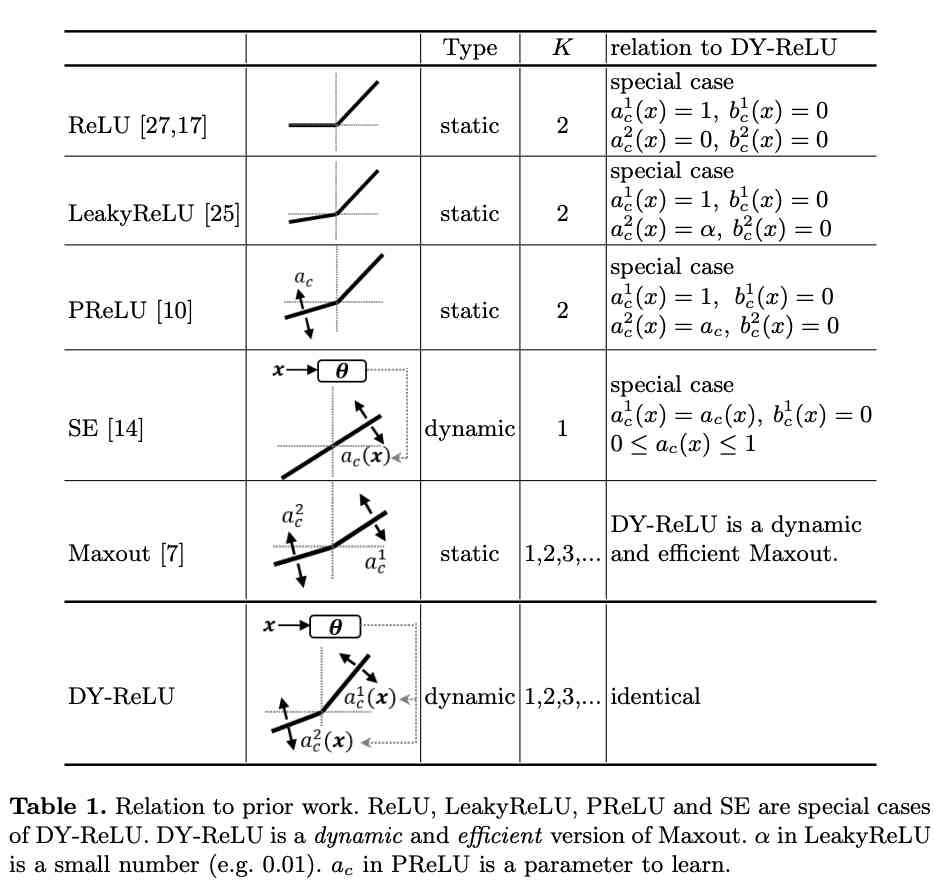
DY-ReLU的可能性很大,表1展示了DY-ReLU与原版ReLU以及其变种的关系。在学习到特定的参数后,DY-ReLU可等价于ReLU、LeakyReLU以及PReLU。而当$K=1$,偏置$b^1_c=0$时,则等价于SE模块。另外DY-ReLU也可以是一个动态且高效的Maxout算子,相当于将Maxout的$K$个卷积转换为$K$个动态的线性变化,然后同样地输出最大值。
Variations of Dynamic ReLU
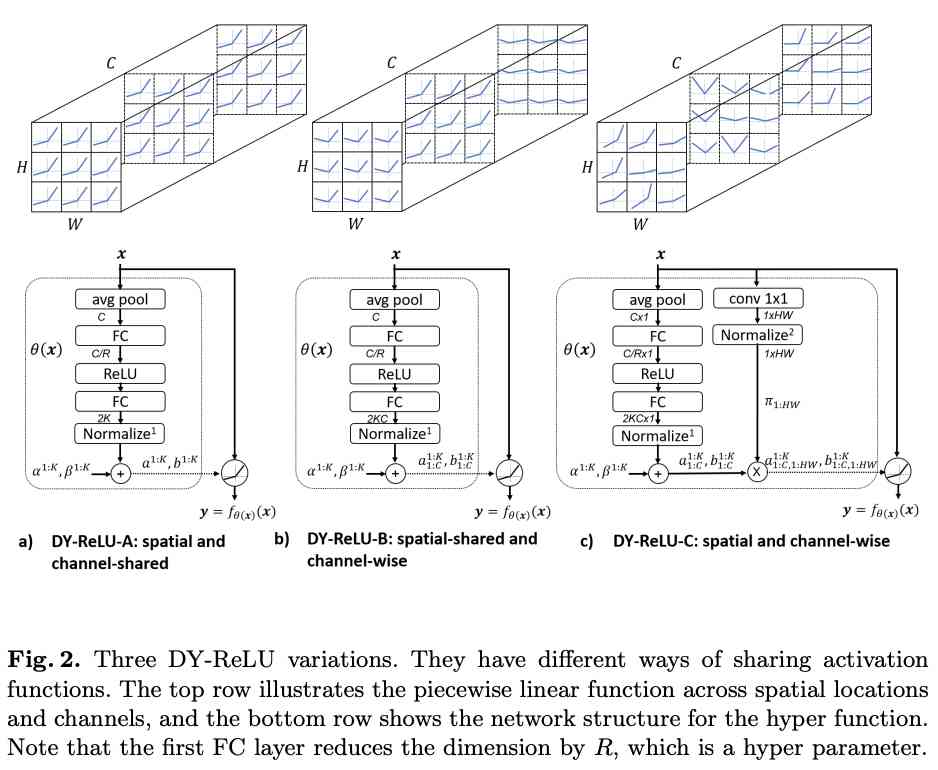
论文提供了三种形态的DY-ReLU,在空间位置和维度上有不同的共享机制:
DY-ReLU-A
空间位置和维度均共享(spatial and channel-shared),计算如图2a所示,仅需输出$2K$个参数,计算最简单,表达能力也最弱。
DY-ReLU-B
仅空间位置共享(spatial-shared and channel-wise),计算如图2b所示,输出$2KC$个参数。
DY-ReLU-C
空间位置和维度均不共享(spatial and channel-wise),每个维度的每个元素都有对应的激活函数$max_k{a^k_{c,h,w} x_{c, h, w} + b^k_{c,h,w} }$。虽然表达能力很强,但需要输出的参数($2KCHW$)太多了,像前面那要直接用全连接层输出会带来过多的额外计算。为此论文进行了改进,计算如图2c所示,将空间位置分解到另一个attention分支,最后将维度参数$[a^{1:K}{1:C}, b^{1:K}{1:C}]$乘以空间位置attention$[\pi_{1:HW}]$。attention的计算简单地使用$1\times 1$卷积和归一化方法,归一化使用了带约束的softmax函数:
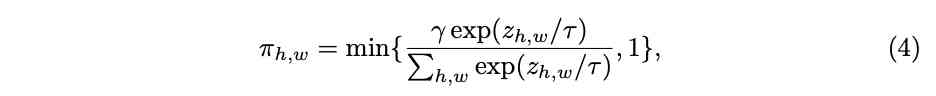
$\gamma$用于将attention平均,论文设为$\frac{HW}{3}$,$\tau$为温度,训练前期设较大的值(10)用于防止attention过于稀疏。
Experimental Results
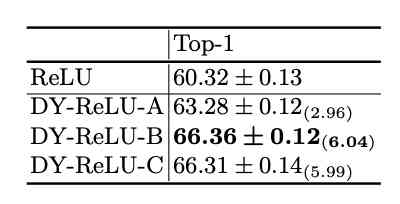
图像分类对比实验。
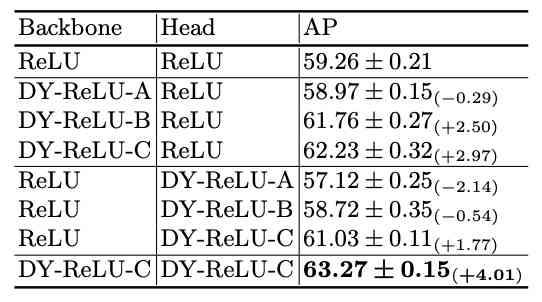
关键点识别对比实验。
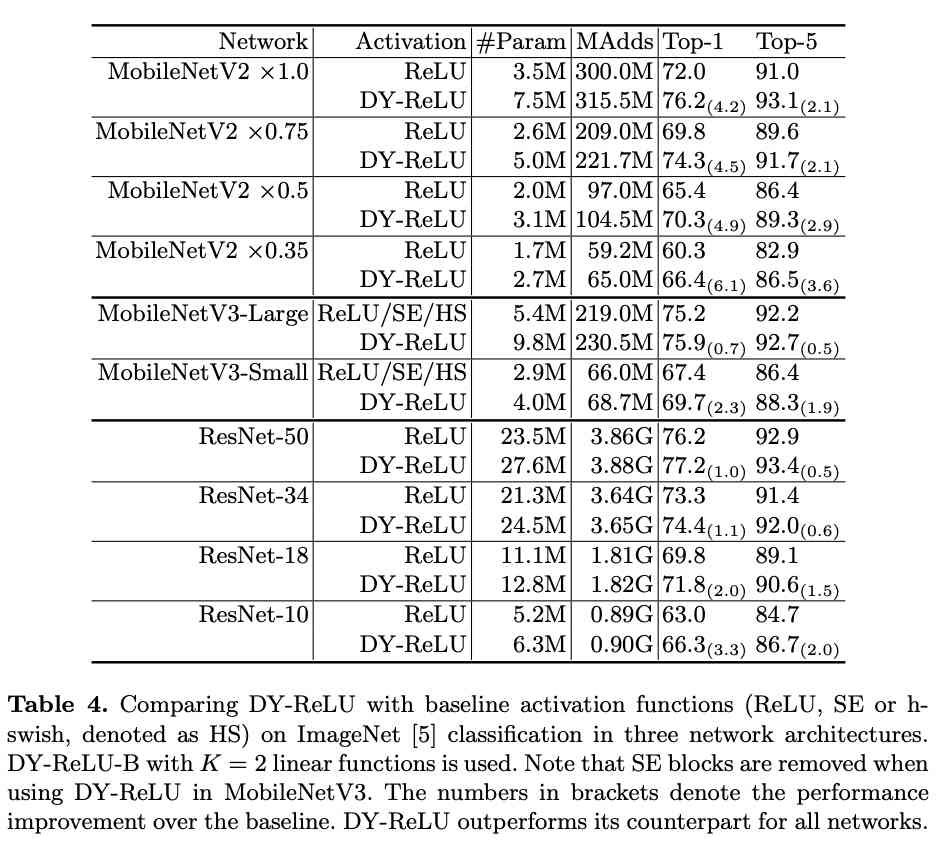
与ReLU在ImageNet上进行多方面对比。
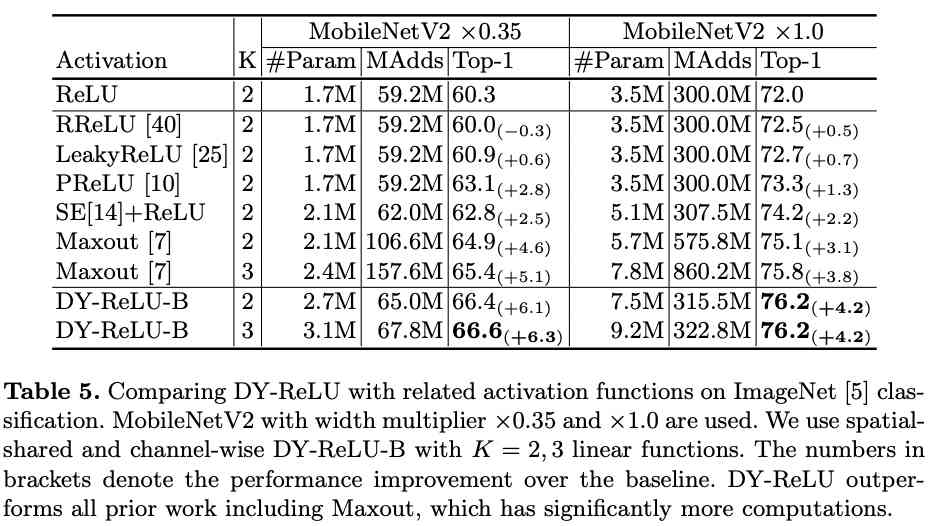
与其它激活函数进行实验对比。
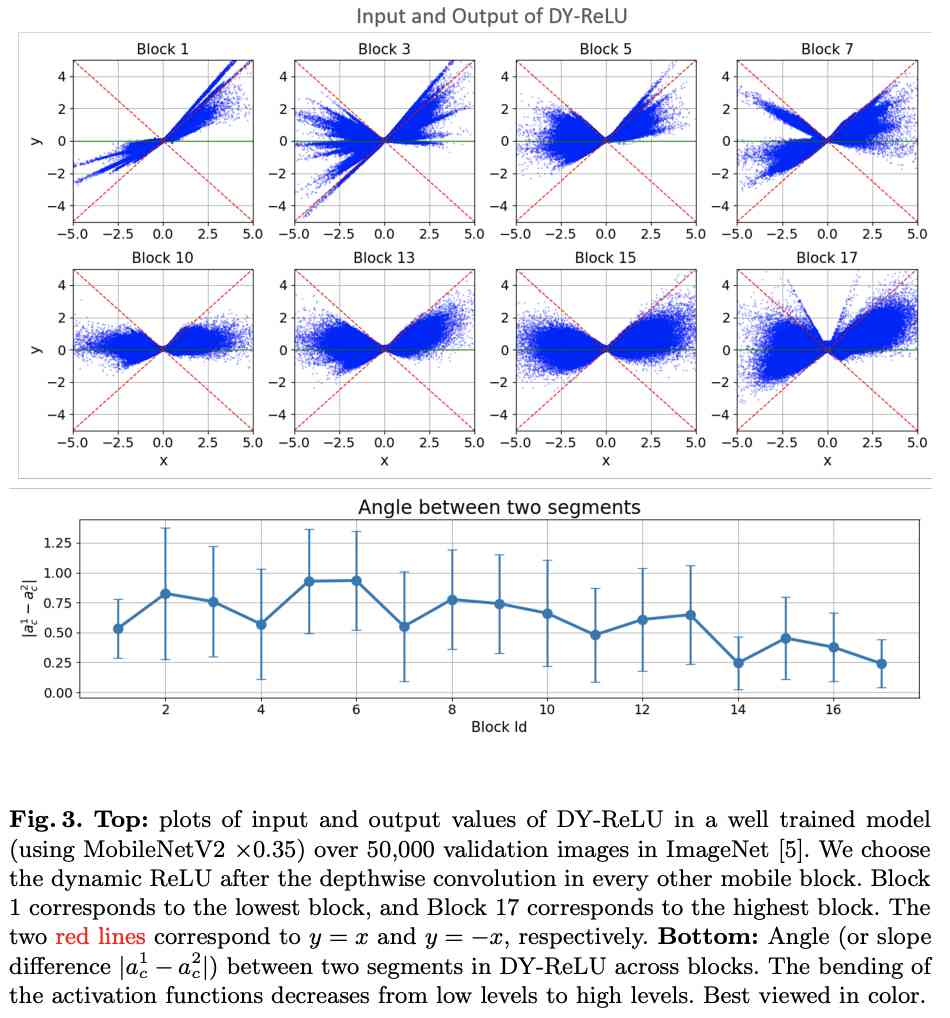
可视化DY-ReLU在不同block的输入输出以及斜率变化,可看出其动态性。
Conclustion
论文提出了动态ReLU,能够根据输入动态地调整对应的分段激活函数,与ReLU及其变种对比,仅需额外的少量计算即可带来巨大的性能提升,能无缝嵌入到当前的主流模型中。前面有提到一篇APReLU,也是做动态ReLU,子网结构十分相似,但DY-ReLU由于$max_{1\le k \le K}$的存在,可能性和效果比APReLU更大。
> 如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

版权声明
本文为[晓飞的算法工程笔记]所创,转载请带上原文链接,感谢
https://my.oschina.net/u/4490761/blog/4708282
边栏推荐
猜你喜欢

新手入坑指南:工作原因“重启”Deepin系统,发现真的香啊
动态规划设计:最大子数组
Part I - Chapter 1 Overview
experiment
动态规划答疑篇
Brief introduction of Integrated Architecture
Python 列表的11个重要操作
Not a programmer, code can't be too ugly! The official writing standard of Python: pep8 everyone should know
Proficient in high concurrency and multithreading, but can't use ThreadLocal?

都说程序员钱多空少,程序员真的忙到没时间回信息了吗?
随机推荐
Part I - Chapter 1 Overview
Solve the failure of go get download package
LeetCode 45 跳跃游戏II
CMS garbage collector
Django之简易用户系统(3)
Regular backup of WordPress website program and database to qiniu cloud
npm install 无响应解决方案
Five design schemes of singleton mode
线程池运用不当的一次线上事故
PAT_ Grade A_ 1056 Mice and Rice
How to deploy pytorch lightning model to production
net.sf.json.JSONObject对时间戳的格式化处理
寻找性能更优秀的不可变小字典
Development and deployment of image classifier application with fastai
使用Fastai开发和部署图像分类器应用
CMS垃圾收集器
EntityFramework Core上下文实例池原理分析
快来看看!AQS 和 CountDownLatch 有怎么样的关系?
To introduce to you, this is my flow chart software—— draw.io
使用基于GAN的过采样技术提高非平衡COVID-19死亡率预测的模型准确性