当前位置:网站首页>Language model
Language model
2022-07-05 12:39:00 【NLP journey】
Language model
As long as the word model is mentioned , I will feel very abstract , But if it is understood as a series of functions or mappings , There will be a more intuitive understanding . For language models , Input is a sentence , The output is the probability that this sentence exists . This function from output to output , It can be regarded as a model . This is a personal loose understanding .
The content of this blog is as follows ( Content comes from collins stay coursera Handouts for online courses ):
- brief introduction
- Markov model
- Ternary language model (Trigram Language Model)
- Smoothing
- Other themes
brief introduction
First, a corpus containing several sentences is given , Define a vocabulary V, It contains all the words that appear in the corpus . for example ,V It might look like this :
V={the,dog, laughs, saw, barks, cat,…}
actually V It could be very big , But we think it is a finite set . Such a sentence can be expressed as
x1x2x3…xn
among xn For a stop stop,x1…xn-1 Belong to V. for example
the dog barks stop
the cat saw the dog stop
the stop
cat cat cat stop
stop
…
Use V+ Indicates all uses V Words generated sentences in . Because sentences can be of any length , therefore V+ Is an infinite set .
To define a ( Language model ): A language model contains a finite set V, And a mapping p(x1,x2,…,xn) Satisfy :
1. To any ren It means <x1,x2,...,xn>∈V+,p(x1,x2,...,xn)>0
2.
therefore p(x1,x2,…xn) It's a V+ A probability distribution on .
So how to find the probability value of each sentence of this probability distribution ? Definition c(x1,x2…xn) For sentences x1x2..xn The number of occurrences in the corpus ,N Is the number of all sentences in the corpus . Obviously we can use p(x1,x2…xn)=c(x1…xn)/N Ask for a sentence x1,x2…xn Probability . But this simple method is not suitable for sentences in the corpus , Its probability will be equal to 0. Although all the words in the sentence belong to V Of .
Markov model
Markov model of fixed length sequence
Markov model is actually a conditional independence assumption . In seeking p(x1,x2…xn) when ,
p(x1,x2…xn)=p(x1)p(x2|x1) *p(x3|x1x2) *p(x4|x1x2x3) … p(xn|x1x2…xn-1)
First order Markov hypothesis p(x3|x1x2)=p(x3|x2)… That is, each conditional probability above is equal to the conditional probability of the previous element . be :
p(x1,x2….xn)=p(x1)*p(x2|x1) *p(x3|x2)…. *p(xn|xn-1)
The second-order Markov assumption is that the conditional probability of each term is equal to the conditional probability of the first two terms .
namely
p(x1,x2…xn)=p(x1)*p(x2|x1) *p(x3|x1x2) *p(x4|x2x3)….p(xn|xn-2,xn-1)
And so on
Markov model of variable length Markov sequence
Variable length Markov model is a model of sequence generation :
1 initialization i=1, meanwhile x0=x−1=*(x0 and x−1 It can be regarded as two virtual nodes )
2 According to the probability p(xi|xi−2,xi−1) Generate xi
3 If xi=STOP, Just return the sequence x1…xi. otherwise , Set up i=i+1 And repeat the steps 2.
Trigram Language Models( Ternary language model )
Basic concepts
p(x1,x2,x3….xn)=∏ni=1p(xi|xi−2,xi−1)
among x0=x−1=*.xn=STOP.
Definition ( The ternary model ): A three-dimensional model contains a finite set V, And parameters :p(w|u,v). For each u,v,w If w∈v∪STOP meanwhile u,v ∈v∪∗, Under the ternary model , The probability of a sentence is p(x1,x2…xn)=∏ni=1p(xi|xi−2,xi−1) among x0 And x−1 Are pseudo nodes *.
There is this model , The problem now is how to estimate the parameters of the model according to the corpus p(w|u,v).
Maximum likelihood estimation
For parameter estimation , Of course, the simplest is to use maximum likelihood estimation . Specifically for p(w|u,v)
In statistical corpus uvw And uv The number of times , Then divide and you get p(w|u,v).
Such as p(barks|the,dog)=c(the,dog,barks)/c(the,dog).
But this simple parameter estimation method has the following two problems :
- If the molecular term is zero , Then probability is defined as 0. That is, there is no corresponding phrase in the corpus . It may be that the corpus is not large enough and the data is sparse .
- If the molecule equals zero , The probability value cannot be calculated .
Evaluation of the model
For a good model , How to evaluate its quality
The method is to give a test data set , There are m A sentence s1,s2,…,sm. For each sentence si, Calculate the probability that it will be generated under the current model . Quadrature the probability of all sentences . namely :
∏mi=1p(xi)
The bigger this is , The better the model .
Smoothing of parameter estimation
Previously, we mentioned the problem of parameter estimation caused by sparse data . Two methods are discussed here , The first is linear interpolation, The second is discounting methods.
linear interpolation
Definition trigram,bigram, as well as unigram The maximum likelihood estimate is :
p(w|u,v)=c(u,v,w)/c(u,v)
p(w|v)=c(v,w)/c(v)
p(w)=c(w)/c()
linear interpolation Is to use three estimates , By defining
p(w|u,v)=c1*p(w|u,v)+ c2 * p(w|v) +c3*p(w)
among c1>=0;c2>=0;c3>=0 And
c1+c2+c3=1;
For how to choose the right c1,c2,c3. One way is to use a validation set of data , Selection of the c1,c2,c3 Make the probability of verification set maximum . Another method is another c1=c(u,v)/(c(u,v)+t),
c2=(1-c1)* c(v)/(c(v)+t)),c3=1-c1-c2. among t Is a pending parameter .t The value of can still be maximized validation set .
discounting Methods
Consider a binary model . That is, find the parameters p(w|v)
So let's define a discounted counts. For any c(v,w) as long as c(v,w)>0, Just define
c∗(v,w)=c(v,w)-r;
among r It's a 0 To 1 Number between .
Then for any p(w|v)=c∗(v,w)/c(v); This is equal to not equal to 0 Of c, All extracted from it r. Then you can put r Assigned to those c be equal to 0 's phrases , Prevent zero .
边栏推荐
- Using docker for MySQL 8.0 master-slave configuration
- Interviewer: is acid fully guaranteed for redis transactions?
- Two minutes will take you to quickly master the project structure, resources, dependencies and localization of flutter
- GPON other manufacturers' configuration process analysis
- [hdu 2096] Xiaoming a+b
- Iterator details in list... Interview pits
- GPS data format conversion [easy to understand]
- SENT协议译码的深入探讨
- Cypher syntax of neo4j graph database
- MySQL transaction
猜你喜欢
Take you two minutes to quickly master the route and navigation of flutter
Redis clean cache
UNIX socket advanced learning diary -ipv4-ipv6 interoperability
Pytoch loads the initialization V3 pre training model and reports an error
Automated test lifecycle
Making and using the cutting tool of TTF font library
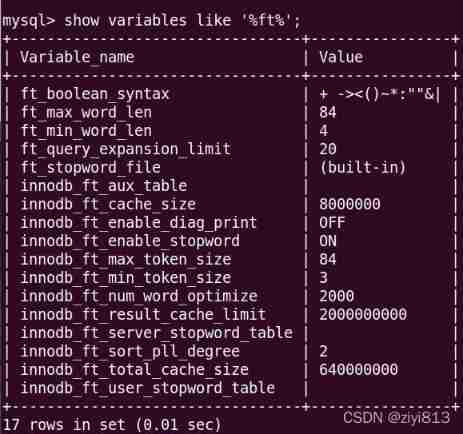
MySQL index (1)
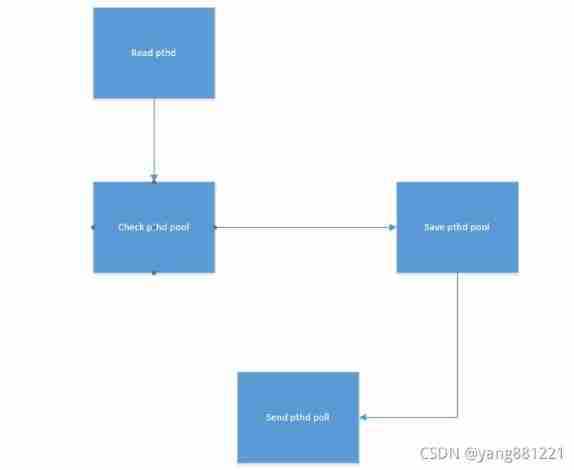
Principle of universal gbase high availability synchronization tool in Nanjing University
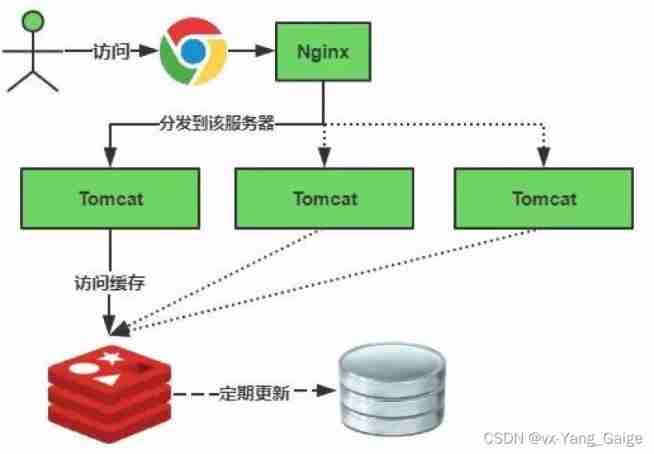
Distributed cache architecture - cache avalanche & penetration & hit rate
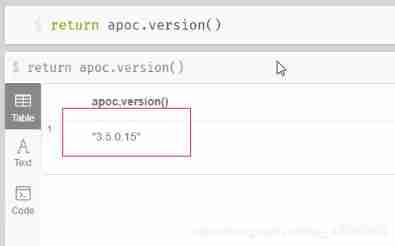
Migrate data from Mysql to neo4j database


随机推荐
Redis highly available sentinel cluster
Volatile instruction rearrangement and why instruction rearrangement is prohibited
POJ-2499 Binary Tree
MySQL index - extended data
byte2String、string2Byte
Understand redis persistence mechanism in one article
PXE启动配置及原理
[HDU 2096] 小明A+B
Third party payment interface design
MySQL installation, Windows version
Learn garbage collection 01 of JVM -- garbage collection for the first time and life and death judgment
End to end neural network
Swift - add navigation bar
C language structure is initialized as a function parameter
Learn JVM garbage collection 02 - a brief introduction to the reference and recycling method area
Master-slave mode of redis cluster
Time conversion error
Full text search of MySQL
Pytoch counts the number of the same elements in the tensor
Take you hand in hand to develop a service monitoring component