当前位置:网站首页>用TensorFlow预测纽约市AirBnB租赁价格
用TensorFlow预测纽约市AirBnB租赁价格
2020-11-06 01:14:00 【人工智能遇见磐创】

作者|TIMOTHY102 编译|VK 来源|Analytics Vidhya
介绍
Airbnb是一个在线市场,允许人们将自己的房产或空余房间出租给客人。每预订3位客人,收取12%和6%的佣金。
该公司自2009年成立以来,已从每年帮助2.1万名客人找到住处,发展到每年帮助600万人度假,目前在90个不同国家的34000个城市列出了惊人的80万套房产。
在本文中,我将使用Kaggle-newyorkcityairbnb开放数据集,尝试用TensorFlow建立一个神经网络模型来进行预测。
目标是建立一个合适的机器学习模型,能够预测未来住宿数据的价格。
在本文中,我将展示我创建的Jupyter Notebook。你可以在GitHub上找到它:https://github.com/Timothy102/Tensorflow-for-Airbnb-Prices
加载数据
首先,让我们看看如何加载数据。我们用wget直接从Kaggle网站上获取数据。注意-o标志表示文件名。
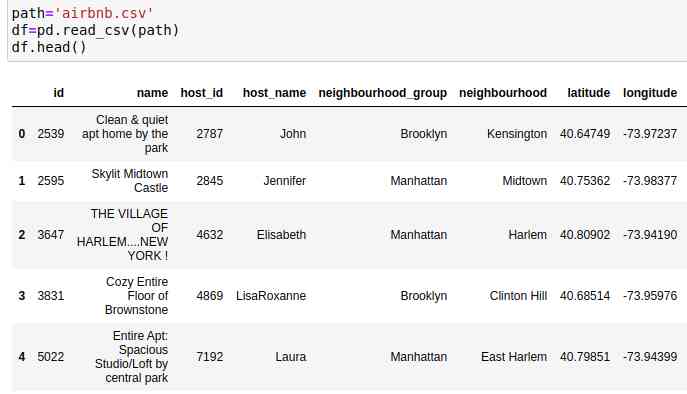
数据集应该如下所示。共有48895行16列。
数据分析与预处理
Seaborn有一个非常简洁的API,可以为各种数据绘制各种图形。如果你对语法不太熟悉,可以查看本文:https://www.analyticsvidhya.com/blog/2019/09/comprehensive-data-visualization-guide-seaborn-python/
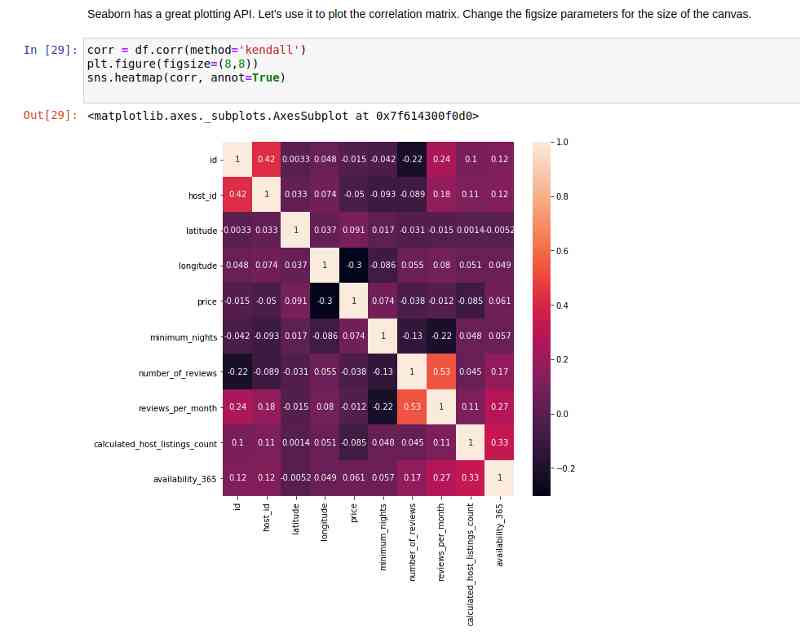
在pandas数据帧上使用corr之后,我们将其传递给一个heatmap函数。结果如下:
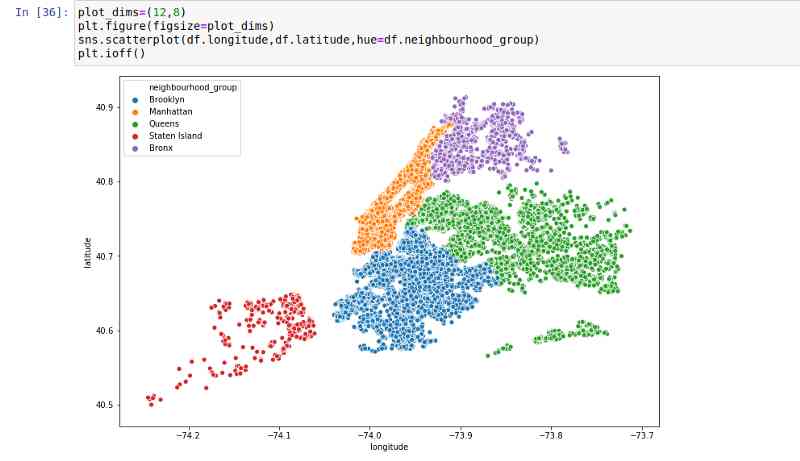
既然我们有经度和经度以及邻里数据,让我们创建一个散点图:
此外,我删除了重复项和一些不必要的列,并填写了“reviews_per_month”,因为它有太多的缺失值。数据看起来像这样。它有10列,没有零值:
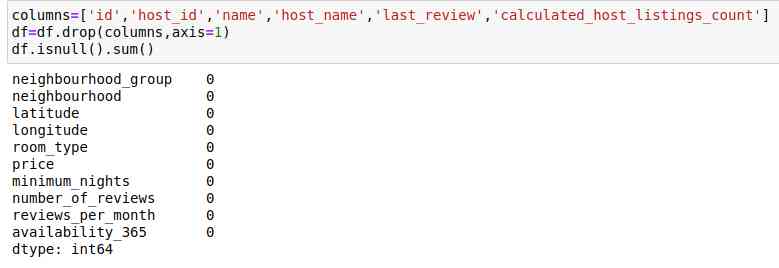
很好,对吧?
首先,电脑是做数字的。这就是为什么我们要把分类列转换成一个one-hot编码的向量。这是使用pandas的factorize方法完成的。你可以使用很多其他工具:
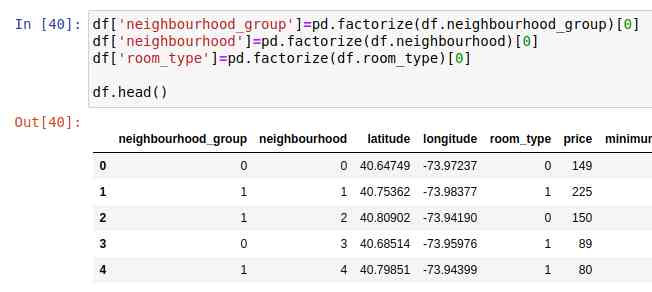
为了使损失函数保持在稳定的范围内,让我们对一些数据进行规范化,使平均值为0,标准差为1。
特征交叉
我们必须做出一个改变,这是一个必不可少的改变。为了使经度和纬度与模型输出相关联,我们必须创建一个特征交叉。下面的链接应该为你提供足够的背景知识,使你能够正确地感受到特征交叉:
- https://developers.google.com/machine-learning/crash-course/feature-crosses/video-lecture
- https://www.kaggle.com/vikramtiwari/feature-crosses-tensorflow-mlcc
我们的目标是介绍经纬度交叉,这是本书中最古老的技巧之一。如果我们只将这两列作为值放入模型,它将假定这些值与输出逐步相关。
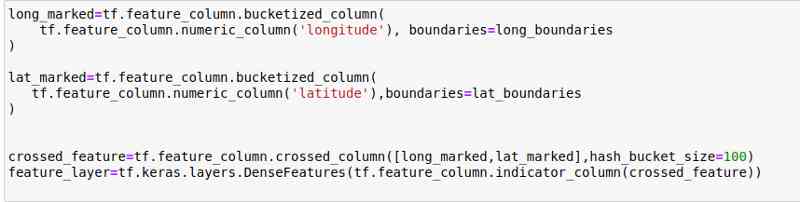
相反,我们将使用特征交叉,这意味着我们将把经度*经度地图分割成一个网格。幸运的是,TensorFlow使它变得容易。
我通过迭代(max-min)/100,从而生成一个分布均匀的帧网格。
我用的是100×100网格:

本质上,我们在这里所做的,是定义一个bucked列和前面定义的边界,并创建一个DenseFeatures层,然后将传递给Sequential API。
如果你不熟悉Tensorflow语法,请检查文档:https://www.tensorflow.org/api_docs/python/tf/feature_column/
现在,终于,我们为模型训练做好了准备。除了拆分数据部分,也就是说。

显然,我们必须创建两个数据集,一个包含所有数据,另一个包含预测得分。由于数据大小不匹配,这可能会给我们的模型带来问题,所以我决定截断太长的数据。
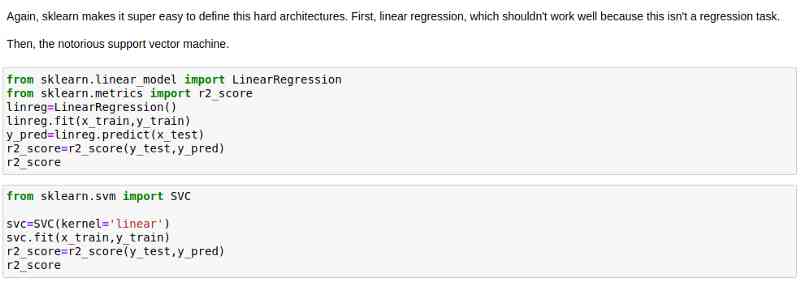
创建模型
最后,建立了Keras序列模型。
我们使用Adam优化器、均方误差损失和两个指标来编译模型。
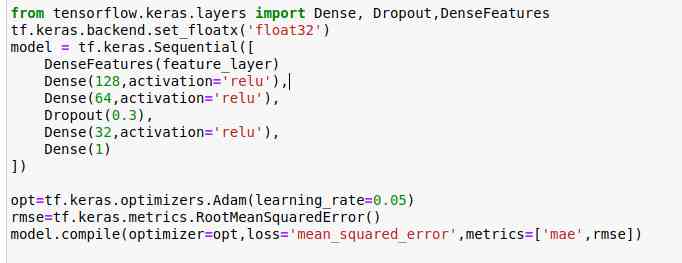
此外,我们使用两个回调:
-
早停,这是不言而喻的
-
降低高原学习率。

经过50个epoch的训练,batch大小为64,我们的模型是相当成功的。
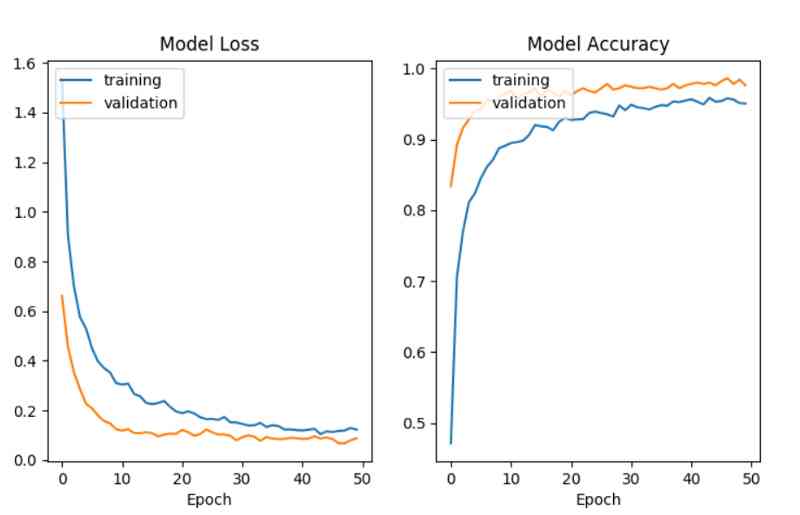
结尾
我们使用纽约市的AirBnB数据建立了一个全连接的神经网络来预测未来的价格。Pandas和seaborn使得可视化和检查数据变得非常容易。我们在模型中引入了经纬度交叉作为特征的思想。并且多亏了Kaggle的开放数据集,我们得到了一个完全可操作的机器学习模型。
原文链接:https://www.analyticsvidhya.com/blog/2020/10/predicting-nyc-airbnb-rental-prices-tensorflow/
欢迎关注磐创AI博客站: http://panchuang.net/
sklearn机器学习中文官方文档: http://sklearn123.com/
欢迎关注磐创博客资源汇总站: http://docs.panchuang.net/
版权声明
本文为[人工智能遇见磐创]所创,转载请带上原文链接,感谢
https://my.oschina.net/u/4253699/blog/4701578
边栏推荐
猜你喜欢




随机推荐
【數量技術宅|金融資料系列分享】套利策略的價差序列計算,恐怕沒有你想的那麼簡單
自然语言处理之分词、命名主体识别、词性、语法分析-stanfordcorenlp-NER(二)
Probabilistic linear regression with uncertain weights
用git2consul从Git同步配置到Consul
Gradient understanding decline
为什么民营企业要做党建?——极客邦控股党支部专题学习
NodeJs爬虫抓取古代典籍,共计16000个页面心得体会总结及项目分享
阿里CCO项目组面试的思考
一文带你了解 Jest 单元测试
使用ES5实现ES6的Class
键盘录入抽奖人随机抽奖
Using tensorflow to forecast the rental price of airbnb in New York City
vite + ts 快速搭建 vue3 專案 以及介紹相關特性
别走!这里有个笔记:图文讲解 AQS ,一起看看 AQS 的源码……(图文较长)
JVM内存区域与垃圾回收
通用的底层埋点都是怎么做的?
互联网 舆情系统的架构实践
十二因子原则和云原生微服务 - DZone
經典動態規劃:完全揹包問題
基于 Flink SQL CDC 的实时数据同步方案