当前位置:网站首页>Transformer model (pytorch code explanation)
Transformer model (pytorch code explanation)
2022-07-06 19:42:00 【Unstoppable~~~】
Catalog
Transformer
Basic introduction of the model
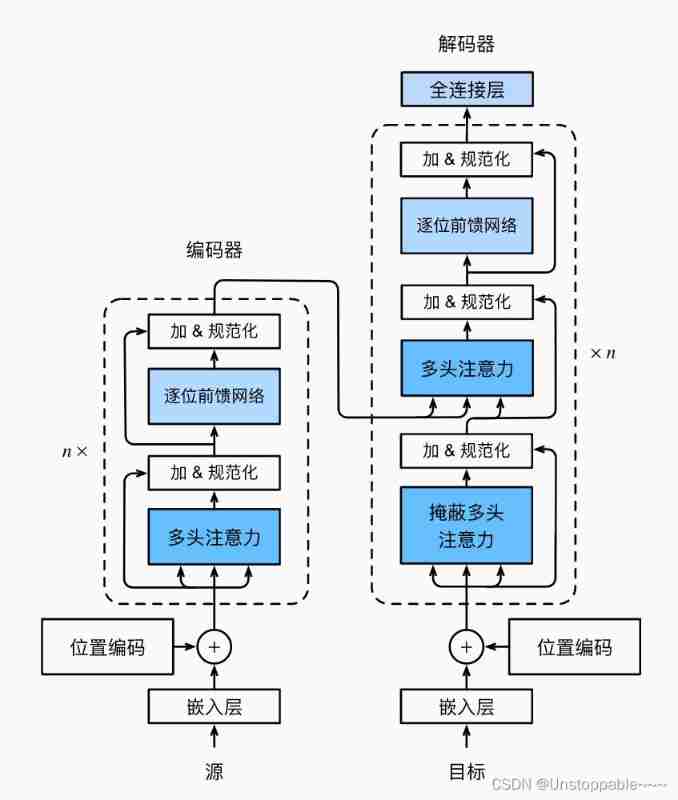
And seq2seq comparison transformer Is a purely attention based architecture ( Self attention has two advantages: parallel computing and the shortest maximum path length ), There's no use for CNN and RNN.
As shown in the figure below ,transformer By Encoder and decoder Composed of .transformer The encoder and decoder of are Based on the superposition of self attention modules , Source ( Input ) Sequence and target ( Output ) Sequential Embedded representation Add Location code , Then input to the encoder and decoder respectively .
Long attention
The same key,value,query, Hope to extract different information
- Such as short-distance relationship and long-distance relationship ( It is similar to the multi output channel in convolution )
Long attention use h An independent attention pool
- Merge headers (head) Output to get the final result
Specific ideas :
We can learn by ourselves h Different groups Linear projection To transform the query 、 Key and value . then , this h Query after group transformation 、 Keys and values will be sent to attention gathering in parallel . Last , Will this h The output of attention gathering Splice together , And transform through another linear projection that can be learned , To produce the final output . This design is called multi headed attention :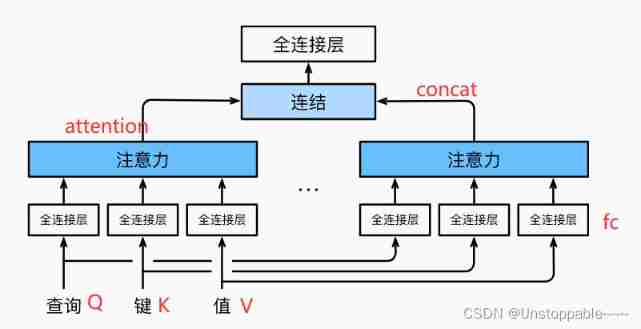
Model :

As shown above , Additional learnable parameters are added W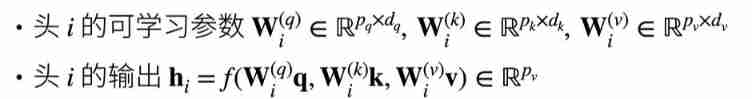
This parameter will query From the dimension of Dq It maps to Pq, take key From the dimension of Dq It maps to Kq, take value From the dimension of Dq It maps to Vq.( This mapping usually reduces the number )
Finally, the output learnable parameters Wo And hi Multiply the splicing results to get the output of multiple attention (Po)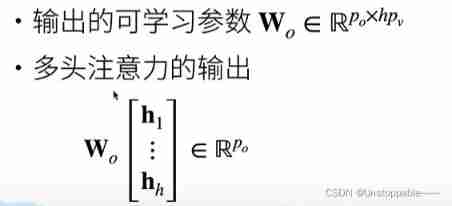
Masked bull attention
decoder When outputting to an element in the sequence , Elements after this element should not be considered
This can be achieved through a mask
- That is, calculating Xi When the output , Pretend that the current sequence length is i( take i Later content covers / Masking )
Position based feedforward network
The essence is a full connection layer
Enter the shape from (b, n, d) Change to (bn, d)b by batch_size n Is the length of the sequence d For the characteristic dimension
Act on two fully connected layers
The output shape consists of (bn, d) Change back to (b, n, d)
Equivalent to two-layer kernel window is 1 One dimensional convolution of
Layer normalization
Batch normalization for each feature / Normalize the elements in the channel ( Variance changes 1 The mean value changes 0)
- Unsuitable sequence length will become nlp application (bn in n The length of the sequence is constantly changing )
Layer normalization normalizes the elements of each sample 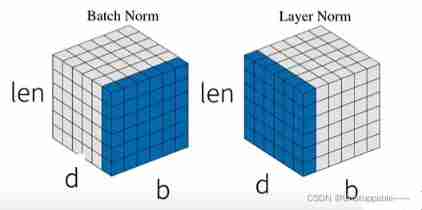
As shown in the figure above :
Batch Normalization Dealing with d Each of them b*len Matrix ( The blue part in the left figure ) Variance changes 1 The mean value changes 0. The operation scope is in each feature dimension .
Layer Normalization It deals with every batch Medium len*d Matrix ( The blue part on the right ) Variance changes 1 The mean value changes 0. The operating range is within a single sample . When changing the length, it is BN A more stable
Information transmission ( The line connecting the decoder and encoder in the corresponding structure diagram )
Output in encoder y1…yn
Take it as the... In decoding i individual Transformer The attention of the bulls in the block key and value(query From the target sequence )
It means that the number and output dimension of blocks in encoder and decoder are the same
forecast
In the forecast t+1 One output , Before input in the decoder t Predicted values ( In self attention , front t A prediction is used as key and value, The first t A prediction is used as query)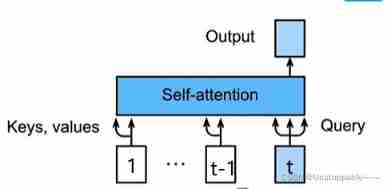
In progress t+1 Predicted hours , I already know that before t Predicted value
It can be parallel during training , It is sequential in prediction .
Summary :
- Transformer It's a pure attention code - decoder
- Both encoder and decoder have n individual transformer block
- Use multiple heads in each block ( since ) attention , Position based feedforward network and layer normalization
Long attention to achieve
Select zoom dot product attention as each attention head
import math
import torch
from torch import nn
from d2l import torch as d2l
#@save
class MultiHeadAttention(nn.Module):
""" Long attention """
def __init__(self, key_size, query_size, value_size, num_hiddens,
num_heads, dropout, bias=False, **kwargs):
super(MultiHeadAttention, self).__init__(**kwargs)
self.num_heads = num_heads
self.attention = d2l.DotProductAttention(dropout)
self.W_q = nn.Linear(query_size, num_hiddens, bias=bias)
self.W_k = nn.Linear(key_size, num_hiddens, bias=bias)
self.W_v = nn.Linear(value_size, num_hiddens, bias=bias)
self.W_o = nn.Linear(num_hiddens, num_hiddens, bias=bias)
def forward(self, queries, keys, values, valid_lens):
# queries,keys,values The shape of the :
# (batch_size, Search or “ key - value ” The number of right ,num_hiddens)
# valid_lens The shape of the :
# (batch_size,) or (batch_size, Number of queries )
# After transformation , Output queries,keys,values The shape of the :
# (batch_size*num_heads, Search or “ key - value ” The number of right ,
# num_hiddens/num_heads)
queries = transpose_qkv(self.W_q(queries), self.num_heads)
keys = transpose_qkv(self.W_k(keys), self.num_heads)
values = transpose_qkv(self.W_v(values), self.num_heads)
if valid_lens is not None:
# In the shaft 0, Put the first ( Scalar or vector ) Copy num_heads Time ,
# Then copy the second item like this , And so on .
valid_lens = torch.repeat_interleave(
valid_lens, repeats=self.num_heads, dim=0)
# output The shape of the :(batch_size*num_heads, Number of queries ,
# num_hiddens/num_heads)
output = self.attention(queries, keys, values, valid_lens)
# output_concat The shape of the :(batch_size, Number of queries ,num_hiddens)
output_concat = transpose_output(output, self.num_heads)
return self.W_o(output_concat)
#@save
def transpose_qkv(X, num_heads):
""" Shape transformation for parallel computing of multiple attention heads """
# Input X The shape of the :(batch_size, Search or “ key - value ” The number of right ,num_hiddens)
# Output X The shape of the :(batch_size, Search or “ key - value ” The number of right ,num_heads,
# num_hiddens/num_heads)
X = X.reshape(X.shape[0], X.shape[1], num_heads, -1)
# Output X The shape of the :(batch_size,num_heads, Search or “ key - value ” The number of right ,
# num_hiddens/num_heads)
X = X.permute(0, 2, 1, 3)
# The shape of the final output :(batch_size*num_heads, Search or “ key - value ” The number of right ,
# num_hiddens/num_heads)
return X.reshape(-1, X.shape[2], X.shape[3])
#@save
def transpose_output(X, num_heads):
""" reverse transpose_qkv Function operation """
X = X.reshape(-1, num_heads, X.shape[1], X.shape[2])
X = X.permute(0, 2, 1, 3)
return X.reshape(X.shape[0], X.shape[1], -1)
num_hiddens, num_heads = 100, 5
attention = MultiHeadAttention(num_hiddens, num_hiddens, num_hiddens,
num_hiddens, num_heads, 0.5)
attention.eval()
batch_size, num_queries = 2, 4
num_kvpairs, valid_lens = 6, torch.tensor([3, 2])
X = torch.ones((batch_size, num_queries, num_hiddens))
Y = torch.ones((batch_size, num_kvpairs, num_hiddens))
attention(X, Y, Y, valid_lens).shape
Transformer Realization
## from https://github.com/graykode/nlp-tutorial/tree/master/5-1.Transformer
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import math
def make_batch(sentences):
input_batch = [[src_vocab[n] for n in sentences[0].split()]]
output_batch = [[tgt_vocab[n] for n in sentences[1].split()]]
target_batch = [[tgt_vocab[n] for n in sentences[2].split()]]
return torch.LongTensor(input_batch), torch.LongTensor(output_batch), torch.LongTensor(target_batch)
## 10
def get_attn_subsequent_mask(seq):
""" seq: [batch_size, tgt_len] """
attn_shape = [seq.size(0), seq.size(1), seq.size(1)]
# attn_shape: [batch_size, tgt_len, tgt_len]
subsequence_mask = np.triu(np.ones(attn_shape), k=1) # Generate an upper triangular matrix
subsequence_mask = torch.from_numpy(subsequence_mask).byte()
return subsequence_mask # [batch_size, tgt_len, tgt_len]
## 7. ScaledDotProductAttention
class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
def forward(self, Q, K, V, attn_mask):
## The dimensions entered are [batch_size x n_heads x len_q x d_k] K: [batch_size x n_heads x len_k x d_k] V: [batch_size x n_heads x len_k x d_v]
## First pass through matmul Function to get scores The shape is : [batch_size x n_heads x len_q x len_k]
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k)
## Then the key words came , The following is what we focused on before attn_mask, The quilt mask Make the place infinitely small ,softmax Then basically 0, Yes q Words don't work
scores.masked_fill_(attn_mask, -1e9) # Fills elements of self tensor with value where mask is one.
attn = nn.Softmax(dim=-1)(scores)
context = torch.matmul(attn, V)
return context, attn
## 6. MultiHeadAttention
class MultiHeadAttention(nn.Module):
def __init__(self):
super(MultiHeadAttention, self).__init__()
## Input in QKV They are equal. , We'll use mapping linear Do a mapping to get the parameter matrix Wq, Wk,Wv
self.W_Q = nn.Linear(d_model, d_k * n_heads)
self.W_K = nn.Linear(d_model, d_k * n_heads)
self.W_V = nn.Linear(d_model, d_v * n_heads)
self.linear = nn.Linear(n_heads * d_v, d_model)
self.layer_norm = nn.LayerNorm(d_model)
def forward(self, Q, K, V, attn_mask):
## This bull is divided into these steps , First, map the header , And then calculate atten_scores, And then calculate atten_value;
## Enter the data shape : Q: [batch_size x len_q x d_model], K: [batch_size x len_k x d_model], V: [batch_size x len_k x d_model]
residual, batch_size = Q, Q.size(0)
# (B, S, D) -proj-> (B, S, D) -split-> (B, S, H, W) -trans-> (B, H, S, W)
## The following is the first mapping , Split back ; It must be noted that q and k After the split, the dimension is the same amount , So at first glance, it's all dk
q_s = self.W_Q(Q).view(batch_size, -1, n_heads, d_k).transpose(1,2) # q_s: [batch_size x n_heads x len_q x d_k]
k_s = self.W_K(K).view(batch_size, -1, n_heads, d_k).transpose(1,2) # k_s: [batch_size x n_heads x len_k x d_k]
v_s = self.W_V(V).view(batch_size, -1, n_heads, d_v).transpose(1,2) # v_s: [batch_size x n_heads x len_k x d_v]
## Enter the number of attn_mask The shape is batch_size x len_q x len_k, Then through the following code, we get new attn_mask : [batch_size x n_heads x len_q x len_k], Is to put pad The message is repeated n Head up
attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1)
## Then we calculate ScaledDotProductAttention This function , Go to 7. to glance at
## There are two results :context: [batch_size x n_heads x len_q x d_v], attn: [batch_size x n_heads x len_q x len_k]
context, attn = ScaledDotProductAttention()(q_s, k_s, v_s, attn_mask)
context = context.transpose(1, 2).contiguous().view(batch_size, -1, n_heads * d_v) # context: [batch_size x len_q x n_heads * d_v]
output = self.linear(context)
return self.layer_norm(output + residual), attn # output: [batch_size x len_q x d_model]
## 8. PoswiseFeedForwardNet
class PoswiseFeedForwardNet(nn.Module):
def __init__(self):
super(PoswiseFeedForwardNet, self).__init__()
self.conv1 = nn.Conv1d(in_channels=d_model, out_channels=d_ff, kernel_size=1)
self.conv2 = nn.Conv1d(in_channels=d_ff, out_channels=d_model, kernel_size=1)
self.layer_norm = nn.LayerNorm(d_model)
def forward(self, inputs):
residual = inputs # inputs : [batch_size, len_q, d_model]
output = nn.ReLU()(self.conv1(inputs.transpose(1, 2)))
output = self.conv2(output).transpose(1, 2)
return self.layer_norm(output + residual)
## 4. get_attn_pad_mask
## for instance , My current sentence length is 5, In the latter part of the attention mechanism , We're working out QK Transpose divided by the root sign ,softmax Before , The shape we get
## len_input * len*input Represents the influence of each word on the rest of the words containing itself
## So here I need to have a matrix of the same size and shape , Tell me which position is PAD part , Then calculate softmax I used to set this to infinity ;
## It must be noted that the matrix shape obtained here is batch_size x len_q x len_k, We are right k Medium pad Symbol to identify , It did not k Mark in , Because there's no need
## seq_q and seq_k Not necessarily the same , In interactive attention ,q From the decoder ,k From the coding end , So tell the model coding side pad Symbol information can , Decoding end pad Information is not used in the interactive attention layer ;
def get_attn_pad_mask(seq_q, seq_k):
batch_size, len_q = seq_q.size()
batch_size, len_k = seq_k.size()
# eq(zero) is PAD token
pad_attn_mask = seq_k.data.eq(0).unsqueeze(1) # batch_size x 1 x len_k, one is masking
return pad_attn_mask.expand(batch_size, len_q, len_k) # batch_size x len_q x len_k
## 3. PositionalEncoding Code implementation
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000):
super(PositionalEncoding, self).__init__()
## The implementation of location coding is actually very simple , Just type the code directly against the formula , The following code is just one of the implementation methods ;
## In terms of understanding , It should be noted that even numbers and odd numbers have a common part in the formula , We use log The function takes down the power , Easy to calculate ;
## pos It represents the index of words in sentences , This is something to be aware of ; such as max_len yes 128 individual , So the index is from 0,1,2,...,127
## Suppose my demodel yes 512,2i In that symbol i from 0 Here we are 255, that 2i The corresponding value is 0,2,4...510
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)## What needs to be noted here is pe[:, 0::2] This usage , It's from 0 Start to the back , Reinforcement is 2, In fact, it represents the even position
pe[:, 1::2] = torch.cos(position * div_term)## What needs to be noted here is pe[:, 1::2] This usage , It's from 1 Start to the back , Reinforcement is 2, In fact, it represents odd positions
## After obtaining the above code pe:[max_len*d_model]
## After the following code , What we got pe The shape is :[max_len*1*d_model]
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe) ## Set a buffer , In fact, it is simply understood that this parameter can be used without updating
def forward(self, x):
""" x: [seq_len, batch_size, d_model] """
x = x + self.pe[:x.size(0), :]
return self.dropout(x)
## 5. EncoderLayer : There are two parts , Multi head attention mechanism and feedforward neural network
class EncoderLayer(nn.Module):
def __init__(self):
super(EncoderLayer, self).__init__()
self.enc_self_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, enc_inputs, enc_self_attn_mask):
## The following is the self attention layer , Input is enc_inputs, The shape is [batch_size x seq_len_q x d_model] It should be noted that the initial QKV The matrix is equivalent to this input , To have a look at enc_self_attn function 6.
enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs, enc_self_attn_mask) # enc_inputs to same Q,K,V
enc_outputs = self.pos_ffn(enc_outputs) # enc_outputs: [batch_size x len_q x d_model]
return enc_outputs, attn
## 2. Encoder The part consists of three parts : The word vector embedding, Position coding part , Attention layer and subsequent feedforward neural network
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.src_emb = nn.Embedding(src_vocab_size, d_model) ## This is actually to define and generate a matrix , Size is src_vocab_size * d_model
self.pos_emb = PositionalEncoding(d_model) ## Location coding , Here is the fixed sine and cosine function , You can also use words like vectors nn.Embedding Get a location code that can update learning
self.layers = nn.ModuleList([EncoderLayer() for _ in range(n_layers)]) ## Use ModuleList For many encoder To stack , Because of the following encoder Word vectors and position coding are not used , So pull it out ;
def forward(self, enc_inputs):
## Here our enc_inputs The shape is : [batch_size x source_len]
## The following code passes src_emb, Index location ,enc_outputs The output shape is [batch_size, src_len, d_model]
enc_outputs = self.src_emb(enc_inputs) # Convert the numerical index into the corresponding vector
## Here is the location code , Add the two together into this function , From here, we can take a look at the implementation of location coding function ;3.
enc_outputs = self.pos_emb(enc_outputs.transpose(0, 1)).transpose(0, 1)
##get_attn_pad_mask In order to get pad Location information for , Give it to the back of the model , When calculating self attention and interactive attention, remove pad The influence of symbols , Take a look at this function 4.
enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs)
enc_self_attns = []
for layer in self.layers:
## Go and see EncoderLayer Layer function 5.
enc_outputs, enc_self_attn = layer(enc_outputs, enc_self_attn_mask)
enc_self_attns.append(enc_self_attn)
return enc_outputs, enc_self_attns
## 10.
class DecoderLayer(nn.Module):
def __init__(self):
super(DecoderLayer, self).__init__()
self.dec_self_attn = MultiHeadAttention()
self.dec_enc_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask):
dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask)
dec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs, enc_outputs, dec_enc_attn_mask)
dec_outputs = self.pos_ffn(dec_outputs)
return dec_outputs, dec_self_attn, dec_enc_attn
## 9. Decoder
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.tgt_emb = nn.Embedding(tgt_vocab_size, d_model)
self.pos_emb = PositionalEncoding(d_model)
self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)])
def forward(self, dec_inputs, enc_inputs, enc_outputs): # dec_inputs : [batch_size x target_len]
dec_outputs = self.tgt_emb(dec_inputs) # [batch_size, tgt_len, d_model]
dec_outputs = self.pos_emb(dec_outputs.transpose(0, 1)).transpose(0, 1) # [batch_size, tgt_len, d_model]
## get_attn_pad_mask From the attention level pad part
dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs)
## get_attn_subsequent_mask What this does is the self attention layer mask part , Is that you can't see after the current word , Use an upper triangle for 1 Matrix
dec_self_attn_subsequent_mask = get_attn_subsequent_mask(dec_inputs)
## Add two matrices , Greater than 0 For the 1, No more than 0 For the 0, by 1 After that, it will be fill To infinity
dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequent_mask), 0)
## What this does is... In the mechanism of interactive attention mask matrix ,enc The input is k, I'll see this k Which ones are pad Symbol , To the later model ; Watch out! , I q There must be pad Symbol , But here I don't care , I've said it many times before
dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs)
dec_self_attns, dec_enc_attns = [], []
for layer in self.layers:
dec_outputs, dec_self_attn, dec_enc_attn = layer(dec_outputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask)
dec_self_attns.append(dec_self_attn)
dec_enc_attns.append(dec_enc_attn)
return dec_outputs, dec_self_attns, dec_enc_attns
## 1. From the overall network structure , It's divided into three parts : Coding layer , Decoding layer , Output layer
class Transformer(nn.Module):
def __init__(self):
super(Transformer, self).__init__()
self.encoder = Encoder() ## Coding layer
self.decoder = Decoder() ## Decoding layer
# Output layer d_model It's each of our decoding layers token The dimension size of the output , Then I'll do a tgt_vocab_size The size of softmax
self.projection = nn.Linear(d_model, tgt_vocab_size, bias=False)
def forward(self, enc_inputs, dec_inputs):
# Here are two data inputs , One is enc_inputs Shape is [batch_size, src_len], It is mainly used as the input of coding segment , One dec_inputs, Shape is [batch_size, tgt_len], It is mainly used as the input of the decoding end
# enc_inputs As input Shape is [batch_size, src_len], The output is specified internally by its own function , Specify what you want to output , Can be all tokens Output , It can be the output of each specific layer ; It can also be the output of some parameters in the middle ;
# enc_outputs Is the main output ,enc_self_attns I remember right here QK After transposing and multiplying softmax Then the matrix value , It represents the correlation between each word and other words ;
enc_outputs, enc_self_attns = self.encoder(enc_inputs)
# dec_outputs yes decoder The main output , For subsequent linear mapping ; dec_self_attns Analogy to enc_self_attns Is to look at each word pair decoder The relevance of the remaining words entered in ;dec_enc_attns yes decoder Each word pair in encoder The relevance of each word in ;
dec_outputs, dec_self_attns, dec_enc_attns = self.decoder(dec_inputs, enc_inputs, enc_outputs)
# dec_outputs Do mapping to thesaurus size
dec_logits = self.projection(dec_outputs) # dec_logits : [batch_size x src_vocab_size x tgt_vocab_size]
return dec_logits.view(-1, dec_logits.size(-1)), enc_self_attns, dec_self_attns, dec_enc_attns
if __name__ == '__main__':
## The input part of the sentence ,
sentences = ['ich mochte ein bier P', 'S i want a beer', 'i want a beer E']
# Transformer Parameters
# Padding Should be Zero
## Building a vocabulary
src_vocab = {
'P': 0, 'ich': 1, 'mochte': 2, 'ein': 3, 'bier': 4}
src_vocab_size = len(src_vocab)
tgt_vocab = {
'P': 0, 'i': 1, 'want': 2, 'a': 3, 'beer': 4, 'S': 5, 'E': 6}
tgt_vocab_size = len(tgt_vocab)
src_len = 5 # length of source
tgt_len = 5 # length of target
# Model parameters
d_model = 512 # Embedding Size
d_ff = 2048 # FeedForward dimension
d_k = d_v = 64 # dimension of K(=Q), V
n_layers = 6 # number of Encoder of Decoder Layer
n_heads = 8 # number of heads in Multi-Head Attention
model = Transformer()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
enc_inputs, dec_inputs, target_batch = make_batch(sentences)
for epoch in range(20):
optimizer.zero_grad()
outputs, enc_self_attns, dec_self_attns, dec_enc_attns = model(enc_inputs, dec_inputs)
loss = criterion(outputs, target_batch.contiguous().view(-1))
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
loss.backward()
optimizer.step()
边栏推荐
猜你喜欢
【基础架构】Flink/Flink-CDC的部署和配置(MySQL / ES)
腾讯T3大牛手把手教你,大厂内部资料

Live broadcast today | the 2022 Hongji ecological partnership conference of "Renji collaboration has come" is ready to go
![[translation] micro survey of cloud native observation ability. Prometheus leads the trend, but there are still obstacles to understanding the health of the system](/img/63/3addcecb69dcb769c4736653952f66.png)
[translation] micro survey of cloud native observation ability. Prometheus leads the trend, but there are still obstacles to understanding the health of the system

Black Horse - - Redis Chapter
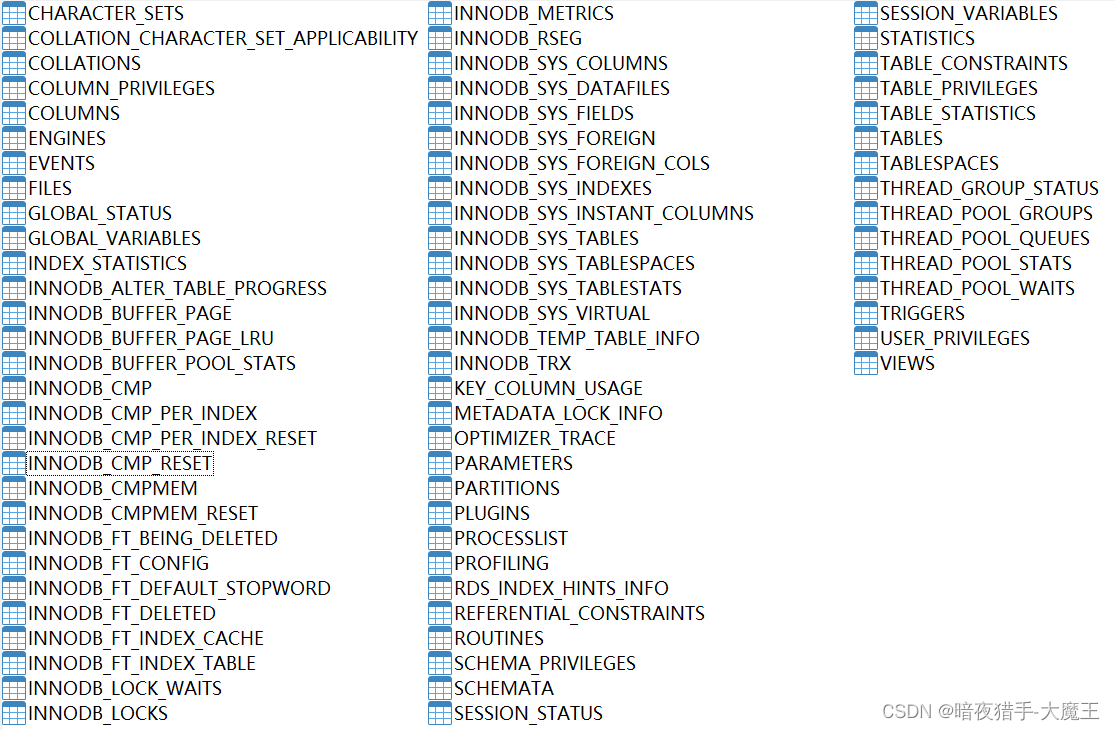
MySQL information schema learning (I) -- general table
信息系统项目管理师---第八章 项目质量管理
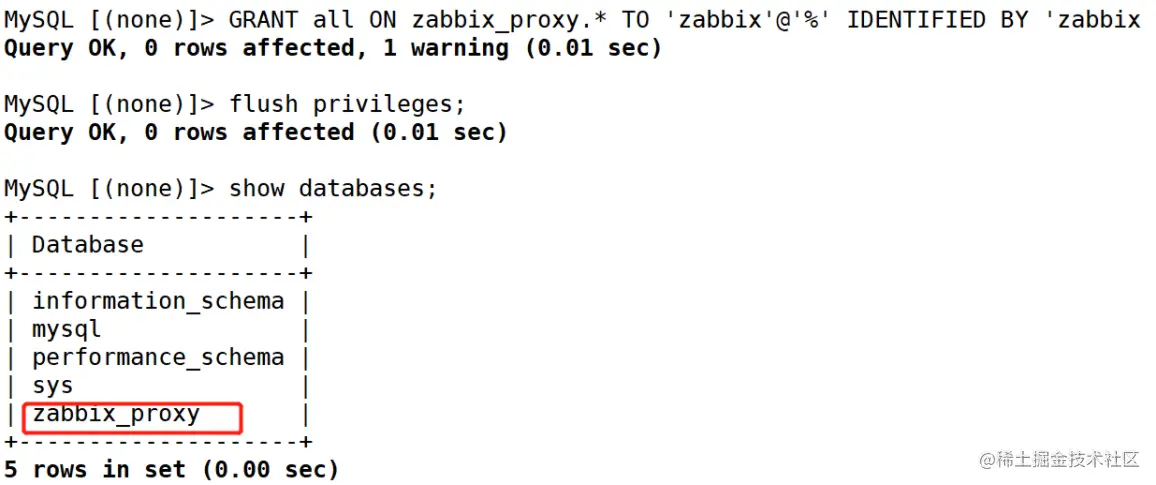
ZABBIX proxy server and ZABBIX SNMP monitoring
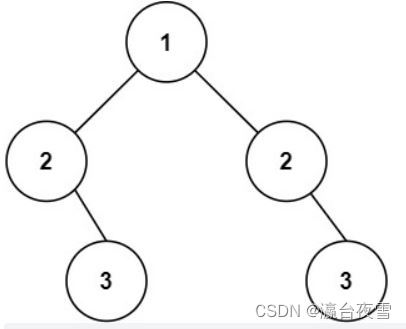
Li Kou 101: symmetric binary tree

MySQL information schema learning (II) -- InnoDB table
随机推荐
谷粒商城--分布式高级篇P129~P339(完结)
关于图像的读取及处理等
[translation] supply chain security project in toto moved to CNCF incubator
从sparse.csc.csr_matrix生成邻接矩阵
usb host 驱动 - UVC 掉包
MySql必知必会学习
凤凰架构3——事务处理
Information System Project Manager - Chapter VIII project quality management
Low CPU load and high loadavg processing method
深入分析,Android面试真题解析火爆全网
【翻译】数字内幕。KubeCon + CloudNativeCon在2022年欧洲的选择过程
Lick the dog until the last one has nothing (simple DP)
LeetCode_格雷编码_中等_89.格雷编码
js实现力扣71题简化路径
short i =1; I=i+1 and short i=1; Difference of i+=1
Tensorflow2.0 自定义训练的方式求解函数系数
How to access localhost:8000 by mobile phone
Learning and Exploration - Seamless rotation map
利用 clip-path 绘制不规则的图形
企业精益管理体系介绍