当前位置:网站首页>Ut2013 learning notes
Ut2013 learning notes
2022-07-03 10:29:00 【IFI_ rccsim】
Challenge description
A.SPL Challenge
SPL The challenge requires every team to have players , If there are six teams participating , Each team contributes One or two substitute players . If you use two players from the same team , They are playing on the same side . Both teams are composed of randomly selected substitutes , Each contestant participates 4 A substitute game , Every game lasts 5 minute . Shorter games are used to allow more games to be played within a specified time . In the normal SPL In the game , The goalkeeper is designated as a goalkeeper at the beginning of the game . In the challenge , The first defender to enter the penalty area became the goalkeeper of the game .
During the challenge , Players are allowed to communicate with each other using a simple protocol , But this kind of communication is unnecessary . The agreement allows communication of the player and the position of the ball , Variance of player and ball position ( uncertainty ), The speed of the ball , Time since the last time I saw the ball , And whether the robot falls or is punished .
SPL The challenge uses two indicators to score : Average goal difference and average score of three referees . These two scoring indicators are combined to determine SPL Challenge champion . Human referees are used to help Identify good teamwork ability in agents , And in a limited number of games Reduce the influence of random variance . For every game , Every referee is asked to score every player , Score at 0( Bad ) To 10( good ) Between . The judges were asked to focus on the ability of teamwork , Not personal skills , Such a robot with low skills can still get high scores for good teamwork .
B. Two dimensional challenge
about 2D Substitute challenge , Every team has contributed Two substitute players , Two of the teams are composed of substitutes . The competition includes two 5 Half a minute , Team has 7 player , Not the standard one 11 player . The number of players has been changed , Because most teams release based on the same code , It's for 11 Player teams provide default formation , Provide implicit coordination for these teams . The seventh player of each team is from agent2d Our goalkeeper , Coach is not used in the challenge . Substitute players are encouraged to use default agents 2d Communication protocol for communication , But it's not necessary .
Players pass Average goal difference score ; There is no human referee . In order to accurately measure their performance , Each team plays at least one game with each other's opponents . A total of nine teams participated in this challenge . Game pairing is a Greedy algorithm Select the , The algorithm tries to balance the number of cooperation and confrontation between agents from different teams , Such as Alg.1 Shown . The algorithm is universal , It can be applied to other special team cooperation settings . When all agent With other teams At least one game when , The algorithm stops .
C.3D Challenge
about 3D Substitute challenge , Each team contributed to a match Two substitute players . The game lasted for two 5 Half a minute , Both teams are made up of substitute players . In the challenge There is no goalkeeper To increase the possibility of scoring .
Every substitute can communicate with his teammates about the ball and his position , But using this protocol is optional . The challenge score is only obtained by the agent in all competitions Average goal difference decision . During the challenge, there were four temporary matches ,10 All teams participated in every competition . The team matching of the competition is made by Alg.1 decision . So every substitute player plays at least one game .

Greedy algorithm gets Locally optimal solution , Select the conditions that should meet the local optimization
Dynamic programming is to find the global optimal solution
The basic idea : 1. Build a mathematical model to describe the problem
2. Divide the problem into several sub problems
3. Solve every subproblem , Get the local optimal solution of the subproblem
4. The local optimal solution corresponding to the subproblem is synthesized into a near of the original whole problem Quasi optimal solution
Analysis of competition results
* SPL( Standard group ) match
* drop-in challenges The team with good performance in the team has strong cooperation ability , But not necessarily the best low-level skills
* On the whole , Race results and drop-in challenge Is positively correlated
* 2D match
* The race data sample is not enough , Later, the teams played against UT The standard team matches are 1000 site , The average value and standard deviation of goal difference are recorded
* drop-in challenge There is no significant direct relationship with the race results , But in the standard team competition ( Zheng sai ) Teams that do well in tend to do well in drop-in challenge Better performance in
* drop-in challenge An important link is adaptation ( From other teams ) Teammate
* Dynamic role assignment can be improved in drop-in challenge Performance in
* 3D match
* drop-in challenge There is no significant direct relationship with the race results , But in drop-in challenge The team that performs well in the team tends to compete in the standard team ( Zheng sai ) Better performance in
* Drop-in Challenge Strategic analysis
* Build four teams to run and V-C The same as described in part drop-in match
* Dribble: Never play football , With ball only
* DynamicRoles: Dynamic role assignment
* NoKickoff: Do not pass to the side of the ball to kick off ?
* UTAustinVilla: The program used in the competition
* Dribble > UTAV > NoKickoff > DynamicRoles
* Conclusion
* When no teammate kicks off, passing it to the side of the ball to kick off will help improve the performance (UTAV > NoKickoff)
* play football / Passing will negatively affect the result . Probably because UT Low level skills are better than drop-in Teammate , So passing the ball to them will reduce the level of the team
边栏推荐
- An open source OA office automation system
- [LZY learning notes -dive into deep learning] math preparation 2.5-2.7
- [C question set] of Ⅵ
- Matplotlib drawing
- 20220605数学:两数相除
- Leetcode刷题---189
- [graduation season] the picture is rich, and frugality is easy; Never forget chaos and danger in peace.
- 20220603 Mathematics: pow (x, n)
- Handwritten digit recognition: CNN alexnet
- 20220610其他:任务调度器
猜你喜欢

Pytorch ADDA code learning notes

Raspberry pie 4B installs yolov5 to achieve real-time target detection
Yolov5 creates and trains its own data set to realize mask wearing detection
CV learning notes - deep learning

An open source OA office automation system

Leetcode - 1172 plate stack (Design - list + small top pile + stack))

Tensorflow—Neural Style Transfer

CV learning notes - edge extraction
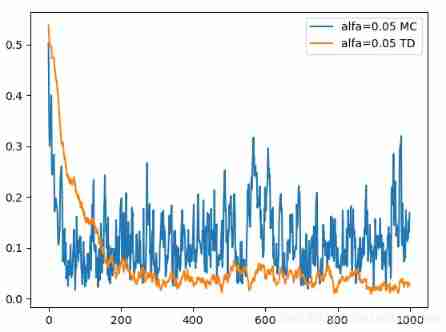
4.1 Temporal Differential of one step
![[LZY learning notes -dive into deep learning] math preparation 2.5-2.7](/img/57/579357f1a07dbe179f355c4a80ae27.jpg)
[LZY learning notes -dive into deep learning] math preparation 2.5-2.7
随机推荐
CV learning notes - camera model (Euclidean transformation and affine transformation)
CV learning notes - edge extraction
[LZY learning notes -dive into deep learning] math preparation 2.5-2.7
3.1 Monte Carlo Methods & case study: Blackjack of on-Policy Evaluation
Leetcode - the k-th element in 703 data flow (design priority queue)
Leetcode-513:找树的左下角值
Tensorflow—Image segmentation
二分查找法
Several problems encountered in installing MySQL under MAC system
Hands on deep learning pytorch version exercise solution - 2.4 calculus
Leetcode - 1172 plate stack (Design - list + small top pile + stack))
侯捷——STL源码剖析 笔记
20220609其他:多数元素
【SQL】一篇带你掌握SQL数据库的查询与修改相关操作
Free online markdown to write a good resume
Seata分布式事务失效,不生效(事务不回滚)的常见场景
Markdown latex full quantifier and existential quantifier (for all, existential)
1. Finite Markov Decision Process
Out of the box high color background system
MySQL报错“Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggre”解决方法