当前位置:网站首页>浅学一下二叉树的顺序存储结构——堆
浅学一下二叉树的顺序存储结构——堆
2022-08-02 04:10:00 【LeePlace】

基本概念介绍
树的基本概念和结构
树是一种非线性的数据结构,它是由有限个节点组成的一个具有层次关系的集合。
- 每棵树都有一个根节点,根节点没有前驱结点;
- 除根节点外,其他节点被分成 M(M>0) 个互不相交的集合 T1、T2、……、Tm,其中每一个集合 Ti(1<= i<= m) 又是一棵结构与树类似的子树,子树也是由根节点和子树构成;
- 每棵树的子树只能有一个前驱,但可以有若干个后继;
- 树是递归定义的。
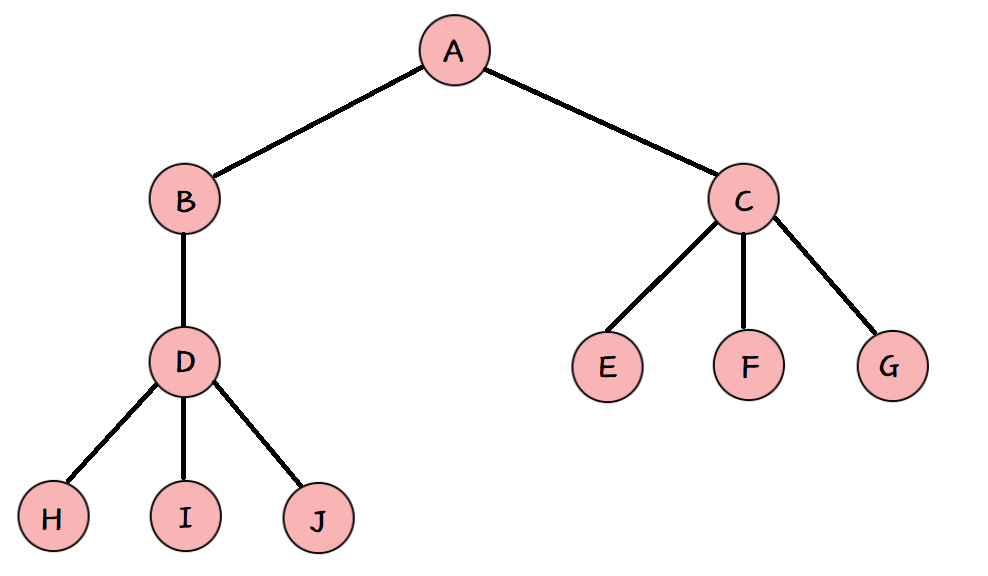
如上图就是一颗树,下面介绍树相关的一些基本概念。
- 节点的度:一个节点含有的子树的个数称为该节点的度。 如上图:A 的为 2 ,B 的为 1 ,C 的为 3
- 叶节点或终端节点:度为 0 的节点称为叶节点。 如上图:E、F、G、H、I、J、K 为叶节点
- 非终端节点或分支节点:度不为0的节点; 如上图:B、C、D 为分支节点
- 双亲节点或父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点。 如上图:A 是 B 的父节点
- 孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点。如上图:B 是 A 的孩子节点
- 兄弟节点:具有相同父节点的节点互称为兄弟节点。如上图:B、C 是兄弟节点
- 树的度:一棵树中,最大的节点的度称为树的度。 如上图:树的度为 3
- 节点的层次:从根开始定义起,根为第 1 层,根的子节点为第 2 层,以此类推。
- 树的高度或深度:树中节点的最大层次。如上图:树的高度为 4
- 堂兄弟节点:双亲在同一层的节点互为堂兄弟。如上图:D、E 互为堂兄弟节点
- 节点的祖先:从根到该节点所经分支上的所有节点。如上图:A 是所有节点的祖先
- 子孙:以某节点为根的子树中任一节点都称为该节点的子孙。如上图:所有节点都是 A 的子孙
- 森林:由 m(m>0) 棵互不相交的树的集合称为森林
树的表示
树结构相对线性表就比较复杂了,要存储表示起来就比较麻烦了,实际中树有很多种表示方式,如:双亲表示法,孩子表示法、孩子兄弟表示法等等。我们这里就简单的了解其中最常用的孩子兄弟表示法。
typedef int DataType;
struct Node
{
struct Node* _firstChild1; // 第一个孩子结点
struct Node* _pNextBrother; // 指向其下一个兄弟结点
DataType _data; // 结点中的数据域
};

这种表示树的方法,只能由父亲节点找到下一层的第一个子节点,由该子节点找到它的兄弟节点,也就是父亲节点的其他子节点。
二叉树的概念和结构
一棵二叉树是结点的一个有限集合,该集合或者为空,或者是由一个根节点加上两棵别称为左子树和右子树的二叉树组成。
顾名思义,二叉树是一种特殊的树,它的特点如下:
- 每个结点最多有两棵子树,即二叉树不存在度大于2的结点。
- 二叉树的子树有左右之分,其子树的次序不能颠倒。
如下图就是一颗标准的二叉树。

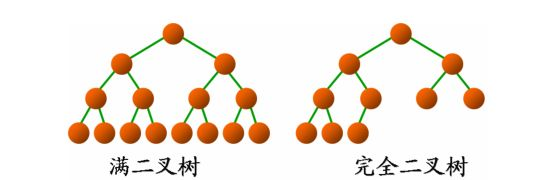
二叉树还有两种特殊的结构——完全二叉树和满二叉树:
- 满二叉树:一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是满二叉树。也就是
说,如果一个二叉树的层数为K,且结点总数是 2k -1 ,则它就是满二叉树。 - 完全二叉树:完全二叉树是效率很高的数据结构,完全二叉树是由满二叉树而引出来的。对于深度 K
的,有 n 个结点的二叉树,当且仅当其每一个结点都与深度为 K 的满二叉树中编号从 1 至 n 的结点一一对应时称之为完全二叉树。 要注意的是满二叉树是一种特殊的完全二叉树。可以理解为满二叉树最下一层从右往左删掉几个节点后就成了一颗普通完全二叉树。
二叉树的性质
- 若规定根节点的层数为 1 ,则一棵非空二叉树的第 i 层上最多有 2i-1 个结点
- 若规定根节点的层数为 1 ,则深度为 h 的二叉树的最大结点数是 2h-1
- 对任何一棵二叉树, 如果其叶结点个数为 n0, 度为 2 的分支结点个数为 n2 ,则有 n0=n2+1
- 若规定根节点的层数为 1,具有 n 个结点的满二叉树的深度,h=log2(n+1)
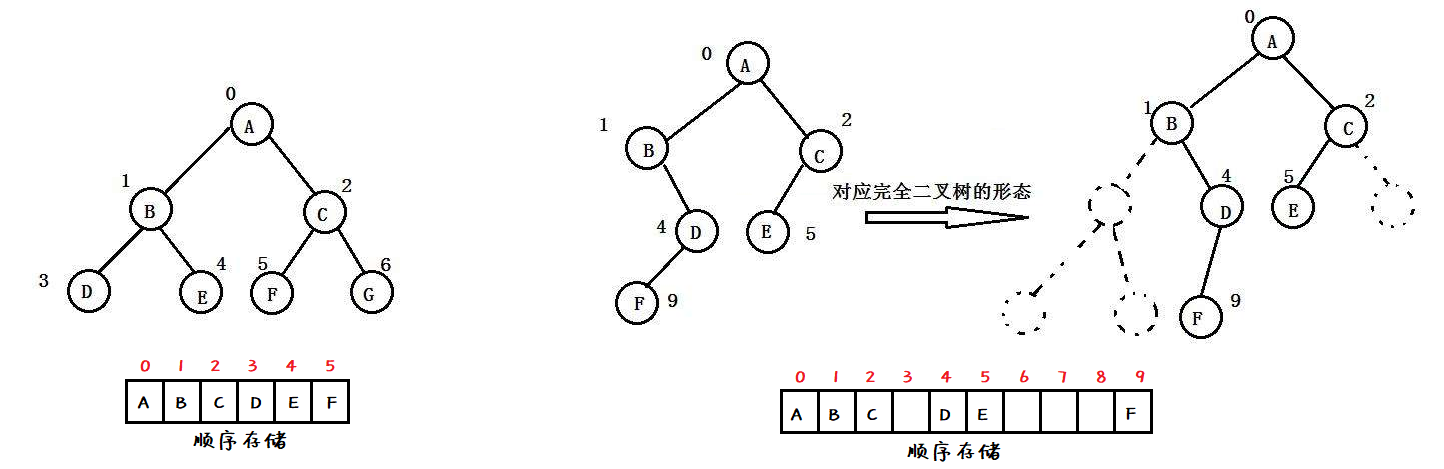
- 对于具有 n 个结点的完全二叉树,如果按照从上至下从左至右的数组顺序对所有节点从 0 开始编号,则对于序号为 i 的结点有:
- 若 i > 0,则 i 位置节点的双亲序号为 (i - 1) / 2
- 若 i = 0,则 i 为根节点编号,无双亲节点
- 若 2i + 1 < n ,左孩子序号为 2i + 1
- 若 2i + 2 < n ,右孩子序号为 2i + 2
顺序储存结构 – 堆
顺序结构存储就是使用数组来存储。
普通的二叉树是不适合用数组来存储的,因为可能会存在大量的空间浪费。
而完全二叉树更适合使用顺序结构存储。
现实中我们通常把堆(一种二叉树)使用顺序结构的数组来存储,需要注意的是这里的堆和操作系统虚拟进程地址空间中的堆是两回事,一个是数据结构,一个是操作系统中管理内存的一块区域分段。
下面就介绍一下堆的相关概念和应用。
堆的概念及结构
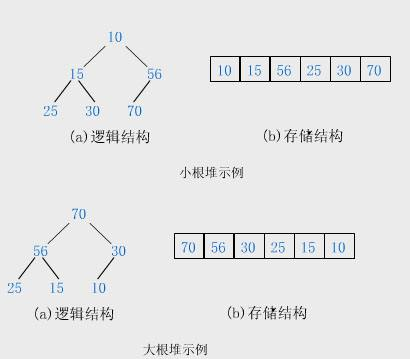
如果有一个集合 K = {k0,k1, k2,…,kn-1} ,
把它的所有元素按完全二叉树的顺序存储方式存储在一个一维数组中,
并满足:ki <= k2i+1 且 ki <= k2i+2 (或 ki >= k2i+1 且 ki >= k2i+2) 其中 i = 0,1,2…,
则称为其为小堆(或大堆)。
将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。
可见,堆总是一棵完全二叉树,堆中某个节点的值总是不大于或不小于其父节点的值。
堆的实现
首先先创建一个结构表示堆:
typedef int HPDataType;
struct HP {
HPDataType* a;
int size; //记录当前元素个数
int capacity;//记录堆的容量
}
堆向下调整算法
现在我们给出一个数组,逻辑上看做一颗完全二叉树。
int a[] = {
27,15,19,18,28,34,65,49,25,37};
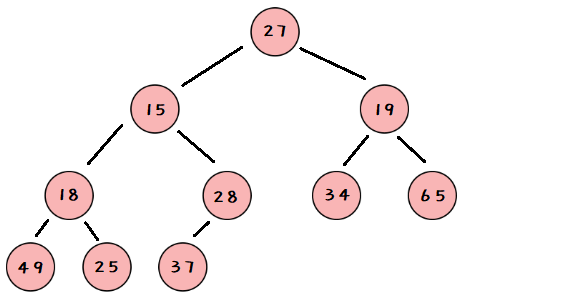
此时它的左子树和右子树都是小堆,
那么接下来如何将它处理为一个小堆呢?
对其做如下变换:
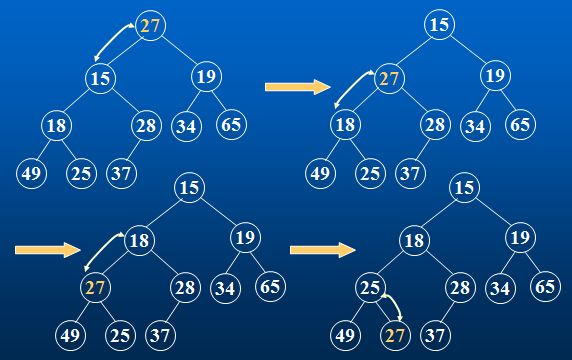
从根节点开始,
每次跟子节点中较小的那个交换,
直至子节点都比自己大或调到最后,
调整完成就得到了一个标准的小堆。
如是的调整方法称为根的向下调整算法。
其代码实现如下:
void Swap(HPDataType* a, HPDataType* b) {
HPDataType tmp = *a;
*a = *b;
*b = tmp;
}
void AdjustDown(HPDataType* a, int sz, int parent) {
int child = parent * 2 + 1;
while (child < sz)
{
if (child + 1 < sz && a[child + 1] > a[child])//1
++child;
if (a[child] > a[parent])//2
{
Swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
break;
}
}
上面代码后调整得到的是大堆,如果想调小堆只需要改一下 1 和 2 处的逻辑判断符号。
注意:以要调整的节点为根节点,当根节点的左右子树都是大堆(或小堆)时,向下调整算法才有用。
假设一共有 n 个节点,
则树最多有 log2n 层,
向下调整算法中的循环最多执行 log2n 次,
所以向下调整算法的时间复杂度是
O(logN)。
堆的创建
下面我们给出一个数组,这个数组逻辑上可以看做一颗完全二叉树,但是还不是一个堆。
int a[] = {
1,5,3,8,7,6};
现在我们通过算法,把它构建成一个大堆。
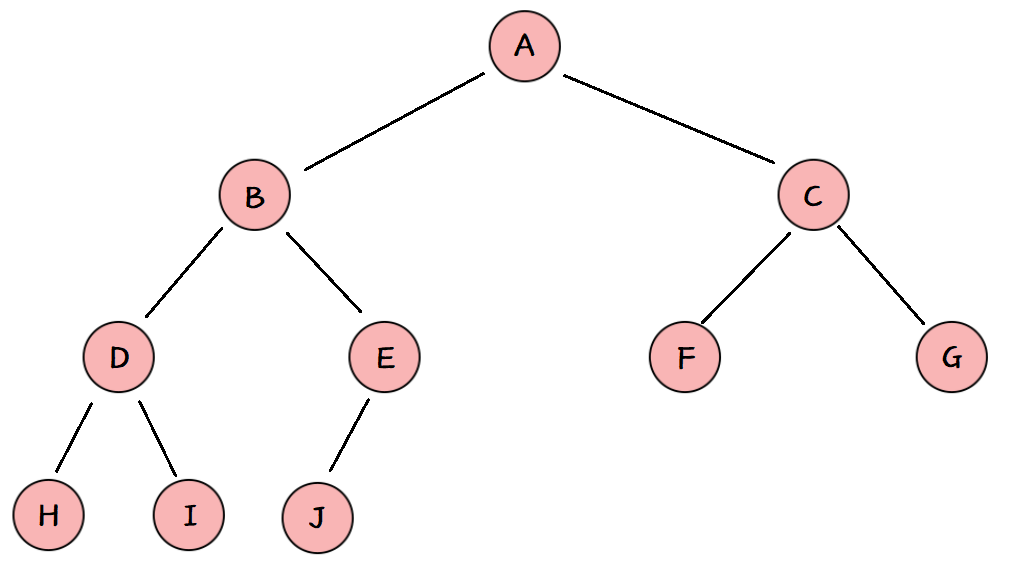
以上图为例。
- 首先从第一个非叶子节点开始执行向下调整算法,这里的第一个非叶子节点是 E ,以它为根节点执行向下调整算法,调整后 E-J 就是一个大堆
- 依次向前遍历,接下来对 D 进行向下调整,调整后 D-H/I 就是一个大堆
- 对 C 进行向下调整,调整后 C-F/G 就是一个大堆
- 对 B 进行调整,此前它的两个子树都已调成大堆,所以调整后 B-D/E-H/I/J 就是一个大堆
- 对 A 进行调整,此前它的两个子树都已调成大堆,所以调整后大堆就建好了。
建堆的实现代码如下:
//将给定的数组转移到堆里来,并调整为大堆
void HeapInit(HP* php, HPDataType* a, int n)
{
//创建堆并导入数据
assert(php);
php->a = (HPDataType*)malloc(sizeof(HPDataType) * n);
if (php->a == NULL)
exit(-1);
memcpy(php->a, a, sizeof(HPDataType) * n);
php->capacity = n;
php->sz = n;
//建大堆
for (int i = (php->sz - 1 - 1) / 2; i >= 0; --i)
{
AdjustDown(php->a, php->sz, i);
}
}

以上图为例来讨论建堆的时间复杂度。
假设树高为 k(k = 5),
从第四层最后一个非叶子节点开始调整,
第四层每个节点最多需要调整 1 次,有 24-1 个节点,
第三层每个节点最多需要调整 2 次,有 23-1 个节点,
第二层每个节点最多需要调整 3 次,有 22-1 个节点,
第一层每个节点最多需要调整 4 次,有 21-1 个节点,
抽象出来,第 i 层最多需要调整 k - i 次,有 2i-1 个节点,
所以第 i 层的调整次数 Si = 2i-1 × (k - i),
所以总调整次数 S = S1 + S2 + … + Sk-1,
其中 k = log2n,
利用错位相减法求得 S = n - log2n - 1。
所以建堆的时间复杂度为
O(n)
堆的插入
假设现在有一个大堆,想往堆里插入一个数据:

首先将数据放到堆尾,也就是数组末尾,
然后对该数据进行向上调整,
与向下调整相反,
每次拿该节点与父亲节点比较交换,
直至调整完成。
代码如下:
//沿着路径向上调整
static void AdjustUp(HPDataType* a, int child)
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (a[parent] < a[child])
{
Swap(&a[parent], &a[child]);
child = parent;
parent = (child - 1) / 2;
}
else
return;
}
}
//插入
void HeapPush(HP* php, HPDataType x)
{
assert(php);
if (php->sz == php->capacity)
{
HPDataType* tmp = (HPDataType*)realloc(php->a, sizeof(HPDataType) * php->capacity * 2);
if (tmp == NULL)
exit(-1);
php->a = tmp;
php->capacity *= 2;
}
php->a[php->sz] = x;
++php->sz;
AdjustUp(php->a, php->sz-1);
}
由于向上调整次数最多为层数,
所以插入的时间复杂度为 O(logn) 。
堆的删除
堆的删除是删除堆顶的数据。
先将堆顶的数据与最后一个数据进行交换,
然后删除最后一个数据,
再重新进行向下调整。
代码如下:
void HeapPop(HP* php)
{
assert(php);
assert(php->sz > 0);
Swap(&php->a[0], &php->a[php->sz - 1]);
--php->sz;
AdjustDown(php->a, php->sz, 0);
}
显然时间复杂度是 O(n)
堆排序
堆排序是一种极为优秀的排序算法。
其思想如下:
现在想对一组数据进行升序排序,
首先对这组数据建大堆 (排降序就建小堆),
此时堆顶的数据就是数组中最大的元素,
将堆顶最大的数据与数组末尾的数据进行交换,
然后除去已经排好的数据,
对剩余数据重复上述过程。
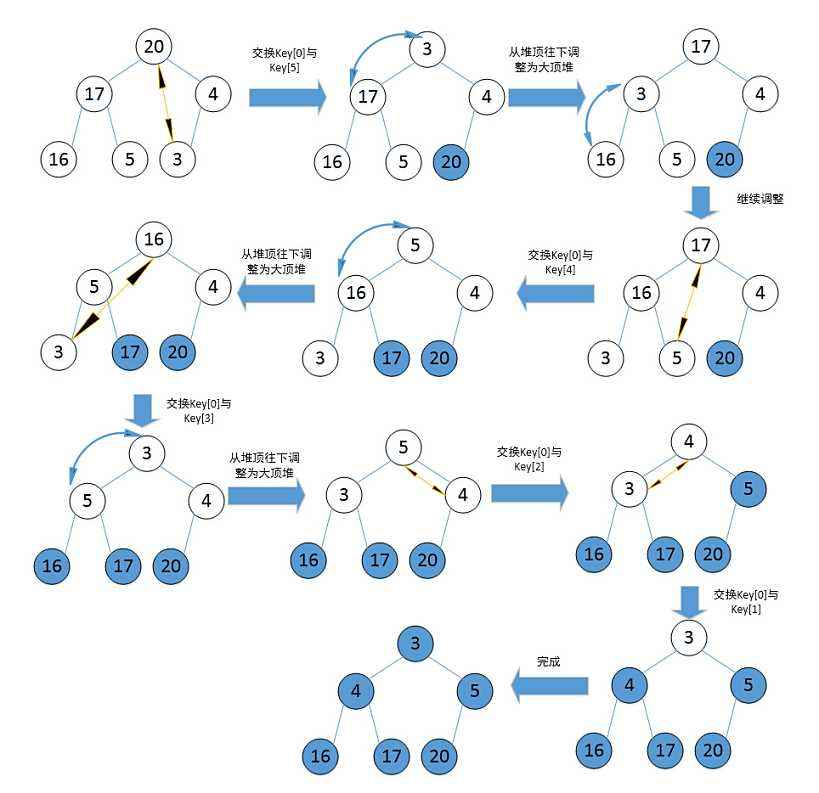
代码如下:
void Swap(int* x, int* y)
{
int tmp = *x;
*x = *y;
*y = tmp;
}
//向下调整算法
void AdjustDown(int* arr, int n, int parent)
{
int child = parent * 2 + 1;
while (child < n)
{
//大于号为大堆,小于号为小堆
if (child < n - 1 && arr[child + 1] > arr[child])
++child;
if (arr[child] > arr[parent])
{
Swap(&arr[parent], &arr[child]);
parent = child;
child = parent * 2 + 1;
}
else
break;
}
}
//降序每次要把最小的调到堆顶,所以要建小堆
//升序每次要把最大的调到堆顶,所以要建大堆
void HeapSort(int* arr, int sz)
{
for (int i = (sz - 1 - 1) / 2; i >= 0; i--)
AdjustDown(arr, sz, i);
int end = sz - 1;
while (end)
{
Swap(&arr[end], &arr[0]);
AdjustDown(arr, end, 0);
--end;
}
}
时间复杂度为 O(nlogn)
TopK问题的最优解
TopK 问题是指在含 N 个数的无序序列中找出其中最大的 K 个数。
很容易,因为我们只需要对这 N 个数进行降序排序,排序后的前 K 个数就是最大的 K 个数。
但是,尽管有多种优秀的排序算法供我们使用,但当 N 特别大,大到内存无法一次性容纳这 N 个数,此时简单的排序就不那么可靠。
一种解决方案是将 N 个数据平均分为若干份,分别对每份数据进行排序,然后排序好的若干组进行归并排序,此时得到的 N 个数据就是有序的。显然这种解决方案开销非常大。
另一种解决方案是,先取出其中的 K 个元素,将这 K 个数建成小堆,那么堆顶的数就是这 K 个数中最小的数。然后将剩下的 N - K 个数依次与堆顶的数进行比较,如果比堆顶的数小,那绝不可能是最大的前 K 个数;如果比堆顶的数大,那么该数就有可能是 K 个数之一,这时就替换掉堆顶的数据,此时堆就破坏了,所以还需要重新建堆。遍历结束,堆中的 K 个数就是 TopK 。
代码如下:
void TopK(int* arr, int sz, int k) {
//建小堆
int* topK = (int*)malloc(sizeof(int) * k);
memcpy(topK, arr, sizeof(int) * k);
for (int i = (k - 1 - 1) / 2; i >= 0; --i)
AdjustDown(topK, k, i);
for (int i = k; i < sz; ++i) {
if (topK[0] < arr[i]) {
topK[0] = arr[i];
AdjustDown(topK, k, 0);
}
}
for (int i = 0; i < k; ++i)
printf("%d ", topK[i]);
free(topK);
}
时间复杂度为 O(NlogK)
空间复杂度为 O(K)
边栏推荐
- 张成分析(spanning test):portfolio_analysis.Spanning_test
- 科研笔记(五) SLAC WiFi Fingerprint+ Step counter融合定位
- Scientific research notes (5) SLAC WiFi Fingerprint+ Step counter fusion positioning
- 斐波那契数列
- 洛谷P2670扫雷游戏
- 复制延迟案例(2)-读己之写
- 科研笔记(八) 深度学习及其在 WiFi 人体感知中的应用(上)
- 深蓝学院-视觉SLAM十四讲-第六章作业
- 【FreeRTOS】12 任务通知——更省资源的同步方式
- SCI writing strategy - with common English writing sentence patterns
猜你喜欢

论文速读:Homography Loss for Monocular 3D Object Detection

如何解决QByteArray添加quint16双字节时错误?
如何将PDF中的一部分页面另存为新的PDF文件

ScholarOne Manuscripts提交期刊LaTeX文件,无法成功转换PDF!
数学建模学习(76):多目标线性规划模型(理想法、线性加权法、最大最小法),模型敏感性分析

1318_将ST link刷成jlink

线代005
Reinforcement Learning (Chapter 16 of the Watermelon Book) Mind Map

Deep blue college - handwritten VIO operations - the first chapter
MapFi论文架构整理
随机推荐
吴恩达机器学习系列课程笔记——第七章:正则化(Regularization)
论文速读:Homography Loss for Monocular 3D Object Detection
温暖的世界
OpenPCDet environment configuration of 3 d object detection and demo test
SCI writing strategy - with common English writing sentence patterns
STM32 OLED显示屏
区间和 离散化
列表总结
EasyCVR视频广场切换通道,视频播放协议异常的问题修复
P1192 台阶问题
洛谷P2437蜜蜂路线
DOM系列之 click 延时解决方案
[Win11] PowerShell无法激活Conda虚拟环境
Qt编写物联网管理平台49-设备模拟工具
Deep Blue Academy - 14 Lectures on Visual SLAM - Chapter 7 Homework
如何让固定点的监控设备在EasyCVR平台GIS电子地图上显示地理位置?
【C语言程序】求直角三角形边长
1318_将ST link刷成jlink
The most authoritative information query steps for SCI journals!
吴恩达机器学习系列课程笔记——第八章:神经网络:表述(Neural Networks: Representation)