当前位置:网站首页>Oracle迁移中关于大容量表使用数据泵(expdp、impdp)导出导入容易出现的问题和注意事项
Oracle迁移中关于大容量表使用数据泵(expdp、impdp)导出导入容易出现的问题和注意事项
2022-07-07 01:13:00 【Major_ZYH】
概况
最近要到了一次Oracle数据(Linux)迁移,因为源库数据量较大,所以确定的实施方案如下:
1.源库Oracle用户使用数据泵工具expdp整库(用户)导出。
2.目标库使用impdp导入。
3.使用kettle工具同步所有数据变化的表。
4.确定服务数据源时间,在源库停止服务连接,执行最后一次数据同步同时,将相关服务数据源切换目标库。最后启动服务完成迁移。
在使用expdp工具导出时指定并发为10,分为两部分导出,由于源库中个别的几张表数据量都在几亿到十几亿以上,并且有超过2T的图片类LOB数据额外指定表名导出:
导出1
expdp username/password directory=expdp_dir dumpfile=2022xxxx_username_%U.dmp logfile=2022xxxx_username.log exclude=TABLE:“IN(‘TB_XX01’,‘TB_XX02’,‘TB_XX03’,‘TB_XX04’)” parallel=10
导出2
expdp username/password directory=expdp_dir dumpfile=TP2022xxxx_username_%U.dmp logfile=2022xxxx_username.log TABLES=‘TB_XX01’,‘TB_XX02’,‘TB_XX03’,‘TB_XX04’ parallel=10
出现的问题
在导入图片类大容量表和十几亿条文字类数据的大表是发现导入过程中数据库的临时表空间temp和回退表空间undotbs1的使用量持续增加,并且持续了几天都没有导入成功一张表。发现问题后停止了导入,但是造成的undo表空间的大量占用也并没有释放,经查询发现undo中存在大量未完成的事务,并且事务都是由于导入时的表上存在的主键在数据入库是的维护主键相关的事务。
其实在导入前已经将表上除了主键外其他索引和约束以及触发器全部删除和禁用,但是没想到只是维护主键就导致了这么大量的undo数据。
处理方式
发现问题原因后,将表上所有主键也进行了删除,并且在导入是执行了参数(undo表空间迟迟不释放可以参考博客结尾的附录进行操作):
impdp username/password directory=expdp_dir dumpfile=ZP2022xxxx_username_%U.dmp logfile=impdp_username_2022xxxx.log TABLES=‘TB_XX01’,‘TB_XX02’,‘TB_XX03’,‘TB_XX04’ parallel=10 access_method=direct_path
这次导入在很短时间内就完成了,并且没有产生很多的undo数据。
总结
1.在处理大容量数据表使用数据泵导出时,建议根据服务器的cpu核数,适当的设置并行度,加快导出速度。并且导出的dmp也要配置%U,配合并行度并发写dmp文件。
2.在导入市,大容量的表在非必要的情况下建议清除表上所有索引和约束,包括主键,不然会产生大量的undo数据,占用undo表空间。导致大量事务累积,表数据导入极慢。
3.impdp的导出参数access_method=direct_path会忽略对数据库元数据的检查,虽然会使导入速度加快,但是同样的也会一定概率出现报错,还是要慎用。
附录
在停止导入时,undo表空间已经产生了大量的undo数据,并且本次因为大量数据导入,所以并没有开启归档,这也导致了undo数据在redo日志循环后数据覆盖,迟迟不能释放undo数据,并且即便是设置新的默认表空间UNDOTBS2后,仍然不能删除旧的UNDOTBS1表空间,而且会发现数据库操作会非常卡顿,这时因为数据库还在处理旧的undo表空间中的事务数据。因为表空间中还有状态为ONLINE的回退段,需要等所有回退段全部OFFLINE后才可以将UNDOTBS1表空间删除,但是因为没有开启归档,其中部分表空间回退段已经不能自动offline了。查看回退段状态方式如下:
select * from dba_rollback_segs where tablespace_name=‘UNDOTBS1’
为了不耽误数据迁移,所以用了特殊方式处理。
1.创建新的undo表空间UNDOTBS2。
2.将数据库默认的undo表空间指定为UNDOTBS2。
3.强制关闭数据库 shutdown abort 。因为是迁移库,并未正式使用所以可以执行,但是生产库不要这么做,强制停止会导致undotbs1的数据文件损坏。
4.开启数据库,本次启动正常,不过在alter database open阶段持续时间较长,查看alter日志会发现数据库扫描现在的redo,并进行一次介质恢复。
5.数据open后,sys用户登录数据库查看视图:
select * from dba_rollback_segs where tablespace_name=‘UNDOTBS1’
会发现很多旧的undo表空间UNDOTBS1中很多回退段状态变成了“PARTLY AVAILABLE”,此时的状态已经表示数据文件损坏了。
6.记录所有状态“PARTLY AVAILABLE”的回退段的名字,也就是SEGMENT_NAME。
7.创建pfile:create pfile=‘/home/oracle/initORCL.ora’ from spfile;
8.关闭数据库,还是需要强制关闭 shutdown abort。修改pfile,设置参数:
*._corrupted_rollback_segments=(_SYSSMU1 , S Y S S M U 2 ,_SYSSMU2 ,SYSSMU2,_SYSSMU3 , S Y S S M U 4 ,_SYSSMU4 ,SYSSMU4,_SYSSMU5 , S Y S S M U 6 ,_SYSSMU6 ,SYSSMU6,_SYSSMU7 , S Y S S M U 8 ,_SYSSMU8 ,SYSSMU8,_SYSSMU9 , S Y S S M U 10 ,_SYSSMU10 ,SYSSMU10)
(注:允许在rollback segments损坏的情况下启动数据库)
参数值就是状态为“PARTLY AVAILABLE”的回退段的名字。
将参数添加到pfile中。
9.数据库以pfile启动:startup pfile=‘/home/oracle/initORCL.ora’;
10.数据库此次启动后还是会有一段介质恢复的时间,在完全打开后,就可以删除UNDOTBS1回退表空间了。
11.删除旧表空间后,关闭数据库,此次可以正常的关闭:shutdown immediate。关闭后即可正常打开数据库:startup。到此undo表空间可正常使用了。
边栏推荐
- Detailed explanation of platform device driver architecture in driver development
- Chain storage of stack
- Opensergo is about to release v1alpha1, which will enrich the service governance capabilities of the full link heterogeneous architecture
- Randomly generate session_ id
- Say sqlyog deceived me!
- jvm命令之 jcmd:多功能命令行
- VScode进行代码补全
- Nvisual network visualization
- How to improve website weight
- Peripheral driver library development notes 43: GPIO simulation SPI driver
猜你喜欢
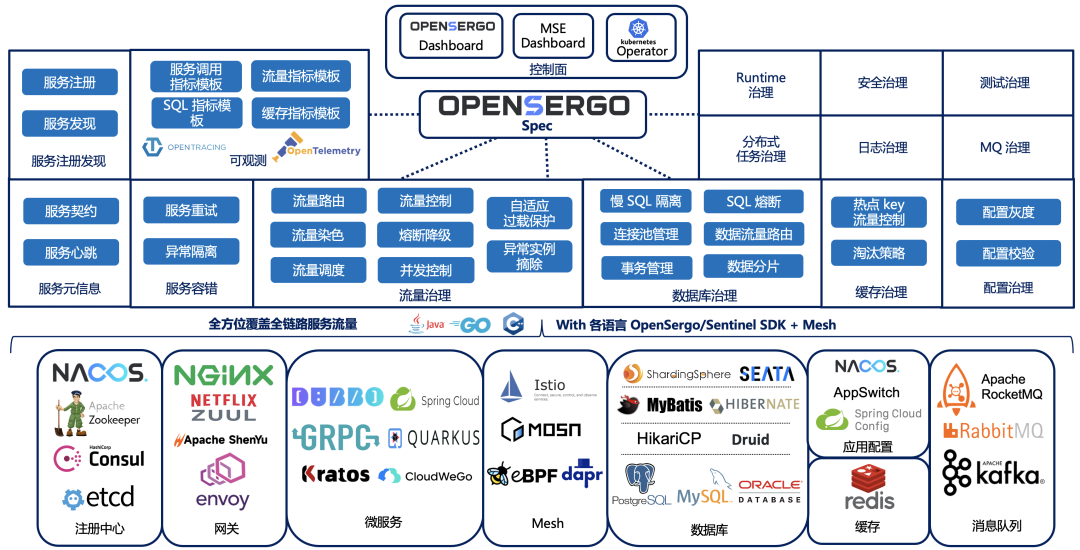
OpenSergo 即将发布 v1alpha1,丰富全链路异构架构的服务治理能力
![[InstallShield] Introduction](/img/df/4522d06510ff918d00659b8358368f.jpg)
[InstallShield] Introduction
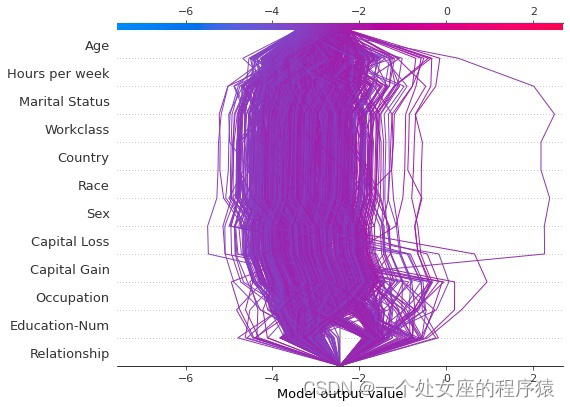
ML之shap:基于adult人口普查收入二分类预测数据集(预测年收入是否超过50k)利用shap决策图结合LightGBM模型实现异常值检测案例之详细攻略
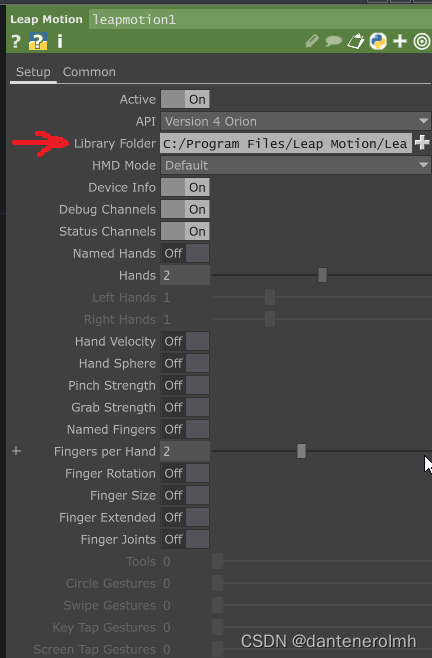
如何在Touch Designer 2022版中设置解决Leap Motion不识别的问题?
一名普通学生的大一总结【不知我等是愚是狂,唯知一路向前奔驰】
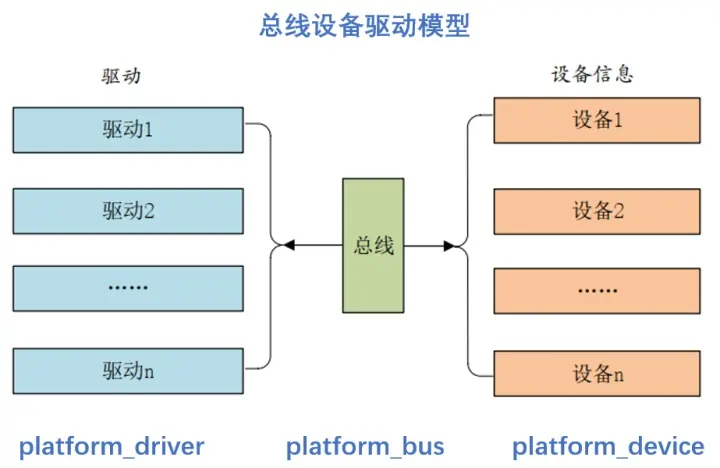
Detailed explanation of platform device driver architecture in driver development
JVM命令之- jmap:导出内存映像文件&内存使用情况
C note 13
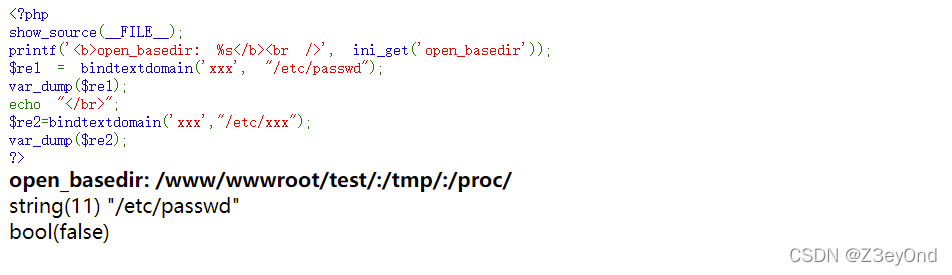
绕过open_basedir
Why does the data center need a set of infrastructure visual management system
随机推荐
cf:C. Column Swapping【排序 + 模拟】
Nvisual network visualization
Loss function and positive and negative sample allocation in target detection: retinanet and focal loss
目标检测中的损失函数与正负样本分配:RetinaNet与Focal loss
从“跑分神器”到数据平台,鲁大师开启演进之路
980. Different path III DFS
【FPGA教程案例14】基于vivado核的FIR滤波器设计与实现
原生小程序 之 input切換 text與password類型
Classic questions about data storage
Jstack of JVM command: print thread snapshots in JVM
Mac version PHP installed Xdebug environment (M1 version)
Web authentication API compatible version information
一名普通学生的大一总结【不知我等是愚是狂,唯知一路向前奔驰】
Interview questions and salary and welfare of Shanghai byte
[cloud native] what is the microservice architecture?
PTA ladder game exercise set l2-004 search tree judgment
Ten stages of becoming a Senior IC Design Engineer. What stage are you in now?
Jmeter自带函数不够用?不如自己动手开发一个
SQL Server 2008 各种DateTime的取值范围
PowerPivot——DAX(函数)