当前位置:网站首页>window10下半自动标注
window10下半自动标注
2022-08-02 14:02:00 【weixin_50862344】
前言
我看了一眼我们项目的标签很多不行,得重新标注。想借助一下自动标注或者半自动标注救救一万多近两万张照片
方法1:easyDL智能标注
(1)借助百度easyDL进行标注
- 选择EasyDL图像–>物体检测
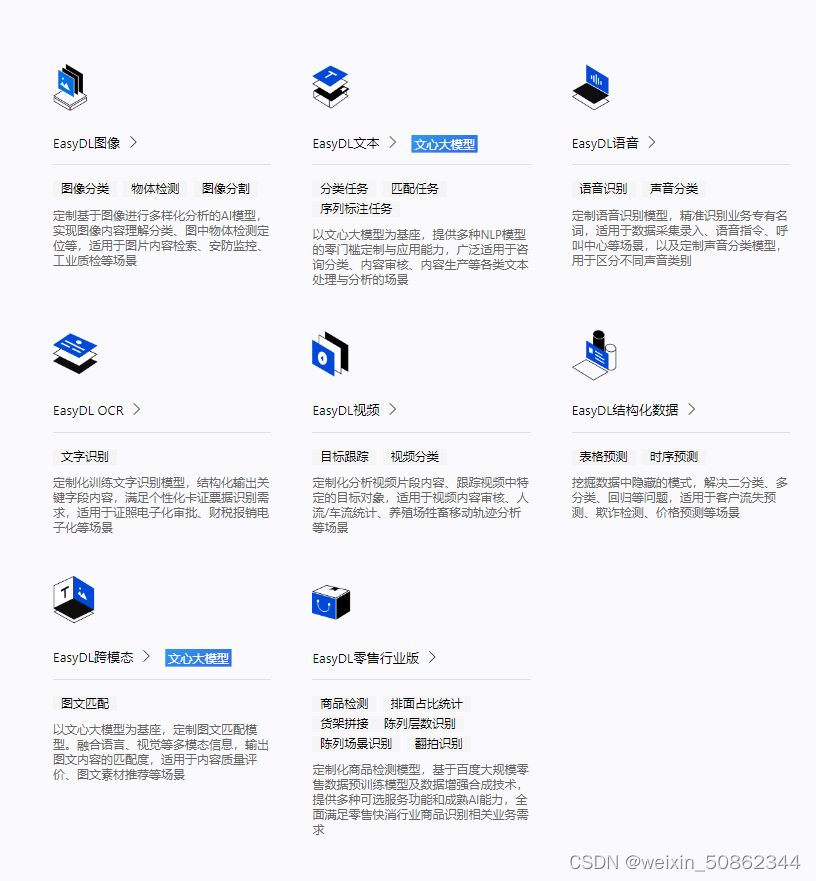
我是做图像识别所以选择EasyDL图像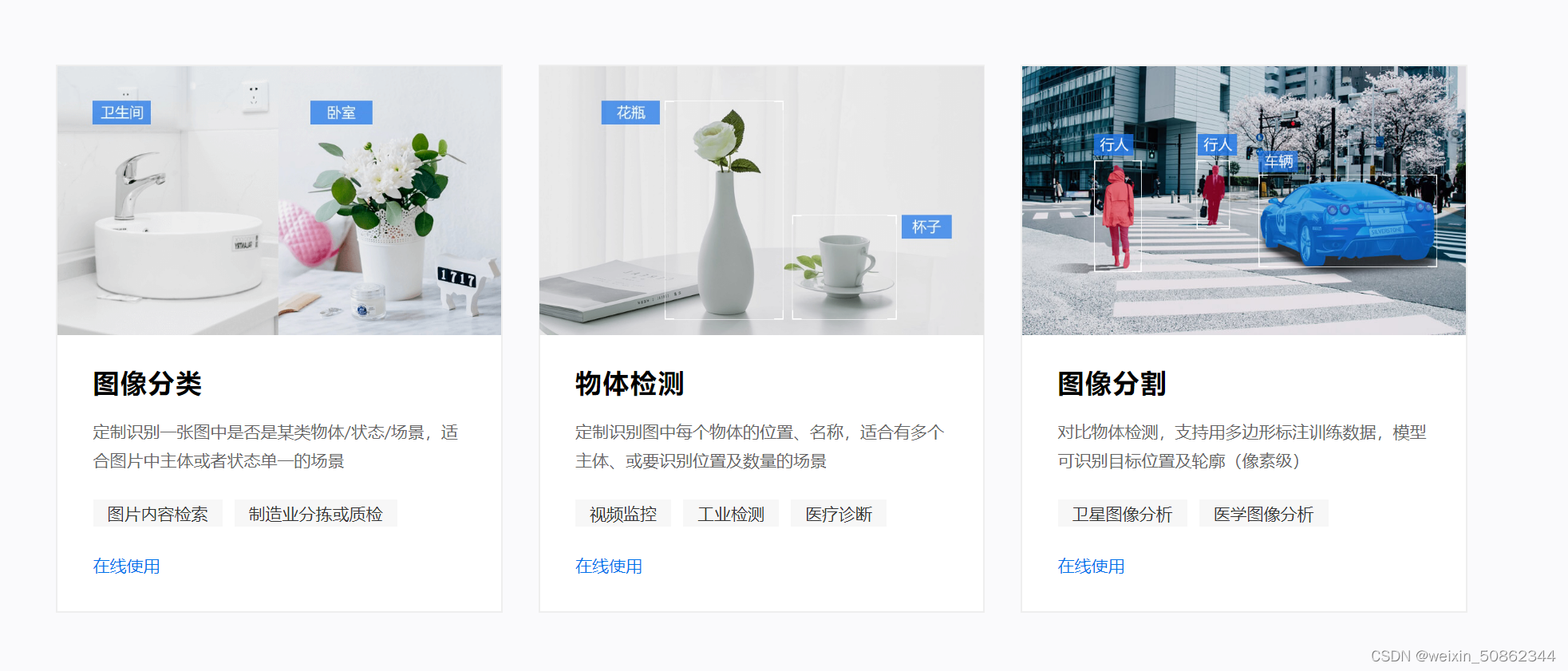
- 简单的注册信息之后导入图片或者是压缩包就可以进行标注了
- 我标注了百来张就想试试自动标注
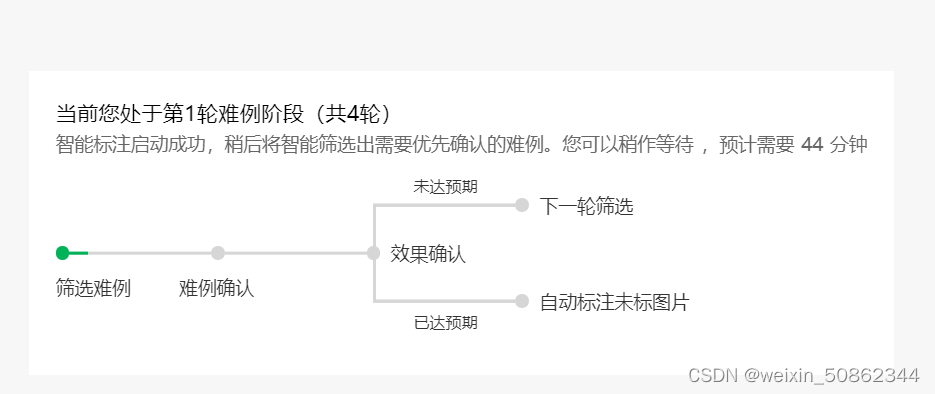
实际上后面还是要更正和修正
最后可以在数据总览看见如下图的结果 - 点击红圈圈出的“立即前往”,进入EasyDAata,点击 “立即使用”,再点击“导出”
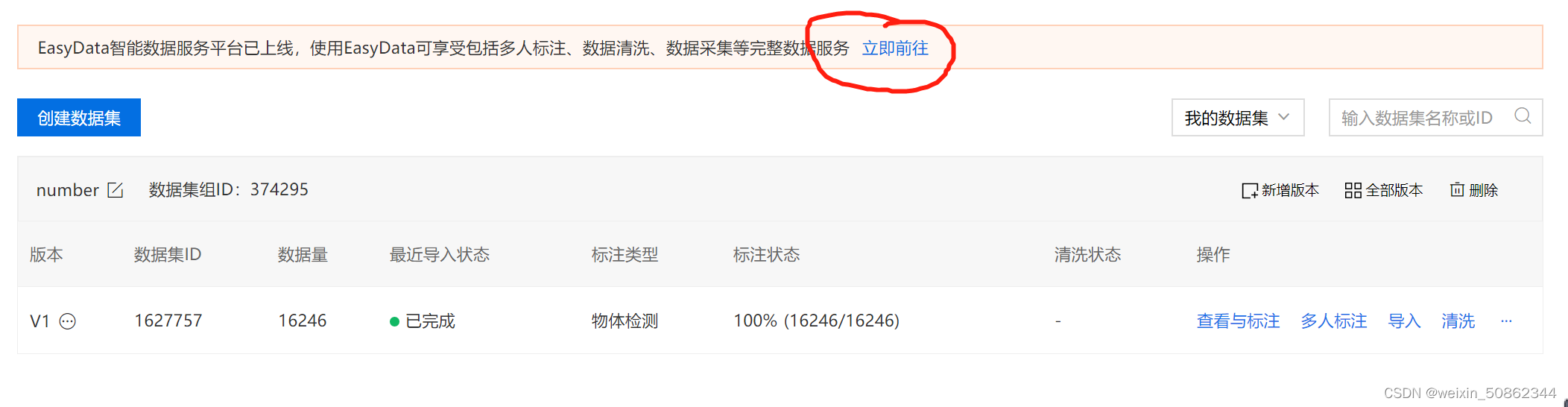
- 在等待一段时间之后就可以下载了
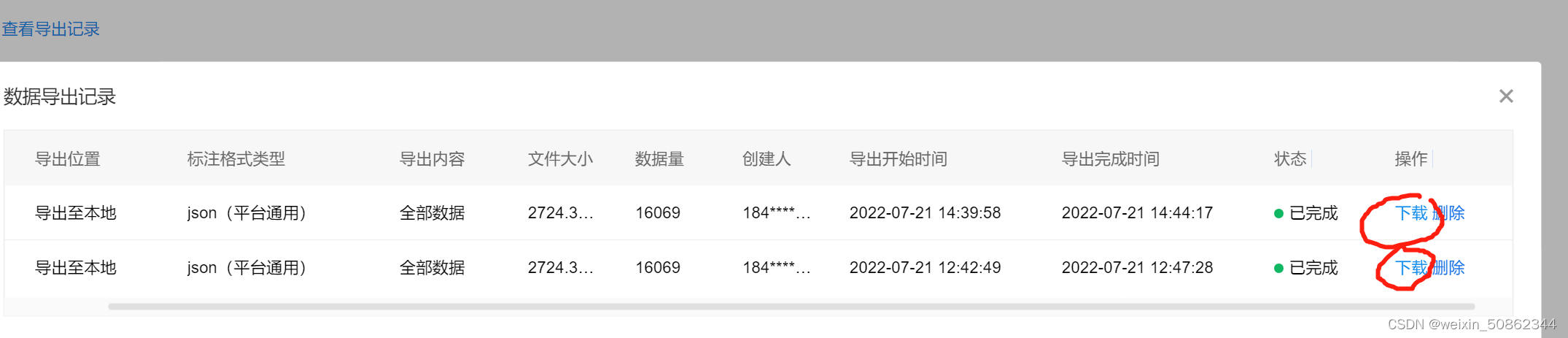
最后放上一张结果图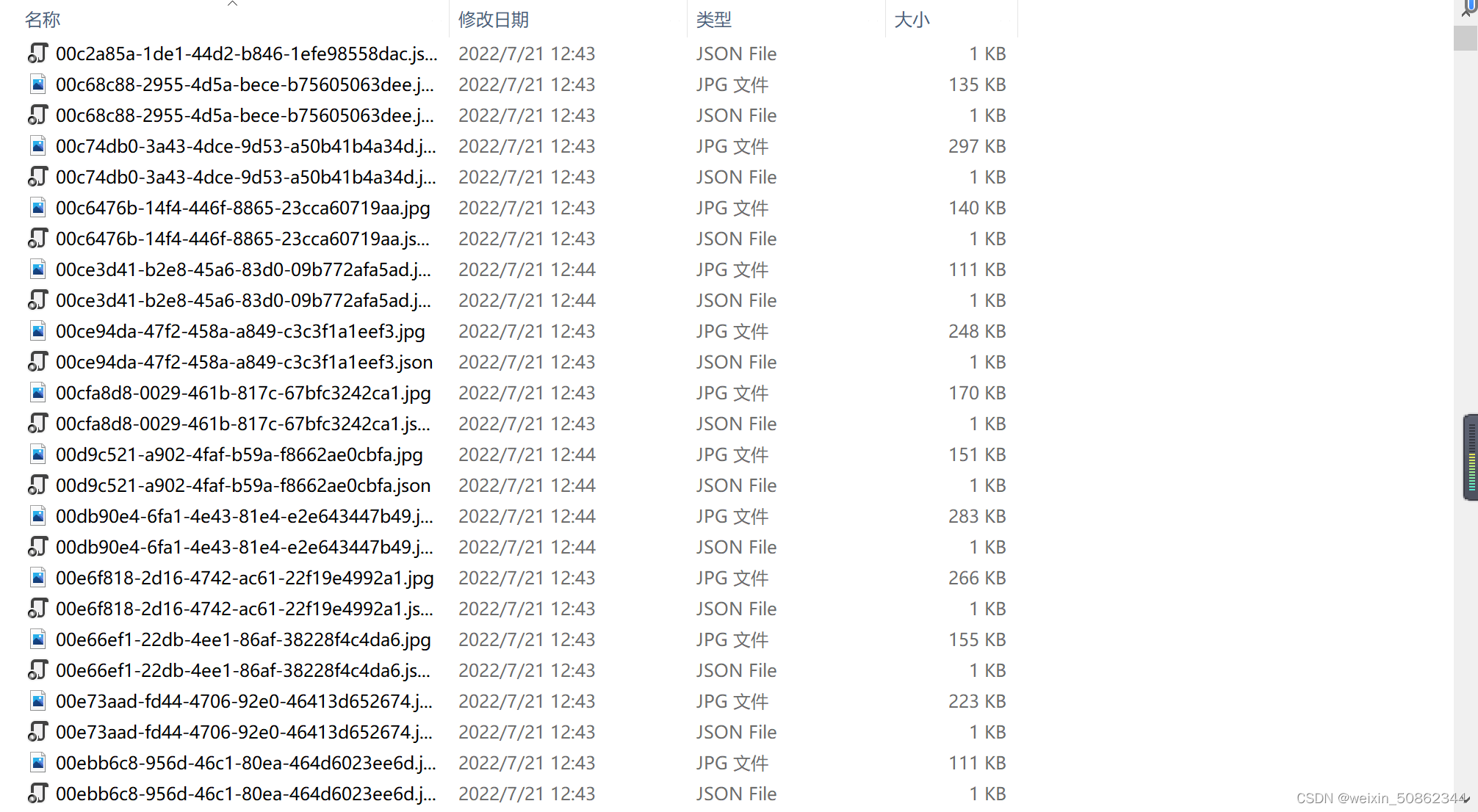
它是一一对应的
后面估计还得写一个脚本,把两种文件分开
我写的脚本都会因为版权限问题失败,后面发现我自己好呆。直接在搜索栏里面输入.jpg或者是.json,然后全选复制到另一个文件夹就行了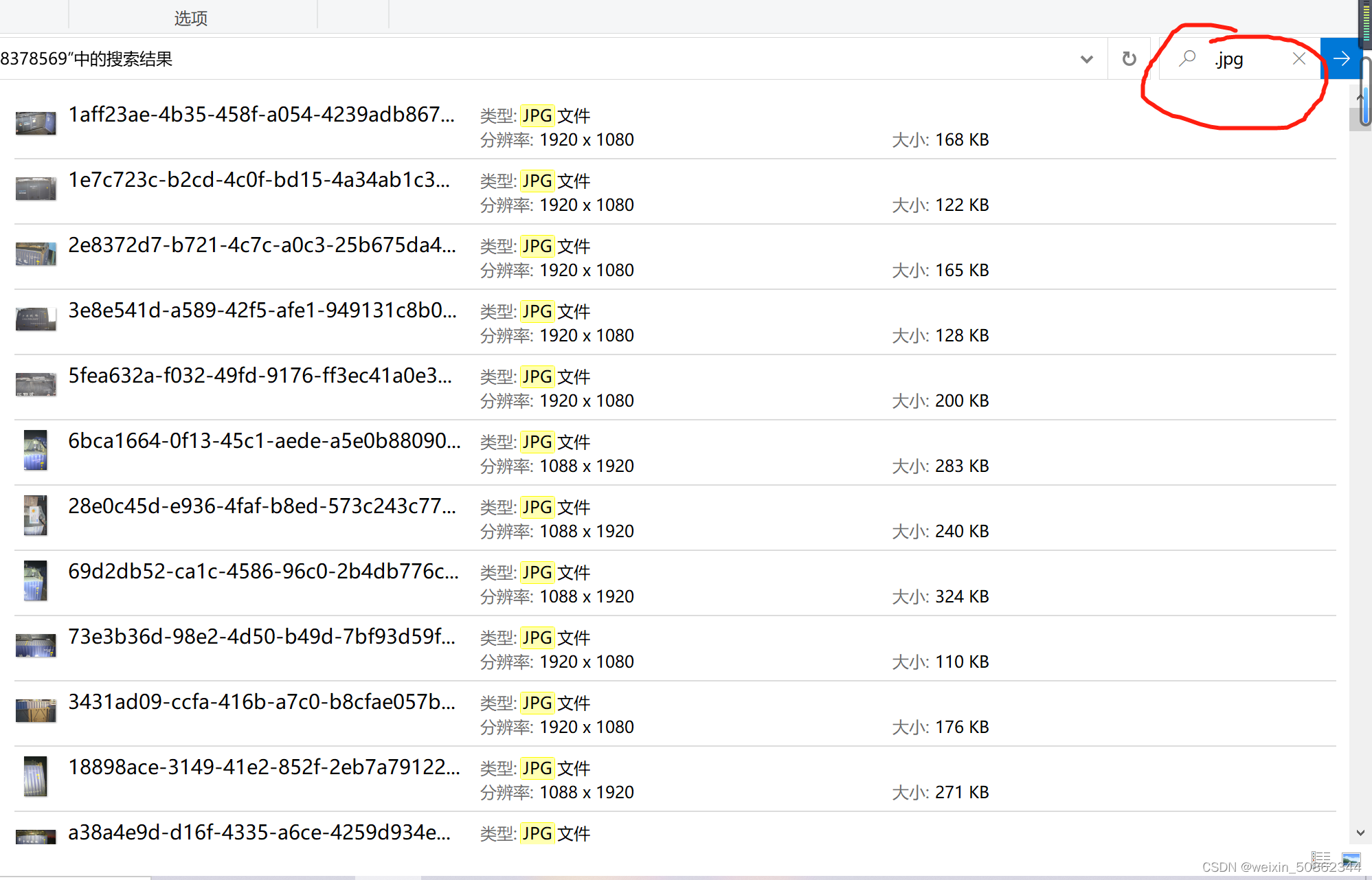
方法2:使用labelimg和pytorch框架下的yolov5实现自动标注
(1)环境配置
环境配置的就不说了
框架选用的也是pytorch
(2)思路
先训练一个小批量数据的模型,然后使用这个权重进行识别并进行标注
!!!提醒一下大家小样本的训练集的数量,也不能真的太小(建议是有千来张,建议是根据自己的数据集)
出于两方面的考虑:①样本太小训练效果不好,到后面有可能变成半手动(出力不讨好)
②可以适当增加一些比较特殊的训练样本以增加训练效果
(3)步骤
1 )首先就是先训练一个小的权重
- 先利用之前标注好的文件进行yolov5训练
不知道怎么训练的看看Pytorch搭建YoloV5目标检测平台
但是有一个问题就是博主给的代码和官方给的代码是有差异的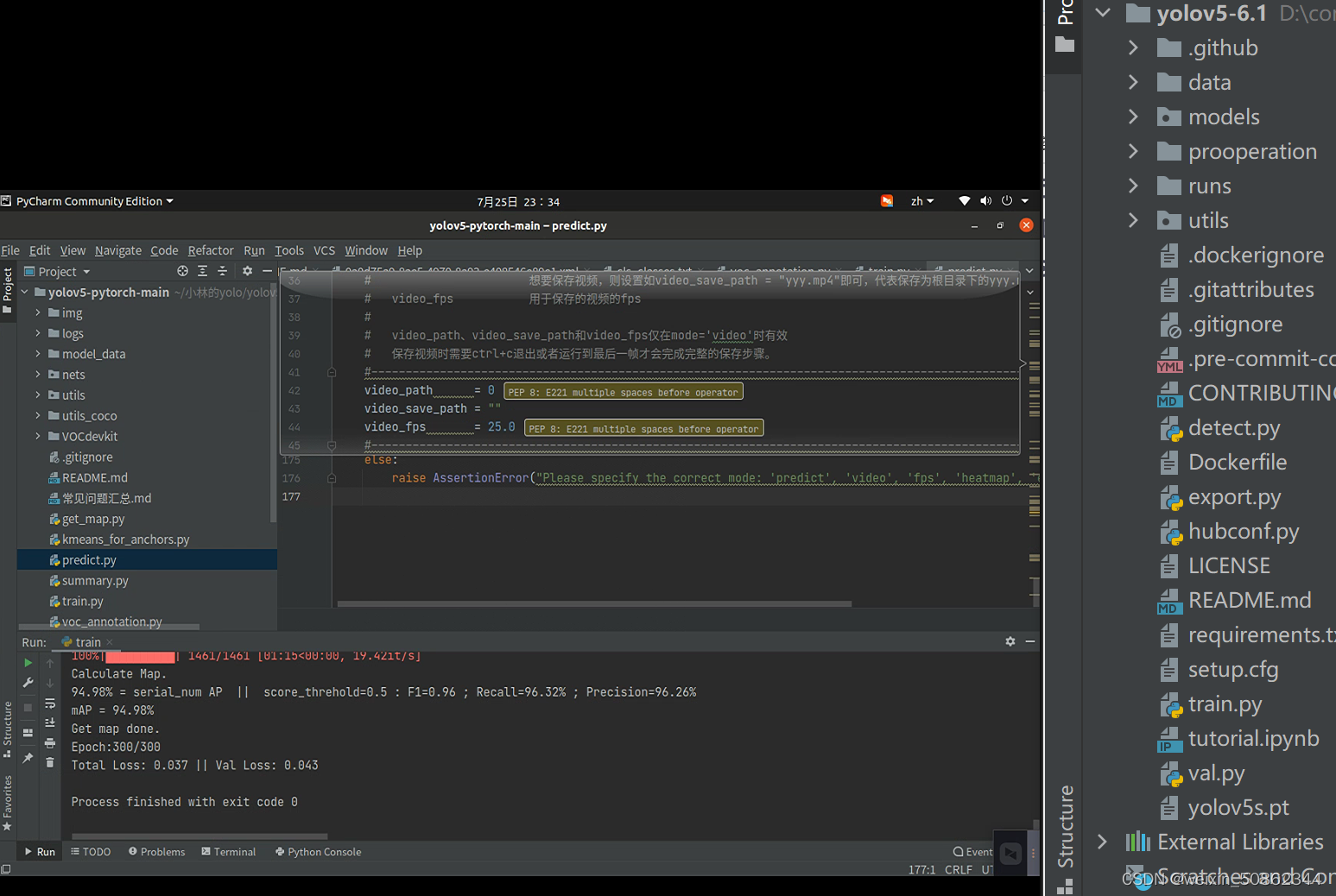
左边是该博主的代码右边是在官网下载的,而且生成的权重文件是pth类型,官网下载的生成的好像是pt文件
- 如果只按照这个博主来的接下来就得考虑pth转pt文件了
下次一定写个脚本!!!
- 使用官方的代码的话
可以看看我之前写的这篇可能有些地方写得不清楚,可以私信我或者是直接评论,看到了(我会的)一定解答
2)开始自动标注
我试了很多代码最后效果比较好的就是神秘cv男的自动标注整体操作比较简单,还有视频讲解。
操作下:
- 直接在github下载在这
- 然后放入yolov5的文件夹中
pip Install natsort因为之前没下载过报红了- 给个示意图吧!
一万六千张照片一会就搞完了!但是我发现有一个比较麻烦的问题是他只能在window系统下运行,如果在linux(我用的是ubantu)就会出现xml文件进入不了文件夹子!!!
下次一定改改!下次一定下次一定!
3)xml转成yolo(即txt)格式
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import glob
###!!!!!!!!!###
###(1)改类名
classes = ['number']
def convert(size, box):
dw = 1.0 / size[0]
dh = 1.0 / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_name):
###!!!!!!!!!###
#(2)修改为自己的xml路径
in_file = open('D:/computervision/ocr/data/xml_file/' + image_name[:-3] + 'xml') # xml文件路径
#(3)改txt路径
out_file = open('D:/computervision/ocr/data/txt/' + image_name[:-3] + 'txt', 'w') # 转换后的txt文件存放路径
f = open('D:/computervision/ocr/data/xml_file/' + image_name[:-3] + 'xml')
xml_text = f.read()
root = ET.fromstring(xml_text)
f.close()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in classes:
print(cls)
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
if __name__ == '__main__':
###!!!!!!!!!###
###(4)改jpg文件路径
for image_path in glob.glob("D:/computervision/ocr/data/jpg_file/*.jpg"): # 每一张图片都对应一个xml文件这里写xml对应的图片的路径
image_name = image_path.split('\\')[-1]
convert_annotation(image_name)
这份代码存在一个问题就是没有xml文件(因为训练结果可能不一定保证每一张图片都能标注到),此时就要手动修正了!
方法3:基于PaddleHub和Labelimg
emmm…前面两种效果都很好 ,我就没仔细研究。下次一定!下次一定!
边栏推荐
- web测试和app测试的区别?
- MySQL数据库语法格式
- 【Tensorflow】AttributeError: module 'keras.backend' has no attribute 'tf'
- 史上最全!47个“数字化转型”常见术语合集,看完秒懂~
- 政策利空对行情没有长期影响,牛市仍将继续 2021-05-19
- How to solve mysql service cannot start 1069
- Data Organization---Chapter 6 Diagram---Graph Traversal---Multiple Choice Questions
- Sentinel源码(三)slot解析
- RowBounds[通俗易懂]
- Mysql's case the when you how to use
猜你喜欢
理解TCP长连接(Keepalive)

Flask框架的搭建及入门

Awesome!Alibaba interview reference guide (Songshan version) open source sharing, programmer interview must brush

The future of financial services will never stop, and the bull market will continue 2021-05-28

期货具体是如何开户的?

政策利空对行情没有长期影响,牛市仍将继续 2021-05-19

第二届中国Rust开发者大会(RustChinaConf 2021~2022)线上大会正式开启报名
如何解决1045无法登录mysql服务器

微信小程序-最近动态滚动实现
保姆级教程:写出自己的移动应用和小程序(篇三)
随机推荐
uview 2.x版本 tabbar在uniapp小程序里头点击两次才能选中图标
智能指针-使用、避坑和实现
网络安全第二次作业
Object detection scene SSD-Mobilenetv1-FPN
【Tensorflow】AttributeError: ‘_TfDeviceCaptureOp‘ object has no attribute ‘_set_device_from_string‘
How to solve 1045 cannot log in to mysql server
此次519暴跌的几点感触 2021-05-21
RHCE第一天作业
【学习笔记】数位dp
配置zabbix自动发现和自动注册。
Audio processing: floating point data stream to PCM file
Data Organization---Chapter 6 Diagram---Graph Traversal---Multiple Choice Questions
玉溪卷烟厂通过正确选择时序数据库 轻松应对超万亿行数据
政策利空对行情没有长期影响,牛市仍将继续 2021-05-19
线代:已知一个特征向量快速求另外两个与之正交的特征向量
Kunpeng devkit & boostkit
A number of embassies and consulates abroad have issued reminders about travel to China, personal and property safety
网络安全第一次作业(2)
Differences and concepts between software testing and hardware testing
MySQL数据库设计规范