The paper puts forward the dynamic ReLU, It can dynamically adjust the corresponding segment activation function according to the input , And ReLU And its variety contrast , Only a small amount of extra computation can lead to a significant performance improvement , It can be embedded into the current mainstream model seamlessly
source : Xiaofei's algorithm Engineering Notes official account
The paper : Dynamic ReLU

- Address of thesis :https://arxiv.org/abs/2003.10027
- Paper code :https://github.com/Islanna/DynamicReLU
Introduction
ReLU It's a very important milestone in deep learning , Simple but powerful , It can greatly improve the performance of neural networks . There are a lot of ReLU Improved version , such as Leaky ReLU and PReLU, And the final parameters of the improved version and the original version are fixed . So the paper naturally thought of , If you can adjust according to the input characteristics ReLU Parameters of might be better .

Based on the above ideas , The paper puts forward the dynamic ReLU(DY-ReLU). Pictured 2 Shown ,DY-ReLU It's a piecewise function $f_{\theta{(x)}}(x)$, Parameters are defined by the hyperfunction $\theta{(x)}$ According to input $x$ obtain . Hyperfunctions $\theta(x)$ The context of each dimension of the integrated input comes from the adaptation activation function $f_{\theta{(x)}}(x)$, Can bring a small amount of extra computation , Significantly improve the expression of the network . in addition , This paper provides three forms of DY-ReLU, There are different sharing mechanisms in spatial location and dimension . Different forms of DY-ReLU For different tasks , The paper is also verified by experiments ,DY-ReLU In the key point recognition and image classification have a good improvement .
Definition and Implementation of Dynamic ReLU
Definition
Define the original ReLU by $y=max{x, 0}$,$x$ Is the input vector , For the input $c$ Whitman's sign $x_c$, The activation value is calculated as $y_c=max{x_c, 0}$.ReLU It can be expressed as piecewise linear function $y_c=max_k{a^k_c x_c+bk_c}$, Based on this piecewise function, this paper extends dynamic ReLU, Based on all the inputs $x={x_c}$ The adaptive $ak_c$,$b^k_c$:
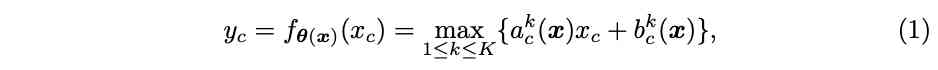
factor $(a^k_c, b^k_c)$ It's a hyperfunction $\theta(x)$ Output :

$K$ Is the number of functions ,$C$ Is the number of dimensions , Activation parameters $(a^k_c, b^k_c)$ Not only with $x_c$ relevant , Also with the $x_{j\ne c}$ relevant .
Implementation of hyper function $\theta(x)$
This paper adopts the method similar to SE Module lightweight network for the implementation of hyperfunctions , For size $C\times H\times W$ The input of $x$, First, use global average pooling for compression , Then use two full connection layers ( The middle contains ReLU) To deal with , Finally, a normalization layer is used to constrain the results to -1 and 1 Between , The normalization layer uses $2\sigma(x) - 1$,$\sigma$ by Sigmoid function . The subnet has a common output $2KC$ Elements , They correspond to each other $a{1:K}_{1:C}$ and $b{1:K}_{1:C}$ Residual of , The final output is the sum of the initial value and the residual error :

$\alphak$ and $\betak$ by $ak_c$ and $bk_c$ The initial value of the ,$\lambda_a$ and $\lambda_b$ Is the scalar used to control the size of the residual . about $K=2$ The situation of , The default parameter is $\alpha1=1$,$\alpha2=\beta1=\beta2=0$, It's the original ReLU, Scalar defaults to $\lambda_a=1.0$,$\lambda_b=0.5$.
Relation to Prior Work
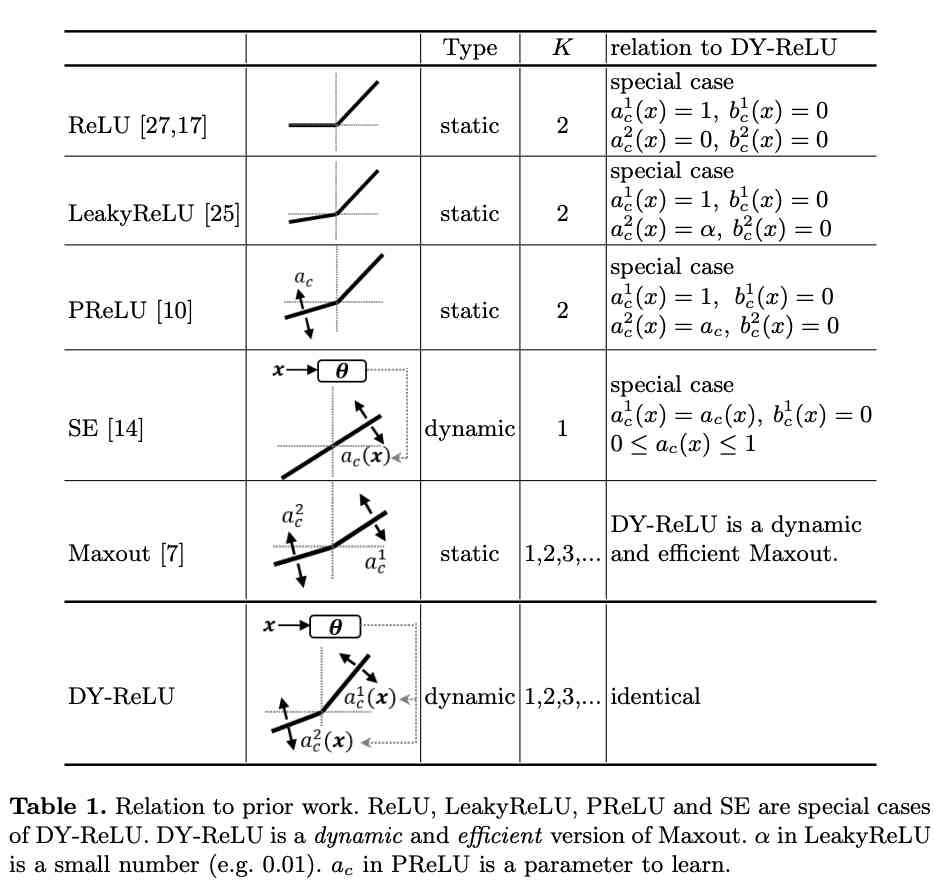
DY-ReLU There's a lot of possibility , surface 1 It shows DY-ReLU With the original ReLU And the relationship between its variants . After learning the specific parameters ,DY-ReLU It is equivalent to ReLU、LeakyReLU as well as PReLU. And when $K=1$, bias $b^1_c=0$ when , Is equivalent to SE modular . in addition DY-ReLU It can also be a dynamic and efficient Maxout operator , Is equivalent to Maxout Of $K$ Convolutions are converted to $K$ A dynamic linear change , And then output the maximum again .
Variations of Dynamic ReLU
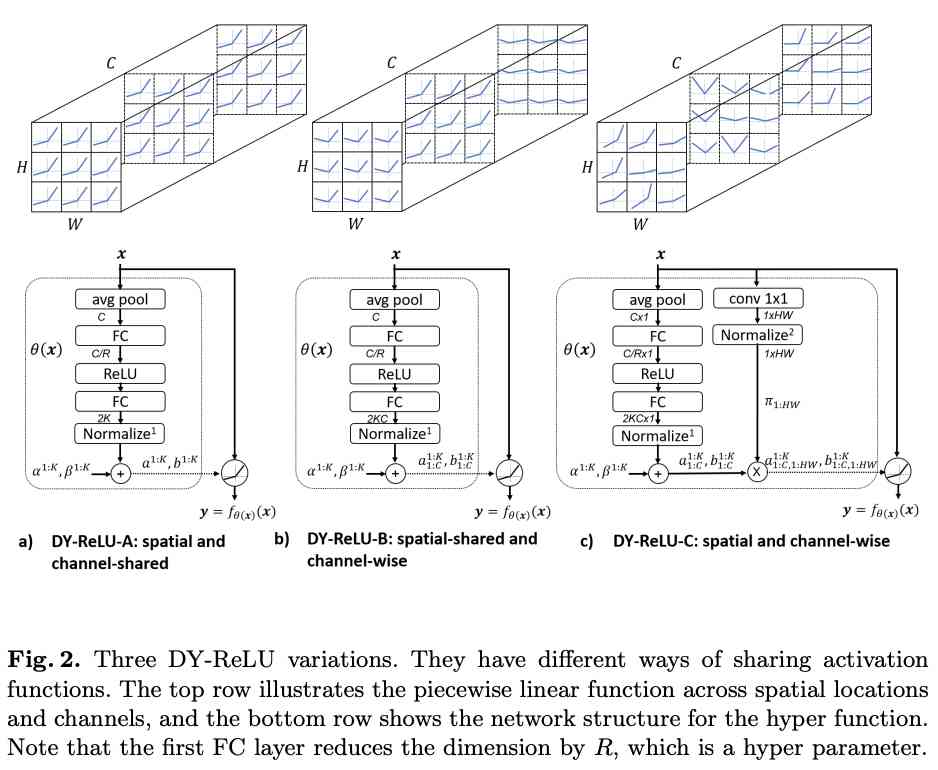
This paper provides three forms of DY-ReLU, There are different sharing mechanisms in spatial location and dimension :
DY-ReLU-A
Spatial location and dimensions are shared (spatial and channel-shared), The calculation is shown in the figure 2a Shown , Just output $2K$ Parameters , The calculation is the simplest , Expression is also the weakest .
DY-ReLU-B
Only spatial location sharing (spatial-shared and channel-wise), The calculation is shown in the figure 2b Shown , Output $2KC$ Parameters .
DY-ReLU-C
Spatial location and dimensions are not shared (spatial and channel-wise), Each element of each dimension has a corresponding activation function $max_k{a^k_{c,h,w} x_{c, h, w} + b^k_{c,h,w} }$. Although it's very expressive , But the parameters that need to be output ($2KCHW$) That's too much , Like the previous one, using full connection layer output directly will bring too much extra computation . Therefore, the paper has been improved , The calculation is shown in the figure 2c Shown , Decompose the spatial location to another attention Branch , Finally, the dimension parameter $[a^{1:K}{1:C}, b^{1:K}{1:C}]$ Multiply by the space position attention$[\pi_{1:HW}]$.attention The calculation of is simple to use $1\times 1$ Convolution and normalization methods , Normalization uses constrained softmax function :
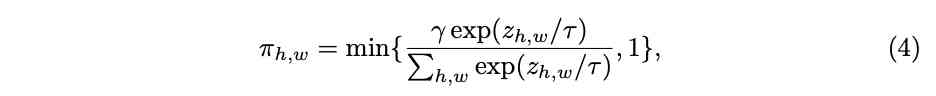
$\gamma$ Is used to attention Average , The paper is set as $\frac{HW}{3}$,$\tau$ Is the temperature , Set a larger value at the beginning of training (10) Used to prevent attention Too sparse .
Experimental Results
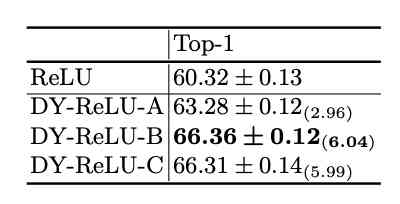
Image classification and contrast experiment .
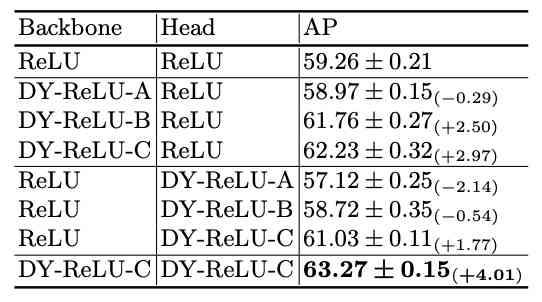
Key point recognition contrast experiment .
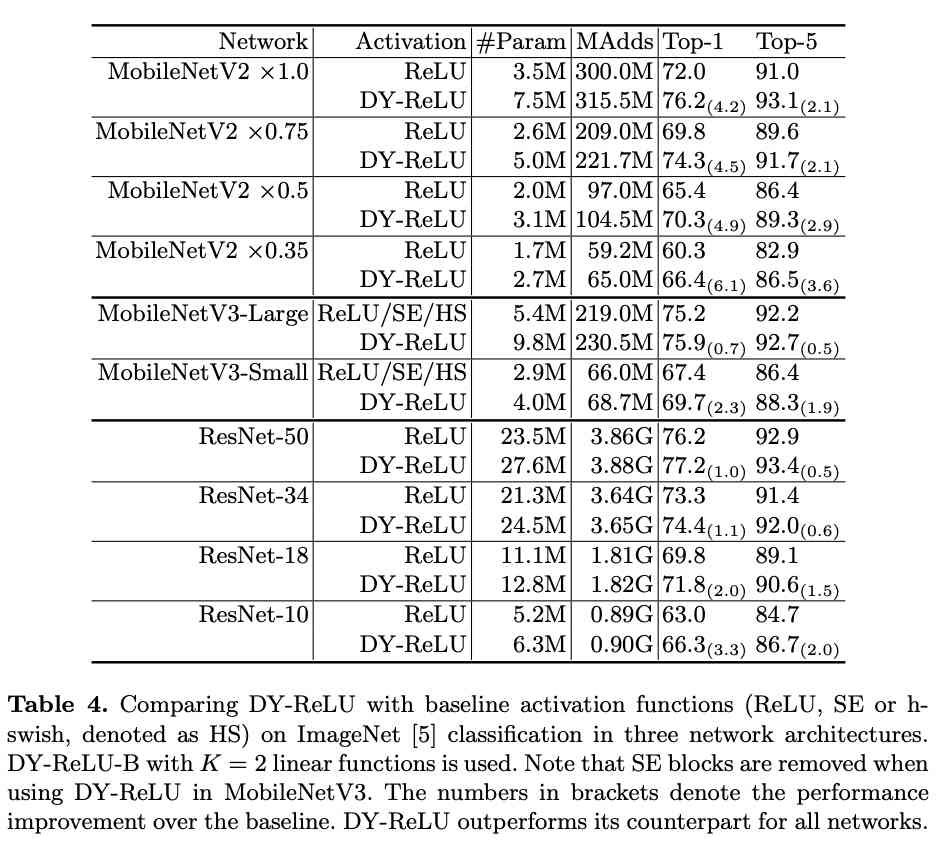
And ReLU stay ImageNet Compare in many ways .
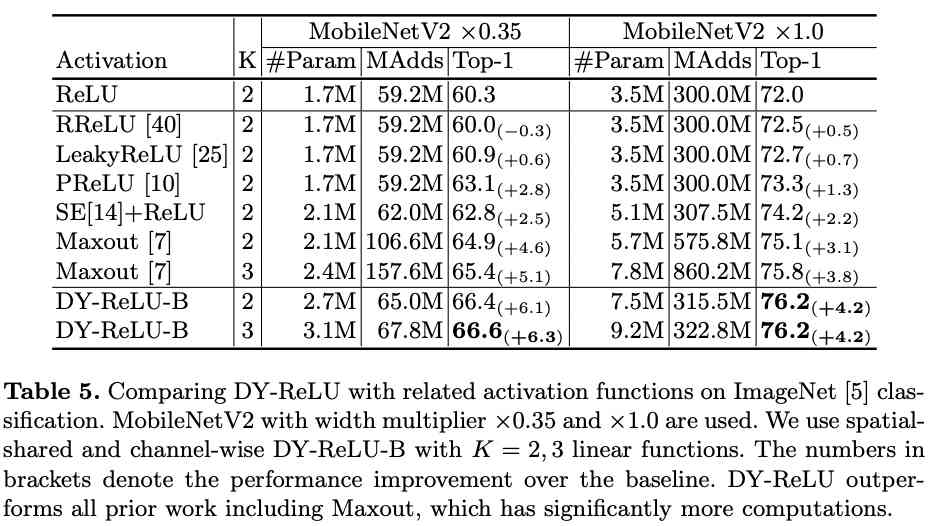
Compared with other activation functions .
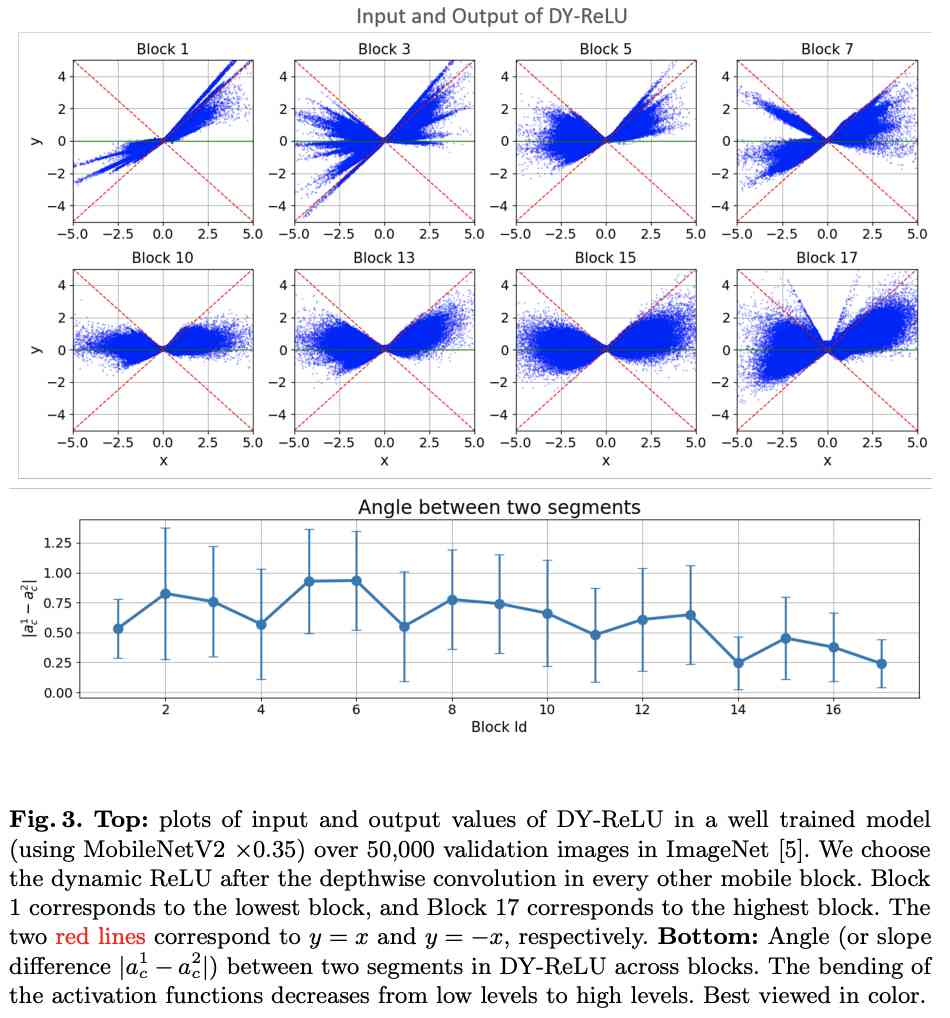
visualization DY-ReLU In different block I / O and slope change , We can see its dynamic nature .
Conclustion
The paper puts forward the dynamic ReLU, It can dynamically adjust the corresponding segment activation function according to the input , And ReLU And its variety contrast , Only a small amount of extra computation can bring about huge performance improvement , It can be embedded into the current mainstream model seamlessly . There is a reference to APReLU, It's also dynamic ReLU, The subnet structure is very similar , but DY-ReLU because $max_{1\le k \le K}$ The existence of , The possibility and the effect are better than APReLU Bigger .
If this article helps you , Please give me a compliment or watch it ~
More on this WeChat official account 【 Xiaofei's algorithm Engineering Notes 】