当前位置:网站首页>线上故障突突突?如何紧急诊断、排查与恢复
线上故障突突突?如何紧急诊断、排查与恢复
2022-07-05 01:24:00 【InfoQ】
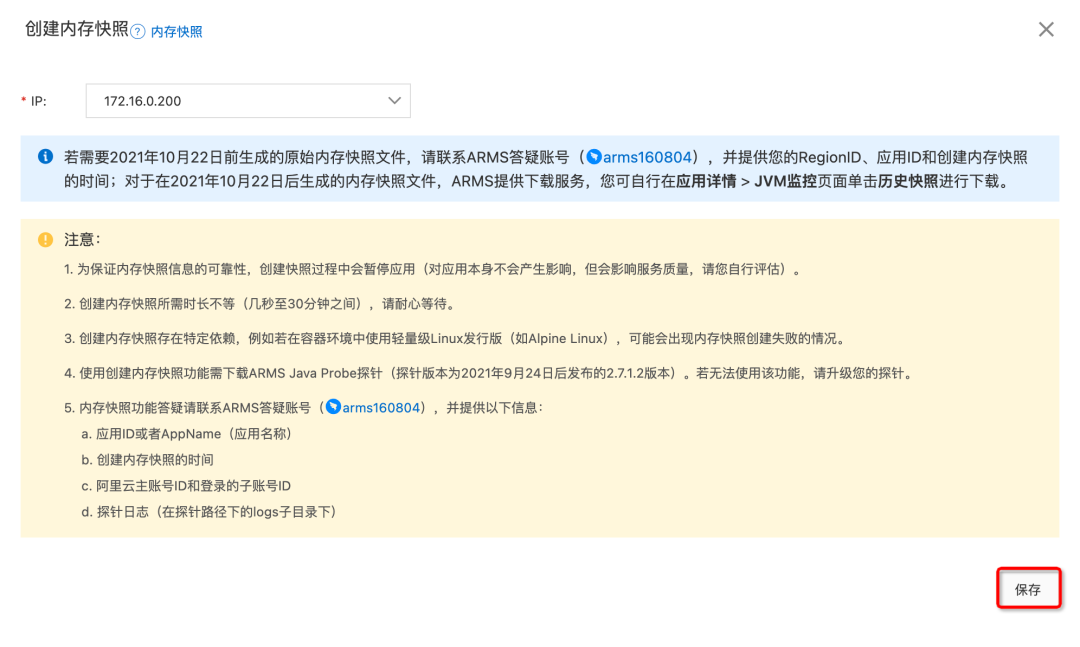
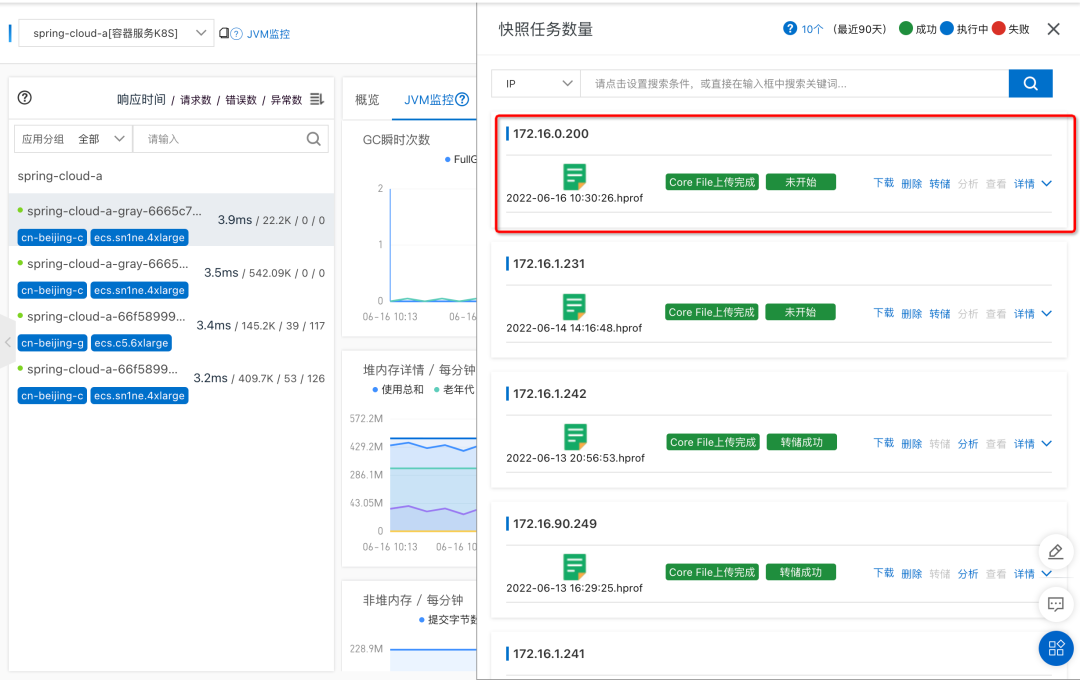
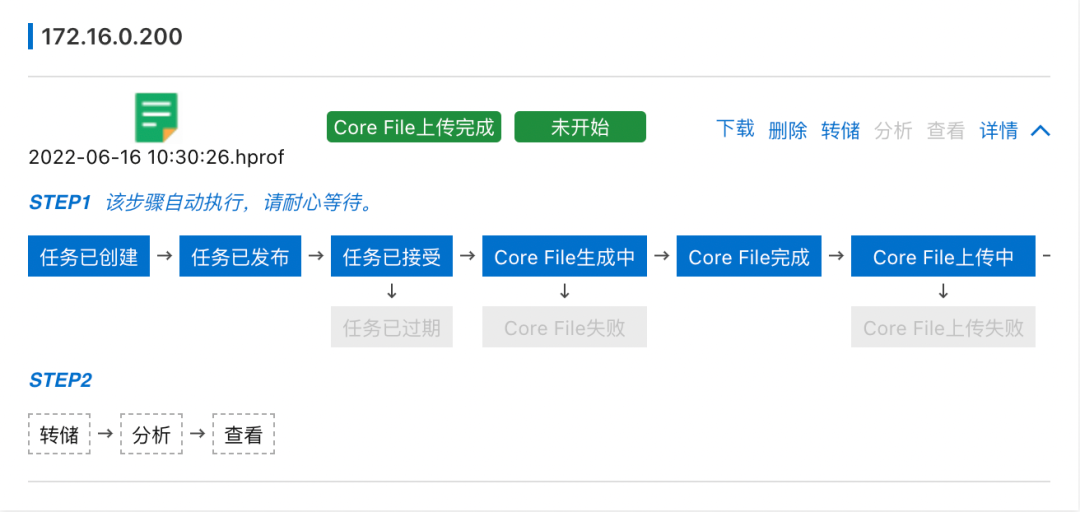
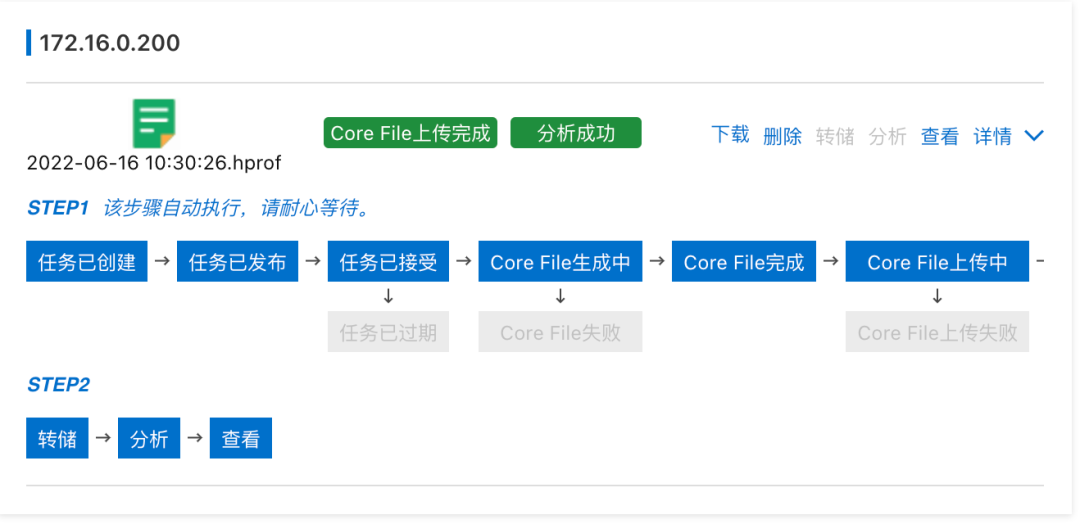
概述
1 分钟发现
监控
告警
- 集成事件后管理更高效。
- 告警管理默认支持一键化集成阿里云常见的监控工具,并支持更多的监控工具手动接入,方便统一维护。
- 事件接入模块稳定,能提供 7x24 小时的无间断事件处理服务。
- 处理海量事件数据时可以保证低延时。
- 及时准确地将告警通知给联系人。
- 配置通知规则,对事件合并后再发送告警通知,减少运维人员出现通知疲劳的情况。
- 根据告警的紧急程度选择邮件、短信、电话、钉钉等不同的通知方式,来提醒联系人处理告警。
- 通过升级通知对长时间没有处理的告警进行多次提醒,保证告警及时解决。
- 帮助您快速便捷地管理告警。
- 联系人能通过钉钉随时处理告警。
- 使用通用告警格式,联系人能更好的分析告警。
- 多个联系人通过钉钉协同处理。
- 统计告警数据,实时分析处理情况,改进告警处理效率。
5 分钟定位故障
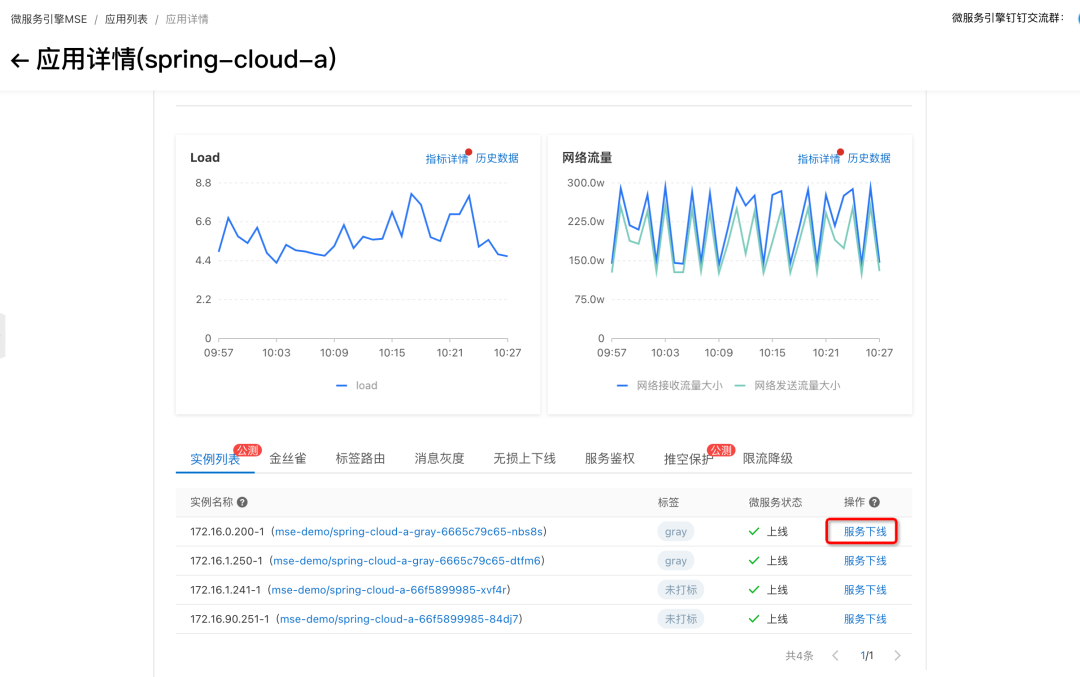
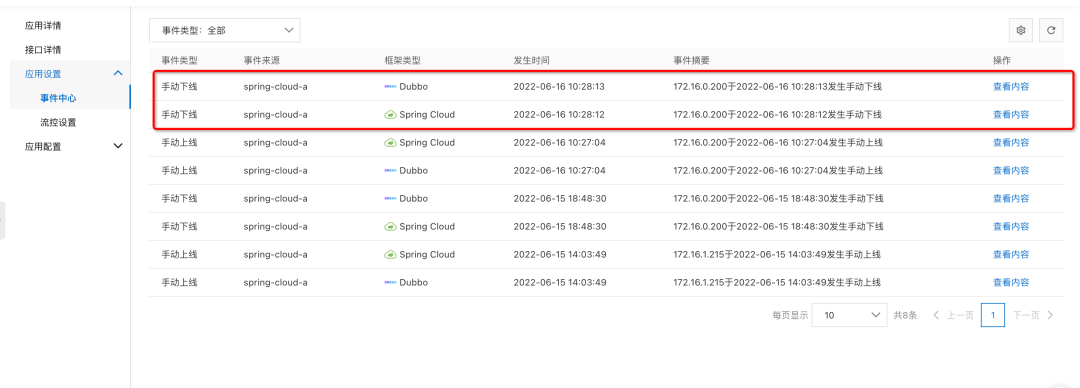
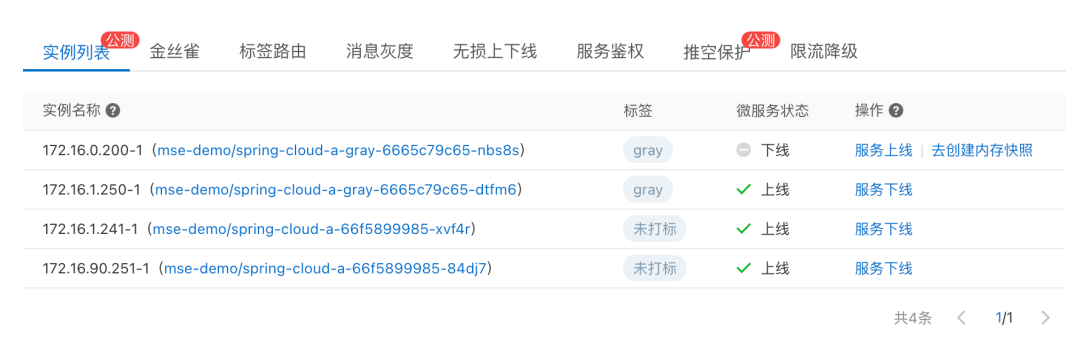
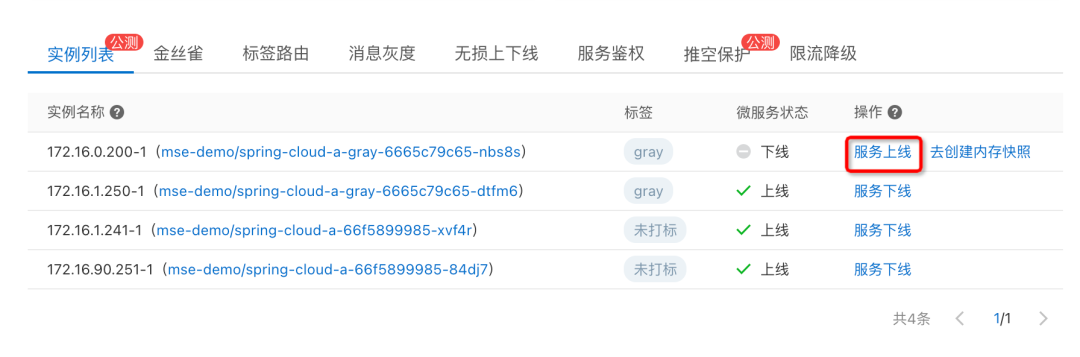
服务实例隔离与诊断
- 实践
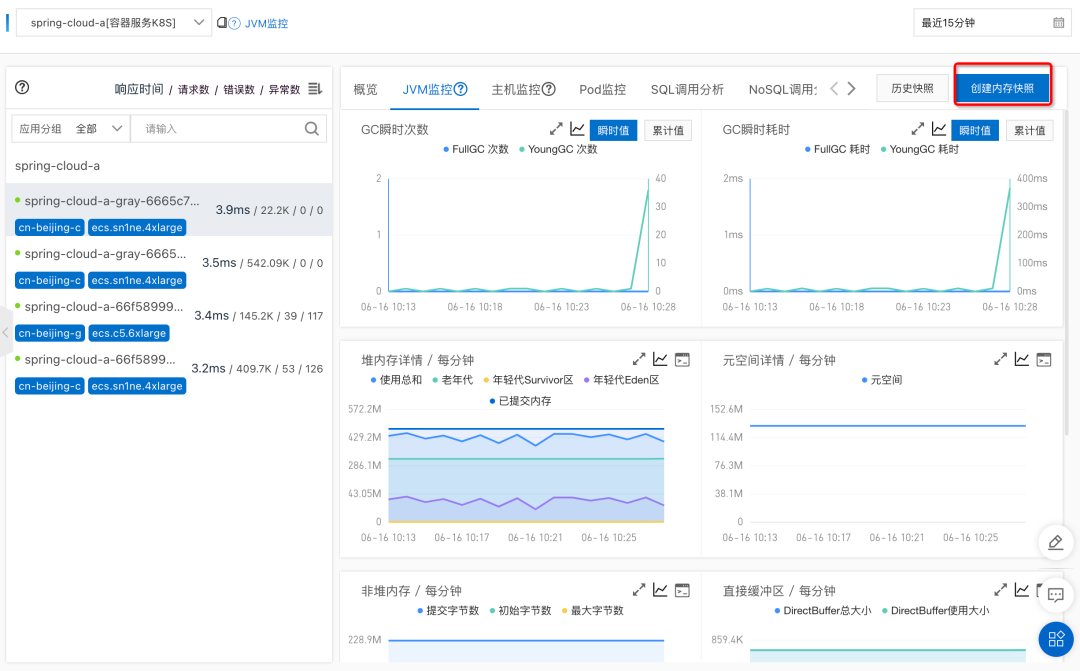
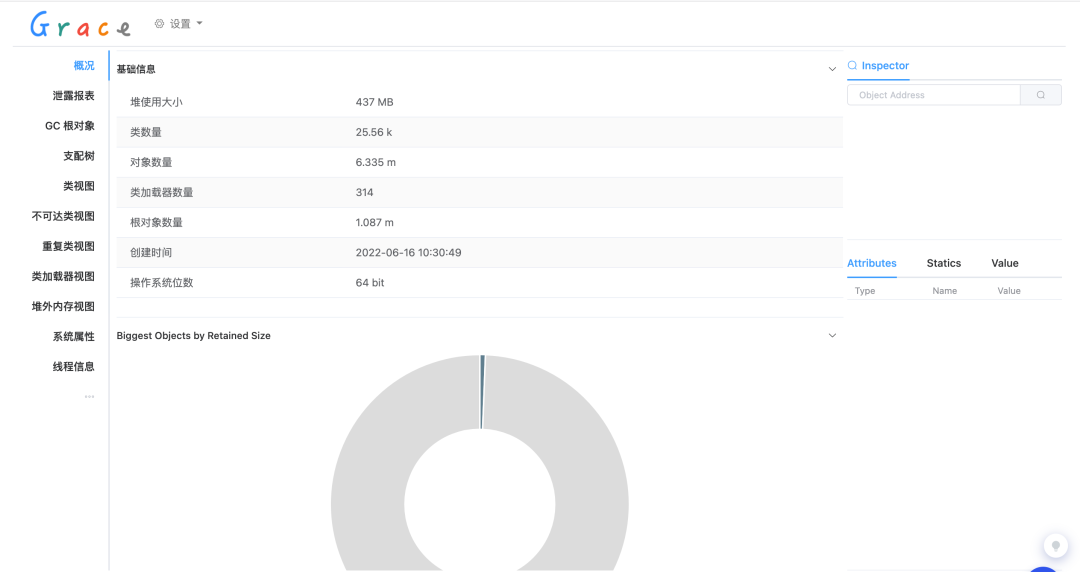
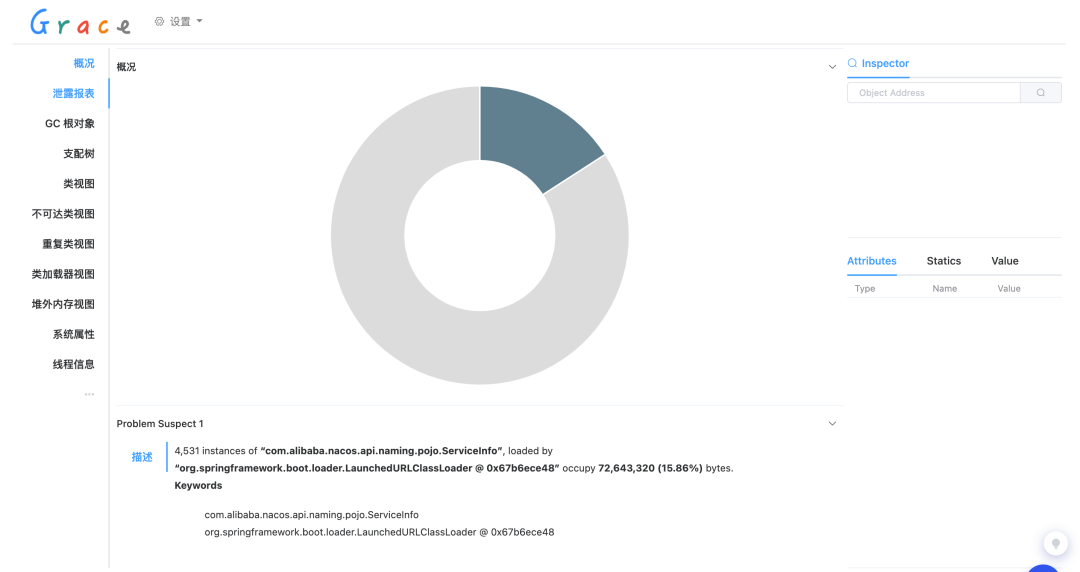
Arthas 诊断
- JVM 概览

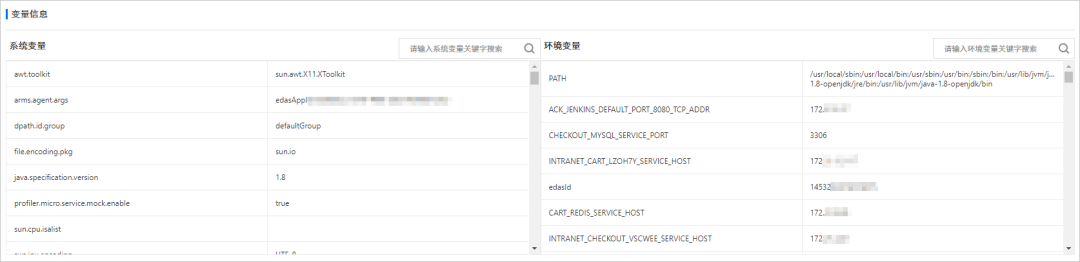
- 线程耗时分析
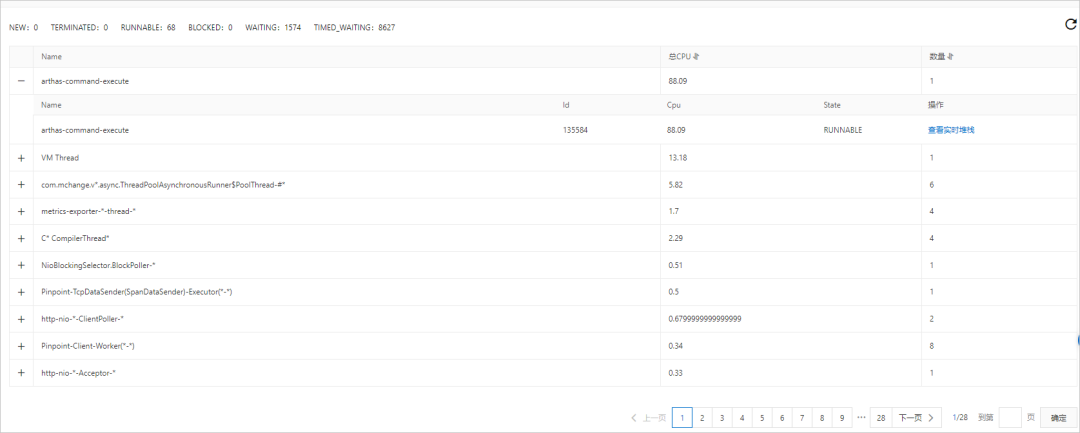
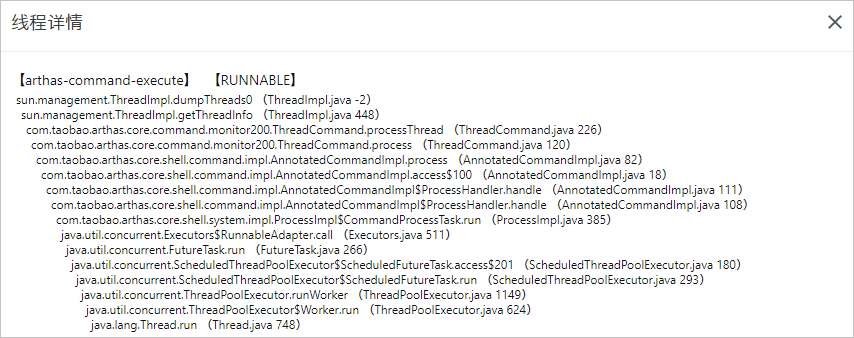
- 方法执行分析
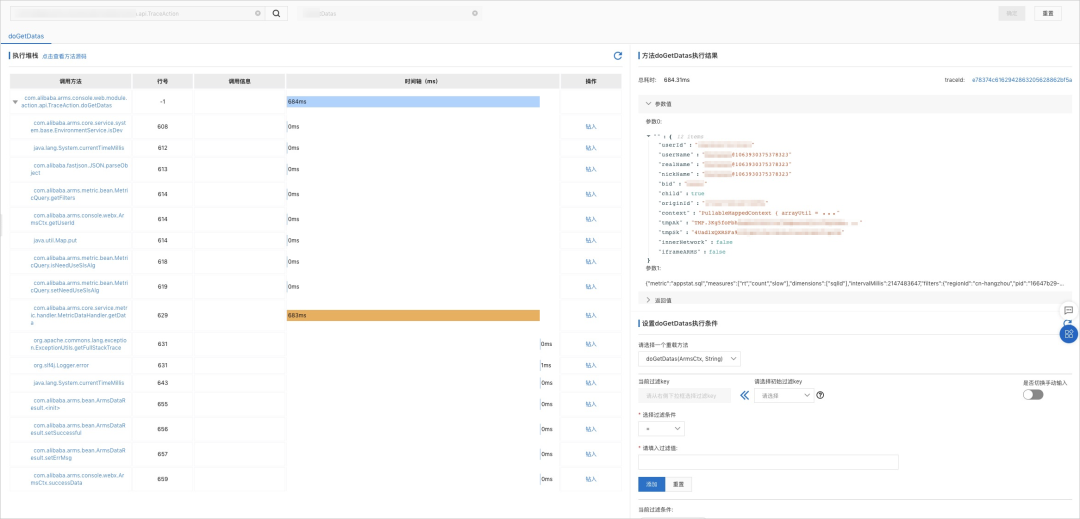
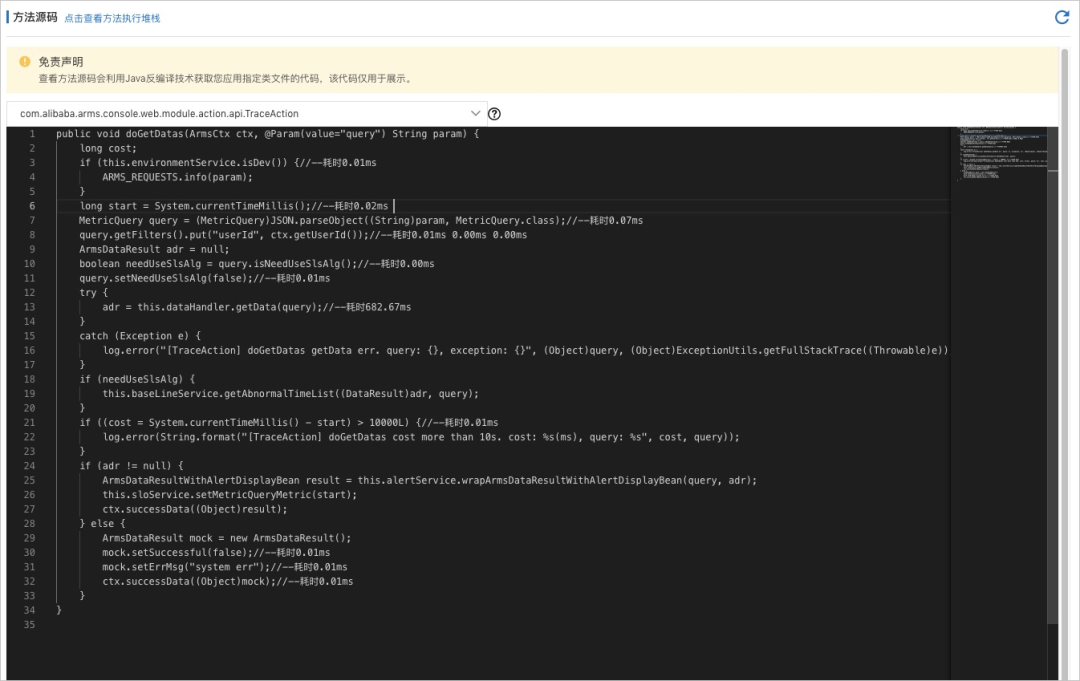
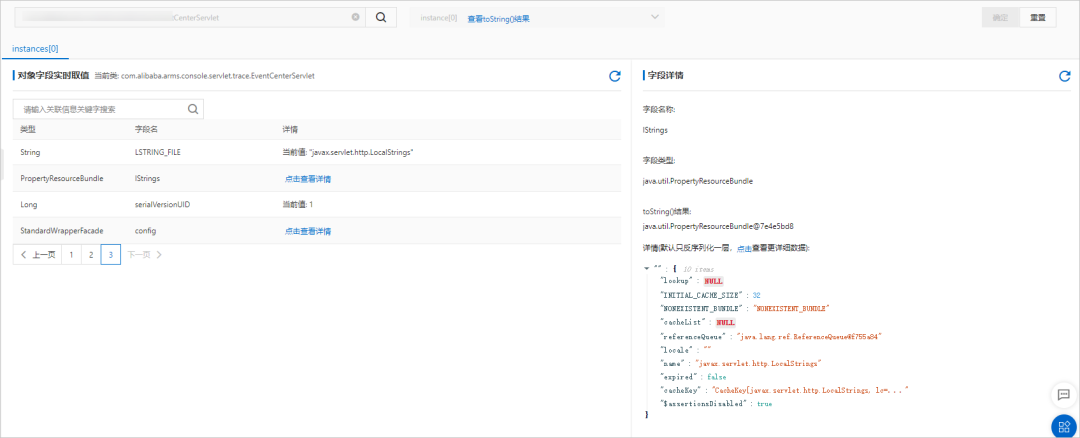
- 对象查看器
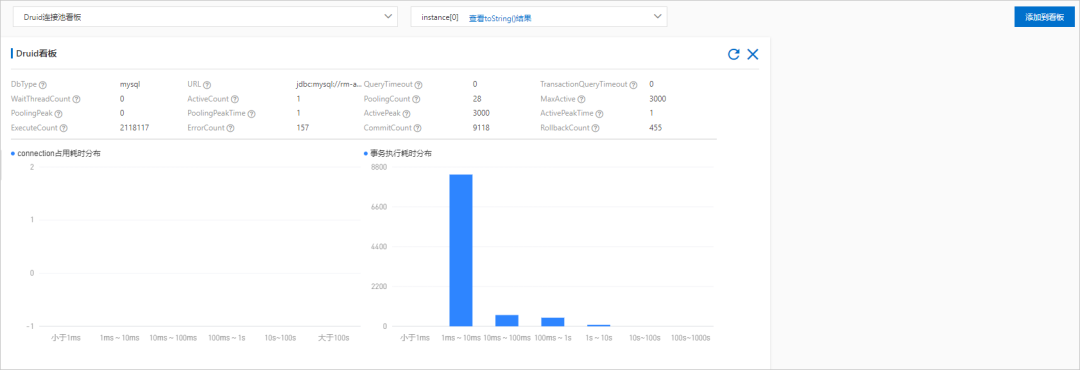
- 实时看板
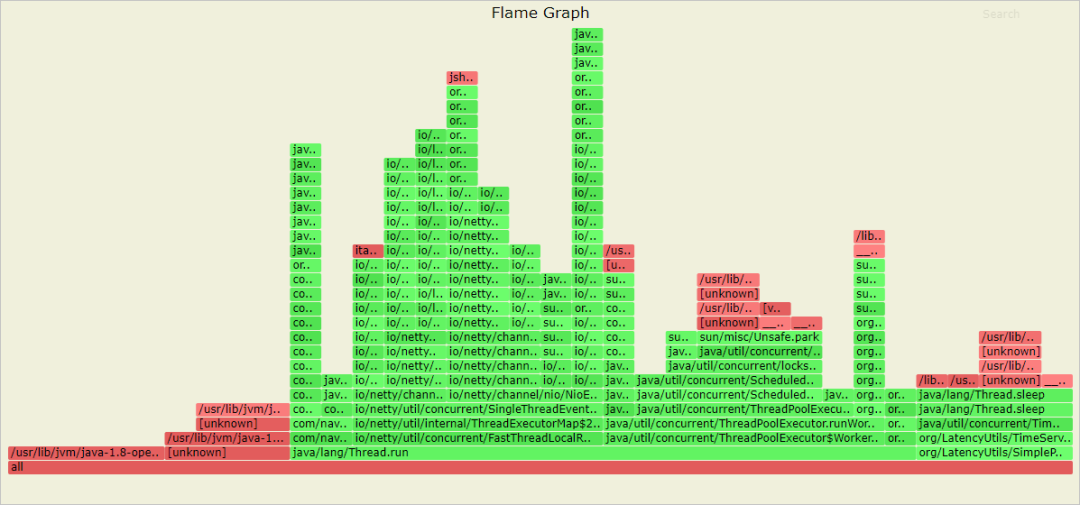
- 性能分析
10 分钟恢复
离群实例摘除
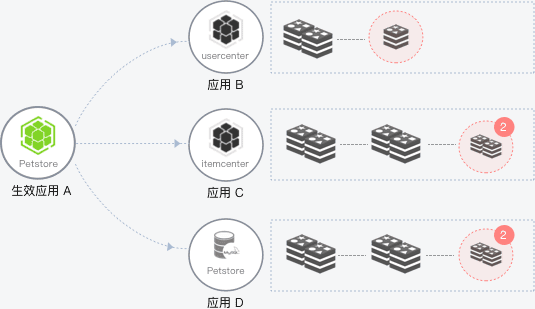
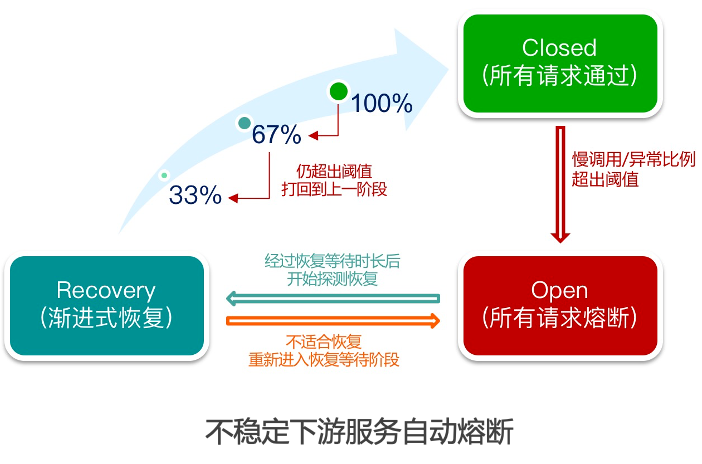
服务熔断与降级
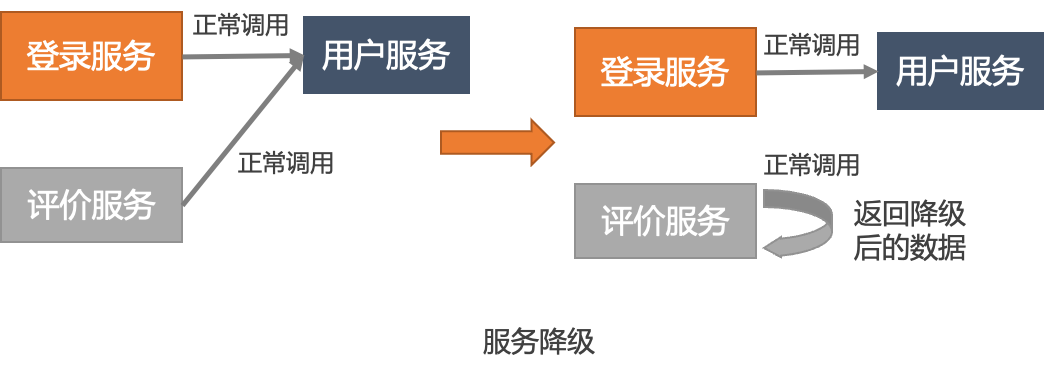
流控、扩容、重启、回滚
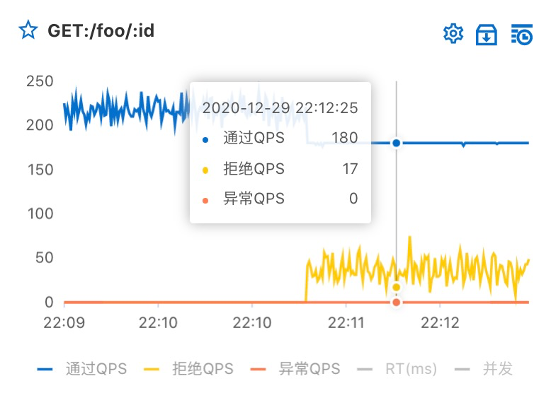
- 流量控制:根据流量、并发线程数、响应时间等指标,把随机到来的流量调整成合适的形状,即流量塑形。通过流控能力,为服务接口配置流控规则,让容量范围内的请求通过,多余的请求被拒绝,相当于安全气囊的作用。层层防护,在 Nginx/Ingress 网关层进行粗粒度保护,在微服务层进行 API、接口、方法、参数粒度控制。避免应用被瞬时的流量高峰冲垮,从而保障应用的高可用性。
- 扩容:水平横向扩容提升集群可用性
- 重启:重新启动 JVM 进程,从而暂时消除长时间运行累积的问题如内存泄露等
- 回滚:消除变更引入的问题
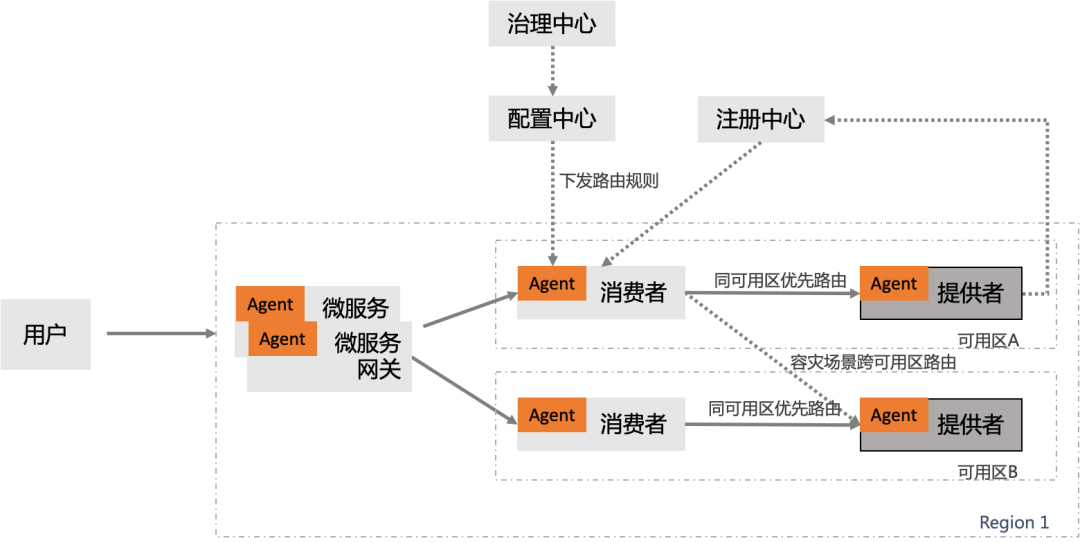
基于同可用区优先的一键切流
尾
边栏推荐
- 当产业互联网时代真正发展完善之后,将会在每一个场景见证巨头的诞生
- Delaying wages to force people to leave, and the layoffs of small Internet companies are a little too much!
- 抓包整理外篇——————状态栏[ 四]
- node工程中package.json文件作用是什么?里面的^尖括号和~波浪号是什么意思?
- 26.2 billion! These universities in Guangdong Province have received heavy support
- BGP comprehensive experiment
- 【CTF】AWDP总结(Web)
- Senior Test / development programmers write no bugs? Qualifications (shackles) don't be afraid of mistakes
- Robley's global and Chinese markets 2022-2028: technology, participants, trends, market size and share Research Report
- 【微处理器】基于FPGA的微处理器VHDL开发
猜你喜欢
Wechat applet: Xingxiu UI v1.5 WordPress system information resources blog download applet wechat QQ dual end source code support WordPress secondary classification loading animation optimization
Talking about JVM 4: class loading mechanism
Playwright recording
![Yyds dry goods inventory [Gan Di's one week summary: the most complete and detailed in the whole network]; detailed explanation of MySQL index data structure and index optimization; remember collectio](/img/e8/de158982788fc5bc42f842b07ff9a8.jpg)
Yyds dry goods inventory [Gan Di's one week summary: the most complete and detailed in the whole network]; detailed explanation of MySQL index data structure and index optimization; remember collectio
Wechat applet: the latest WordPress black gold wallpaper wechat applet two open repair version source code download support traffic main revenue
Take you ten days to easily complete the go micro service series (IX. link tracking)
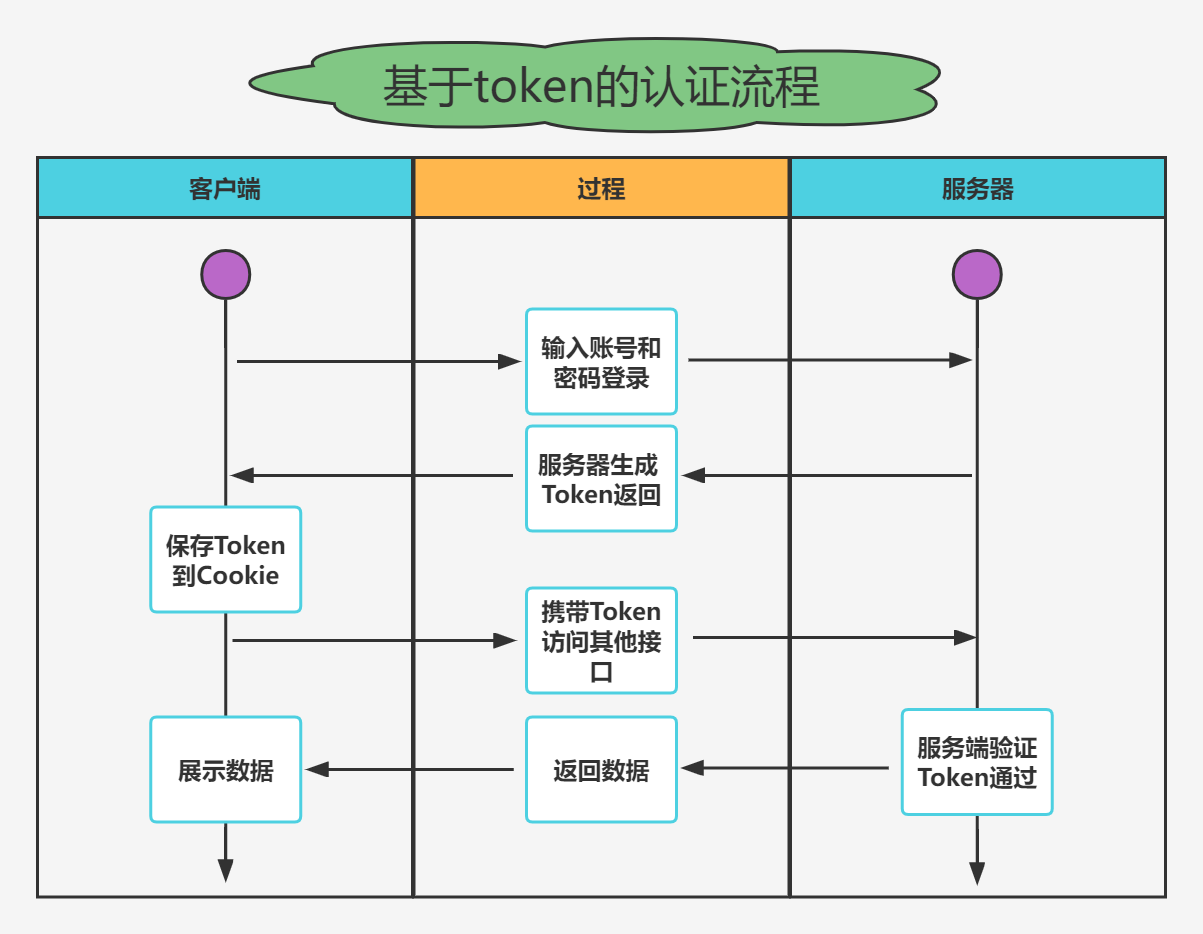
Actual combat simulation │ JWT login authentication

Game 280 of leetcode week
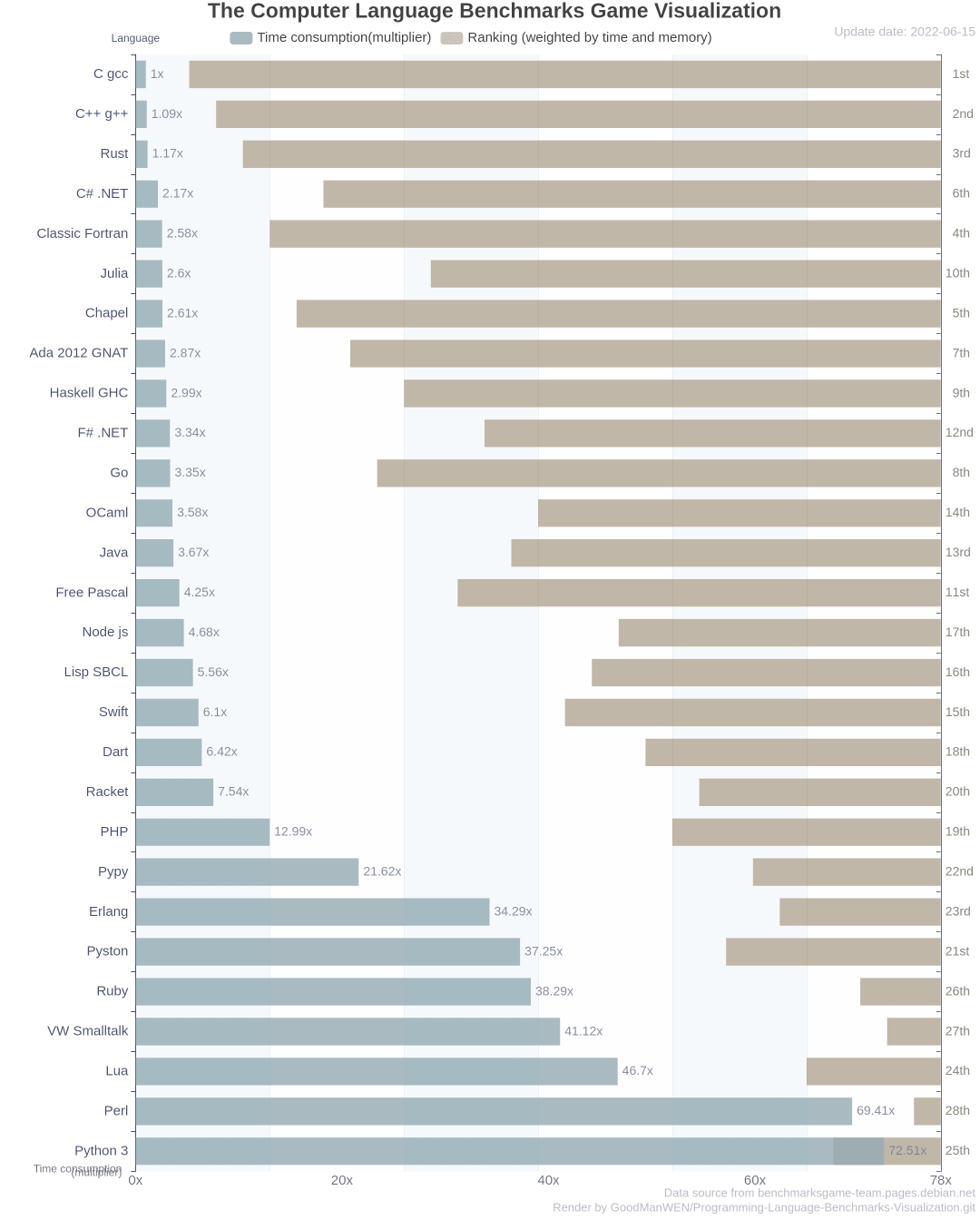
The performance of major mainstream programming languages is PK, and the results are unexpected
微信小程序:全网独家小程序版本独立微信社群人脉
随机推荐
Pandora IOT development board learning (RT thread) - Experiment 4 buzzer + motor experiment [key external interrupt] (learning notes)
整理混乱的头文件,我用include what you use
Database postragesql client authentication
Discrete mathematics: propositional symbolization of predicate logic
当产业互联网时代真正发展完善之后,将会在每一个场景见证巨头的诞生
Nebula Importer 数据导入实践
JS implementation determines whether the point is within the polygon range
视频网站手绘
[untitled]
Classification of performance tests (learning summary)
La jeunesse sans rancune de Xi Murong
微信小程序:星宿UI V1.5 wordpress系统资讯资源博客下载小程序微信QQ双端源码支持wordpress二级分类 加载动画优化
Database performance optimization tool
Intel sapphire rapids SP Zhiqiang es processor cache memory split exposure
ROS command line tool
Wechat applet: independent background with distribution function, Yuelao office blind box for making friends
Pycharm professional download and installation tutorial
Arbitrum: two-dimensional cost
Database postragesq PAM authentication
Heartless sword English translation of Xi Murong's youth without complaint