当前位置:网站首页>哈希表、哈希函数、布隆过滤器、一致性哈希
哈希表、哈希函数、布隆过滤器、一致性哈希
2022-07-04 19:28:00 【wrdoct】
前言
哈希表、哈希函数、布隆过滤器、一致性哈希。
一、哈希表、哈希函数
哈希表中存入的数据是key,value类型的,哈希函数又名散列函数。
对于经典哈希函数来说,它具有以下5点性质:
1、输入域无穷大
2、输出域有穷尽
3、输入一样输出肯定一样
4、当输入不一样输出也可能一样(哈希碰撞)
5、不同输入会均匀分布在输出域上(哈希函数的散列性)
哈希表hash table(key,value) 的做法其实很简单,就是把Key通过一个固定的算法函数既所谓的哈希函数转换成一个整型数字,然后就将该数字对数组长度进行取余,取余结果就当作数组的下标,将value存储在以该数字为下标的数组空间里。
而当使用哈希表进行查询的时候,就是再次使用哈希函数将key转换为对应的数组下标,并定位到该空间获取value,如此一来,就可以充分利用到数组的定位性能进行数据定位。
【注】key的设计应该要保证种类很多,使得低频、中频、高频都有数量,这样才可以根据哈希函数的性质进行均分。
【注】例如,我们有一个10TB的大文件存在分布式文件系统上,存的是100亿行字符串,并且字符串无序排列,现在我们要统计该文件中重复的字符串。
假设,我们可以调用100台机器来计算该文件。 那么,现在我们需要怎样通过哈希函数来统计重复字符串呢。
首先,我们需要将这一百台机器分别从0-99标好号,然后我们在分布式文件系统中一行行读取文件(多台机器并行读取),通过哈希函数计算hashcode,将计算出的hashcode模以100,根据模出来的值,将该行存入对应的机器中。
根据哈希函数的性质,我们很容易看出,相同的字符串会存入相同的机器中。
然后我们就能并行100台机器,各自分别计算相应的数据,大大加加快统计的速度。
注意:这10TB文件并不是均分成100GB,分给100台机器,而是这10TB文件中不同字符串的种类,均分到100台机器中。如果还嫌单个机器处理的数据过大,可以按照同样的方法,在一台机器中并行多个进程,处理数据。
二、布隆过滤器
如果想要判断一个元素是不是在一个集合里,一般想到的是将所有元素保存起来,然后通过比较确定。但是还可以使用哈希表,可以通过一个Hash函数将一个元素映射成一个位阵列(Bit array)中的一个点。这样一来,我们只要看看这个点是不是1就可以知道集合中有没有它了。这就是布隆过滤器的基本思想。
布隆过滤器:k个哈希函数计算出k个散列值,之后取模描黑(数组中对应的比特位置为1),判断时还是k个哈希函数取模做判断,只有全为黑(全是1)才属于,有一个为白就不属于。所以有可能把白判断为黑,但绝不可能把黑判断为白。
三个公式:
n = 样本量;
p = 失误率;
m = 最优的位数组大小;
k = Hash 函数个数选取最优数目;
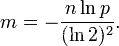
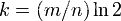
算法错误的认为某一原本不在集合中的元素却被检测为在该集合中(False Positives),该概率(失误率p)由以下公式确定: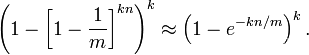
三、一致性哈希
以上的方法都是对服务器的数量进行取模,而一致性哈希算法是对2^32取模。
把二的三十二次方想象成一个圆,就像钟表一样,钟表的圆可以理解成由60个点组成的圆,而此处我们把这个圆想象成由2^32个点组成的圆,示意图如下: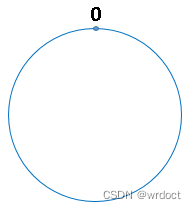
圆环的正上方的点代表0,0点右侧的第一个点代表1,以此类推,2、3、4、5、6……直到 2^32-1 ,也就是说0点左侧的第一个点代表2^32-1。
我们把这个由2的32次方个点组成的圆环称为hash环。
将需要缓存的对象经过哈希函数映射后,在哈希环中顺时针找离自己最近的那台,作为缓存的归属服务器。
一致性哈希算法就是通过这种方法,判断一个对象应该被缓存到哪台服务器上的,将缓存服务器与被缓存对象都映射到hash环上以后,从被缓存对象的位置出发,沿顺时针方向遇到的第一个服务器,就是当前对象将要缓存于的服务器。
由于被缓存对象与服务器hash后的值是固定的,所以,在服务器不变的情况下,一张图片必定会被缓存到固定的服务器上。
那么,当下次想要访问这张图片时,只要再次使用相同的算法进行计算,即可算出这个图片被缓存在哪个服务器上,直接去对应的服务器查找对应的图片即可。
边栏推荐
- Function analysis and source code of hash guessing game system development
- 针对深度学习的“失忆症”,科学家提出基于相似性加权交错学习,登上PNAS
- WinCC7.5 SP1如何通过交叉索引来寻找变量及其位置?
- After inserting a picture into word, there is a blank line above the picture, and the layout changes after deletion
- BFC interview Brief
- Qt五子棋人机对战画棋子之QPainter的使用误区总结
- Play the music of youth
- 电脑怎么保存网页到桌面上使用
- 实践示例理解js强缓存协商缓存
- FS4061A升压8.4V充电IC芯片和FS4061B升压12.6V充电IC芯片规格书datasheet
猜你喜欢

hash 表的概念及应用
Flet教程之 08 AppBar工具栏基础入门(教程含源码)
Alibaba testers use UI automated testing to achieve element positioning
Flet教程之 05 OutlinedButton基础入门(教程含源码)

Idea configuration standard notes

From automation to digital twins, what can Tupo do?
工厂从自动化到数字孪生,图扑能干什么?
What if the brightness of win11 is locked? Solution to win11 brightness locking

黄金k线图中的三角形有几种?

分析伦敦银走势图的技巧
随机推荐
强化学习-学习笔记2 | 价值学习
栈:如何实现有效括号的判断?
word中插入图片后,图片上方有一空行,且删除后布局变乱
#夏日挑战赛#带你玩转HarmonyOS多端钢琴演奏
Idea plug-in
Fleet tutorial 08 introduction to AppBar toolbar Basics (tutorial includes source code)
Taishan Office Technology Lecture: about the order of background (shading and highlighting)
node强缓存和协商缓存实战示例
Play the music of youth
分析伦敦银走势图的技巧
被奉为经典的「金字塔原理」,教给我们哪些PPT写作技巧?
科普达人丨一文看懂阿里云的秘密武器“神龙架构”
MySQL中的日期时间类型与格式化方式
《动手学深度学习》(三) -- 卷积神经网络 CNN
【ISMB2022教程】图表示学习的精准医疗,哈佛大学Marinka Zitnik主讲,附87页ppt
Understand Alibaba cloud's secret weapon "dragon architecture" in the article "science popularization talent"
What ppt writing skills does the classic "pyramid principle" teach us?
[ismb2022 tutorial] the picture shows the precision medicine of learning. Marinka zitnik, Harvard University, keynote speaker, with 87 ppt
ICML 2022 | meta proposes a robust multi-objective Bayesian optimization method to effectively deal with input noise
Is it safe for Great Wall Securities to open an account? Stock account opening process online account opening